 ISSN
ISSN 




-
在图像的各种任务中,图像聚类[1-2]将相似图像聚在一个类,将不相似图像分开。而图像分类[3]则需判断图像属于某个类别,在图像分析任务中扮演着重要角色。近年来,随着智能手机等可手持摄像设备的普及,图像数据大幅提高。在图像的分类方法中,深度神经网络扮演着重要的角色[4-5]。但随着图像的分辨率及内容复杂度急剧增加,好的神经网络往往需要复杂的结构以及大量带标签的图像才能训练。
针对有效神经网络结构复杂等问题,提出了大量优秀的图像分类网络,如AlexNet[6]、InceptionV3[7]等。现有的分类任务均使用这些成熟的分类网络初始化自身网络[8-9]。一般情况下,在使用已有网络参数进行模型初始化后,会添加针对于任务本身的网络结构并依据任务目标进行参数优化,如文献[10]结合了无监督深度卷积生成对抗网络表示学习算法(unsupervised representation learning with deep convolutional generative adversarial networks, DC-GAN)[11]和Resnet[12]完成图像分类;文献[13]则对MobileNet[14]进行改进,将标准卷积形式替换为深度可分离卷积进行图像分类。对于有监督的数据,标签信息可以指导参数的准确优化,而在一些真实场景中,存在标签不足、准确标记困难等问题,使获得具有良好标记训练集的代价很大。但对于无标签的复杂图像,因为缺乏强有力的模型目标,往往难以达到预期效果。
为了解决这些问题,无监督领域适应(unsupervised domain adaptation, UDA)应运而生。它的目的是将源域的带标签数据中的知识转移到无标签的目标域上,以提高目标域样本的分类预测性能。现有的无监督域适应算法主要分为两类:1) 使用深度神经网络和域之间的距离函数作为损失函数优化网络,这类方法难以找到合适的域间距离衡量标准,以及受源域样本量影响,导致模型欠拟合,如文献[15]用最大平均差异(maximum mean discrepancy, MMD)[16]来计算域间的差异;2) 基于生成对抗网络的UDA方法,无监督像素域适应方法(unsupervised pixel-level domain adaptation, PixelDA)[17]使用生成器生成“假”(fake)样本,并使用判别器来区分这些生成的实例是否来自目标域的样本。耦合生成对抗网络(coupled generative adversarial networks, Co-GAN)[18]使用一对生成器,前几层通过权重共享约束促使来自不同域的实例样本提取相同的语义,并在生成器的最后几层中被分解为不同的低层细节。这类模型的缺陷在于GAN的不稳定性,利用GAN生成复杂图片需要大量的样本量以及精细的模型参数优化过程,严重影响聚类分类效率。
为此,本文提出了面向特征生成的无监督域适应算法Feature-GAN,结合DAN方法在特征层完成域适应,模型易训练,又结合GAN可用于特征生成,避免寻找特定域间距离衡量标准,解决了现有无监督域适应方法存在的问题。
-
文献[19]提出的生成对抗网络,是一个利用极小极大博弈来训练深度生成模型的框架。其目的是学习一个生成器网络G,从这个生成器中生成的样本分布
$ {P}_{G}\left(x\right) $ 与真实数据分布$ {P}_{{\rm{data}}}\left(x\right) $ 相匹配。训练中判别器网络D最大化生成分布和真实分布的距离,而G致力于生成最小化这个最大距离的数据。它们的最小最大化博弈表达式为:式(1)可优化为JS散度[19],JS散度衡量两个分布的相似度,通过生成器的优化,两个分布的JS散度降低了,即生成分布接近了真实分布。但当两个分布本来的重叠度很低时,JS散度将维持常数[20],目标函数的梯度为零,即对于接近最优的判别器来说,生成器很可能面临梯度消失的问题。本文根据图像分类任务的特点,即在特征空间上进行区分而不是原始数据上进行区分,提出特征生成网络(Feature-GAN),将低维高斯噪声
$ \boldsymbol{z} $ 加入较高维的带标签特征$ {\boldsymbol{f}}^{s} $ 后,一起输入生成器网络中,生成同一维度的特征而不是高维原始数据,判别器网络则区分真实特征分布和生成特征分布。 -
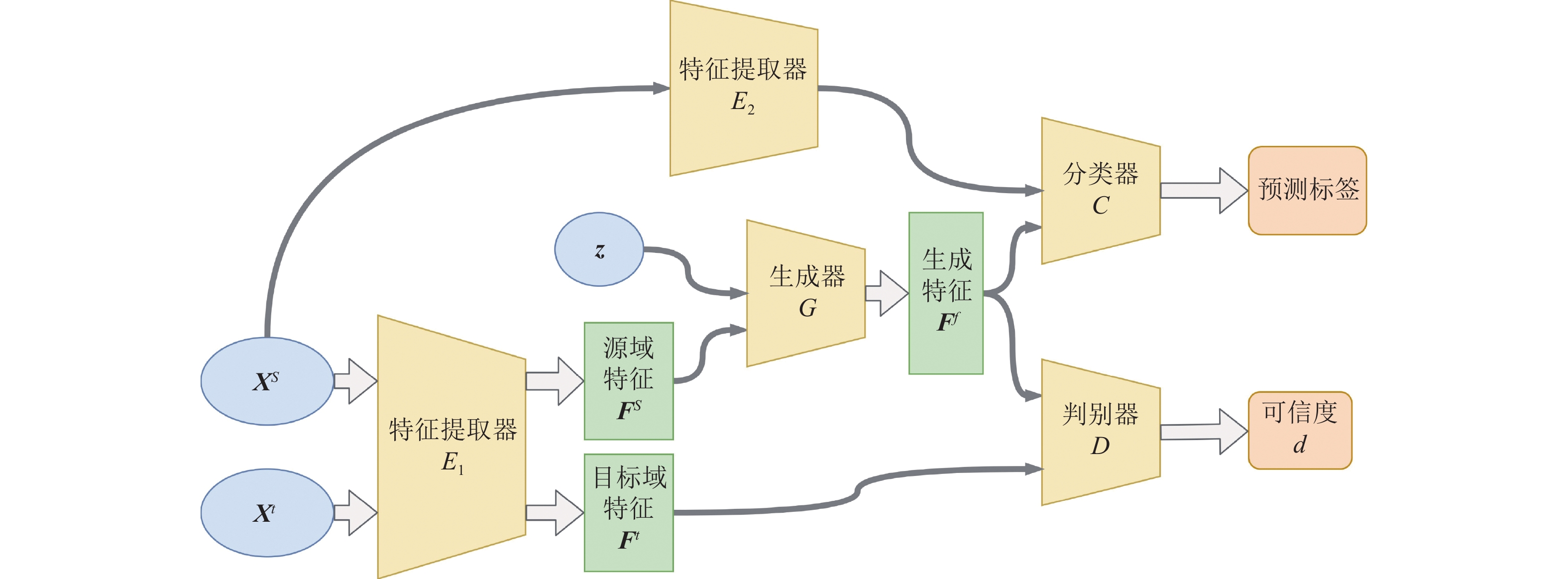
对于无监督领域适应问题,通常假设有一个具有
$ {{N}}^{{s}} $ 个带标签样本的源域,记为$ {\boldsymbol{X}}^{s}={\left\{{\boldsymbol{x}}_{i}^{s},{\boldsymbol{y}}_{i}^{s}\right\}}_{i=1}^{{N}^{s}} $ ,和一个具有$ {N}^{t} $ 个无标签样本的目标域,记为$ {\boldsymbol{X}}^{t}= {\left\{{\boldsymbol{x}}_{i}^{t}\right\}}_{i=1}^{{N}^{t}} $ 。任务目标是训练一个能同时在源域和目标域上都取得良好分类结果的分类器。模型由特征生成对抗网络和分类器构成,网络结构如图1所示。图1中,源域带标签的样本
$ {\boldsymbol{X}}^{\boldsymbol{s}} $ 和目标域不带标签的样本$ {\boldsymbol{X}}^{t} $ 由同一个特征提取器$ {{E}}_{1} $ 提取出特征后,源域特征$ {\boldsymbol{F}}^{s} $ 加入高斯噪声$ \boldsymbol{z} $ 经生成器$ {G} $ 映射成符合目标域分布的生成特征$ {\boldsymbol{F}}^{f} $ ,同样的源域样本与不同的噪声可以生成不同的“假”特征,可解决源域样本不足的问题。判别器$ {D} $ 则对生成特征$ {\boldsymbol{F}}^{f} $ 和目标域特征$ {\boldsymbol{F}}^{t} $ 进行区分,经过生成器和判别器的对抗训练后就可以得到符合目标域分布的生成特征$ {\boldsymbol{F}}^{f} $ ,带标签的生成特征和通过另一个特征提取器$ {{E}}_{2} $ 提取的源域特征一起用于训练分类器$ {C} $ ,得到同时适合源域和目标域的分类器。该模型可以分为以下3部分。
1) 特征提取器:
$ E\left(\boldsymbol{x};{\theta }_{E}\right)\to \boldsymbol{f} $ ,模型中两个特征提取网络$ {{E}}_{1} $ 和$ {{E}}_{2} $ 参数分别为$ {\theta }_{{E}_{1}} $ 和$ {\theta }_{{E}_{2}} $ ,$ {E} $ 将源域和目标域的数据$ \boldsymbol{x} $ 映射成生成特征空间F上的向量$ \boldsymbol{f} $ ;2) 特征生成网络(Feature-GAN):生成器
$ G\left({\boldsymbol{f}}^{s},\boldsymbol{z};{\theta }_{G}\right)\to {\boldsymbol{f}}^{f} $ ,模型参数为$ {\theta }_{G} $ ,将来自源域特征空间的输入$ {\boldsymbol{f}}^{s} $ 加入高斯噪声$ \boldsymbol{z} $ 后映射成符合目标域特征分布的向量$ {\boldsymbol{f}}^{f} $ ;判别器$ D\left(\boldsymbol{f};{\theta }_{D}\right)\to d $ ,模型参数为$ {\theta }_{D} $ ,该函数输出给定输入特征$ \boldsymbol{f} $ 从目标域中采样的可能性$ d $ 。判别器试图区分生成器产生的“假”特征$ {\boldsymbol{f}}^{f} $ 和来自目标域的“真”特征$ {\boldsymbol{f}}^{t} $ ;3) 特征分类器:
$C\left(\boldsymbol{f};{\theta }_{C}\right)\to \hat{\boldsymbol{y}}$ ,模型参数为$ {\theta }_{C} $ ,训练阶段使用源域数据和生成特征训练$ {C} $ ,测试阶段分类器$ {C} $ 用于预测目标域数据的类别。
本文模型中生成阶段和分类阶段使用了不同的特征提取网络
$ {{E}}_{1} $ 和$ {{E}}_{2} $ 。在实际训练中,$ {{E}}_{1} $ 和$ {{E}}_{2} $ 会与特征生成网络、特征分类网络一起训练,因此使用不同的特征提取器可以提取分别适合特征生成对抗网络和特征分类的特征。在本文使用的两个特征提取网络中,源域和目标域共享一个特征提取网络$ {{E}}_{1} $ ,提取的特征输入到特征生成对抗网络。另一个特征提取网络$ {{E}}_{2} $ 提取适合分类器训练的源域特征。模型的目标函数如下:
式中,
$ {\mathcal{L}}_{d} $ 为生成对抗损失,由式(3)定义;$ {\mathcal{L}}_{c} $ 为分类任务的损失,采用交叉熵损失定义;超参数$ \alpha $ 控制他们之间的大小关系,有:值得注意的是,分类器的交叉熵损失的计算同时考虑了源域特征和生成的“假”特征,比起只用生成的“假”特征训练分类器,源域特征的加入可以加快生成器的训练并保证“假”特征的类间距离。
将特征提取器加入损失函数后,模型的目标函数变为:
随后使用梯度下降法更新模型网络参数。
Feature-GAN模型训练算法如下。
Input:源域数据集
$ {\boldsymbol{X}}^{s}={\left\{{\boldsymbol{x}}_{i}^{s},{\boldsymbol{y}}_{i}^{s}\right\}}_{i=1}^{{N}^{s}} $ ,目标域数据集$ {\boldsymbol{X}}^{t}={\left\{{\boldsymbol{x}}_{i}^{t}\right\}}_{i=1}^{{N}^{t}} $ ,迭代次数$ {\rm{epoc}}\mathrm{hs} $ ,学习率$ \lambda $ ,平衡系数$ \alpha $ Output:Feature-GAN模型
初始化网络参数
from 1 to
$ {\rm{epochs}} $ do:${\boldsymbol{f}}^{s} =$ ${E}_{1}({\boldsymbol{x}}^{s};{\theta }_{{E}_{1}})$ 从高斯分布中采样噪声样本
$ \boldsymbol{z} $ ${\boldsymbol{f}}^{f} =$ $G({\boldsymbol{f}}^{s},\boldsymbol{z};{\theta }_{G})$ ${d}^{f}=D({\boldsymbol{f}}^{f};{\theta }_{D})$ 和${d}^{t}=D({\boldsymbol{f}}^{t};{\theta }_{D})$ 根据式(6)计算判别器损失
$ {\mathcal{L}}_{d} $ ${\boldsymbol{f}}_{\boldsymbol{c}}^{s}= $ ${E}_{2}({\boldsymbol{x}}^{s};{\theta }_{{E}_{2}})$ ${\hat{\boldsymbol{y}}}^{f}=C({\boldsymbol{f}}^{f};{\theta }_{C})$ 和${\hat{\boldsymbol{y}}}^{s}=D({\boldsymbol{f}}^{s};{\theta }_{D})$ 根据式(7)计算分类器损失
$ {\mathcal{L}}_{C} $ 使用梯度下降法反向传播梯度
end from
输出训练好的Feature-GAN模型
Feature-GAN模型训练好后,将待分类的目标域图像输入特征提取器E2后,再通过分类器C计算得到预测标签,即
${\hat{\boldsymbol{y}}}^{t}=C({E}_{2}({\boldsymbol{x}}^{t};{\theta }_{{E}_{2}});{\theta }_{C})$ 。 -
Office-31[21]是一个应用最为广泛的基于图片的领域适应的数据集。一共包含4 652张图片,分为31个类别。这些图片来自3个不同的领域,分别为 Amazon(A)、DSLR(D)和Webcam(W)。其图像均为办公室中的日常物品,分别为amazon网站上的商品展示图、数码单反相机拍摄的图片、经过webcam软件处理后的图像。由于Office-31的实例数较少,本文选取其中5个类(Keyboard, Laptop, Mouse, Printer和Scissors)做数据增强(即噪声添加、随机旋转和强化)以获得更多数据。每个领域都有500个样本,每个类提供100个样本,样本图片如图2所示。实验中将基于这3个领域的数据集设置6个迁移任务。

Office-Home[22]:原始的Office-Home数据集包含来自4个领域的65个类别共15500张图像,本文选用了其中3个领域:Clipart(C), Product(P), Real World(R)中数据量较多的7个类(Candles, Chair, Flowers, Keyboard, Monitor, Scissors, Speaker)。其图像均为日常生活物品,这3个域的图像分别为剪贴画、无背景的产品图像、用相机拍摄的常规图像,样本图片如图3所示。实验中将基于这3个领域的数据集设置6个迁移任务。
数据集设置如表1所示。

数据集 数据域 类别数 输入大小 Office-31 Amazon(A) 5 299*299 DSLR(D) Webcam(W) Office-Home Clipart(C) 7 299*299 Product(P) Real World(R) 现将Feature-GAN与以下5种算法进行比较。
1) InceptionV3[7]:使用源域数据训练的InceptionV3网络进行目标域数据分类,作为对比试验的基准数据。
2) 最大化类间差异无监督域适应算法(maximum classifier discrepancy for unsupervised domain adaptation, MCD)[23]:通过最大化生成器的分类差异,避免生成器在类边界生成模糊特征。
3) PixelDA[17]:像素级别领域适应算法,将源域图像和随机噪声输入进生成器以生成符合目标域图像分布的数据。
4) 基于伪标签选择结构预测的域适应算法(unsupervised domain adaptation via structured prediction based selective pseudo-labeling, SPL)[24]:采用在特征层面完成域适应的方法,其特征提取网络参数固定,不参与训练,且在目标域的分类过程中采用了自步技巧。
5) 无监督域适应性搭建域空间的桥梁(bridging domain spaces for unsupervised domain adaptation, FixBi)[25]:引入了一种基于固定比率的混合来增加源域和目标域之间的多个中间域,逐渐将知识从源域迁移到目标域。
-
本文实验中,MCD、SPL、FixBi均用原作者公开的代码,PixelDA采用github用户eriklindernoren复现的代码。为了公平比较,本文提出的Featrue-GAN模型中的两个特征提取网络和所有对比算法中的特征提取网络都采用InceptionV3[7]网络,其初始化参数采用ImageNet数据集上预训练的模型参数。所有实验均在同一环境下完成,计算机处理器的配置为Intel(R) Core(TM) i7-6800K CPU @ 3.40 GHz,内存 10 GB,GPU为 NVIDIA GeForce GTX 1080Ti 11 GB。在 Ubuntu 环境下配置 python 环境以及 pytorch 框架。所有实验均在 python 3.7,CUDA 9.0以及 pytorch 1.4 的框架下实现。
-
模型在Office-31和Office-Home两个数据集上的准确率测试结果分别如表2和表3所示,表格中每列的最优值加粗表示。从对比实验结果可以看出,Feature-GAN在绝大部分迁移任务上都取得了更好的结果。与InceptionV3实验的对比说明,迁移后的特征所训练的分类器极大地优于未迁移特征所训练的分类器。与PixelDA的对比结果说明,将生成器的任务由生成图像修改为生成特征所能带来的改善,提升率大多超过10%。与MCD和FixBi等最新域适应算法的对比也说明了Feature-GAN的有效性。与SPL算法比较时,在D→A,W→A等子实验中,由于数据集Amazon的噪声较大,而SPL算法使用了自步域适应算法,故其精度高于其他对比算法。
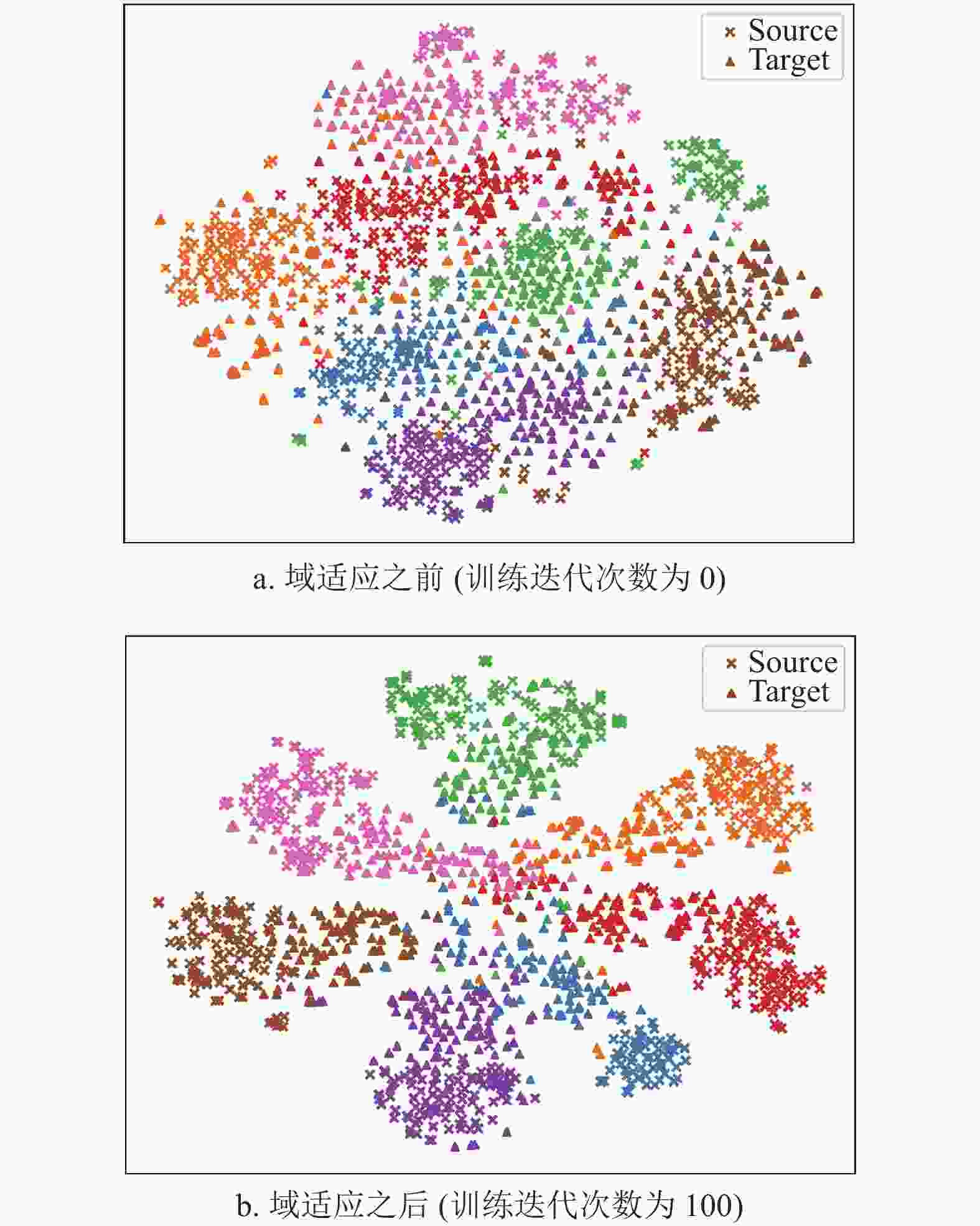
模型 A→D A→W D→A D→W W→A W→D Avg InceptionV3 77.08 78.33 71.25 94.38 73.33 93.33 81.28 MCD 93.00 73.80 81.40 95.00 81.80 98.40 87.23 PixelDA 88.20 86.00 81.20 96.00 70.40 98.60 86.73 SPL 70.32 84.65 95.60 82.76 94.36 85.73 85.58 FixBi 92.40 85.80 64.40 88.80 59.60 95.40 81.07 Feature-GAN 91.20 92.40 85.60 99.20 86.80 99.00 92.37 模型 C→P C→R P→C P→R R→C R→P Avg InceptionV3 80.03 86.24 70.76 85.89 75.58 87.83 81.06 MCD 78.32 88.85 76.32 90.07 77.34 86.27 82.86 PixelDA 76.75 84.32 71.49 84.84 78.07 86.73 80.37 SPL 76.20 76.68 80.75 96.83 83.28 75.29 81.51 FixBi 68.95 77.53 61.11 80.14 59.36 78.47 70.93 Feature-GAN 89.39 93.38 82.60 93.55 83.34 92.04 89.05 为了说明域适应过程使得目标域和源域数据更好区分的结果,图4展示了在域适应之前和域适应之后源域及目标域的样本分布(通过t-SNE[26]进行特征可视化),可以看到在域适应完成以后,无论是源域还是目标域,不同类别的样本分界线更明显,源域与目标域同一类别之间的样本也趋于同一分布形态。
另外,Feature-GAN是面向特征层面的域适应模型,图5a展示了域适应操作的不同特征维数变化对模型的影响。在Office-Home数据集的实验证明了本文的模型对进行域适应的特征维数的鲁棒性。当特征维度在一个较大的范围内变化时,模型可保持较为平稳的分类精度。超参数
$ \alpha $ 对模型的影响在Office-31数据集上进行了对比实验,结果如图5b所示,平衡系数$ \alpha $ 的取值对模型准确率的影响较小,进一步验证了本文模型训练的稳定性。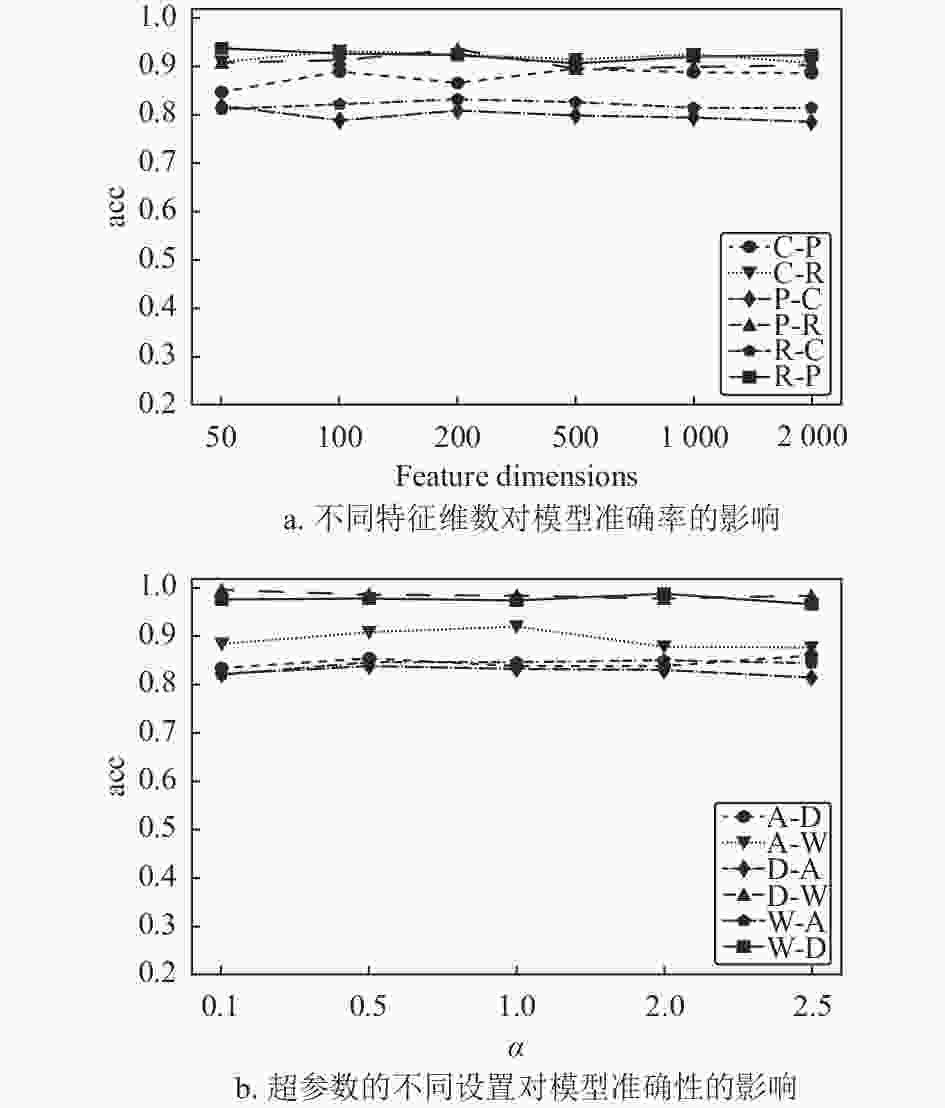
-
本文提出了图像特征层面的无监督域适应方法Feature-GAN,克服了传统域适应算法域间距离函数难以定义的问题,避免了基于样本生成的算法中训练慢、不稳定的问题。具体地,Feature-GAN通过使用源域图像的特征生成目标域图像的特征。生成的特征既拥有源域图像特征的标签,又拥有目标域的图像特征的分布。域适应过程和图像分类过程采用不同的特征提取器,避免域适应过程模糊特征类间差异。该方法参数量少,训练稳定。
Unsupervised Feature-Level Domain Adaptation with Generative Adversarial Networks
doi: 10.12178/1001-0548.2021314
- Received Date: 2021-10-26
- Rev Recd Date: 2021-12-25
- Available Online: 2022-07-11
- Publish Date: 2022-07-09
-
Key words:
- GAN /
- image classification /
- transfer learning /
- unsupervised domain adaptation
Abstract: For the classification problem of unlabeled high-dimensional images, the commonly used deep neutral networks have difficulty in producing good classification results in the unlabeled datasets. This paper proposes an unsupervised feature-level domain adaptation with generative adversarial networks (Feature-GAN), which learns the feature level transformation from one domain to another in unsupervised manner. It maps the source domain image features to the target domain image features and keeps the label information, and these generated labeled features can be used to train a classifier adapted to the target domain features. This model avoids the generation process of the image itself in the complex image domain adaptation problem and focuses on feature generation. The model is easy to train and has high stability. Experiments show that the proposed method can be widely applied to complex image classification scenarios, and it outperforms traditional sample generation-based unsupervised domain adaptation algorithms in terms of accuracy, convergence speed, and stability.
| Citation: | WU Zirui, YANG Zhimeng, PU Xiaorong, XU Jie, CAO Sheng, REN Yazhou. Unsupervised Feature-Level Domain Adaptation with Generative Adversarial Networks[J]. Journal of University of Electronic Science and Technology of China, 2022, 51(4): 580-585, 607. doi: 10.12178/1001-0548.2021314

|
















































































 DownLoad:
DownLoad: