 ISSN
ISSN 




-
碳排放增加导致的全球变暖已成为制约人类社会可持续发展的主要障碍,全球已有超过40个国家和经济体正式宣布了碳中和目标[1]。中国提出2030年前实现碳达峰,2060年前实现碳中和。
对于移动通信行业来说,践行碳中和也已势在必行。移动通信行业在节能减排、绿色低碳发展方面进行了积极探索,一方面是为了彰显了通信行业的社会责任,另一方面是因为网络能耗支出在OPEX的占比不断提升。5G网络能效相比4G提升了10~20倍,但随着网络承载数据量的急剧增加,将导致5G通信设备总能耗增长,基站能耗成为运营商实现碳中和目标的重要挑战。大规模多输入多输出(massive multiple-input multiple-output,massive MIMO)是5G系统的标志性技术,该技术利用大规模天线有效提高空口容量和频谱利用率。随着未来5G Advanced和6G业务需求和性能要求的大幅提升,massive MIMO将向超大规模MIMO和超大孔径阵列(extremely large aperture array, ELAA)演进,需要支持更多的天线数和更复杂的算法,而基带算法复杂度一般随着天线数的平方至立方增长,因此基带计算能耗会成为持续提升网络能效的主要挑战之一[2-3]。
现有支持massive MIMO技术的底层硬件架构方案主要有两种,即专用计算架构和通用计算架构。专用计算架构以ASIC芯片为主,通过面向5G的定制化芯片持续提升性能和能效,是当前业界的主流方案。通用计算以CPU通用处理器为主,可利用FPGA或GPU进行基带硬件加速,是Open RAN的技术主张之一。当前专用计算架构的能效优于通用计算架构,通用计算在性能和能效上仍然有较大的挑战[4],但业界对未来不同基站架构的能效优劣和发展趋势仍存在争议:一种观点认为随着技术发展,未来两者的能效比差距会缩小甚至反转,另一种观点认为两者的能效比差距不变甚至拉大。随着基站计算复杂度的增加,不同计算架构对碳排放的影响将成为未来基站架构选择的关键因素,因此针对不同基站计算架构的能效比差值趋势做量化研究非常有必要。
当前已有文献研究某个5G空口算法在不同计算架构下的性能和能效,如文献[5] 提出了一种基于ASIC的专用FFT算法,证明基于ASIC实现FFT相对通用CPU有超过180倍的能效提升。文献[6] 从功能可重构角度,提出基于FPGA硬件加速实现massive MIMO功能,但是没有给出量化能效分析。文献[7] 利用FPGA的多千兆收发器(multi gigabit transceivers, MGTs)来实现C-RAN集中信号处理,但只评估了FPGA硬件吞吐能力,没有分析如何将硬件能力转化为无线空口性能或能效的收益。综上,现有文献主要分析单点5G空口算法的计算性能,虽然能够定性体现出专用计算在能效上的优势,但由于缺少对基站基带全系统的计算需求和能效的量化建模,从现有文献的研究结果并不能得到不同计算架构的整体系统能效差异和演进趋势。
基于通信基站碳排放最小化的目标,本文通过计算需求建模、计算架构能效建模和量化功耗分析的研究方法,给出了不同基站计算架构的能效对比,并对基站计算能效的发展趋势进行量化研究。
-
本文以典型5G三扇区站点为例,包含1个BBU和3个AAU天线,5G典型的AAU天线为64 TRX,小区带宽为100 MHz。
从系统层面上典型的5G收发器由以下组件组成:L1/L2/L3数字信号处理、数字中频前端、模拟RF前端和天线。5G需要的基带处理技术非常复杂,基带运算有如下特征:1)计算密集型,massive MIMO天线所涉及的矩阵运算复杂度与天线数呈2~3次方关系;2)功能单一,基站工作在网络协议的底层,对所有的数据都按固定流程处理,只执行特定功能。
按3GPP协议定义,数据信道负责用户数据传输,并且占用了绝大多数的时频资源,在基带芯片中的大部分计算为数据信道服务。数据信道分为下行数据信道PDSCH和上行数据信道PUSCH,按协议定义,下行数据信道主要划分为LDPC编码、层映射、多天线权值映射、IFFT模块,上行数据信道主要划分为FFT、信道估计与测量、权值计算、MIMO均衡、LDPC译码模块。在整个基带处理部分,LDPC译码、MIMO均衡、权值计算和下行加权占用了整个芯片资源的80%以上,本文以这几项关键算法来代表整个基站数字信号处理,用以分析基站数字信号处理部分的功耗。
-
LDPC译码:在NR 协议中采用LDPC码作为上下行数据信道的编码方式,文献[8] 给出了LDPC译码复杂度,对数域译码只需要加法和比较,其加法次数为:
比较次数为:
考虑到加法器和比较器复杂度相近,这里统一为加法,则需加法器次数为:
式中,
$ {d}_{\mathrm{v},1} $ 为校验矩阵除了列重为1列的平均列重;$ {d}_{\mathrm{c}} $ 为校验矩阵的平均行重;$ M $ 为矩阵行数;$ {N}_{1} $ 为矩阵行数。NR协议的最小时域调度粒度为Slot,即一次调度数据需要占据同一个Slot的所有数据信道资源。由于协议的LDPC最大码长限制,1个Slot的传输数据可能不只1个LDPC编码块,需要有
$ {N}_{\mathrm{C}\mathrm{B}} $ 个LDPC编码块。同时,考虑到LDPC译码需要多次迭代才能有较好的性能,则1 s内LDPC译码所需要的加法次数为:式中,
$ {N}_{\mathrm{i}\mathrm{t}\mathrm{e}\mathrm{r}} $ 为LDPC译码迭代次数,典型取值为15;$ {N}_{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}} $ 为1秒内的Slot个数。按3GPP 38.212协议[9]定义,校验矩阵由
$ {\boldsymbol{H}}_{\mathrm{B}\mathrm{G}} $ 和$ \boldsymbol{Z} $ 矩阵决定,其中$ {\boldsymbol{H}}_{\mathrm{B}\mathrm{G}} $ 中的${\tilde{d}}_{\mathrm{v},1}=\dfrac{274}{26}$ ,${\tilde{d}}_{\mathrm{c}}=\dfrac{316}{46}$ ,$ {\tilde{N}}_{1}=26 $ ,$ \tilde{M}=46 $ ;$ {\boldsymbol{H}}_{\mathrm{B}\mathrm{G}} $ 中非0值由单位阵的置换矩阵$ \boldsymbol{Z} $ 替换,维度为$ {Z}_{\mathrm{c}} \times {Z}_{\mathrm{c}} $ ,协议规定$ {Z}_{\mathrm{c}} $ 取大取值为384(CB块长为8448 bits)。则校验矩阵的${d}_{\mathrm{v},1}=\dfrac{274}{26}$ ,${d}_{\mathrm{c}}=\dfrac{316}{46}$ ,$ {N}_{1}=26 \times 384 $ ,$ M=46 \times 384 $ 。从实际性能来看迭代次数一般在15次左右。MIMO均衡:MIMO均衡的经典算法为最小均方误差(minimum mean square error, MMSE)均衡算法,其表达式如下:
式中,
$ \boldsymbol{y} $ 为接收向量;$ {\boldsymbol{R}}_{\mathrm{u}\mathrm{u}}^{-1} $ 为干扰协方差矩阵;$ \boldsymbol{H} $ 为信道矩阵;$ \widehat{\boldsymbol{x}} $ 为发射向量的估计值。MMSE接收机可以用加法次数和乘法次数来表示[10] ,忽略低阶项后,其加法次数为$\dfrac{17}{3}{{N}_{\mathrm{U}\mathrm{E}}}^{3}+12{N}_{\mathrm{B}\mathrm{S}}{{N}_{\mathrm{U}\mathrm{E}}}^{2}$ ,乘法次数为${N}_{\mathrm{M}\mathrm{u}\mathrm{l}\mathrm{t}\mathrm{i},\mathrm{M}\mathrm{I}\mathrm{M}\mathrm{O}}=\dfrac{19}{3}{{N}_{\mathrm{U}\mathrm{E}}}^{3}+12{N}_{\mathrm{B}\mathrm{S}}{{N}_{\mathrm{U}\mathrm{E}}}^{2}$ 。其中,$ {N}_{\mathrm{U}\mathrm{E}} $ 为上行流数,$ {N}_{\mathrm{B}\mathrm{S}} $ 为基站天线数。NR的MIMO均衡是在RE粒度进行的,1 s内MIMO计算复杂度需要在单次MIMO均衡的基础上乘上1 s内上行数据信道和控制信道的RE个数。同时考虑上行多用户MIMO,虽然上行同时复用的流数最大为
$ {N}_{\mathrm{B}\mathrm{S}} $ ,但考虑连续组网对抗干扰,商用网络中的典型上行流数不会大于$ {N}_{\mathrm{B}\mathrm{S}}/2 $ ,即$ {N}_{\mathrm{U}\mathrm{E}} $ 取值为$ {N}_{\mathrm{B}\mathrm{S}}/2 $ 。则NR MIMO加法器次数可以表示为:NR乘法器次数可以表示为:
式中,
$ {N}_{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}} $ 为1秒内Slot个数;$ {N}_{\mathrm{R}\mathrm{B}}^{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}} $ 为1个Slot内的RB个数;$ {N}_{\mathrm{R}\mathrm{E}}^{\mathrm{R}\mathrm{B}} $ 为一个RB上的RE个数。SU权值计算:对于时分双工(time division duplexing, TDD)系统,下行信道信息利用信道的上下行互易性在基站侧获取,上行信道通过上行探测参考信号(sounding reference signal, SRS)获取。
对单用户权值,奇异值分解(singular value decomposition, SVD) 是有效的权值方案,可将 MIMO信道转化为无干扰的并行信道,以获取MIMO信道的复用收益[11] 。信道
$ \boldsymbol{H} $ 可SVD分解为:式中,酉矩阵
$ \boldsymbol{V} $ 中的前RANK个向量即为SVD权值。SVD权值可以采用幂法进行求取,其算法复杂度为
$ {n}_{\mathrm{P}\mathrm{M}}{{N}_{\mathrm{B}\mathrm{S}}}^{3} $ 次复数加法与$ {n}_{\mathrm{P}\mathrm{M}}{{N}_{\mathrm{B}\mathrm{S}}}^{3} $ 次复数乘法,其中$ {n}_{\mathrm{P}\mathrm{M}} $ 为幂法迭代次数,$ {N}_{\mathrm{B}\mathrm{S}} $ 为基站天线数[12] 。即所需要的实数乘法次数为$ 4{n}_{\mathrm{P}\mathrm{M}}{{N}_{\mathrm{B}\mathrm{S}}}^{3} $ ,实数加法次数为$ 4{n}_{\mathrm{P}\mathrm{M}}{{N}_{\mathrm{B}\mathrm{S}}}^{3} $ 。实际系统中幂法次数迭代次数$ {n}_{\mathrm{P}\mathrm{M}} $ 一般达到30次才能保证SVD分解精度。按NR协议SRS周期发送,1 s内SRS个数
$ {N}_{\mathrm{S}\mathrm{R}\mathrm{S}} $ 由SRS周期决定,最小5 ms周期。同时考虑到下行加权粒度最小为RB粒度,则权值计算也需要与之匹配。则NR SVD计算所需加法次数为$ 4{n}_{\mathrm{P}\mathrm{M}} \times {{N}_{\mathrm{B}\mathrm{S}}}^{3} {N}_{\mathrm{R}\mathrm{B}}^{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}}{N}_{\mathrm{S}\mathrm{R}\mathrm{S}} $ ,其乘法次数为:$ 4{n}_{\mathrm{P}\mathrm{M}} {{N}_{\mathrm{B}\mathrm{S}}}^{3}{N}_{\mathrm{R}\mathrm{B}}^{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}}{N}_{\mathrm{S}\mathrm{R}\mathrm{S}} $ 。对于MU(multi-user)-MIMO,迫零(Zero-forcing, ZF)权值是一种有效的下行多用户权值[13] :
借助SVD可以将MU权值计算简化,由下式可以将
$ \boldsymbol{W} $ 的计算简化为:即MU权值计算可以先由SVD得到
$ \boldsymbol{U} $ 、$ \boldsymbol{S} $ 、$ \boldsymbol{V} $ ,再由矩阵乘法得到$ \boldsymbol{W} $ 。考虑$ {\boldsymbol{S}}^{-1} $ 为实数对角阵,求取$ \boldsymbol{W} $ 所需SVD计算的复杂度与SU相同,所需矩阵乘法算法复杂度为$ {{N}_{\mathrm{B}\mathrm{S}}}^{3} $ 次复数乘法、$ {{N}_{\mathrm{B}\mathrm{S}}}^{2} \times \left({N}_{\mathrm{B}\mathrm{S}}-1\right) $ 次复数加法和$ 2{{N}_{\mathrm{B}\mathrm{S}}}^{2} $ 次实数乘法。因此,所需要的实数乘法次数为$ {4{N}_{\mathrm{B}\mathrm{S}}}^{3}+2{{N}_{\mathrm{B}\mathrm{S}}}^{2} $ 次实数乘法,$ {4{N}_{\mathrm{B}\mathrm{S}}}^{3}-2{{N}_{\mathrm{B}\mathrm{S}}}^{2} $ 次实数加法。由于NR每个Slot都可以调度不同用户,因此每个Slot都需要计算MU权值,同样考虑DRS粒度,MU权值粒度同样最小为RB级。则NR MU计算所需加法次数(忽略低阶项)为
$4\left({n}_{\mathrm{P}\mathrm{M}}+1\right) \times {N}_{\mathrm{B}\mathrm{S}}^{3}{N}_{\mathrm{R}\mathrm{B}}^{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}}{N}_{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}}$ ,其乘法次数为$4\left({n}_{\mathrm{P}\mathrm{M}}+1\right){N}_{\mathrm{B}\mathrm{S}}^{3} {N}_{\mathrm{R}\mathrm{B}}^{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}}{N}_{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}}$ 。结合SU和MU计算,权值计算所需要加法次数为:
乘法次数为:
下行加权计算:下行数据发射之前需要根据权值将数据流映射到天线,加权后数据
$\boldsymbol{x}$ 为:式中,
$ \boldsymbol{W} $ 为计算后权值;$ \boldsymbol{s} $ 为原始数据向量。下行加权的复杂度为
$ {{N}_{\mathrm{B}\mathrm{S}}}^{2}{N}_{\mathrm{R}\mathrm{A}\mathrm{N}\mathrm{K}} $ 次复数乘法、$ {N}_{\mathrm{B}\mathrm{S}}{N}_{\mathrm{R}\mathrm{A}\mathrm{N}\mathrm{K}}\left({N}_{\mathrm{B}\mathrm{S}}-1\right) $ 次复数加法。因此,所需要的实数乘法次数为$ 4{{N}_{\mathrm{B}\mathrm{S}}}^{2}{N}_{\mathrm{R}\mathrm{A}\mathrm{N}\mathrm{K}} $ 次实数乘法,${4{N}_{\mathrm{B}\mathrm{S}}}^{2}{N}_{\mathrm{R}\mathrm{A}\mathrm{N}\mathrm{K}}- 2{N}_{\mathrm{B}\mathrm{S}}{N}_{\mathrm{R}\mathrm{A}\mathrm{N}\mathrm{K}}$ 次实数加法。同样考虑下行多小区间干扰抑制能力,单小区有效流数$ {N}_{\mathrm{R}\mathrm{A}\mathrm{N}\mathrm{K}} $ 取值$ {N}_{\mathrm{B}\mathrm{S}}/2 $ 。忽略低阶项,则NR MIMO加法器次数可以表示为:
NR乘法器次数可以表示为:
考虑到LDPC译码、MIMO均衡、权值计算、下行加权占据了大部分基带算力,这里用这4项之和代表整个NR的基带算力需求,1 s内的总操作数
$ {N}_{\mathrm{O}\mathrm{p}\mathrm{e}\mathrm{r},\mathrm{N}\mathrm{R}} $ 为:式中,NR 1 s内总加法次数为:
1 s内总乘法次数为:
汇总LDPC译码、MIMO均衡、权值计算和下行加权计算计算复杂度,如表1所示。
功能 操作 1 s内操作数 备注 LDPC译码 加法次数 $(2{d}_{\mathrm{v},1}{N}_{1}+2{d}_{\mathrm{c} }{M}+{M}) \times $$ {N}_{\mathrm{i}\mathrm{t}\mathrm{e}\mathrm{r} }{N}_{\mathrm{C}\mathrm{B} }{N}_{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t} }$ $ {N}_{\mathrm{i}\mathrm{t}\mathrm{e}\mathrm{r}} $为LDPC迭代
次数;$ {N}_{\mathrm{C}\mathrm{B}} $是1个Slot内
LDPC CB块个数;$ {N}_{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}} $
为1秒内Slot个数。MIMO
均衡加法次数 $ \dfrac{89}{24}{{N}_{\mathrm{B}\mathrm{S}}}^{3}{N}_{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}}{N}_{\mathrm{R}\mathrm{B}}^{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}}{N}_{\mathrm{R}\mathrm{E}}^{\mathrm{R}\mathrm{B}} $ $ {N}_{\mathrm{B}\mathrm{S}} $为基站天线数;
$ {N}_{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}} $为1秒内Slot个数;
$ {N}_{\mathrm{R}\mathrm{B}}^{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}} $为1个Slot内的RB
个数;$ {N}_{\mathrm{R}\mathrm{E}}^{\mathrm{R}\mathrm{B}} $为一个RB上的RE个数。乘法次数 $ \dfrac{91}{24}{{N}_{\mathrm{B}\mathrm{S}}}^{3}{N}_{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}}{N}_{\mathrm{R}\mathrm{B}}^{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}}{N}_{\mathrm{R}\mathrm{E}}^{\mathrm{R}\mathrm{B}} $ 权值计算 加法次数 $ \left(4\left({n}_{\mathrm{P}\mathrm{M}}+1\right){N}_{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}} + $$ 4{n}_{\mathrm{P}\mathrm{M}}{\mathrm{N}}_{\mathrm{S}\mathrm{R}\mathrm{S}}\right){{N}_{\mathrm{B}\mathrm{S}}}^{3}{N}_{\mathrm{R}\mathrm{B}}^{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}} $ $ {N}_{\mathrm{R}\mathrm{B}}^{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}} $为1个Slot内的
RB个数;$ {N}_{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}} $为
1秒内Slot个数。乘法次数 $ \left(4\left({n}_{\mathrm{P}\mathrm{M}}+1\right){N}_{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}} + $$ 4{n}_{\mathrm{P}\mathrm{M}}{\mathrm{N}}_{\mathrm{S}\mathrm{R}\mathrm{S}}\right){{N}_{\mathrm{B}\mathrm{S}}}^{3}{N}_{\mathrm{R}\mathrm{B}} $ 下行加权 加法次数 $ {2{N}_{\mathrm{B}\mathrm{S}}}^{3}{N}_{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}}{N}_{\mathrm{R}\mathrm{B}}^{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}}{N}_{\mathrm{R}\mathrm{E}}^{\mathrm{R}\mathrm{B}} $ $ {N}_{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}} $为1秒内Slot个数;
$ {N}_{\mathrm{R}\mathrm{B}}^{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}} $为1个Slot内的RB
个数;$ {N}_{\mathrm{R}\mathrm{E}}^{\mathrm{R}\mathrm{B}} $为一个RB上的RE个数。乘法次数 $ {2{N}_{\mathrm{B}\mathrm{S}}}^{3}{N}_{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}}{N}_{\mathrm{R}\mathrm{B}}^{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}}{N}_{\mathrm{R}\mathrm{E}}^{\mathrm{R}\mathrm{B}} $ -
基站计算架构可以分为两种,以ASIC为主的专用计算和以通用处理器CPU为主的通用计算,当前主流方案是以ASIC为主的专用计算。Open RAN宣称采用通用计算技术,如乐天移动的Open RAN建网方案中,BBU硬件基于“Intel X86服务器+FPGA加速卡”。
在通用计算芯片领域,CPU、GPU、FPGA是3大主流技术。其中,CPU适用于处理逻辑复杂、重复性低的串行任务,如基站L3和核心网算法。GPU适合通用并行处理,适合大规模数据的并行加速处理。FPGA具备可重构特性,在无线通信的L1基带信号处理加速和数字中频信号处理中有一定应用。
不同计算架构的计算方案各不相同,其能效评估方法也存在差异。本节针对ASIC专用计算、CPU通用计算、以及CPU+FPGA加速的通用计算分别进行分析,建立能效评估模型。本文对不同架构选取当前主流工艺进行对比,ASIC选择7 nm FinFET工艺,CPU选择Intel 10 nm工艺,FPGA选择Xilinx UltraScale+ 系列16 nm工艺。
每秒浮点运算数(FLOPS)用于限定计算系统的性能,功率用于测量单位时间内消耗的电能。因此,能效可以通过性能和功率之间的比率来定义,即FLOPs/Watt,能效比ρ定义为:
式中,
$ {C}_{\mathrm{P}\mathrm{e}\mathrm{a}\mathrm{k}} $ 为1 s内可运行的操作数;$ P $ 为1 s内的能耗,即功率。 -
由于ASIC的定制化特点,完成一个具体功能的硬件功耗与设计强相关。考虑到本文旨在获取一个较为通用的评估模型,选取当前7 nm FinFET工艺ASIC的典型功耗作为参考,其16 bit加法器和乘法器的典型功耗分别为0.650 FJ和4.018 FJ[14] 。为了保证计算精度,基带计算单元中求逆、SVD等一般采用32 bit进行计算。相比16 bit计算,32 bit加法器复杂度为2倍,乘法器复杂度为4倍[9]。另外,考虑在基带ASIC里面除了负责计算的组合逻辑单元外,还有存储、接口等单元,组合逻辑的占比在20%~50%[14-16] 。取20%占比评估,则单个加法/乘法操作对应的整个芯片的消耗分别为6.5 fJ和80.36 fJ,对应能效比为
$ {\rho }_{\mathrm{A}\mathrm{d}\mathrm{d},\mathrm{A}\mathrm{S}\mathrm{I}\mathrm{C}}=154\;\mathrm{T}\mathrm{F}\mathrm{L}\mathrm{O}\mathrm{P}\mathrm{s}/\mathrm{W}\mathrm{a}\mathrm{t}\mathrm{t} $ ,$ {\rho }_{\mathrm{M}\mathrm{u}\mathrm{l},\mathrm{A}\mathrm{S}\mathrm{I}\mathrm{C}}=12.4\;\mathrm{T}\mathrm{F}\mathrm{L}\mathrm{O}\mathrm{P}\mathrm{s}/\mathrm{W}\mathrm{a}\mathrm{t}\mathrm{t} $ 。采用ASIC架构来实现NR基带,所需功耗(1 s内能耗)为:
代入式(17)、(18)并省略低阶项,可以进一步表示为:
式中,
${k}_{1}=\dfrac{89}{24}{N}_{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}}\beta {N}_{\mathrm{R}\mathrm{E}}^{\mathrm{R}\mathrm{B}}+4{n}_{\mathrm{P}\mathrm{M}}\beta \left({N}_{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}}+{N}_{\mathrm{S}\mathrm{R}\mathrm{S}}\right)+ 2{N}_{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}} \times \beta {N}_{\mathrm{R}\mathrm{E}}^{\mathrm{R}\mathrm{B}}$ ,$ \beta $ 为带宽$ {B}_{\mathrm{w}} $ 与有效RB数之间的折算系数;${k}_{2}=\dfrac{91}{24}{N}_{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}}\beta {N}_{\mathrm{R}\mathrm{E}}^{\mathrm{R}\mathrm{B}}+4{n}_{\mathrm{P}\mathrm{M}}\beta \left({N}_{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}}+{N}_{\mathrm{S}\mathrm{R}\mathrm{S}}\right)+2{N}_{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}}\beta {N}_{\mathrm{R}\mathrm{E}}^{\mathrm{R}\mathrm{B}}$ ;$ m=(2{d}_{\mathrm{v},1}{N}_{1}+2{d}_{\mathrm{c}}M+M){N}_{\mathrm{i}\mathrm{t}\mathrm{e}\mathrm{r}}\alpha {N}_{\mathrm{S}\mathrm{l}\mathrm{o}\mathrm{t}} $ ;$ \alpha $ 为天线数与带宽折算到CB个数的系数。 -
CPU的能效由功耗和峰值计算能力来评估,CPU能效比为:
式中,
$ {P}_{\mathrm{C}\mathrm{P}\mathrm{U}} $ 为CPU功耗;$ {C}_{\mathrm{P}\mathrm{e}\mathrm{a}\mathrm{k},\mathrm{C}\mathrm{P}\mathrm{U}} $ 为CPU的1 s内峰值算力。CPU理论峰值算力可以表示为:
式中,
$ {N}_{\mathrm{C}\mathrm{P}\mathrm{U}\_\mathrm{C}\mathrm{o}\mathrm{r}\mathrm{e}} $ 表示CPU的核数;$ {f}_{\mathrm{C}\mathrm{P}\mathrm{U}} $ 代表CPU单核的主频;$ {N}_{\mathrm{F}\mathrm{l}\mathrm{o}\mathrm{p}\mathrm{s}\_\mathrm{C}\mathrm{y}\mathrm{c}\mathrm{l}\mathrm{e}} $ 表示CPU在每个周期的浮点计算次数。而CPU单周期单精度浮点计算能力
$ {N}_{\mathrm{F}\mathrm{l}\mathrm{o}\mathrm{p}\mathrm{s}\_\mathrm{C}\mathrm{y}\mathrm{c}\mathrm{l}\mathrm{e}} $ 可以表示为:式中,
$ {N}_{\mathrm{F}\mathrm{M}\mathrm{A}} $ 代表每个CPU核中的乘加计算单元(fused multiply-add, FMA)个数;$ {N}_{\mathrm{B}\mathrm{i}\mathrm{t}\mathrm{s}} $ 代表FMA处理比特数;$ {N}_{\mathrm{W}\mathrm{i}\mathrm{d}\mathrm{t}\mathrm{h}} $ 代表操作系统位宽。以最新intel用于服务器的CPU Intel® Xeon® W-11865MLE为例[17] ,采用10 nm工艺,基本参数为8核,单核最大频率为4.5 GHz,功耗为25 W,支持最新的AVX512指令集,共有2个FMA。可得对于32位操作系统$ {N}_{\mathrm{F}\mathrm{l}\mathrm{o}\mathrm{p}\mathrm{s}\_\mathrm{C}\mathrm{y}\mathrm{c}\mathrm{l}\mathrm{e}} $ 为64 FLOPs,则Xeon W-11865MLE对应的理论峰值算力为2304 GFLOPs,对应能效比为$ {\rho }_{\mathrm{C}\mathrm{P}\mathrm{U}}=92.2\;\mathrm{G}\mathrm{F}\mathrm{L}\mathrm{O}\mathrm{P}\mathrm{s}/\mathrm{W}\mathrm{a}\mathrm{t}\mathrm{t} $ 。采用CPU来实现NR基带,所需功耗(1 s内能耗)为:
同样代入式(17)、(18)并省略低阶项,可以进一步表示为:
式中,
$ k={k}_{1}+{k}_{2} $ 。对于混合架构的单次操作功耗可以表示为:
式中,
$ {C}_{\mathrm{P}\mathrm{e}\mathrm{a}\mathrm{k},\mathrm{F}\mathrm{P}\mathrm{G}\mathrm{A}} $ 为FPGA的峰值计算能力。FPGA的算力分为两部分,一部分是逻辑单元的算力$ {C}_{\mathrm{P}\mathrm{e}\mathrm{a}\mathrm{k},\mathrm{L}\mathrm{o}\mathrm{g}\mathrm{i}\mathrm{c}} $ ,一部分是内置DSP的算力$ {C}_{\mathrm{P}\mathrm{e}\mathrm{a}\mathrm{k},\mathrm{D}\mathrm{S}\mathrm{P}} $ ,即:由于FPGA门与ASIC门存在一定转化关系,一个FPGA门等价为β个ASIC门,对于Xilinx而言,一个逻辑单元对应15个ASIC门,则逻辑单元的峰值算力可以表示为:
式中,
$ {N}_{\mathrm{G}\mathrm{a}\mathrm{t}\mathrm{e}}^{\mathrm{A}\mathrm{d}\mathrm{d}\mathrm{e}\mathrm{r}} $ 表示加法器需要的ASIC门数;一个32 bit TCS加法器对应160门[9] 。而DSP的峰值算力为:
式中,
$ {N}_{\mathrm{F}\mathrm{l}\mathrm{o}\mathrm{p}\mathrm{s}\_\mathrm{C}\mathrm{y}\mathrm{c}\mathrm{l}\mathrm{e},\mathrm{D}\mathrm{S}\mathrm{P}} $ 为一个时钟的操作数,由于DSP核一个时钟周期可以进行一次加法和一次乘法,$ {N}_{\mathrm{F}\mathrm{l}\mathrm{o}\mathrm{p}\mathrm{s}\_\mathrm{C}\mathrm{y}\mathrm{c}\mathrm{l}\mathrm{e},\mathrm{D}\mathrm{S}\mathrm{P}} $ 取值为2。FPGA+CPU架构选取Xilinx最新的UltraScale+系列FPGA和CPU Intel® Xeon® W-11865MLE组合。UltraScale+系列FPGA能效比为7系列的2.4倍,Xilinx的V7-690T包含了3600个DSP核和693120个逻辑单元,主频为250 MHz,功耗为30 W。根据式(28)~(30)可得1 s内峰值算力为18 TFLOPs,相同能耗下UltraScale+系列峰值算力为18 TFLOPs×2.4 = 43.2 TFLOPs。则UltraScale+ FPGA与W-11865MLE组合架构的能效比为
$ {\rho }_{\mathrm{M}\mathrm{i}\mathrm{x}}= 854\;\mathrm{G}\mathrm{F}\mathrm{L}\mathrm{O}\mathrm{P}\mathrm{s}/ \mathrm{W}\mathrm{a}\mathrm{t}\mathrm{t} $ 。FPGA与CPU混合架构在1 s内的功率消耗为:同样代入式(17)、(18)并省略低阶项,可以进一步表示为:
-
对基于64TRX的massive MIMO基站进行分析,设带宽为100 MHz、调制阶数为256QAM、码率为0.926、采用30 kHz子载波间隔,1 s内有2000个Slot,每个Slot有14个OFDM符号,每个OFDM符号有效子载波为3276个,SRS周期为5 ms,考虑小区间干扰上下行最大流数为收发天线数的一半。下面将基于上述参数和上一章的计算复杂度模型给出具体的基带计算复杂度。
根据上述参数可以计算出一个Slot最大的上行物理共享信道(physical uplink shared channel, PUSCH)传输量为10860596 bit,则最大可以有
$ ⌈\dfrac{10\;860\;596}{8\;448}⌉=1\;286 $ 个CB块。按式 (4) 计算出LDPC需要的加法次数为1.75×1013次。MIMO均衡为RE粒度的,基于式(6)、(7)可以计算出MIMO均衡需要的加法次数为8.92×1013次,乘法次数为9.12×1013次。
权值计算的计算次数由RB数、SRS周期等决定,根据式(11)、(12)计算得出权值计算所需要的加法次数和乘法次数皆为1.95×1013次。
下行加权是RE级的,按式(14)、(15)可以得出所需加法次数和乘法次数皆为4.81×1013次。
按本文分析,7 nm ASIC单个加法/乘法操作对应的整个芯片的消耗为6.5/80.36 fJ。Intel 10 nm CPU单次操作的功耗为10.85 pJ,UltraScale+ FPGA与W-11865MLE组合架构的单次操作对应功耗为1.17 pJ。则根据本文分析的基带计算复杂度,可以得出3种架构的不同功耗,如表2所示。
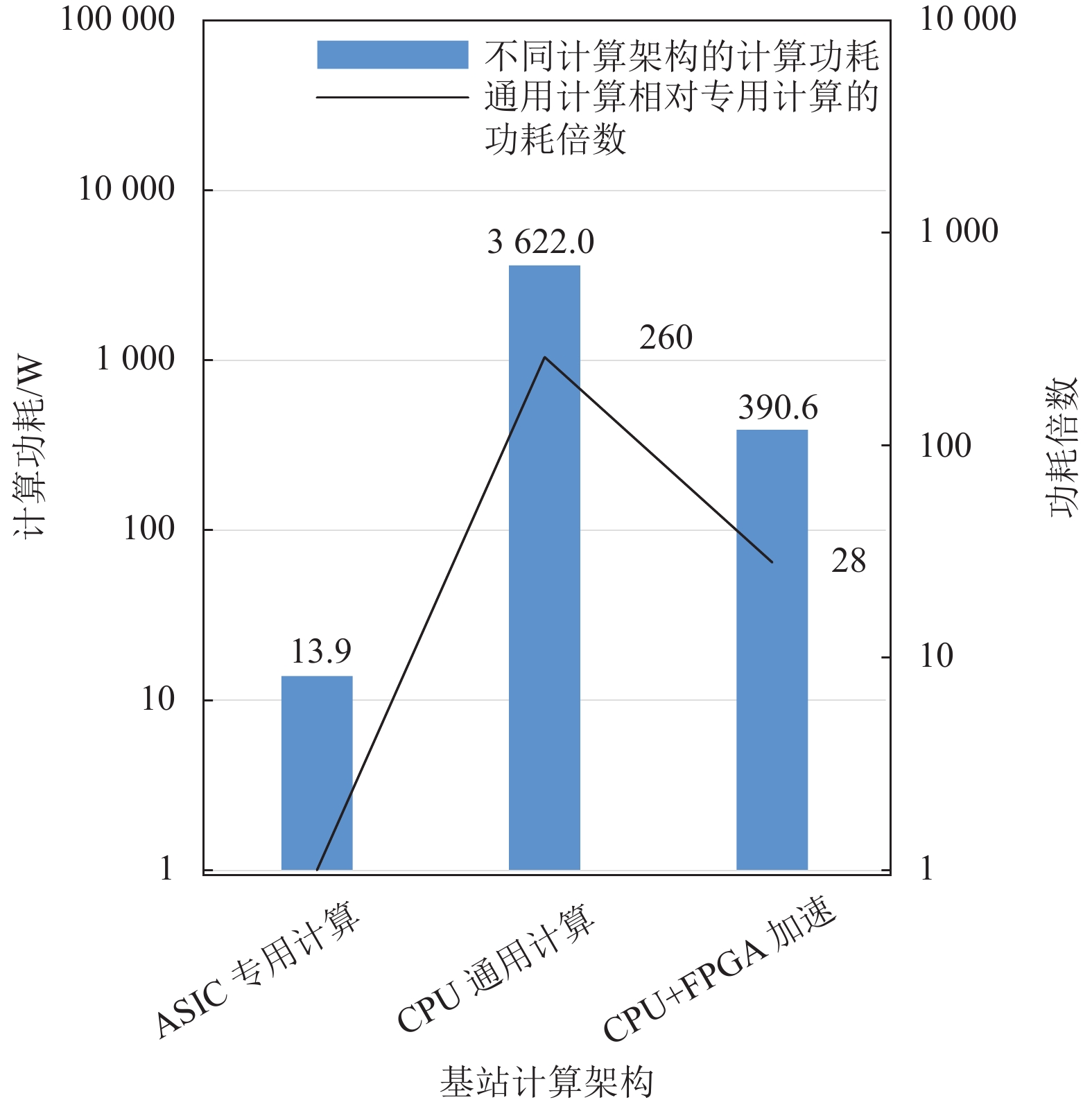
根据表2给出的不同架构的功耗,可以计算得出不同计算架构的功耗对比系数,如图3所示。
单小区 操作数/FLOPs 单位功耗 总功耗/W ASIC专用计算 加法 1.90×1014 6.5fJ 1.14 合计 13.92 乘法 1.59×1014 80.36fJ 12.78 CPU通用计算 3.48×1014 10.85pJ 3621.99 CPU+FPGA加速通用计算 3.48×1014 1.17pJ 390.57 从图1可以看出,相比ASIC专用计算,CPU通用计算和CPU+FPGA加速的基带整体功耗都有显著提高,其中CPU计算功耗提高260倍,CPU+FPGA加速架构功耗提高28倍。因此,移动通信基站以确定性的计算为主,以ASIC为主的专用计算在功耗上有明显优势。通过使用FPGA或CPU硬件加速,可以在一定程度上提升计算能效,但是相对ASIC专用计算的能效仍然有较大差距。
上述分析只考虑基带计算芯片的能效对比,不包含周边电路和器件,因此计算芯片的能效差异大于整体BBU的能效差异,但典型场景下计算芯片消耗大部分能耗,其占比通常超过50%,因此上述分析结果仅体现不同计算架构的计算能效差异。
基站是网络边缘节点,除了基站主设备的功耗,还包含很多站点配套设备,如电源、空调、监控等。站点配套设备的功耗跟基站主设备功耗强相关,如果基站主设备功耗增加,站点整体能耗将以相应的幅度增加。因此,如果BBU直接采用通用处理器的COTS服务器,成本、功耗、集成度都会与专用硬件BBU有巨大差异,导致更多的站点配套和更多的能源消耗及碳排放。
-
当前ASIC专用计算相对通用计算有明显能效优势,业界已有共识,但对不同计算架构能效的未来变化趋势仍存在争议,本节将通过建模来分析不同计算架构的能效差异的变化趋势。
随着massive MIMO的演进,包括ELAA、cell free massive MIMO等,未来通信系统将走向更大的频谱带宽和更多的天线数,从而带来基带计算需求的增加。另外考虑芯片工艺的进步,计算能效比会持续提升。由于下一代移动通信协议的不确定,这里按NR协议来分析带宽增加、天线数增加和能效比提升3个因素对未来移动通信架构功耗的影响。CPU通用计算相对ASIC专用计算的能耗差值
$ {P}_{\mathrm{t}\mathrm{r}\mathrm{e}\mathrm{n}\mathrm{d},\mathrm{C}\mathrm{P}\mathrm{U}} $ 可以表示为:CPU+FPGA加速架构相对ASIC专用计算的功耗差值
$ {P}_{\mathrm{t}\mathrm{r}\mathrm{e}\mathrm{n}\mathrm{d},\mathrm{M}\mathrm{i}\mathrm{x}} $ 可以表示为:式中,
$ {l}_{\mathrm{n}} $ 为未来芯片工艺进步带来的能效比提升,其取值分别为1.0 (64 TRX 100 MHz,对应2021年)、2.8 (128 TRX 400 MHz,对应2025年)和3.1 (256 TRX 800 MHz,对应2028年)[18] 。将小区带宽、基站天线数和能效比指标带入式(33)和式(34),可以分别得到不同massive MIMO天线数和不同小区带宽下通用计算相对专用计算的能耗差值。
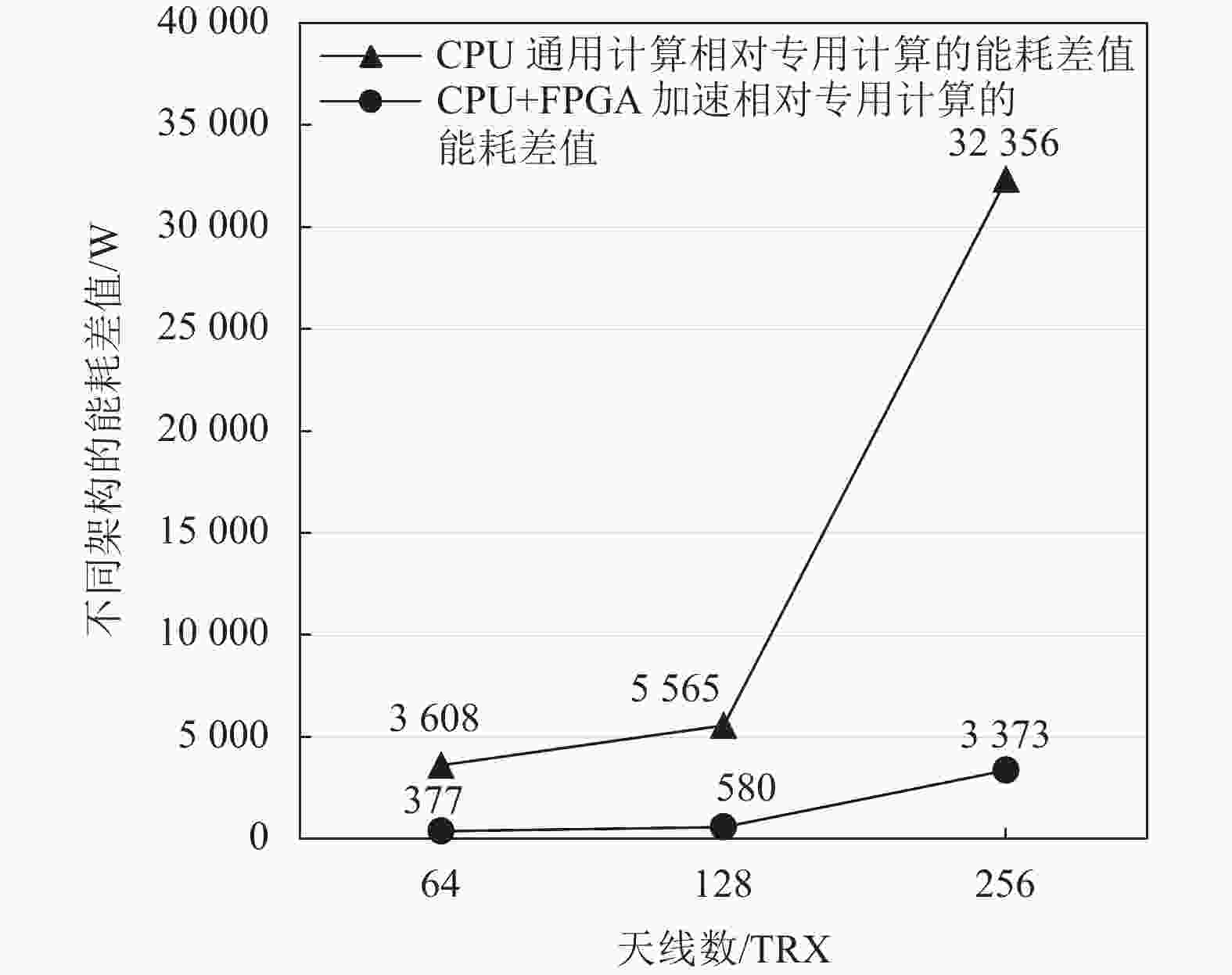
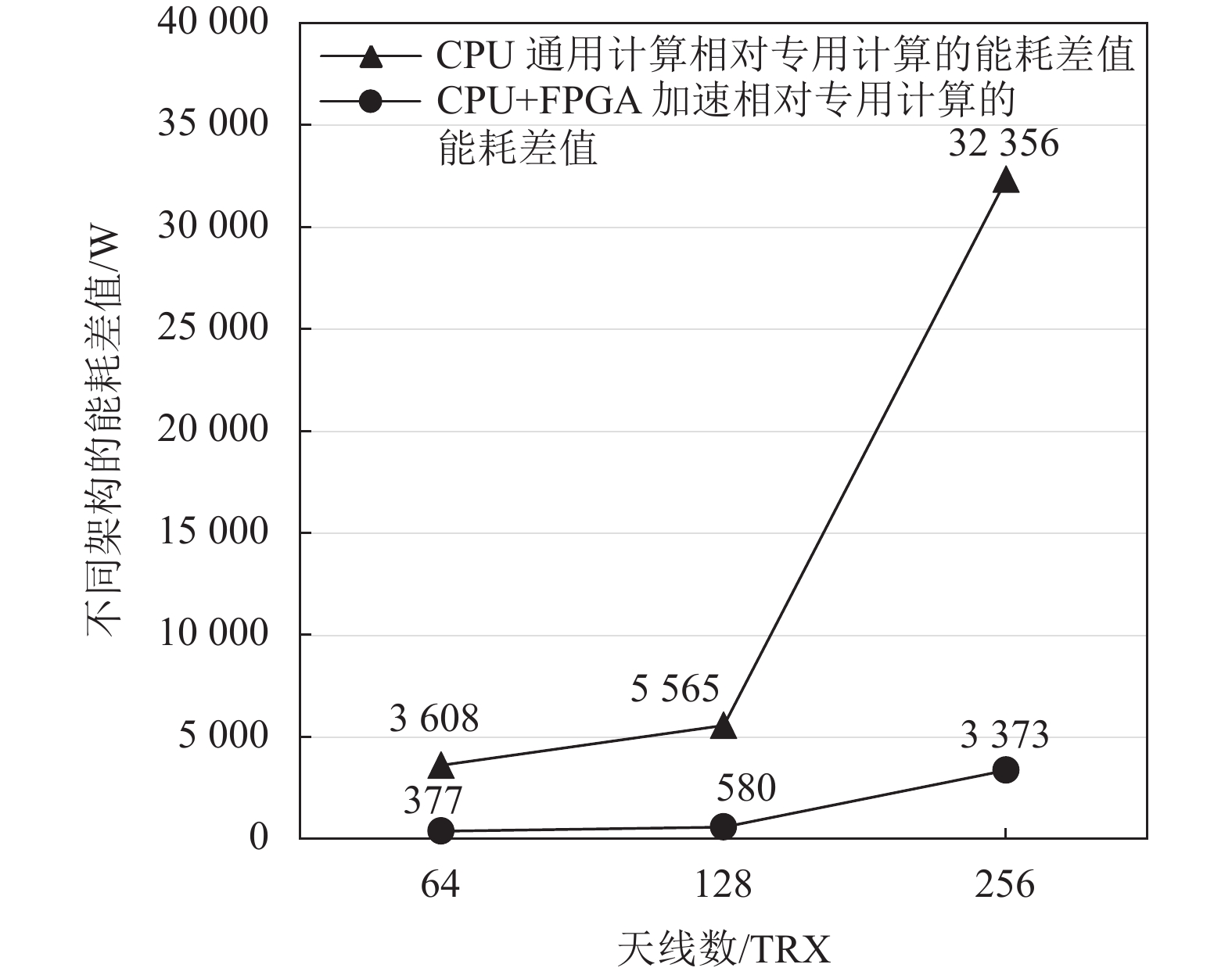
如图2所示,CPU通用计算相对专用计算的基带整体功耗差值随着天线数增加而大幅增加(假设带宽保持100 MHz不变),当天线数从64 TRX提升到256 TRX时,功耗差值从3608 W增加到32356 W(接近9倍)。CPU+FPGA计算架构相对专用计算的基带整体功耗差值也随天线数增加而大幅增加,当天线数从64 TRX提升到256 TRX时,功耗差值从377 W增加到3373 W(接近9倍)。
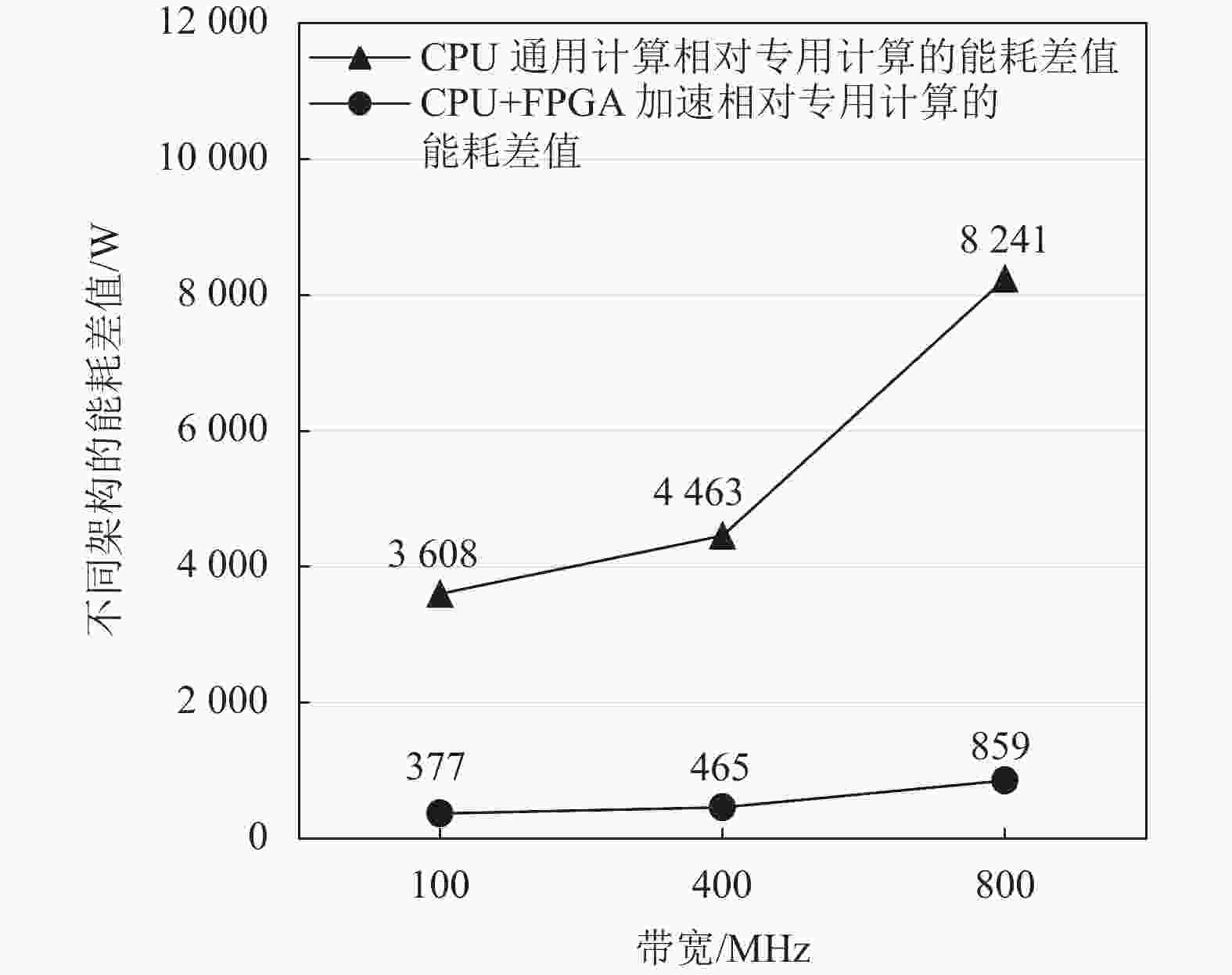
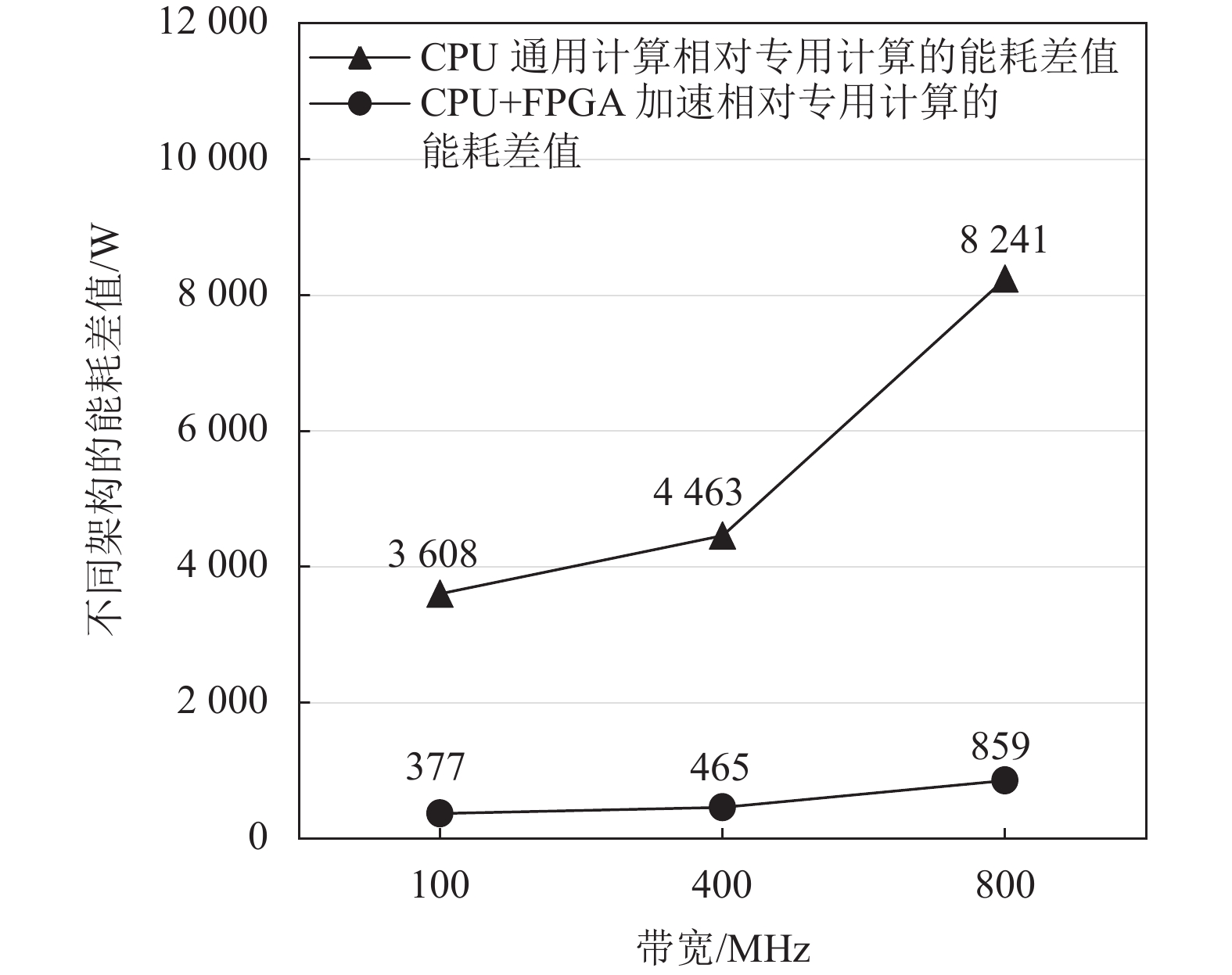
如图3所示,CPU通用计算相对专用计算的基带整体功耗差值随着带宽增加而明显增加(假设天线数保持64 TRX不变),当带宽从100 MHz提升到800 MHz时,功耗差值从3608 W增加到8241 W(大于2倍)。CPU+FPGA计算架构相对专用计算的基带整体功耗差值也随带宽增加而明显增加,当带宽从100 MHz提升到800 MHz时,功耗差值从377 W增加到859 W(大于2倍)。
上述模型中,假设了通用计算和专用计算随未来芯片工艺进步带来相同的能效比提升,采用了相同的
$ {{l}}_{{n}} $ 取值。如果考虑到专用计算架构可以充分发挥异构计算优势,通过专门的芯片设计进行优化,获得相对通用计算更大的能效比提升,将导致专用计算相对通用计算的优势会比本文结果更明显。 -
不同计算架构有各自适用的场景,针对计算需求相对确定的计算密集型应用场景采用专用ASIC芯片提升能效比,已经在深度神经网络、区块链等很多行业的实践中得到证明。
本文通过对massive MIMO基站计算需求建模,同时对不同计算架构的能效建模,给出了定量的分析结果。结果表明当前专用计算相对通用计算(有硬件加速)具有接近30倍的能效优势,而相对纯CPU通用计算架构有200倍以上的能效优势。随着未来基站天线数和小区带宽的增加,通用计算相对专用计算的功耗差值会进一步增加,两者的差距将越来越大,而不是越来越小。即使采用FPGA对通用计算做加速,相对专用计算的差距依然是越来越大。
因此,无论现在还是未来,massive MIMO基站采用通用计算相对专用计算,都不利于节能减排目标。Open RAN主张的基站软硬件解耦、通用计算取代专用计算,也不利于移动通信行业绿色低碳发展。从移动通信行业降低碳排放角度,更应该加大基站专用计算技术的投入。
Energy Efficiency Modeling of Massive MIMO Baseband Processing with Different Base Station Computing Architectures
doi: 10.12178/1001-0548.2021313
- Received Date: 2021-10-26
- Rev Recd Date: 2022-01-26
- Available Online: 2022-07-11
- Publish Date: 2022-07-09
-
Key words:
- dedicated computing /
- energy efficiency /
- general-purpose computing /
- massive MIMO /
- open RAN
Abstract: Massive multiple-input multiple-output (MIMO) is a key enabling technology for future 5G-Advanced/5G mobile networks to effectively increase spectrum utilization by using large-scale antennas. It is expected that with the evolution to 6G massive MIMO will support more antennas and more complex algorithms, and thus baseband energy efficiency (EE) will be one of the crucial challenges to improve network energy efficiency. In such a system, base station (BS) computing architectures consist of dedicated (ASIC) and general-purpose (CPU) computing architectures. It is very difficult to choose the optimal computing architecture due to the lack of quantitative modeling of the computational requirements and EE of the baseband. Hence, it is necessary to study the power consumption model of different computing architectures related to combined logic units and processing cycles. Based on the proposed power consumption model, the closed forms of EE equations are derived with unit floating point operations per-second per-Watt. Numerical results show that the current EE of dedicated computing is 30 times and 200 times higher than that of the general-purpose computing (with hardware acceleration) and CPU general-purpose computing architecture respectively.
| Citation: | DENG Ailin, FENG Gang, LIU Mengjie. Energy Efficiency Modeling of Massive MIMO Baseband Processing with Different Base Station Computing Architectures[J]. Journal of University of Electronic Science and Technology of China, 2022, 51(4): 514-521. doi: 10.12178/1001-0548.2021313

|












































































































 DownLoad:
DownLoad: