 ISSN
ISSN 




-
社交媒体的快速发展为人们提供了获取、处理和共享信息的便捷平台,促进了海量信息的传播和扩散。其中,谣言的传播会带来不可逆、破坏性强、影响极广的负面影响[1-2]。谣言的自动识别有助于早期预防、减少损失,因此,谣言检测技术[3]应运而生。
早期的谣言检测方法主要采用监督学习[4-6],利用特征工程从文本内容[7-9]、用户信息[7]和传播模式[10-13]中提取可区别的特征,如传统机器学习模型[4]。随着深度学习模型的出现,基于RNN(recurrent neural network)、CNN(convolutional neural network)和AE(autoencoder)的方法在特征提取上有所改进,在情绪分析、机器翻译、文本分类等方面均取得了显著成果。文献[10]利用递归神经网络捕捉微博中谣言源帖及其转发帖的语义差异,从而根据语义的变化进行下一个传播点的预测。这是首个引入深度神经网络捕获谣言在整个传播过程的潜在时序变化的研究。文献[14]基于树的递归神经网络模型以捕获谣言在传播结构中的潜在语义信息特征。文献[15]使用一种变分自动编码器(variational autoencoder, VAE)获取帖子涵盖的文本特征和图像特征,以确定该帖子是否为谣言。文献[16]将源帖的传播路径建模为一个多元时间序列,利用RNN和CNN捕捉相关帖子参与者的用户特征沿传播路径的变化。上述模型多采用单一的文本内容检测模型,忽略了社会网络结构信息。此外,部分方法仅从信息个体角度进行考虑,忽略了社交网络信息之间所存在的结构相关性。如果同一用户发布或转发了多个帖子,则可以连接这些帖子。这样的关联可在连接的实例之间共享知识,帮助彼此检测以提高性能。
近年来,GCN(graph convolutional networks)从信息结构化的度检测谣言和假新闻。如文献[17]建立了一个深度扩散网络模型,学习新闻文章、创建者和主题的融合表示,挖掘社交网络的结构性特征。此外,信息在社交网络上的传播过程所构成的图网络具有异质性,从异构图的构建与分析角度可有效提高虚假信息检测模型的性能。如文献[18]通过从社交网络上的帖子、评论和相关用户构建的异构图中,捕获图结构中的语义信息。虽然目前GCN和异构图网络在谣言检测方面性能表现良好,但仍存在部分问题。首先,GCN针对图中每个学习到的节点表示采用的是标量式编码,需要逐一编码节点包含的所有属性,当数据量过大时,效率会大大降低。其次,现有异构图网络着重强调谣言传播过程的文本内容语义变化,忽略了用户之间的社交关系,在一定程度上对检测模型的性能进行了限制。此外,目前已有的谣言检测模型,对社交网络的异构性研究缺乏用户之间社交关系的考虑,而在真实的社交网络中,社交关系是一个较大的影响因素。
针对上述问题,本文提出了一种融合元路径学习和胶囊网络的社交媒体谣言检测方法(rumor detection based on meta-path learning and capsule network, CNMLRD),联合图嵌入和文本内容语义嵌入两方面对谣言在社交网络上的特征学习进行表示,利用胶囊网络以矢量编码增强学习到的特征。该方法首次将胶囊网络矢量编码模型用于谣言早期检测中,针对传统神经网络本身特性导致的检测模型编码效率低下的问题提出了一种新的解决思路。此外,该方法涉及基于元路径学习的异构图分解模型,实现了对用户潜在社交关系及图结构的全局语义信息挖掘,不仅提高了谣言早期检测模型的效率和精度,并在一定程度上增强了模型的可解释性。
-
为了准确描述面向社交网络的谣言检测问题,对以下概念进行定义。
定义 1 社交媒体关系:定义为社交传播实体与其对应的传播内容的集合
$ S = \{ {e_1},{e_2}, \cdots ,{e_s}\} $ ,其中$ {e_s} $ 指第$ s $ 个社交传播实体和其所传播的内容。定义 2 社交传播实体:在社交网络中参与了发表、转发和评论帖子等行为的用户个体,用集合
$ U = \{ {u_1},{u_2} \cdots ,{u_n}\} $ 表示,其中$ {u_n} $ 表示第$ n $ 个用户实体。定义 3 传播内容:用户所发表的帖子,并且这些帖子至少会有不少于1次的转发和评论,用集合
$ T = \{ {t_1},{t_2}, \cdots ,{t_m}\} $ 表示,其中$ {t_m} $ 表示第$ m $ 个帖子实体。定义 4 异常传播实体:以用户是否发起或转发过一条谣言帖子作为评判标准,将用户分为正常用户和异常用户。
根据以上概念,可以构建基础社交信息传播网络,并利用异常传播实体的评判标准将基础社交信息传播网络转化为异构图网络,然后采用图神经网络模型得到每一个传播实体与传播内容的低维向量特征表示,谣言的潜在特征可以结合信息在社交媒体网络上的结构特征以及信息内容的文本语义特征得到。
综上,本文将谣言检测任务看作二分类问题,目标是训练一个模型
$ f(\cdot) $ 以预测一个给定信息的标签$ f({t_i}) $ ,若$ f({t_i}) = 1 $ ,则$ {t_i} $ 为非谣言;$ f({t_i}) = 0 $ ,则$ {t_i} $ 为谣言。 -
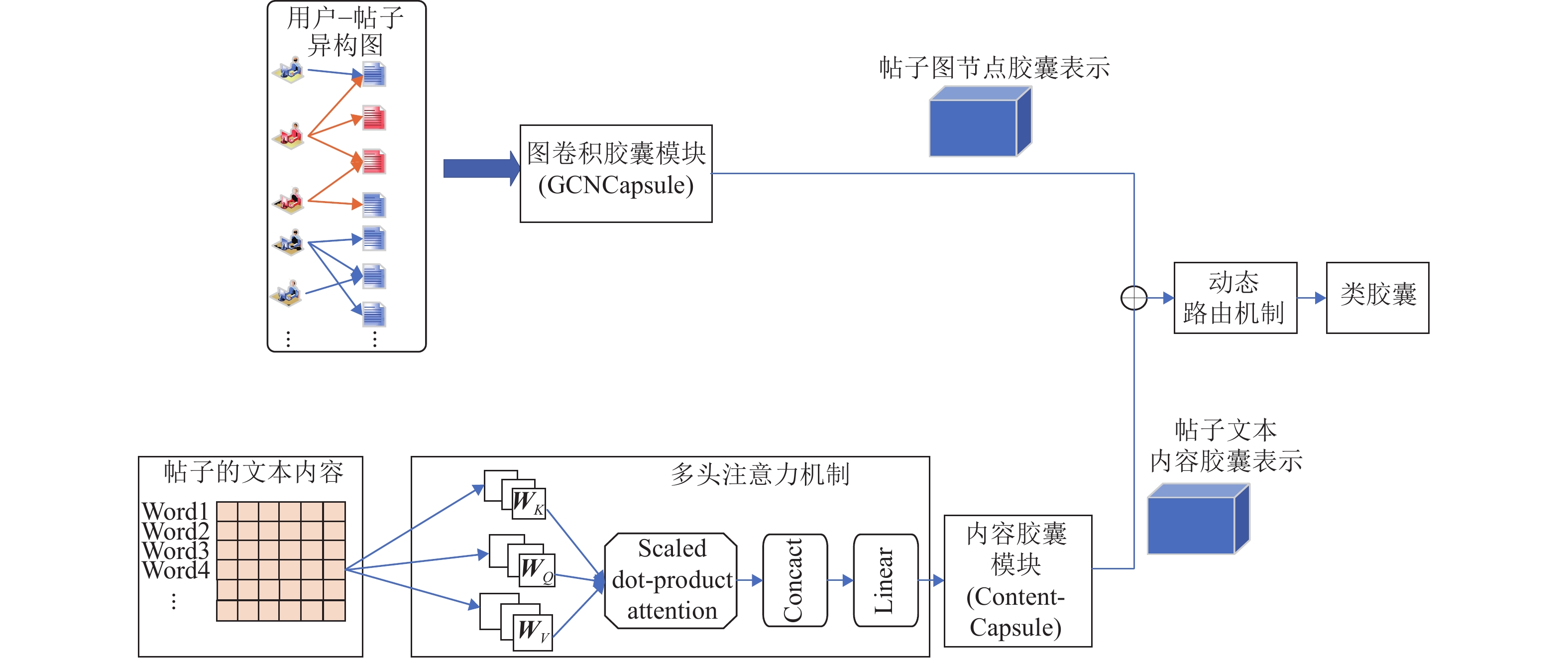
整个模型框架如图1所示,主要包含4个模块:用户−帖子异构图构建模块,图节点结构特征胶囊模块、文本内容特征胶囊模块以及特征融合模块。其中,用户−帖子异构图构建模块主要是完成对原始数据集的清理及预处理,再依据应用场景的需求构建适当的异构图;图节点结构特征胶囊嵌入模块主要是利用图卷积胶囊网络将异构图中节点的特征以胶囊形式嵌入得到图节点胶囊的表示,充分保留节点的属性;文本内容特征胶囊嵌入模块主要是利用内容胶囊网络将帖子文本内容的语义特征以胶囊形式进行嵌入得到帖子文本内容胶囊的表示,充分挖掘文本的语义特征;特征融合模块主要是将帖子在社交网络中的图节点胶囊表示与其文本内容胶囊表示进行融合,并在此基础上实现对谣言的划分。
-
异构图构建模块的目的是对原始数据集进行预处理,进一步对给定的数据按照其在实际社交网络中存在的点边关系,提取对应的点集、边集。针对常见社交网络构建的用户−帖子异构图
$ G $ ,图$ G = (V,E) $ ,$ V $ 表示图中节点的集合,包含所有的用户节点和帖子节点。$ E $ 表示图中边的集合,凡是用户发起、转发或者评论过的帖子,该用户与帖子之间存在社交媒体关系,这两者的节点之间存在一条边。进一步考虑用户的异常状态,以用户是否发起或转发过一条谣言帖子作为评判标准,将用户分为正常用户和潜在威胁用户:
式中,
$ {U_B} = \{ {u_{{b_1}}},{u_{{b_2}}}, \cdots ,{u_{{b_n}}}\} $ 表示社交网络潜在威胁用户的集合,$ {u_{{b_i}}} $ 表示潜在威胁用户;$ {U_Y} = \{ {u_{{y_1}}},{u_{{y_2}}}, \cdots ,{u_{{y_n}}}\} $ 表示正常用户的集合,$ {u_{{y_i}}} $ 表示正常用户;$ T = \{ {t_1},{t_2}, \cdots ,{t_m}\} $ 表示一个话题下的所有帖子的集合,$ {t_i} $ 表示帖子,$ {t_1} $ 表示源帖。节点之间的连接关系可以通过邻接矩阵$ {{{\boldsymbol{A}}}} = {\{ 0,1\} ^{|V| \times |V|}} $ 表示获得。 -
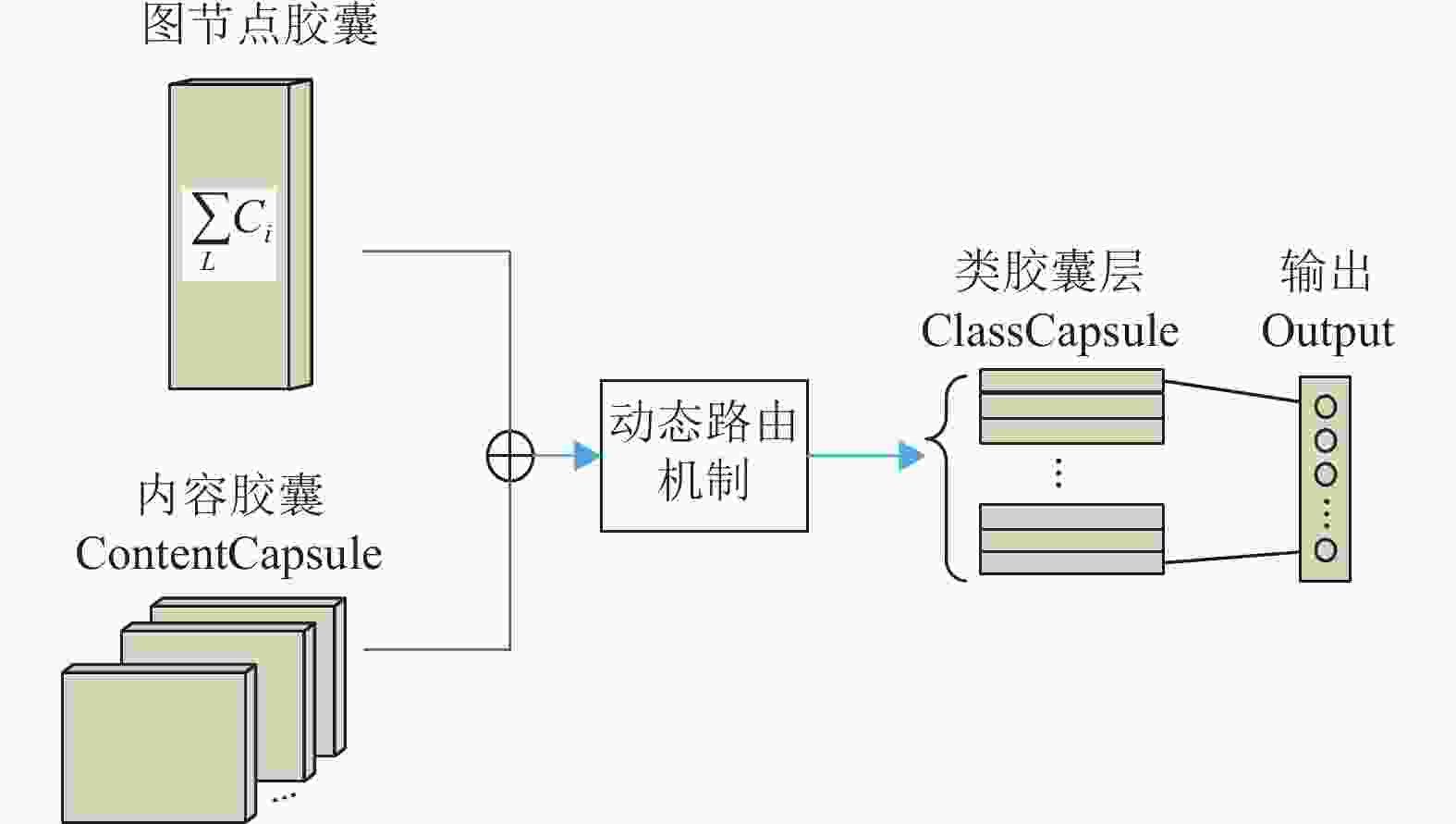
此模块在CapsGNN网络[19]基础上,根据本文的实际应用场景做出相应的调整,实现异构图节点的胶囊嵌入。在原有的CapsGNN网络中,只考虑了图结构信息,而在本文中需要将文本内容信息进行联合,因此在本文的图形嵌入部分的基础上实现对图节点胶囊的嵌入可以简化模型的复杂度。此模块主要包括GCN层、Capsule层和图节点胶囊构建层3部分,如图2所示。

其中,GCN层的目的是从原始图数据中提取图结构的低级特征,每一个
$ {Z_i} $ 表示一个GCN模块,可进行$ h $ 次图卷积操作,$ h $ 属于超参可设置。GCN的应用对象是图结构数据,利用图结构上节点的多阶邻域节点所包含的信息对该节点特征进行学习。假设图$ G = (V,E) $ ,$ V = \{ {v_1},{v_2}, \cdots ,{v_N}\} $ 表示节点集合,$ E = \{ {e_1},{e_2}, \cdots ,{e_m}\} $ 表示边集合,节点初始特征表示为$ X \in {\mathbb{R}^{N \times {d_0}}} $ ,其中$ {d_0} $ 示节点的特征维度。GCN采用的是逐层叠加的学习方式,所有节点同步更新。因此在GCN每层的学习过程中,卷积运算应用于每个节点及其邻居,并通过激活函数计算每个节点的新表示。其过程可表示为:
式中,
${Z^{l - 1}} \in {\mathbb{R}^{d \times {d'}}}$ 表示第$ l - 1 $ 层提取到的节点特征,$ d $ 表节点的维度;${Z^0} = X$ 为输入的初始特征;${\boldsymbol{A}}$ 表示节点的邻接矩阵;$\widetilde {\boldsymbol{D}}$ 表示邻接矩阵对应的度矩阵,可由式(3)表示;${{\boldsymbol{W}}^{l - 1}} \in {\mathbb{R}^{d \times {d'}}}$ 为第$ l - 1 $ 层的权重矩阵;$ \sigma $ 是非线性激活函数。Capsule层的主要目的是将图中所包含的节点特征表示转化为向量形式,有效保留图节点的完整属性。通过将每一个GCN模块提取的节点特征进行封装来实现。即原GCN层的GCN模块之间不再是简单的直接卷积,而是在原有的卷积上进一步捕获GCN模块内部特征通道之间存在的潜在关系,其过程可表示为:
式中,
$ Z_j^l \in {\mathbb{R}^{N \times {d'}}} $ ,$ {Z^0} \in X $ ;$\widetilde {\boldsymbol{A}} = {\boldsymbol{A}} + I$ ;$\widetilde {\boldsymbol{D}} = \displaystyle\sum\limits_j { {{\widetilde{\boldsymbol{A}}_{ij}}}}$ ;${\boldsymbol{W}}_{ij}^{l - 1} \in {\mathbb{R}^{d \times {d'}}}$ 是一个可训练得到的权重矩阵,它表示的是从第$ l - 1 $ 层的第$ i $ 个特征通道在第$ l $ 层的第$ j $ 个特征通道中所占比重;$ \sigma $ 是非线性激活函数,选用的是tanh函数。最后,在图节点胶囊层,通过累加的方式将每一个GCN模块得到的capsule叠加起来得到最后的图节点胶囊,即完成了对图节点胶囊的嵌入表示。
-
文本内容特征胶囊嵌入的主要目的是为了将每个帖子的文本表示用胶囊的形式嵌入,本文采用多头注意力机制和胶囊网络来实现,具体模型如图1下半部分所示。
为了对文本特征进行有效嵌入,首先利用文本截断的方式对文本进行预处理,设定处理后的文本为固定长度
$ L $ 。若文本长度大于$ L $ ,则以$ L $ 长度截断文本,若长度小于$ L $ ,则用0填充,帖子$ {t_i} $ 的文本内容表达式为:式中,
$ {\boldsymbol{x}}_j^i \in {\mathbb{R}^d} $ 为帖子$ {t_i} $ 中第$ j $ 个单词的词嵌入表示,采用热编码方式实现,$ {\boldsymbol{X}}_{1:L}^i \in {\mathbb{R}^{L \times d}} $ 。然后,使用多头注意力机制来细化词的嵌入,利用每一个头捕获某一方面的潜在关系,来捕获词之间的依赖关系。多头注意力机制构建原理的核心是计算三大矩阵集合,分别是索引矩阵集合
$ Q $ 、关键词矩阵集合$ K $ 和值矩阵集合$ V $ 。以本文采用的词嵌入$ {\boldsymbol{X}}_{1:L}^i \in {\mathbb{R}^{L \times d}} $ 为例,采用的是$ h $ 头注意力,则$ Q = \{ {{\boldsymbol{Q}}_1},{{\boldsymbol{Q}}_2}, \cdots ,{{\boldsymbol{Q}}_h}\} $ ,$ K = \{ {{\boldsymbol{K}}_1},{{\boldsymbol{K}}_2}, \cdots ,{{\boldsymbol{K}}_h}\} $ ,$ V = \{ {{\boldsymbol{V}}_1}, {{\boldsymbol{V}}_2}, \cdots , {{\boldsymbol{V}}_h}\} $ ,其中,$ {{\boldsymbol{Q}}_j} \in {\mathbb{R}^{L \times \tfrac{d}{h}}} $ ,表示第$ j $ 个头注意力所对应的索引矩阵,$ {{\boldsymbol{K}}_j} \in {\mathbb{R}^{L \times \tfrac{d}{h}}} $ ,表示第$ j $ 个头注意力所对应的关键词矩阵,$ {{\boldsymbol{V}}_j} \in {\mathbb{R}^{L \times \tfrac{d}{h}}} $ ,表示第$ j $ 个头注意力所对应的值矩阵,则$ {{\boldsymbol{Q}}_j},{{\boldsymbol{K}}_j},{{\boldsymbol{V}}_j} $ 可以通过式(6)计算得到:式中,
${\boldsymbol{W}}_j^Q,{\boldsymbol{W}}_j^K,{\boldsymbol{W}}_j^V \in {\mathbb{R}^{L \times \tfrac{d}{h}}}$ ,分别对应$Q,K,V$ 的权重矩阵,可以通过训练学习得到。在此基础上,结合注意力动态调整方法,按照式(7)计算得到某一头的值${{\boldsymbol{Z}}_j} \in {\mathbb{R}^{L \times \tfrac{d}{h}}}$ :最后将计算得到的
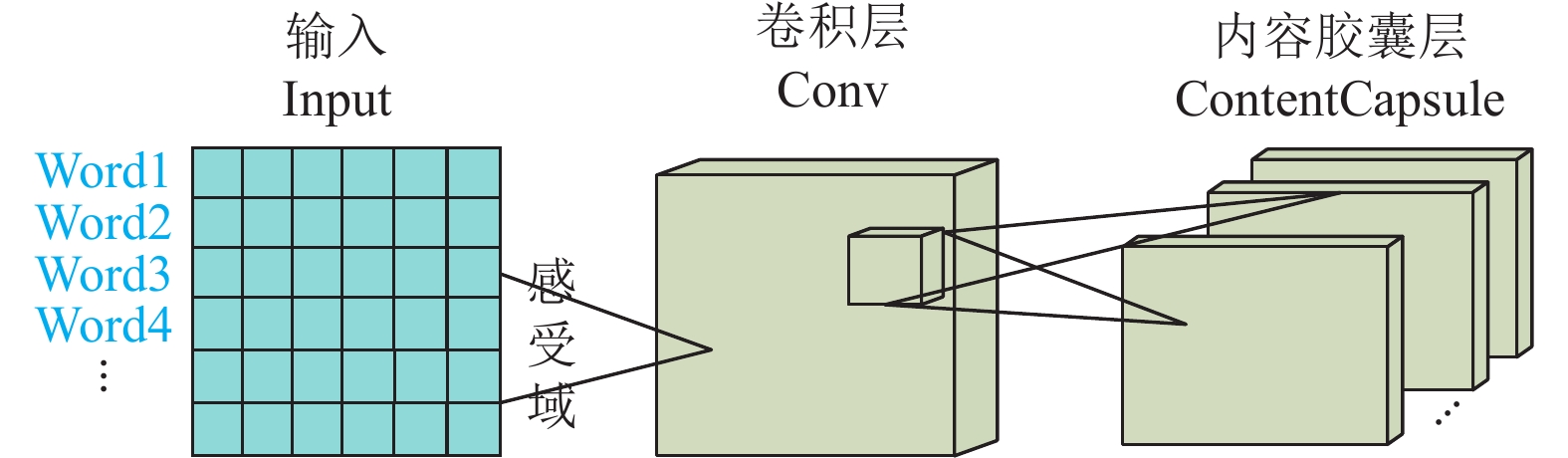
$ {{\boldsymbol{Z}}_1},{{\boldsymbol{Z}}_2}, \cdots ,{{\boldsymbol{Z}}_h} $ 进行拼接,得到通过词向量嵌入方式的文本初级嵌入$ {Z_{}} \in {\mathbb{R}^{L \times d}} $ 。在文本初级嵌入的基础上,利用一个内容胶囊(ContentCapsule)模块对文本的语义信息进行嵌入,模块的具体内容如图3所示。

在ContentCapsule模块的卷积层,将通过多头注意力机制得到的词向量嵌入作为输入,通过卷积层对文本初级嵌入进行一次局部特征检测,抽取低级特征,这样网络就可以在层次较少的情况下尽可能感受多的信息。随后,将卷积层得到的结果作为主胶囊层的输入构建相应的张量结构,在这一层,对上层输出执行
$ n $ 次不同权重的卷积操作,然后将这$ n $ 个卷积结果单元封装在一起组成Capsule神经元,这样就得到文本内容的低级别特征的向量。 -
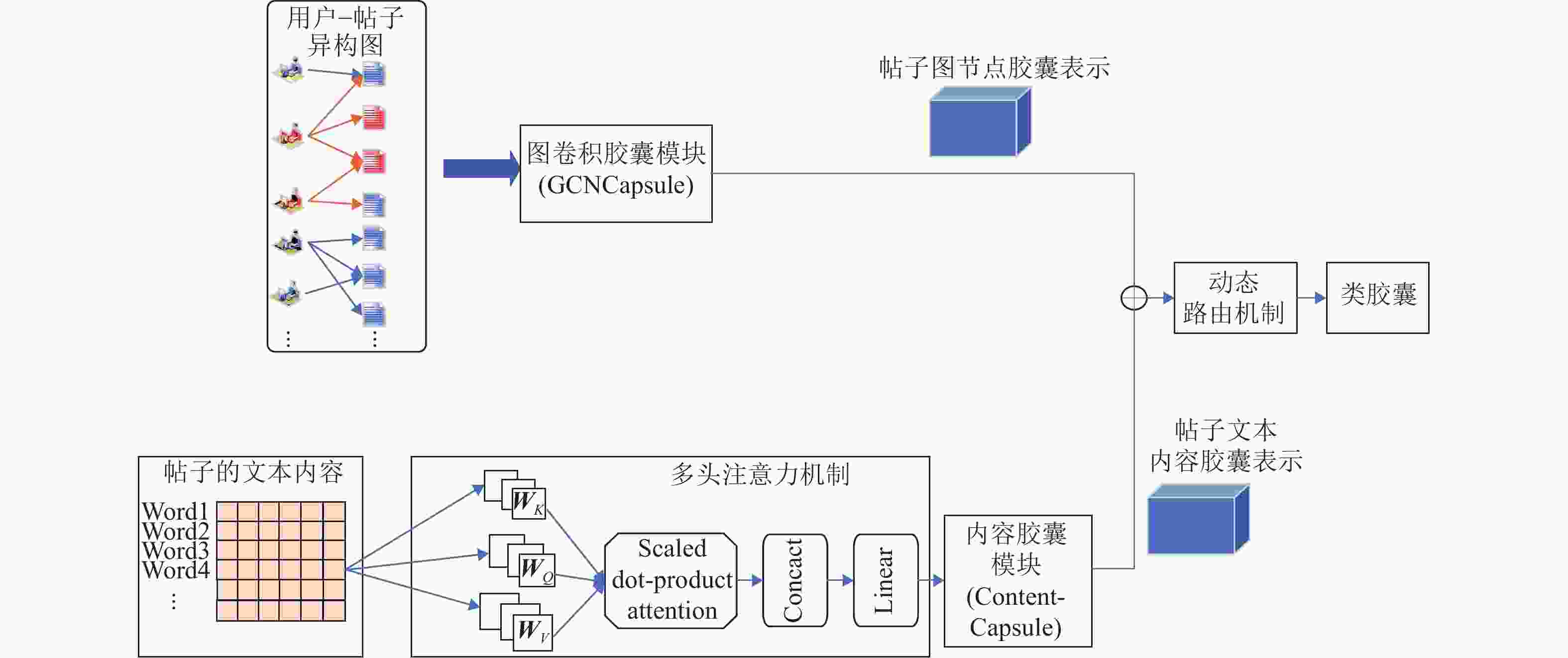
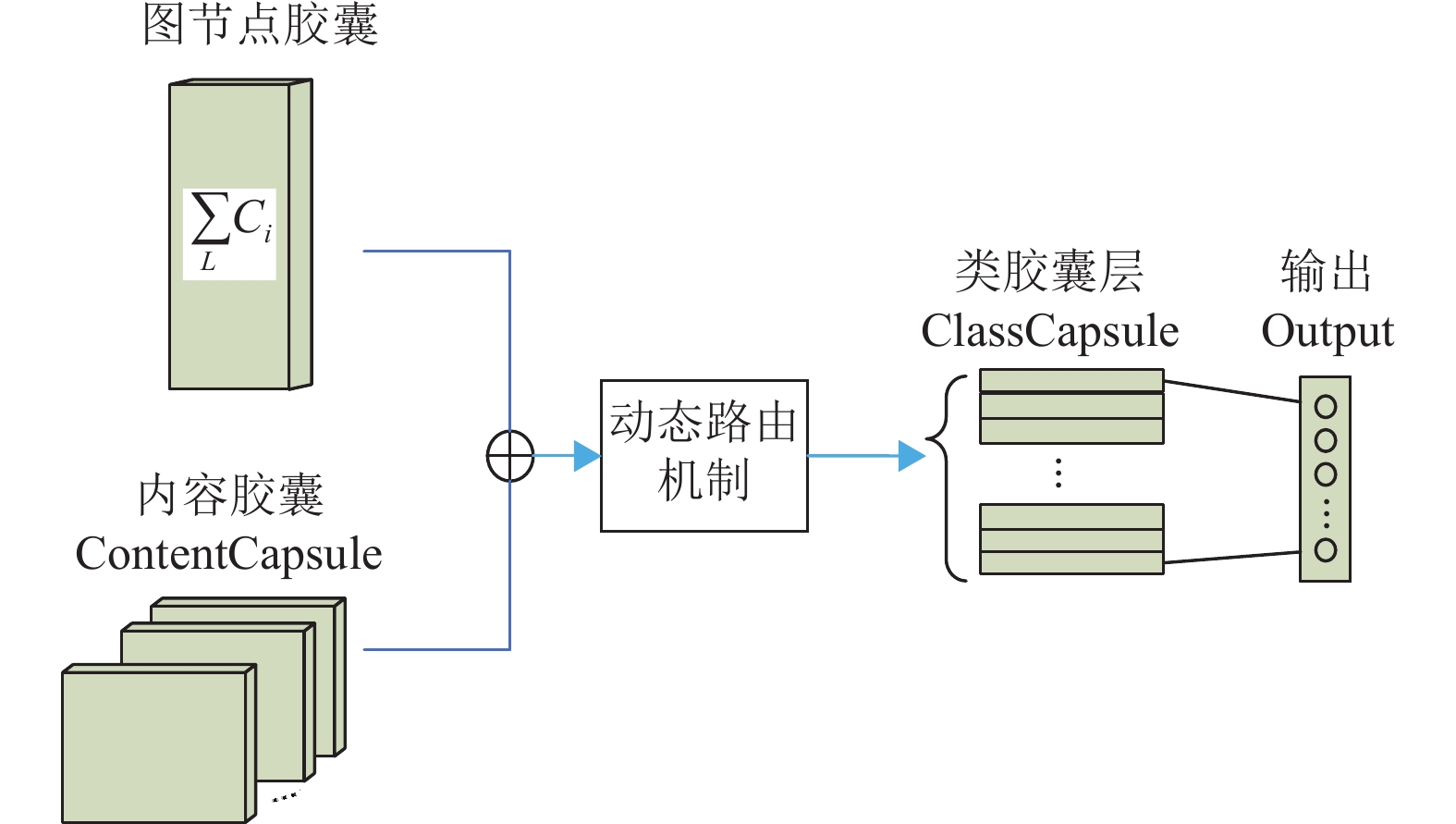
为了提高模型的检测精确度,在分别得到帖子传播图结构和帖子文本内容的特征矢向量以后,本模块将这两个表征矢向量进行融合,进一步学习更深层次的特征表示,用于后续对谣言的分类及检测。此模块的结构如图4所示。
此模块将帖子的图节点胶囊与内容胶囊进行融合,再在此基础上获取高级别特征的向量,由于这不是传统神经网络标量到标量,而是向量到向量,因此,需要用到一个动态路由机制进行传播和更新,得到类胶囊(ClassCapsule),最终根据输出向量模长得出类别概率向量,路由机制实现伪码如算法1所示。
算法 1 层级胶囊映射的路由选择
输入:子级胶囊
$ {\boldsymbol{S}} $ ,初始权重矩阵集$ W $ ,可迭代次数$ t $ 输出:父级胶囊
$ {\boldsymbol{H}} $ 路由选择伪码:
1) 针对所有的
$ l - 1 $ 层的胶囊$ i $ ,计算其与对应$ l $ 层的胶囊$ j $ 之间的预测标量积$ {{\boldsymbol{u}}_{j|i}} = {\boldsymbol{S}}_i^T{{\boldsymbol{W}}_{ij}} $ 2) 定义
$ {r_{ij}} $ 是$ l - 1 $ 层胶囊$ i $ 连接到$ l $ 层胶囊$ j $ 的可能性,初始值为$ {r_{ij}} \leftarrow 0 $ 3) 执行步骤4)~7)
$ t $ 次4) 针对
$ l - 1 $ 层的胶囊$ i $ ,将$ {r_{ij}} $ 转化为概率$ {\tilde r_i} $ :$ {\tilde r_i} \leftarrow {\text{softmax}}({r_{ij}}) $ 5) 对
$ l $ 层的胶囊$ j $ 进行加权求和得到$ {{\boldsymbol{h}}_j} $ :$ {{\boldsymbol{h}}_j} \leftarrow \displaystyle\sum\limits_i {{{\tilde r}_{ij}}{{\boldsymbol{u}}_{j|i}}} $ 6) 对
$ {{\boldsymbol{h}}_j} $ 进行压缩得到$ {\widetilde h_j} $ :$ {\widetilde h_j} \leftarrow {\text{squash}}({{\boldsymbol{h}}_j}) $ 7) 更新
$ {r_{ij}} $ ,$ {r_{ij}} \leftarrow {r_{ij}} + {{\boldsymbol{u}}_{j|i}}{\widetilde h_j} $ 8) 返回
$ {\widetilde h_j} $ 结束
其中,squash和softmax函数的具体计算如式(8)~式(9)所示:
-
本文采用测评数据集Twitter15和Twitter16[12]进行实验验证,2种数据集分别包含1 490和818条谣言源推文。数据集中的每一条源推特被标记为真实谣言(true rumor, TR)、虚假谣言(false rumor, FR)、未经证实的谣言(unverified rumor, UR)或非谣言(non-rumor, NR)。由于原始数据集不包括用户配置文件信息,调用Twitter API3抓取与源推文相关的所有用户的配置文件。数据集的其他细节如表1所示。
数据集 Twitter15 Twitter16 总谣言源推文数/条 1 490 818 真实谣言数/条 372 207 虚假谣言数/条 370 205 未经验证的谣言数/条 374 201 非谣言数/条 374 205 总源推文数/条 331 612 204 820 用户数/人 276 663 173 487 -
针对本文所选用的评测数据集,为验证本文所提出模型的有效性,与下列7种谣言检测模型进行对比。
1) DTR[20]:基于决策树的模型,通过正则表达式对从Twitter流中提取的集群进行排序以识别谣言。
2) DTC[1]:基于决策树模型,利用特征工程提取的推文统计特征得到识别谣言的决策树分类器[1]。
3) BU-RvN[10]:基于从叶子到根节点的传播树遍历方向的递归神经网络,捕获扩散线索和内容语义。
4) TD-RvNN[10]:基于从根节点到叶子节点的传播树遍历方向的递归神经网络,捕获传播线索和内容语义。
5) PPC[15]:由递归和卷积网络组成的传播路径分类器建模用户特征序列。
6) GLAN[9]:构建整体−局部的注意力网络捕获源帖及相关帖子传播结构的局部语义关联和全局结构关联。
7) HGAN[17]:通过构建异构图注意网络框架,捕获源帖及相关帖子在传播结构中的全局语义关联和结构关联。
-
本文所研究的谣言检测问题本质上是二分类问题,本文选用基于分类的评价指标进行谣言检测性能评测。针对本文选用的数据集,采用各类别判断的准确率(accuracy, Acc)和各类别的F1值来评估模型的性能,计算方式为:
式中,TP(true positive)表示真实类别为正例,预测类别也为正例的数量;FP(false positive)表示真实类别为负例,预测类别为正例的数量;FN (false negative)表示真实类别为正例,预测类别为负例的数量;TN(true negative)表示真实类别为负例,预测类别为负例的数量。
-
实验基于PyTorch框架实现,使用Adam优化器,初始学习率为0.005,在模型训练过程中逐渐降低。根据验证集上的性能选择最佳参数设置,并在测试集中评估方法性能。初始化词向量设置为300维。模型训练的批量大小mini batch设置为32。
如表2和表3所示,本文方法在两个数据集上的性能优于其他所有基线。具体而言,本文方法在这两个数据集上分别实现了92.5%和93.6%的分辨率,比最佳基线分别提高了1.4%和1.2%。虽然只有一个百分点,但就数据呈指数级扩增的规模而言,一个百分点带来的效应也是不可低估的,这表明本文方法能够有效地捕获谣言文本内容的全局语义关系,有助于谣言检测。
此外,基于传统机器学习方法(DTR和DTC)的对比实验模型表现不佳,深度学习方法(如BU-RvNN、TD-RvNN、PCC和GLAN)比基于传统机器学习的方法有更好的性能,这表明深度学习方法更容易捕获有效的特征用于谣言检测。此外,GLAN在所有对比模型中表现最好,因为它捕捉到谣言传播源推文的局部语义和全局结构信息,而其他基线未能捕捉到这部分信息。
模型 Acc F1 NR FR TR UR DTR 0.49 0.501 0.331 0.364 0.473 DTC 0.454 0.733 0.355 0.317 0.415 BU-RvNN 0.708 0.695 0.728 0.759 0.653 TD-RvNN 0.723 0.682 0.758 0.821 0.654 PPC 0.842 0.818 0.875 0.811 0.790 GLAN 0.890 0.936 0.908 0.897 0.817 HGAN 0.911 0.953 0.929 0.905 0.854 本文 0.925 0.962 0.936 0.910 0.875 模型 Acc F1 NR FR TR UR DTR 0.414 0.394 0.273 0.630 0.344 DTC 0.465 0.643 0.393 0.419 0.403 BU-RvNN 0.718 0.723 0.712 0.779 0.659 TD-RvNN 0.737 0.662 0.743 0.835 0.708 PPC] 0.863 0.843 0.898 0.820 0.837 GLAN 0.902 0.921 0.869 0.847 0.968 HGAN 0.924 0.935 0.913 0.947 0.899 本文 0.936 0.945 0.918 0.952 0.975 -
本文提出了一种融合元路径学习和胶囊网络的社交媒体谣言检测方法(CNMLRD),利用胶囊网络矢量编码的优势特性,弥补由传统神经网络特性所导致的检测模型编码效率较低的缺陷;利用元路径学习的异构图分解方法,实现了对用户潜在社交关系以及图结构的全局语义信息挖掘,增强对检测模型的可解释性。实验表明,在同等数据集的情况下,该方法相比于其他方法,检测结果的精确度有所提升,这样的优势在数据集呈指数级增加的情况下更为凸显。未来研究将考虑加入视频、图像、声音等数据,利用多模态解决社交媒体谣言检测问题,并进一步提高方法的泛化性。
Rumor Detection Based on Meta-Path Learning and Capsule Network
doi: 10.12178/1001-0548.2021219
- Received Date: 2021-08-10
- Accepted Date: 2022-03-28
- Rev Recd Date: 2021-12-21
- Available Online: 2022-07-11
- Publish Date: 2022-07-09
-
Key words:
- CapsNet /
- data mining /
- Meta-path learning /
- rumor detection
Abstract: Aiming at taking the source Twitter texts as the research object, this paper deeply explores semantic information of Twitter body content and emphasizes structural features of heterogeneous rumor spreading social networks, so as to improve rumor detection effect. This paper combines one-hot encoding word embedding method and multi-head attention mechanism to extract primary semantic feature of source Twitter text content. Furthermore, the content-capsule module is constructed based on CapsNet to extract the deeper semantic features of text content, and the structure features of rumor propagation in social networks are extracted by combining with GCN-capsule module. In order to further enrich the input, two kinds of capsule vectors are fused with a dynamic routing mechanism. And then the classification results of source tweets are output,and source tweets rumors detection is finished. Experimental results show that the accuracy of the model proposed in this paper reaches 93.6%.
| Citation: | LIU Nan, ZHANG Fengli, WANG Ruijin, ZHANG Zhiyang, LAI Jinshan. Rumor Detection Based on Meta-Path Learning and Capsule Network[J]. Journal of University of Electronic Science and Technology of China, 2022, 51(4): 608-614. doi: 10.12178/1001-0548.2021219

|





















































































































 DownLoad:
DownLoad: