 ISSN
ISSN 





-
在医学影像学中,常用的成像技术主要有计算机断层扫描(computed tomography, CT)、磁共振成像(magnetic resonance imaging, MRI)、正电子发射计算机断层扫描(positron emission computed tomography, PET)、单光子发射计算机断层扫描(single photon emission computed tomography, SPECT)等。其中,通过CT和MRI获得的图像可以提供解剖信息,具有较高的空间分辨率;前者可区分骨骼、血管等有密度差异的组织,后者可区分软组织但却无法提供骨骼信息。通过SPECT和PET获得的图像能够反映人体的功能结构和代谢信息,但其空间分辨率一般较低。因此,若能将人体同一部位的不同医学图像融合,就可用一幅图像表示多种结构和功能信息[1]。医生就能根据融合图像做出更精确的诊断。基于以上原因,多模态医学图像融合已经成为图像处理领域的研究热点之一。
多模态医学图像融合是指将不同医学成像技术采集到的同一部位图像进行融合的过程[2]。获得的融合图像与单一成像技术提供的图像相比,其信息更加全面。然而,尽管不同成像技术的图像具有显著差异,这些图像间仍存有大量冗余信息。因此,在有效提取互补信息的同时尽可能剔除冗余信息是获得高质量融合图像的关键。
根据融合方法划分,图像融合算法可分为空间域和变换域算法。空间域算法根据融合规则直接处理图像每个像素,是逻辑较为简单的算法。变换域算法则是通过数学变换方法将图像转换为频域表示方式并得到相应的频域系数,随后采用合适的融合规则对系数进行融合,最后用相应逆变换得到融合图像。对于变换域算法来说,变换方法和融合规则的选择至关重要。
目前,已有多种融合算法应用于多模态医学图像融合领域,如稀疏表示、多尺度变换、神经网络等。然而,这些算法在图像质量和细节保存方面仍有较多缺陷。因此,本文结合引导滤波器与自适应稀疏表示,提出了一种新的多模态医学图像融合算法,用于提升融合图像的清晰度。
-
由于不同图像块的结构差异较大,传统稀疏表示算法通常需要学习一个高度冗余的字典来满足图像重建的要求。然而,这种高冗余字典不仅会使生成的图像产生视觉伪影,而且还会花费较长的运算时间。与其相比,自适应稀疏表示模型不仅构建了一个冗余字典,而且还构建了一组紧凑的子字典并在融合过程中自适应地选择这些子字典进行运算。该模型由文献[3]首次提出并应用于图像融合和去噪。此外,自适应联合稀疏模型(adaptive joint sparse model, JSM)[4]也被提出,其同样是基于自适应稀疏表示的概念。随后,文献[5]根据图像的相似结构将图像分解为相似模型、平滑模型和细节模型。其中,对细节模型使用自适应稀疏表示进行融合,提高了融合效率。文献[6]将自适应稀疏表示与修正后的空间频率结合用于多模态医学图像融合。
随后,自适应稀疏表示模型广泛应用于多尺度变换融合算法中。文献[7]为更好地提取图像边缘和方向信息,利用多个滤波器对输入图像进行分解,采用自适应稀疏表示模型对子带进行融合。文献[8]使用非下采样剪切波变换(non-subsampled shear wave transform, NSST)分解图像,利用自适应稀疏表示模型融合高频子带,得到了较好的融合结果。文献[9]也使用了NSST对输入图像进行分解,但自适应稀疏表示模型被用于低频子带的融合;而高频子带的空间频率被用于神经元的反馈输入,并且激励一个脉冲耦合神经网络(pulse coupled neural network, PCNN)进行融合,也得到了较好的结果。文献[10]则利用自适应的卷积稀疏表示模型融合遥感图像。文献[11]使用拉普拉斯金字塔分解输入图像,使用自适应稀疏表示融合了每一层子带,通过实验证明了该方法应用于医学图像融合的有效性。
在自适应字典的构建中,使用的训练集是由从多幅高质量图像中随机采样出的大量图像块构成的。同时,为保证训练集中的图像块都具有丰富的边缘结构信息,训练集需要删除强度方差小于给定阈值的图像块[12-14]。因此假设最终的训练集为
$P = \left\{ {{p_1},{p_2}, \cdots ,{p_M}} \right\}$ ,即有M个满足以上条件的图像块。然后,对集合P中的图像块根据其梯度主导方向进行分类,构建出一组子词典训练集。子字典训练集的构建采用方向分配方法[15],通过计算每个图像块的梯度方向直方图来决定主导方向。如对于图像块${p_m}\left( {i,j} \right) \in P$ ,其水平梯度${G_x}\left( {i,j} \right)$ 和垂直梯度${G_y}\left( {i,j} \right)$ 通过Sobel算子计算得出:式中,符号*为二维卷积运算符。
${p_m}$ 的每个像素$\left( {i,j} \right)$ 的梯度幅值$G\left( {i,j} \right)$ 和梯度方向$\varTheta \left( {i,j} \right)$ 分别为:随后,根据
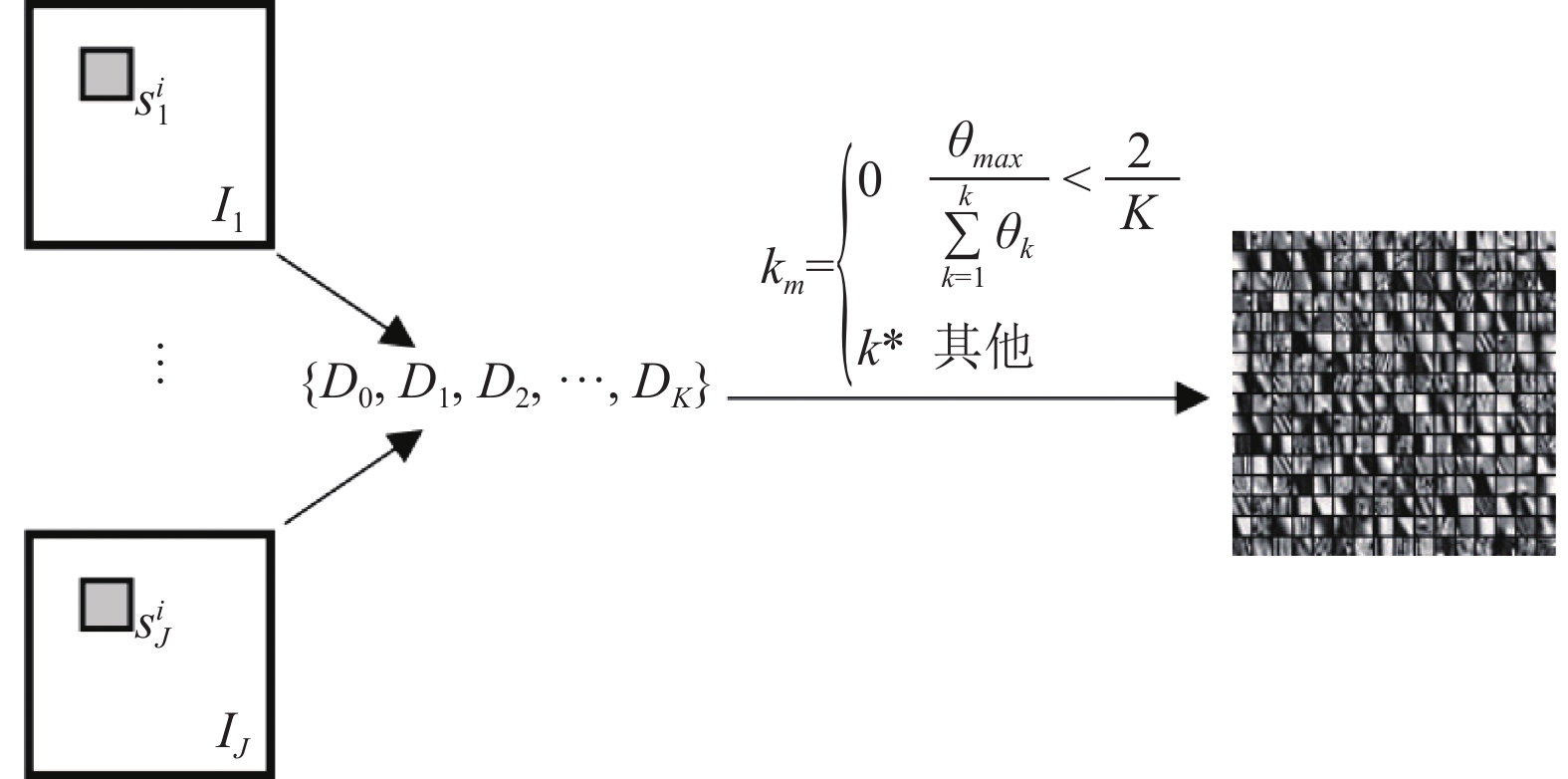
${p_m}$ 中所有像素的梯度幅值和方向来绘制${p_m}$ 的方向直方图。假设将$360^\circ $ 平均划分为K份,用于构建K个子字典,如图1a所示为K=4。其次,根据${p_m}$ 中每个像素的梯度方向将所有像素划分为K个方向。同时,将属于同一方向的所有像素的梯度幅值相加作为该方向在直方图中的统计量,由此得到${p_m}$ 的方向直方图。最后,选择直方图中统计量最大的方向作为${p_m}$ 的主导方向。由此,所有图像块根据其主导方向划分为K个图像块子集$\left\{ {{P_k}\left| {k = 1,2, \cdots ,K} \right.} \right\} \in P$ 。每个子集的图像块都有相同的主导方向因而都具有相似的结构。根据这些子集训练出的子字典将会更紧凑。
此外,模型最终需要构建出K+1个字典
$D = $ $ \left\{ {{D_0},{D_1}, \cdots ,{D_K}} \right\}$ ,其中字典${D_0}$ 如图1b所示,该字典是由集合P中所有图像块训练得到的,其余子字典$\left\{ {{D_k}\left| {k = 1,2, \cdots ,K} \right.} \right\}$ 则是通过其相应子集学习得出的,如图1c~图1f所示。在实际融合过程中,将待融合的输入图像切分成与
${p_m}$ 大小一致的图像块,并自适应地选择合适子字典进行融合。子字典的选择过程如图2所示。设${k_m}$ 表示为切分后的某一输入图像块应被分配到第${k_m}$ 个子集,${k_m}$ 按以下公式得到:式中,
${\theta _{\max }} = \max \left\{ {{\theta _1},{\theta _2}, \cdots ,{\theta _K}} \right\}$ ,${\theta _K}$ 表示该输入图像块的方向直方图中第K类的统计量,${\theta _{\max }}$ 为K个统计量的峰值;${k^*} = \arg \max \left\{ {{\theta _k}\left| {k = 1,2, \cdots ,K} \right.} \right\}$ 是${\theta _{\max }}$ 的指标,若${k_m} = 0$ ,则表示输入的是不规则图像块,将采用字典${D_0}$ 进行融合。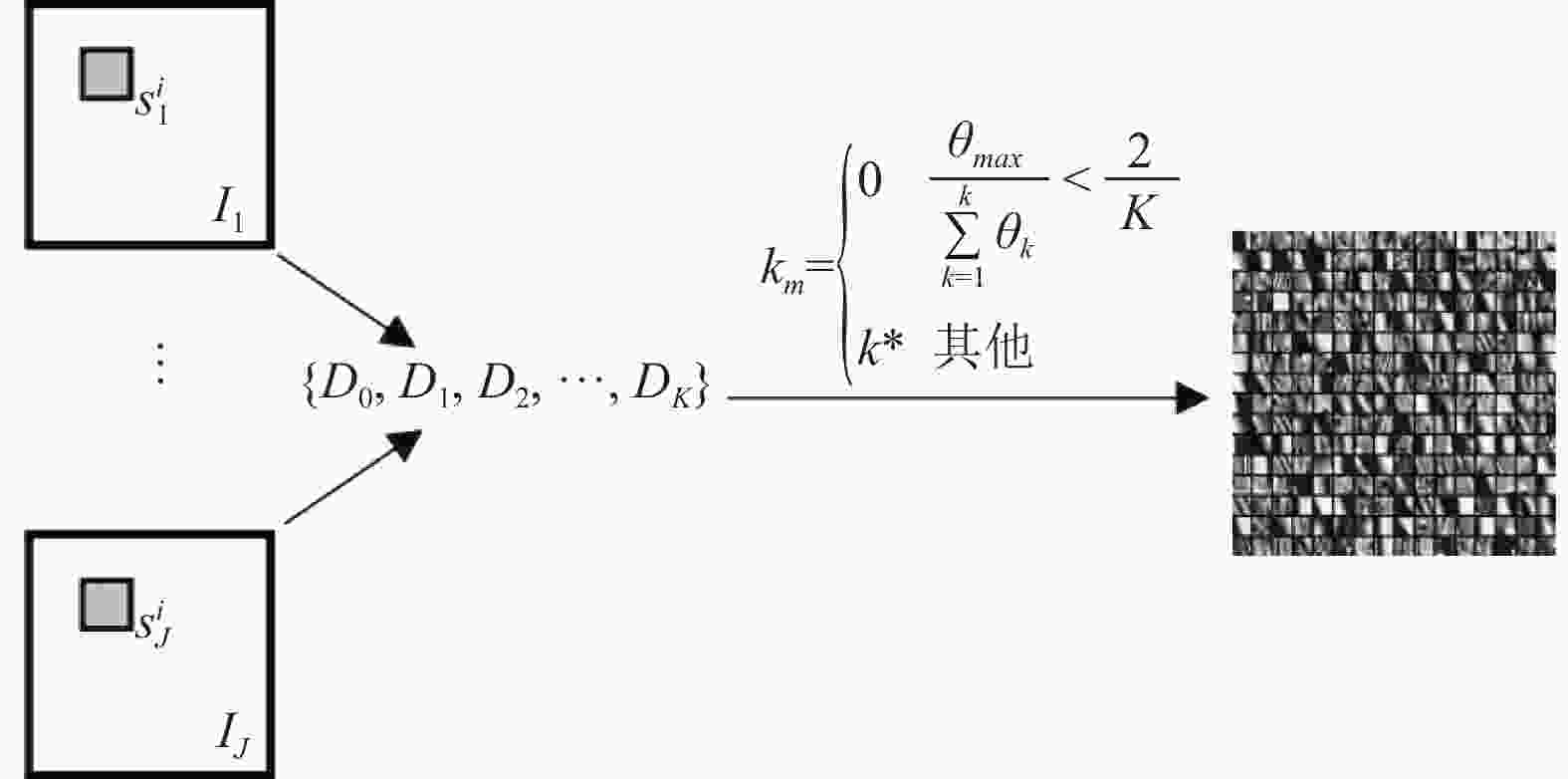
本文应用K-SVD(K-means singular value decomposition)算法对字典进行训练,训练集是通过对30组多模态医学图像进行采样得到的10万个大小为8×8的图像块。通过实验确定了参数K的最佳值为6,最终本文训练出7个字典,每张字典的大小均为64×256。
-
引导滤波器可较好地保持边缘信息,同时具有较低的复杂度。由于其良好的保边平滑性,大量研究将其应用于图像处理领域。文献[16]为在融合中挖掘出更多有效信息,提出基于目标提取和引导滤波增强的图像融合算法。文献[17]引入感知因子对引导滤波器进行改进,对原融合权重进行修正,明显改善了融合图像的边缘特性。此外,为更好保存有效信息以及提高空间连续性,文献[18]通过结合复剪切波变换(complex shearlet transform, CST)与引导滤波器的优点提出了新的图像融合方案。文献[19]使用改进的PCNN模型与引导滤波结合,更好地匹配了人眼视觉感知。文献[20]将引导滤波器与小波变换结合,克服了引导滤波器对噪声图像处理的缺陷,并提出了新颖的权值映射融合规则。文献[21]用引导滤波器和显著性映射分别计算输入图像分解后的权重图,得到较好的融合结果。
此外,引导滤波器也可以看作是一种图像的多尺度变换法,并且可以结合图像的像素值和空间信息来构造权重图。文献[22]基于这种理念结合随机游走模型用于融合多聚焦图像,其客观评价结果表明该方法可以得出很好的融合效果。因此,本文算法利用引导滤波器对输入图像进行分解,从而得到细节层和基础层。下面将介绍本文使用的引导滤波器模型。
引导滤波器可看作是一种具有局部窗口的线性滤波器,定义为:
式中,
$G$ 为引导图像,用于指导输入图像$I$ 进行滤波,得到输出结果$O$ ;${W_{ij}}(G)$ 为$I$ 在$\left( {i,j} \right)$ 处的像素点权重值,其根据$G$ 在$\left( {i,j} \right)$ 处的局部窗口${w_k}$ 中的所有像素计算得出。${W_{ij}}(G)$ 的计算过程如下:式中,
${\mu _k}$ 和${\sigma _k}$ 分别为局部窗口${w_k}$ 中的像素平均值和方差;${G_i}$ 与${G_j}$ 为两个相邻的像素点的像素值;$\varepsilon $ 为惩罚值。通过上式可得出,当像素点${G_i}$ 与${G_j}$ 在边界时,$( {{G_i} - {\mu _k}} )( {{G_j} - {\mu _k}} )$ 为异号,否则为同号。异号时,其权重较低,远小于同号时的权重,因此图像平坦区域的像素将会被添加一个较大的权重值,从而削弱了滤波器平滑模糊的效果,起到保持边缘细节的作用。此外,惩罚值$\varepsilon $ 同样显著影响该滤波器的滤波效果。当$\varepsilon $ 较小时,其滤波效果与上述相同,起到保持边缘细节的作用;而当$\varepsilon $ 较大时,引导滤波器就可以看作是一个均值滤波器,其平滑效果会更加显著,但却起不到保边平滑的效果。此外,也可以从线性滤波器的角度来理解引导滤波器:
式中,
${a_k}$ 和${b_k}$ 为局部窗口${w_k}$ 的常数参数;$w$ 为${w_k}$ 内的像素总数;${\bar I_k}$ 为局部窗口内的输入图像像素均值。在实际滤波中,由于同一个像素会被$w$ 个局部窗口包含,因此参数${a_k}$ 和${b_k}$ 一般会取其在所有局部窗口的均值。此外,对式(8)求导,可以得出:该式表明引导图像的梯度变化与结果图的梯度变化呈线性关系。因此,一般来说,引导图像的作用就是在提示输出图像不同输入区域的位置和梯度信息,以便更好地区分和保存输入图像的平滑和边缘区域。
-
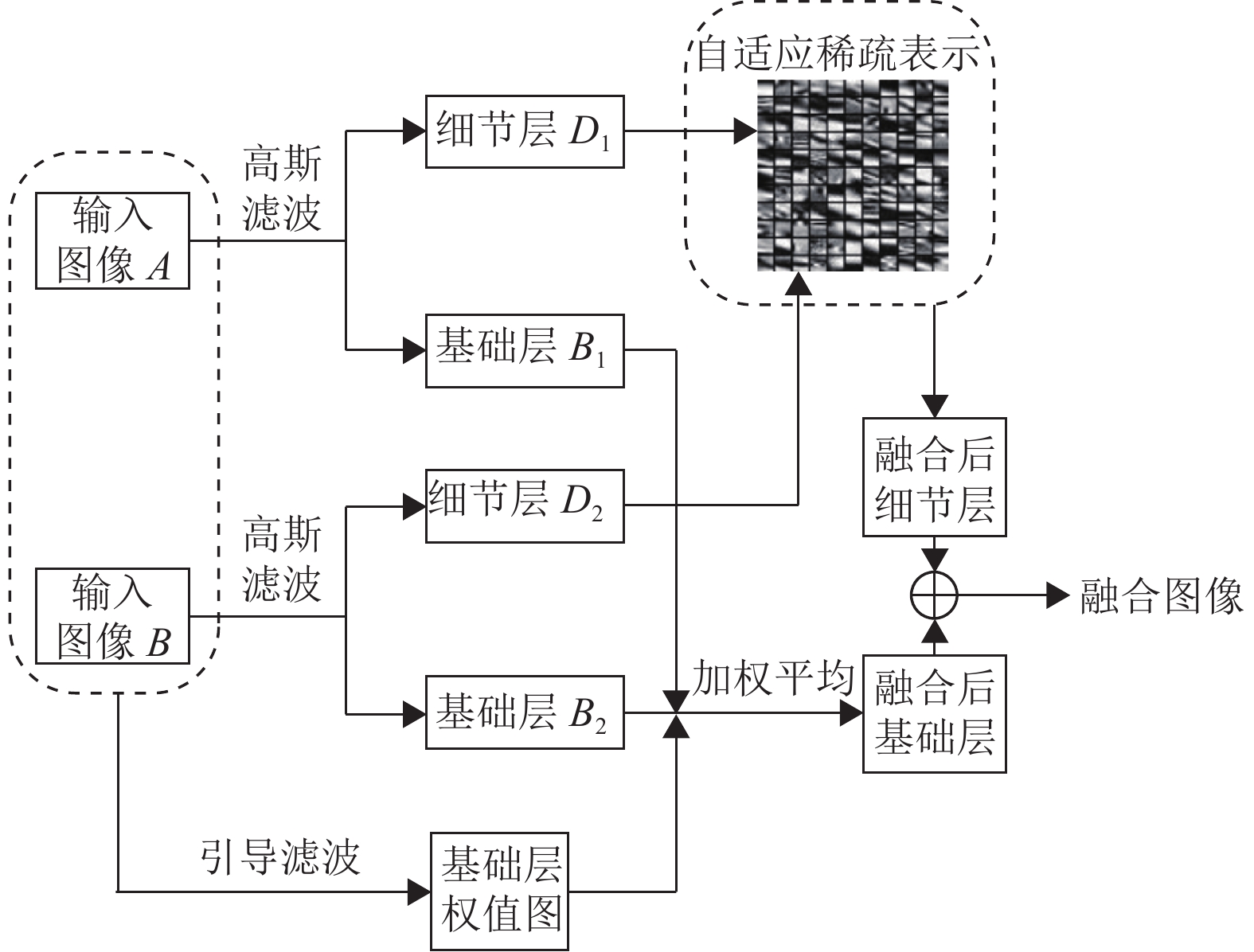
本文结合自适应稀疏表示模型和引导滤波器,提出一种新的多模态医学图像融合算法,该算法的流程图如图3所示。
1) 图像分解。使用高斯滤波器将输入图像
$A$ 和$B$ 分解为细节层图像和基础层图像,其过程如式(12)~式(14)所示:式中,
$G$ 表示高斯函数,使用大小为${\text{3}} \times {\text{3}}$ 的高斯核。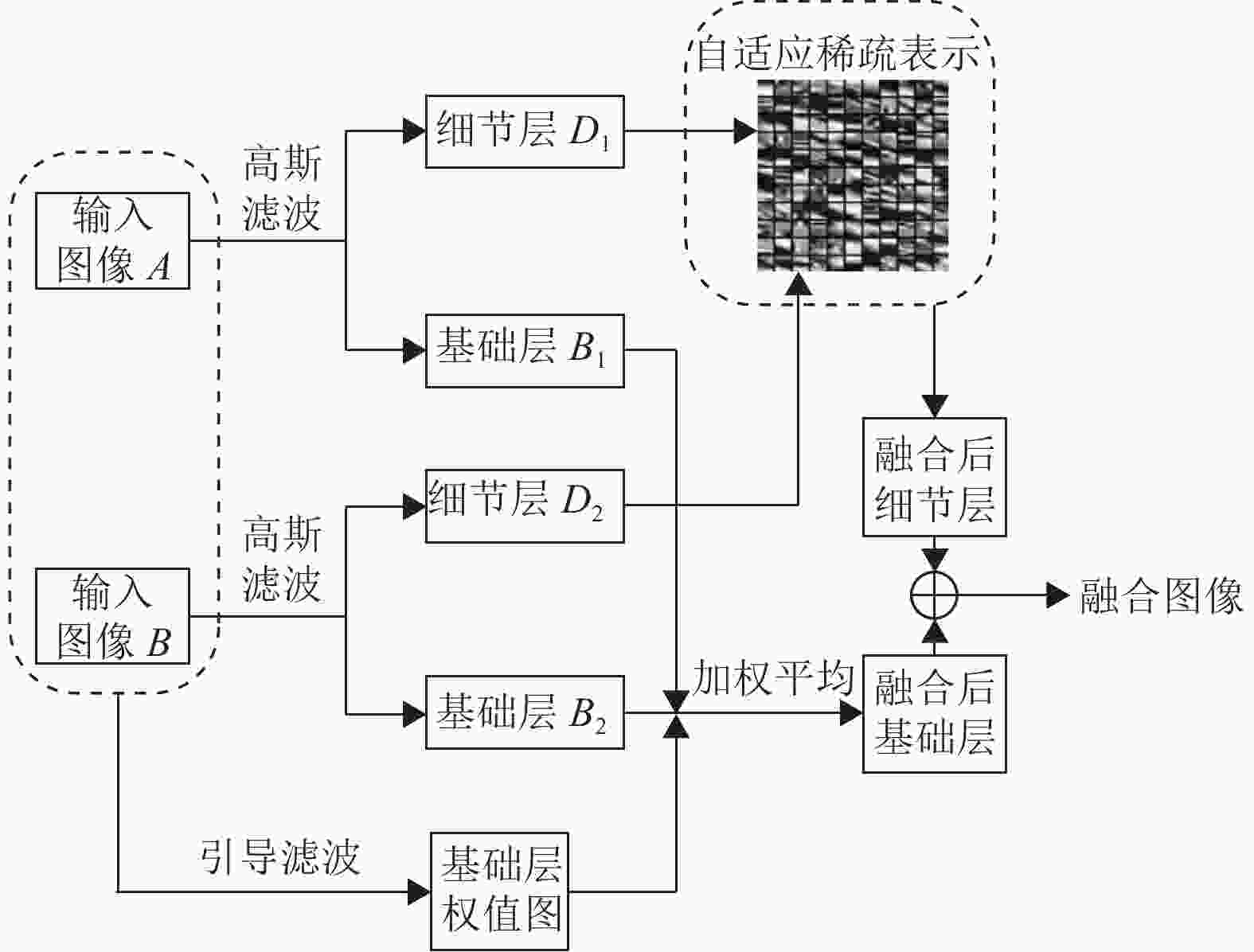
通过高斯滤波器得到基础层
${B_1}$ 和${B_2}$ 后,将输入图像与其基础层相减得到细节层${D_1}$ 和${D_2}$ :2) 结合拉普拉斯滤波器和显著性区域构建基础层的权值图。首先使用大小为
${\text{3}} \times {\text{3}}$ 的拉普拉斯滤波器L作用于输入图像$A$ 和$B$ ,获得其高通图像${H_1}$ 和${H_{\text{2}}}$ :对得到的高斯图像
${H_1}$ 和${H_{\text{2}}}$ 的绝对值进行显著性区域计算,构建显著性图像${S_1}$ 和${S_{\text{2}}}$ ,并得到其相对应的初始权值图${P_1}$ 和${P_2}$ :式中,
$Y$ 是大小为$( {{\text{2}}{\tau _g} + 1} ) ( {{\text{2}}{\sigma_g} + 1} )$ 的高斯低通滤波器,本实验中${\tau _g}$ 和${\sigma _g}$ 的值设置为5。若仅使用
${P_1}$ 和${P_2}$ 对图像进行融合会导致融合结果的拼接感过强,丢失大量边缘信息,从而使得融合图像会不符合人类的视觉系统。因此,将${P_1}$ 和${P_2}$ 作为输入图像$A$ 和$B$ 在引导滤波器中的引导图就可以计算出基础层的最终权值图:式中,
$r$ 和$\varepsilon $ 为引导滤波器的相关参数值,本文算法中这两个参数设置为:$r = 5$ ,$\varepsilon {\text{ = 0}}{\text{.001}}$ 。$ W_1^B $ 和$ W_2^B $ 分别表示输入图像$A$ 和$B$ 经过引导滤波后的基础层权值图。3) 融合基础层。针对计算得出的权值图
$ W_1^B $ 和$ W_2^B $ ,采用加权平均的融合规则来计算得到融合后的基础层${F_B}$ :4) 融合细节层。利用自适应稀疏表示模型对细节层
${D_1}$ 和${D_{\text{2}}}$ 进行融合,从而构建出融合细节层${F_D}$ 。由于医学图像的大小均为${\text{256}} \times {\text{256}}$ ,因此不需要图像配准过程。通过计算细节层图像块的方向直方图,然后根据式(5)自适应地选择不同字典对细节层${D_1}$ 和${D_{\text{2}}}$ 的图像块进行稀疏表示:式中,
${D_{k1}}$ 和${D_{k2}}$ 为自适应挑选的字典;${\alpha _{\text{1}}}$ 和${\alpha _{\text{2}}}$ 分别为细节层${D_1}$ 和${D_2}$ 的稀疏系数。随后,对稀疏系数进行融合。在本文算法中选择依据稀疏系数的方差进行融合。因此,设稀疏系数${\alpha _{\text{1}}}$ 和${\alpha _{\text{2}}}$ 的均值分别为${\mu _{\text{1}}}$ 和${\mu _{\text{2}}}$ ,则${\alpha _{\text{1}}}$ 和${\alpha _{\text{2}}}$ 的方差为:根据稀疏系数的方差大小和稀疏矩阵的稀疏度
${d_1} = {\left\| {{\alpha _1}} \right\|_0}$ 、${d_{\text{2}}} = {\left\| {{\alpha _{\text{2}}}} \right\|_0}$ 来指定稀疏系数的融合规则:最后,根据融合后的稀疏系数进行细节层重构,得到融合细节层:
5) 计算融合结果图。将融合后的基础层图像与融合细节层图像相加,得到融合图像
$F$ : -
为验证提出方法的有效性,选择3组多模态脑部病变医学图像进行对比实验。这些图片由网站(
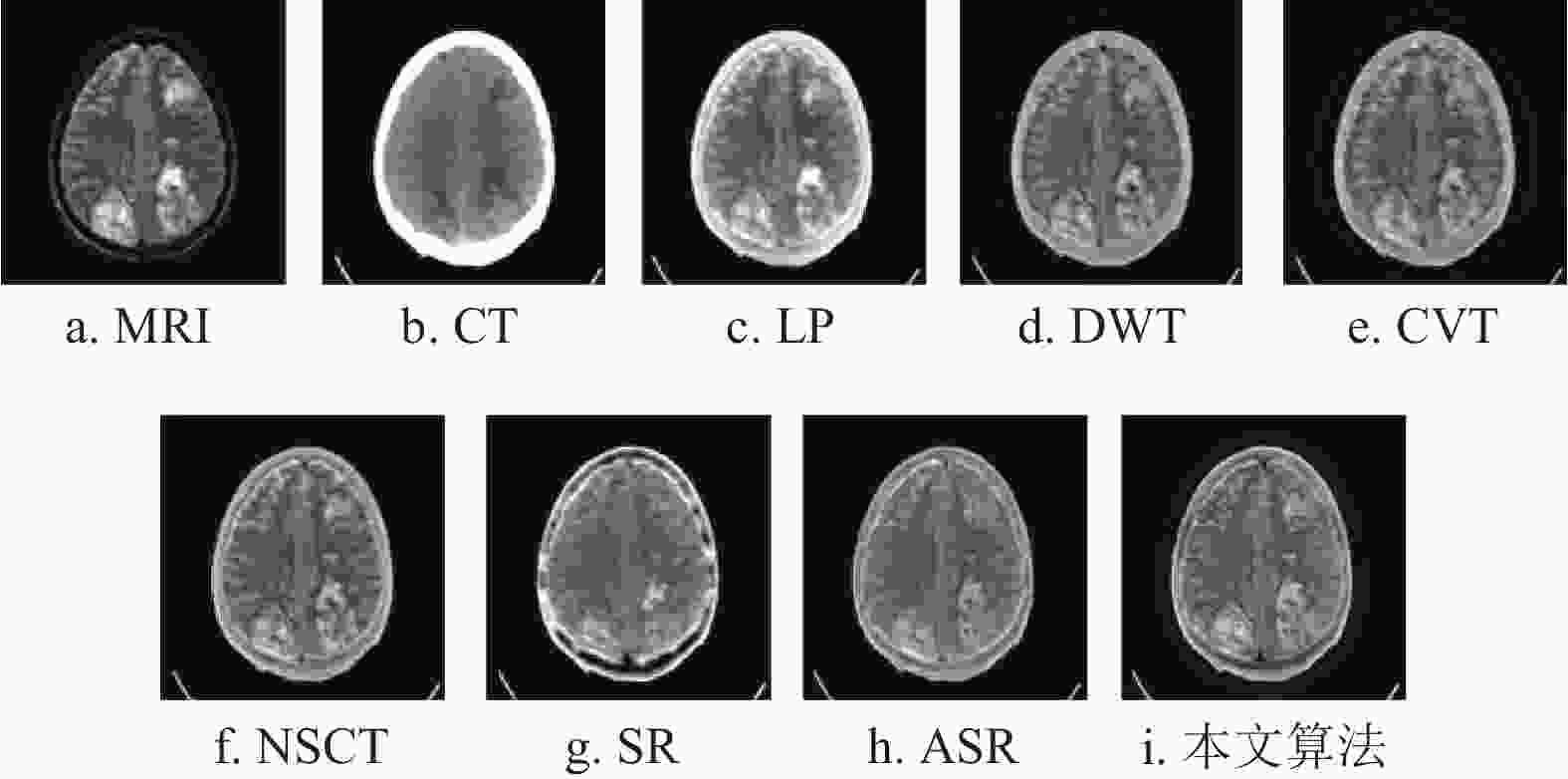
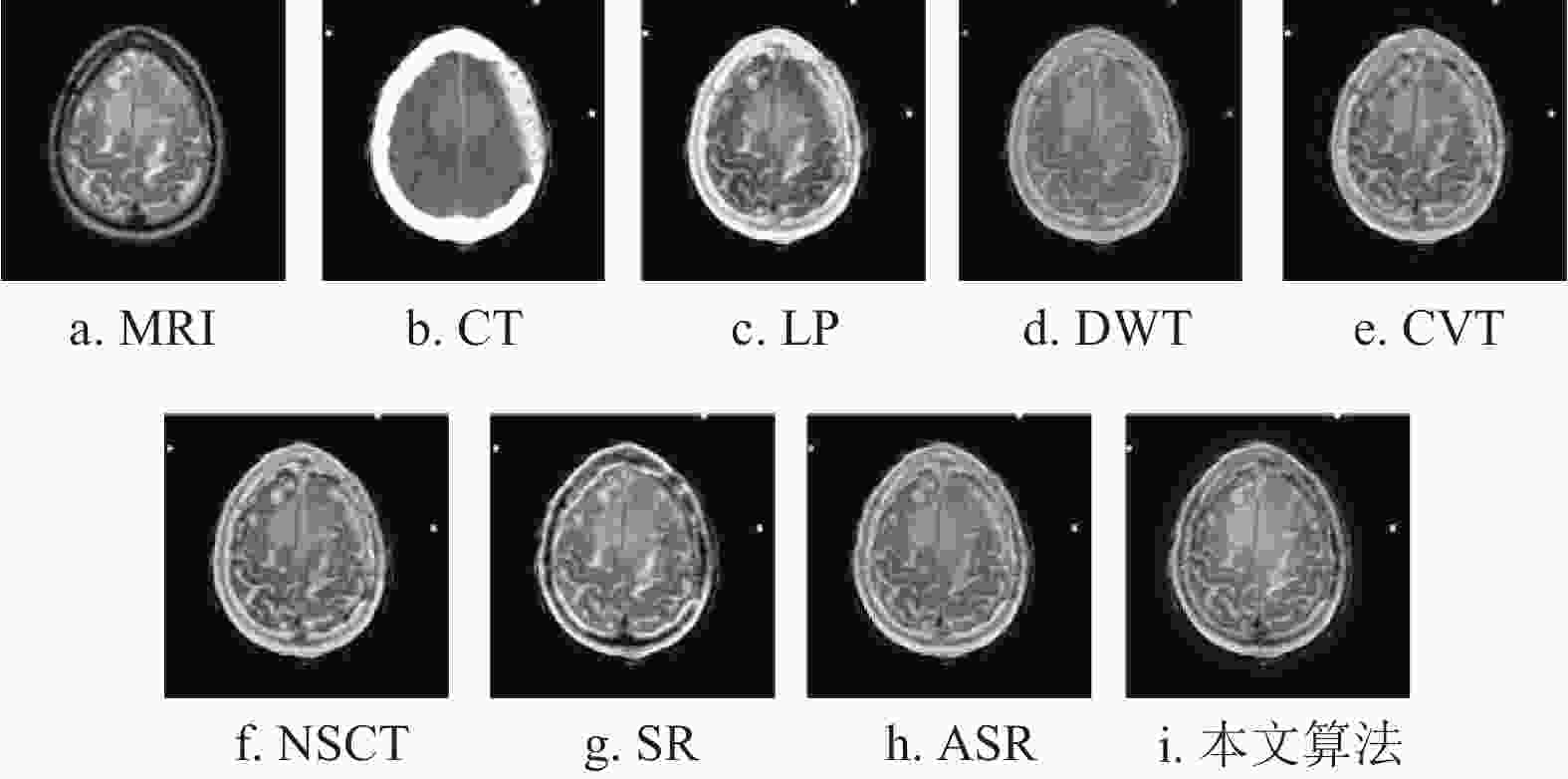
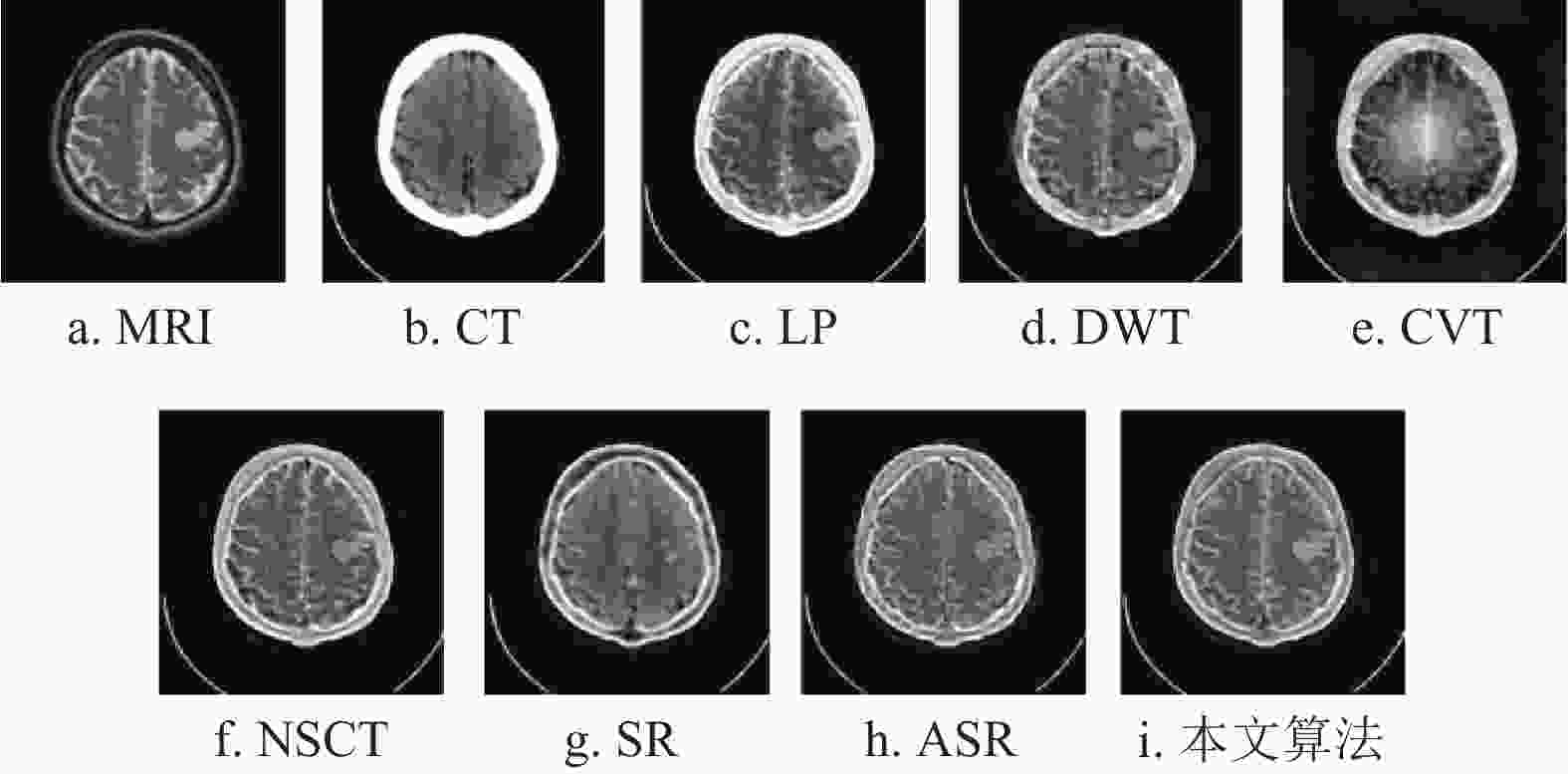
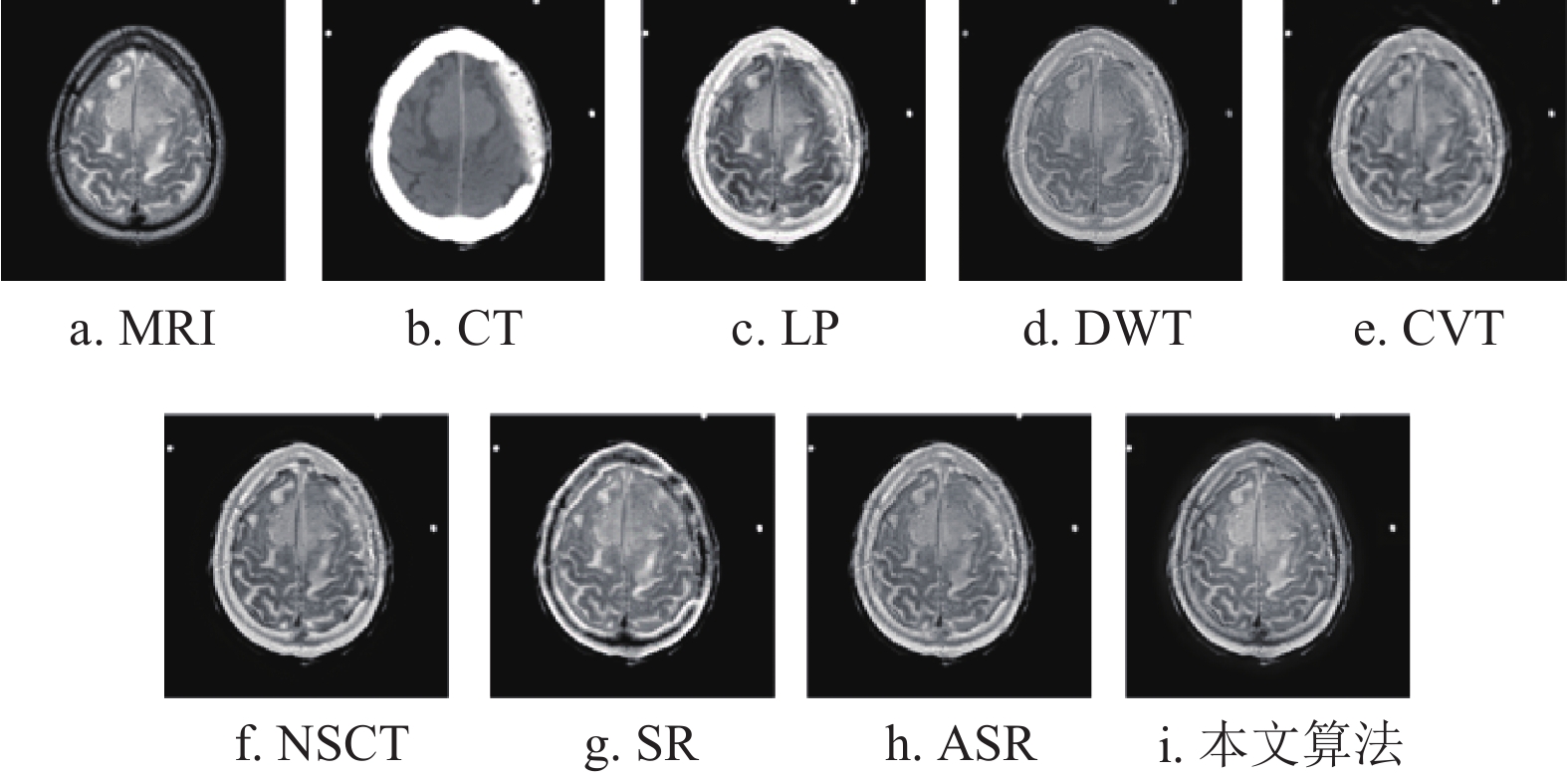
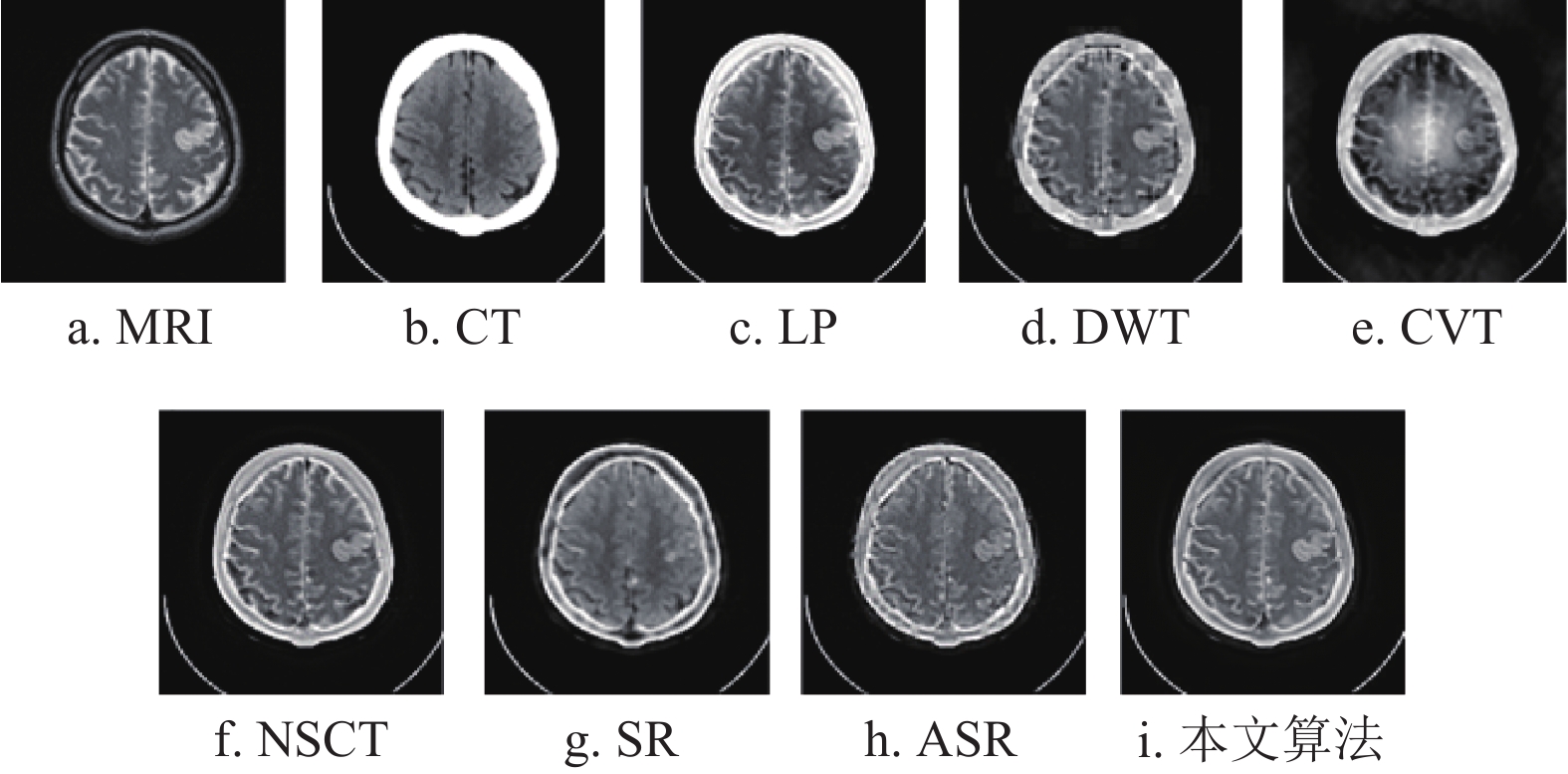
http://www.med.harvard.edu/aanlib/home.html )获取。实验使用的3组CT和MRI图像为:肉瘤患者的第17组脑切片、脑膜瘤患者的第17组脑切片和急性中风言语停止患者的第18组脑切片。所有的CT和MRI图像的大小均为${\text{256}} \times {\text{256}}$ 。本文算法与拉普拉斯金字塔(laplacian-pyramid, LP)、离散小波变换(discrete wavelet transform, DWT)[27]、轮廓波变换(contourlet transform, CVT)[28, 29]、非下采样轮廓波变换(nonsubsampled contourlet, NSCT)[30]、稀疏表示(sparse representation, SR)和自适应稀疏表示(adaptive sparse representation, ASR)等方法进行了比较。实验结果如图4~图6所示。
-
所有算法的融合结果通过以下8个指标进行评价:标准方差(standard deviation, SD)、平均梯度(average gradient, AG)、熵(entropy, E)[23]、空间频率(spatial frequency, SF)[24]、互信息(mutual information, MI)[25]、融合质量QAB/F、融合损失LAB/F和融合伪影NAB/F。其中QAB/F、LAB/F和NAB/F这3个指标是由文献[26]提出,具有互补信息,且三者之和为1。
${\rm{SD}}$ 、${\rm{AG}}$ 、$ {{E}}$ 、${\rm{SF}}$ 仅由融合图像$F$ 计算得出。因此,设$F$ 的图像大小为$M \times N$ ,$ {F_{i,j}} $ 表示$F$ 在$(i,j)$ 处的像素值,则标准差${\rm{SD}}$ 反应了$F$ 的像素离散程度;${\rm{SD}}$ 越大表明像素值分布越分散,越小则表明分布更集中:式中,
$\overline f $ 为$F$ 所有像素的均值。平均梯度
${\rm{AG}}$ 反映了$F$ 的纹理信息,用来评价图像的模糊程度。${\rm{AG}}$ 越大说明像素的变化率越大,图片更清晰:熵E是
$F$ 中所有像素点的信息量之和,当E较大时,$F$ 具有较高的对比度,并且有明显的灰度变化:式中,
$ {P_i} $ 为像素值为$i$ 的像素在$F$ 中出现的概率。空间频率
${\rm{SF}}$ 反映了灰度值的变化率,可用于评估图像的细节及纹理的多少。${\rm{SF}}$ 值越大说明$F$ 的纹理边缘信息更丰富。${\rm{SF}}$ 由横向频率、纵向频率、主对角线频率和副对角线频率组成:式中,
${\rm{RF}}$ 是$F$ 中所有处于同一行的相邻两像素差值的平方平均数;同理,${\rm{CF}}$ 、${\rm{MDF}}$ 、${\rm{SDF}}$ 分别是$F$ 中所有处于同一列、同一主对角线、同一副对角线的相邻两像素差值的平方平均数。此外,
${\rm{MI}}$ 、$ {Q_{{\rm{AB/F}}}} $ 、$ {L_{{\rm{AB/F}}}} $ 、$ {N_{{\rm{AB/F}}}} $ 由输入图像$A$ 和$B$ 以及融合图像$F$ 联合计算得出。其中,互信息${\rm{MI}}$ 表示$F$ 从$A$ 和$B$ 中获取的信息总量。${\rm{MI}}$ 越大,表明融合图像从输入图像中获取的信息量越多,融合效果越好:式中,
$P_i^F$ 、$P_j^A$ 、$P_j^B$ 为$F$ 、$A$ 和$B$ 的边缘分布;$P_{i,j}^{{\rm{FA}}}$ 和$P_{i,j}^{{\rm{FB}}}$ 为其联合分布。指标
$ {Q_{{\rm{AB/F}}}} $ 、$ {L_{{\rm{AB/F}}}} $ 和$ {N_{{\rm{AB/F}}}} $ 的计算需要使用滑动窗口对输入图像和融合图像进行分割计算。其中融合质量$ {Q_{{\rm{AB/F}}}} $ 用于评估$A$ 和$B$ 中的信息在$F$ 中的保存程度,$ {Q_{{\rm{AB/F}}}} $ 指标越高说明融合效果越好:式中,
$ \left| W \right| $ 为滑动窗口$\omega $ 滑动的次数;$ s( A |\omega ) $ 和$ s( B |\omega ) $ 为$A$ 和$B$ 在滑动窗口$\omega $ 内的显著性特征;$ {\rm{SSIM}}( {A,F} |\omega ) $ 和$ {\rm{SSIM}}( {B,F} |\omega ) $ 为$F$ 在$\omega $ 处与$A$ 和$B$ 的结构相似度。融合损失
$ {L_{{\rm{AB/F}}}} $ 是对融合过程中丢失信息的度量,即表示输出中的有价值信息在融合图像中丢失的程度。因此,其值越低,丢失的信息就会越少:式中,gF
$ (\omega ) $ 、gA$ (\omega ) $ 和gB$ (\omega ) $ 分别为$F$ 、$A$ 和$B$ 在窗口$\omega $ 处的区域强度;$ Q_{{\rm{AF}}}^g $ 和$ Q_{{\rm{BF}}}^g $ 表示融合图像的边缘强度;$ Q_{{\rm{AF}}}^a $ 和$ Q_{{\rm{BF}}}^a $ 表示融合图像的方向保持度。融合伪影
$ {N_{{\rm{AB/F}}}} $ 用于评价引入融合图像的无用信息的数量。这些信息在任何输入图像中都没有相对应的特征。因此,融合伪影本质上就是错误的信息,其值越小融合效果越好:不同算法结果的评价指标数值由表1~表3给出。所有指标中的最优数值加粗表示。从表1可以看出,本文方法在
$E $ 、${\rm{MI}}$ 、$ {Q_{{\rm{AB/F}}}} $ 和$ {N_{{\rm{AB/F}}}} $ 指标上的结果是最优,同时在${\rm{AG}}$ 和${\rm{SF}}$ 指标上取得了次优。在表2中,本文算法在${\rm{SD}}$ 、$E $ 、${\rm{SF}}$ 、$ {Q_{{\rm{AB/F}}}} $ 和$ {L_{{\rm{AB/F}}}} $ 指标上取得最优结果;同时,在${\rm{AG}}$ 和${\rm{MI}}$ 指标上取得次优。最后,在表3中,本文算法在$E $ 、${\rm{SF}}$ 、$ {Q_{{\rm{AB/F}}}} $ 和$ {L_{{\rm{AB/F}}}} $ 指标上取得最优结果;同时,在${\rm{AG}}$ 和${\rm{MI}}$ 指标上取得次优。方法 指标 SD AG E MI SF $ {Q_{{\rm{AB/F}}}} $ $ {L_{{\rm{AB/F}}}} $ $ {N_{{\rm{AB/F}}}} $ LP 76.533 8.8794 4.0853 2.6803 25.731 0.8060 0.1701 0.0239 DWT 67.226 8.1820 5.0401 2.4874 23.602 0.7624 0.2211 0.0165 CVT 66.589 8.5765 4.1552 2.4234 23.676 0.7727 0.2079 0.0194 NSCT 68.506 8.7211 4.9081 2.4904 24.364 0.8140 0.1672 0.0188 SR 72.747 10.1546 3.9090 2.2064 30.856 0.7590 0.2039 0.0371 ASR 66.472 8.5015 3.9935 2.4881 24.284 0.7597 0.2203 0.0200 本文 68.527 8.8376 5.4061 2.7121 26.388 0.8168 0.1705 0.0127 方法 指标 SD AG E MI SF $ {Q_{{\rm{AB/F}}}} $ $ {L_{{\rm{AB/F}}}} $ $ {N_{{\rm{AB/F}}}} $ LP 78.456 9.1955 3.8809 2.7126 21.698 0.8265 0.1575 0.0159 DWT 70.783 8.4168 4.1095 2.6828 18.956 0.8006 0.1936 0.0142 CVT 72.284 9.5181 5.2251 2.4214 20.839 0.8088 0.1725 0.0186 NSCT 74.269 9.3888 4.6663 2.5799 21.380 0.8231 0.1634 0.0145 SR 74.804 9.1603 3.7234 3.5916 25.389 0.8077 0.1545 0.0378 ASR 72.760 9.6806 3.9949 2.6422 21.759 0.8136 0.1655 0.0210 本文 78.569 9.6482 5.2857 2.7140 28.769 0.8462 0.1306 0.0232 方法 指标 SD AG E MI SF $ {Q_{{\rm{AB/F}}}} $ $ {L_{{\rm{AB/F}}}} $ $ {N_{{\rm{AB/F}}}} $ LP 81.741 9.9061 3.6812 2.5453 33.284 0.7787 0.2088 0.0125 DWT 65.327 10.6422 5.0856 2.8216 28.805 0.7353 0.2233 0.0414 CVT 71.313 10.4897 6.0979 2.1202 31.712 0.7502 0.2290 0.0208 NSCT 71.256 10.1243 5.1552 2.7553 31.919 0.7875 0.2002 0.0123 SR 69.150 12.8928 4.5865 4.0562 32.603 0.7786 0.1977 0.0238 ASR 68.468 10.5770 4.9699 3.0987 31.837 0.7810 0.2010 0.0179 本文 66.843 9.4702 6.2212 2.6018 33.577 0.8105 0.1626 0.0269 从整体来看,本文算法在
$E $ 、$ {Q_{{\rm{AB/F}}}} $ 上均取得了最优结果,且在${\rm{MI}}$ 和$ {L_{{\rm{AB/F}}}} $ 指标上也可获得最优或次优结果。这证明了本文算法相比于其他算法减少了输入图像的信息损失,保存了最多的输入信息,同时具有优良的纹理保留和细节信息的能力,因而在${\rm{AG}}$ 和${\rm{SF}}$ 指标上多次取得了最优或次优结果。最后,对于${\rm{SD}}$ 和$ {N_{{\rm{AB/F}}}} $ 指标,尽管本文算法分别存在一组最优结果,但其整体表现不佳,这意味着该算法的融合结果存在一定的伪影干扰,且融合图像的像素分布较为集中。此外,其他6种算法在某些指标上的表现也较为优异,甚至可以取得超越本文算法的结果,如表1和表3所示,LP算法在
${\rm{SD}}$ 指标上取得了最优结果。表2中的结果也表明LP算法取得了次优结果。而SR算法和ASR算法在${\rm{AG}}$ 、${\rm{MI}}$ 、${\rm{SF}}$ 这3个指标上表现较为优异,在3组实验中多次取得最优和次优结果。最后,DWT算法在$ {N_{{\rm{AB/F}}}} $ 指标上的表现较为出色,这表明其融合结果有较少的伪影。 -
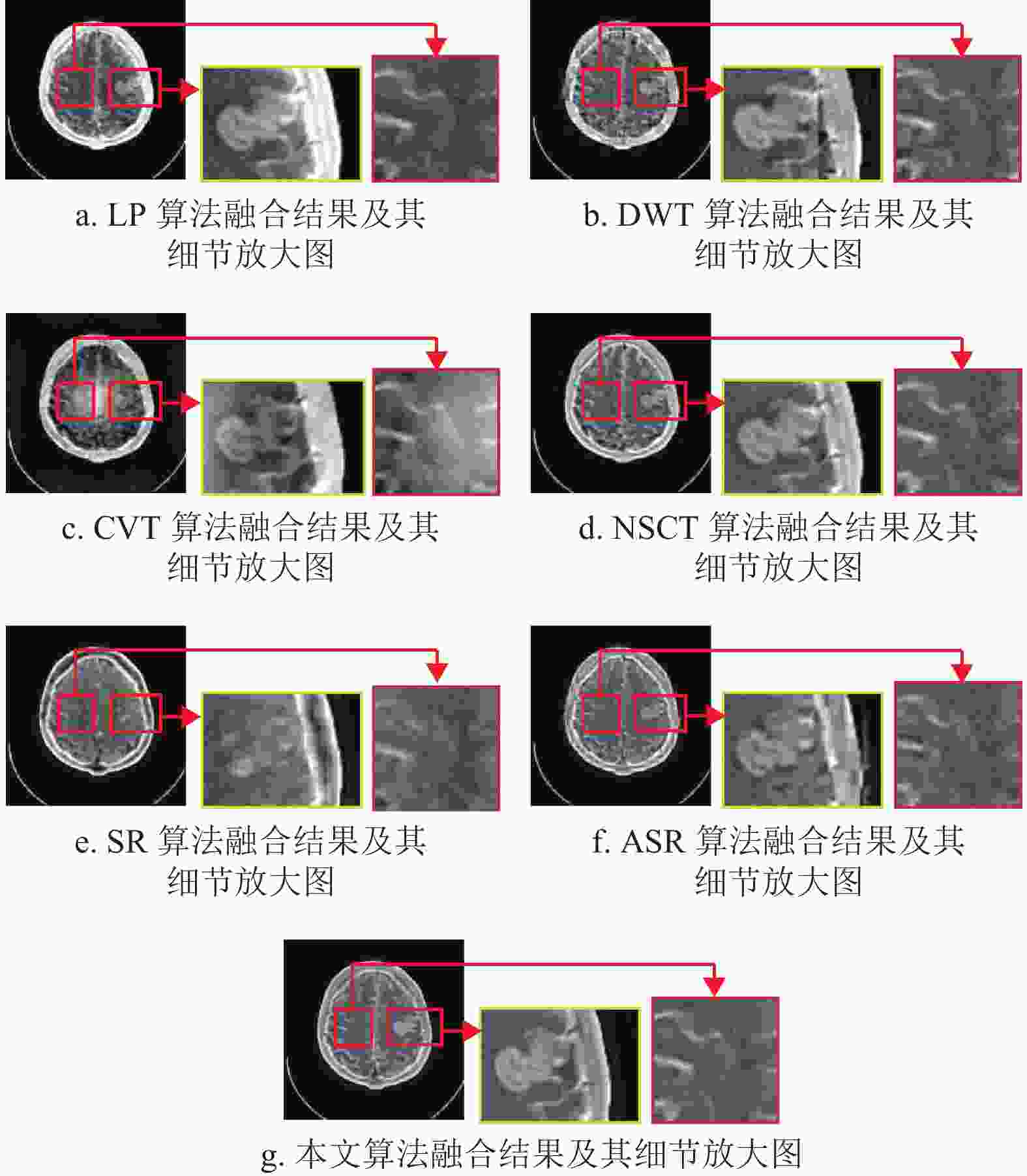
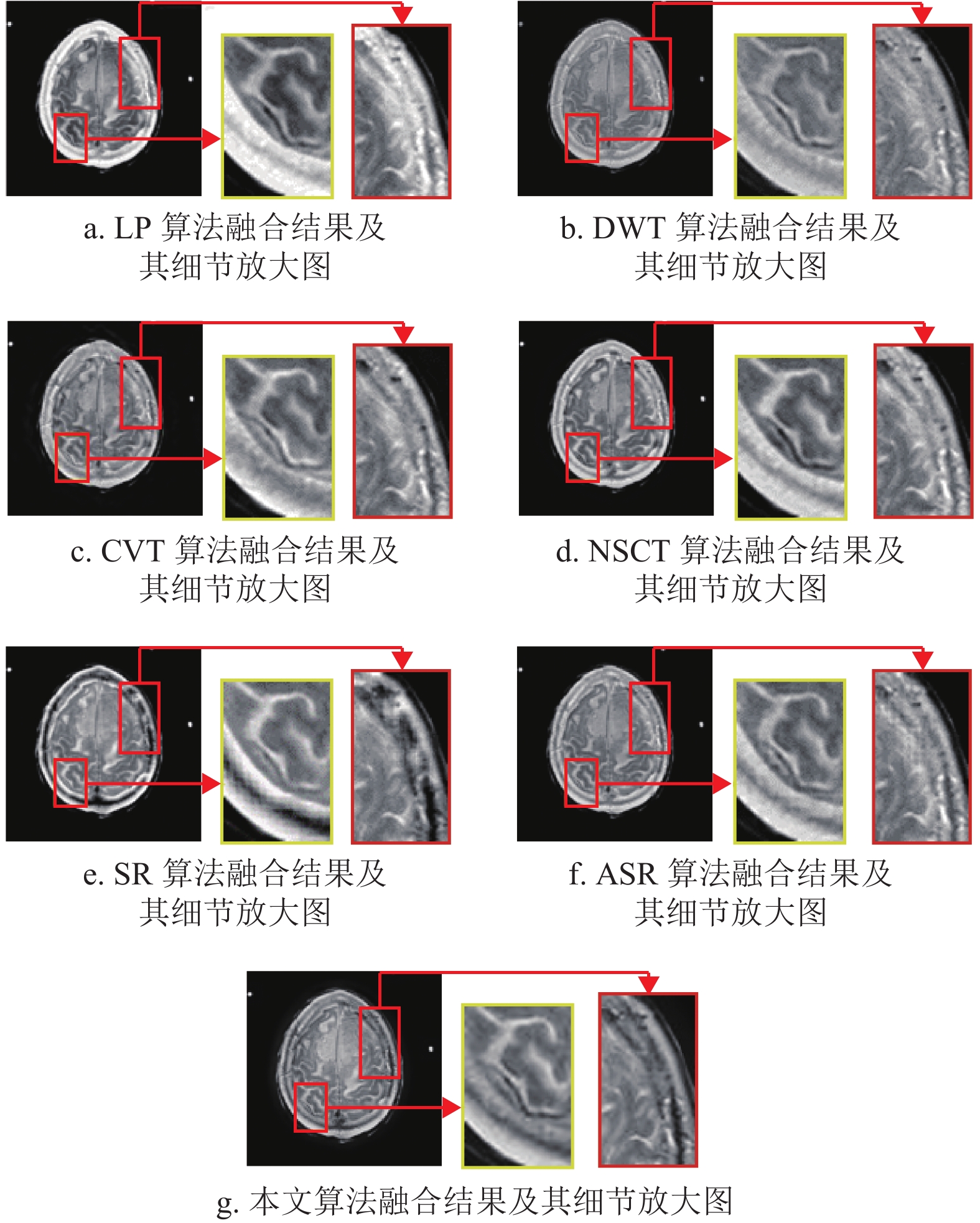
为了进一步证明本文所提算法的有效性,对图4~图6中所有算法融合结果的部分细节和边界区域进行了放大处理,以便在视觉评价方面对比本文算法与其他算法。所有算法的放大结果如图7~图9所示,其中融合图像中的方框为选中放大的图像区域,而放大后的图像在原图像的右侧展示并由对应的箭头连接。
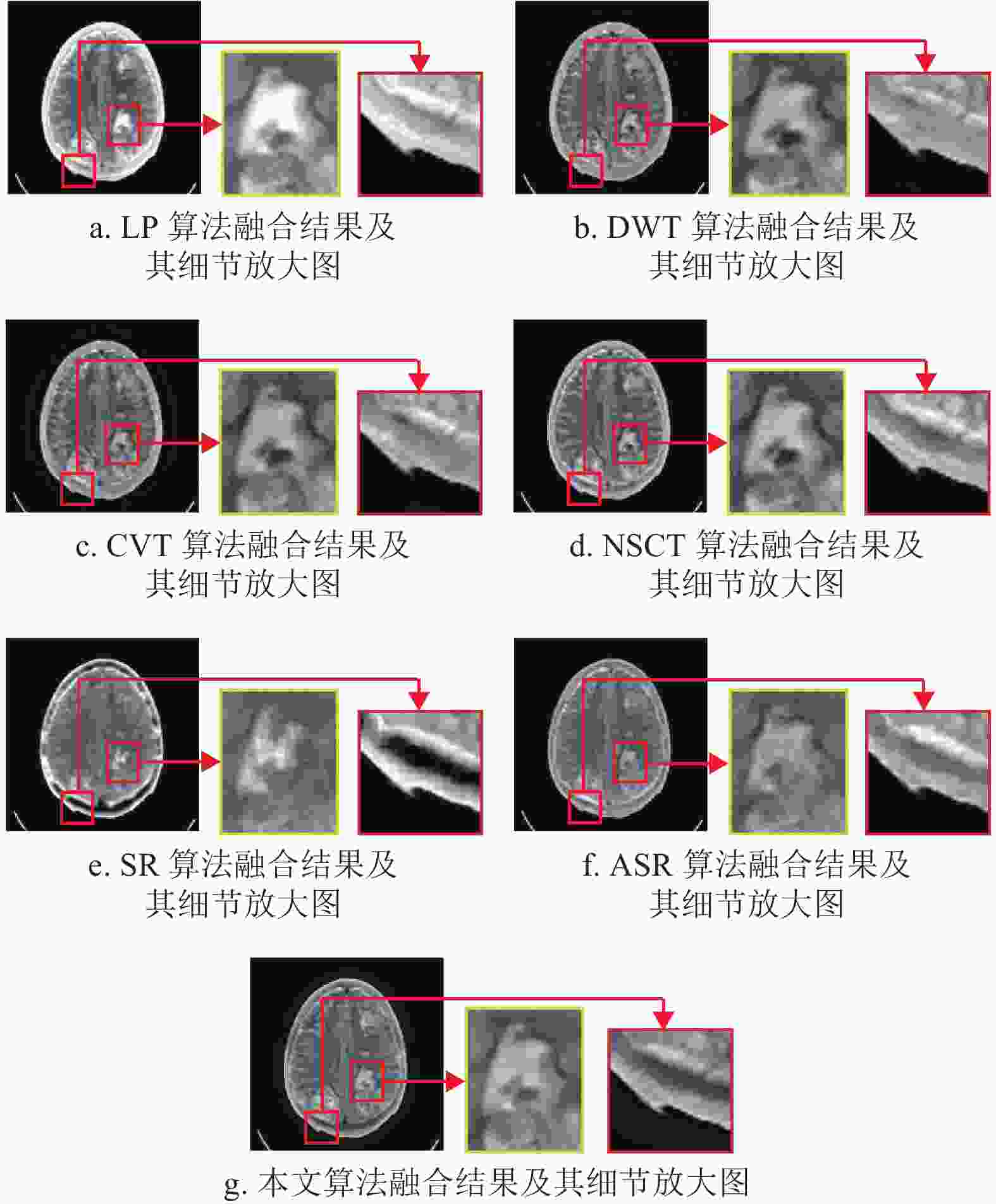
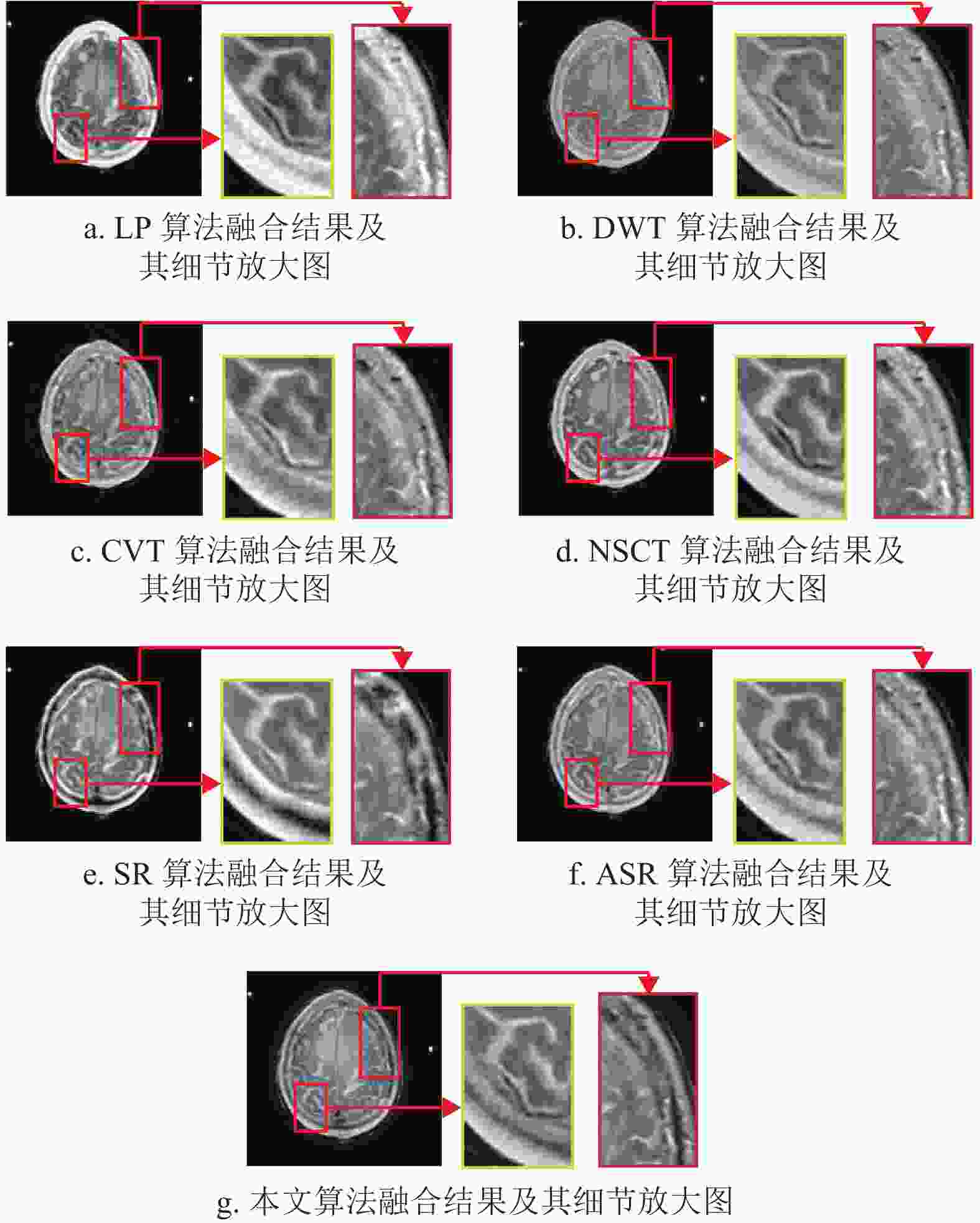
从图7a~图9a可以看出,LP算法的融合结果存在亮度过高的情况,导致该算法会丢失MRI图像的部分边缘细节。而这种情况同样出现在CVT算法中,如图9c所示。
对于DWT算法,从表2可以看出,其在
$ {N_{{\rm{AB}}/F}} $ 指标上取得了最优结果。然而,从图8b可以看出,其相对应融合图像的纹理信息和图像对比度与其他算法相比明显较差。这意味着该算法保存的信息较少,从表2和表3中也可看出,DWT算法在与信息保存相关的$ {Q_{{\rm{AB/F}}}} $ 指标上的数值结果是最差的。对于SR算法和ASR算法,尽管在指标评价分析中,两者的融合结果在与评价细节和纹理信息保存相关的
${\rm{AG}}$ 、${\rm{MI}}$ 、${\rm{SF}}$ 指标上都能取得优异的数值,如表1~表3所示;但在视觉分析中,从图7e~图9e以及图7f~图9f中可以看出,这两种算法融合结果的放大区域与其他算法相比更加模糊,这是由于图像重建的图像块效应导致的。而对于本文算法,尽管也会受到影响,但与SR算法和ASR算法相比有明显的提升。最后,从整体来看,NSCT算法和本文所提算法在纹理和边界信息都取得了较优异的视觉效果。但是通过比较图5b以及图8a~图8f可以看出,6种经典算法都存在不同程度的边界损失情况,而通过图8g可以看出,本文算法与其他6种算法相比保存了最多的边界信息。因而,与NSCT算法相比,本文算法更具鲁棒性。
-
在算法的时间复杂度方面,与传统的变换域融合算法(LP、DWT、CVT、NSCT)相比,基于稀疏表示的算法(SR、ASR、本文算法)更为复杂。对于ASR算法来说,每个待融合的图像块都要根据其梯度特征自适应地选择最适合的子字典,因而该算法会比SR算法更加耗时。而在本文提出的算法中,ASR模型仅用于细节层的融合。因此,为评价SR、ASR和本文算法的时间复杂度,在Inter Core i7-10875H@2.30 GHz八核处理器、16.0 GB内存及NVIDIA GeForce RTX 2060 6 GB显卡的硬件环境下进行实验。每个算法的程序以前文所述的3组实验图像为输入重复运行10次,计算每次的运行时间,并取均值作为最终结果来评价该算法的时间复杂度。
3种算法的平均运行时间如表4所示。其中,ASR算法的运行时间在3组实验中均为最长,而本文算法的运行时间在所有实验中均是最短。除此之外,通过对比SR和ASR算法的3组实验可以看出,不同的输入图像对其运行时间影响较大,尤其是在第三组实验中,SR和ASR算法的运行时间均高于前两组实验。而对于本文算法来说,其运行时间的变化较为稳定,受输入图像影响较小。
实验 运行时间 SR ASR 本文算法 第一组实验 26.1365 38.7666 17.1800 第二组实验 24.2896 36.0629 16.5811 第三组实验 36.2611 49.9927 17.7048 综上所述,与SR和ASR算法相比,本文算法的时间复杂度更低,且不受输入图像影响;然而,与LP、DWT、CVT、NSCT算法相比,该算法的时间复杂度仍有较大改进空间。
-
本文提出了一种基于自适应稀疏表示和引导滤波的多模态图像融合算法。该算法将待融合图像分解为细节层和基础层;利用基于引导滤波器的加权融合方法融合基础层;同时,利用自适应稀疏表示模型融合细节层。实验结果表明,本文算法在纹理和边界信息保存上均取得了优异结果;同时,时间复杂度也优于基于稀疏表示的方法。然而,本文算法在融合图像的对比度、伪影以及块效应上存在一定缺陷,需要进一步改进;算法的时间复杂度也需要进一步降低。
Medical Image Fusion Based on Guided Filtering and Sparse Representation
doi: 10.12178/1001-0548.2021165
- Received Date: 2021-06-11
- Rev Recd Date: 2021-11-18
- Publish Date: 2022-03-25
-
Key words:
- adaptive sparse representation /
- guided filter /
- image fusion /
- multi-modal medical image
Abstract: In order to improve the clarity of fused images, a multi-modal medical image fusion algorithm based on guided filter and adaptive sparse representation is proposed. Specifically, this algorithm adopts Gaussian filter to decompose the input images into detail layers and base layers. Subsequently, the weight maps of base layers are obtained based on saliency characteristics and guided filters, which are further utilized to fuse the base layers in combination with the weighted average rule; at the same time, the detail layers are fused through an adaptive sparse representation algorithm. Finally, the fused layers are directly added into the base layers to obtain the fused image. This algorithm is compared with other six classical algorithms on quality evaluation and visual analysis. In addition, the time complexity of the algorithm is also compared with that of two sparse representation-based algorithms. The results show that this algorithm outperforms other algorithms in the preservation of texture and edge information. Meanwhile, its time complexity is significantly better than that of sparse representation-based algorithms.
| Citation: | WANG Zhaobin, MA Yikun, CUI Zijing. Medical Image Fusion Based on Guided Filtering and Sparse Representation[J]. Journal of University of Electronic Science and Technology of China, 2022, 51(2): 264-273. doi: 10.12178/1001-0548.2021165

|



























































































































































































































































 DownLoad:
DownLoad: