 ISSN
ISSN 




-
随着公共安全体系建设的不断发展,监控摄像头被广泛应用在各种公共场合中,如商场、街道、银行等。由于监控视频内容庞大,人工进行异常事件检测会耗费大量的人力物力[1-4]。因此,如何建立一个高效的自动异常事件检测系统非常重要,这也是计算机视觉研究的一个重要方向。
异常事件检测大体可分为基于手工特征的方法和基于深度学习的方法,近年来基于深度学习的方法被广泛研究[1,5-10]。由于深度神经网络卓越的生成能力,基于重建和预测的异常事件检测方法被广泛地使用。文献[1]开创性地将U-net网络引入异常事件检测领域中,根据历史时刻的视频帧预测未来帧,并根据预测误差进行异常检测。文献[5]对U-Net网络进行改进,将其变化为一个双流网络,网络的两个流分别对视频帧进行重建和预测,并引入生成对抗的思想进行训练,以生成更加逼真的图像,最后根据重建误差进行异常判断。考虑到视频是由一系列关联性很强的图像组成,不少学者提出时间信息的概念,并将其用于视频异常事件检测中。文献[7]利用3D卷积提取输入视频片段中的空间特征和时间信息特征,并使用两个3D反卷积分别进行重建和预测。循环神经网络(recurrent neural network, RNN)及其变体由于其优秀的时间信息编码能力被用于异常事件检测中。文献[8]将LSTM网络与软硬注意力相结合提出行人轨迹预测网络,该网络不仅关注行人的历史轨迹,同时还关注该行人的邻域对其轨迹的影响。文献[9]将卷积自编码器与ConvLSTM相结合,利用卷积自编码器获取空间特征的变化,利用ConvLSTM记录特征随时间的变化,并将光流作为补充信息,从全局−局部的角度分析异常。此外,由于监控视频的视角大多是固定的,视频中可能会出现不同大小的物体,因此多尺度特征被引入到检测模型中。文献[10]提出一种双边多尺度聚合网络,该网络利用不同膨胀率的空洞卷积提取不同大小感受野的特征,利用ConvLSTM进行双边时间信息编码。
虽然视频异常检测已经取得了一些成就,但依然存在一些问题。如视频中物体大小的变化、复杂背景的影响以及不同场景下异常的定义不同等。为了解决以上问题,本文提出一种充分利用多尺度特征和时间−空间信息的异常事件检测方法。首先,利用经过预训练的VGG16网络提取特征,构建多尺度特征融合模块获取更多不同大小感受野的信息,以获得对输入视频帧的完备表示。其次,使用一种轻量化的通道注意力模块来强调视频中重要的前景信息,以减少背景信息对检测的影响。在此基础上,根据历史时刻特征预测当前时刻的特征,这将有助于弥补前文模块中对上下文信息和时间信息利用不足的缺陷。在训练阶段,最小化预测特征与真实特征之间的欧式距离使整个网络收敛。在测试阶段,本文认为仅包含正常事件的视频帧可以很好地预测,而包含异常事件的视频帧将会产生很大的预测误差。因此,在测试时将根据预测误差进行异常判断。在USCD Ped2和UMN两个基准数据集上进行了实验,实验结果表明了提出方法的有效性。
-
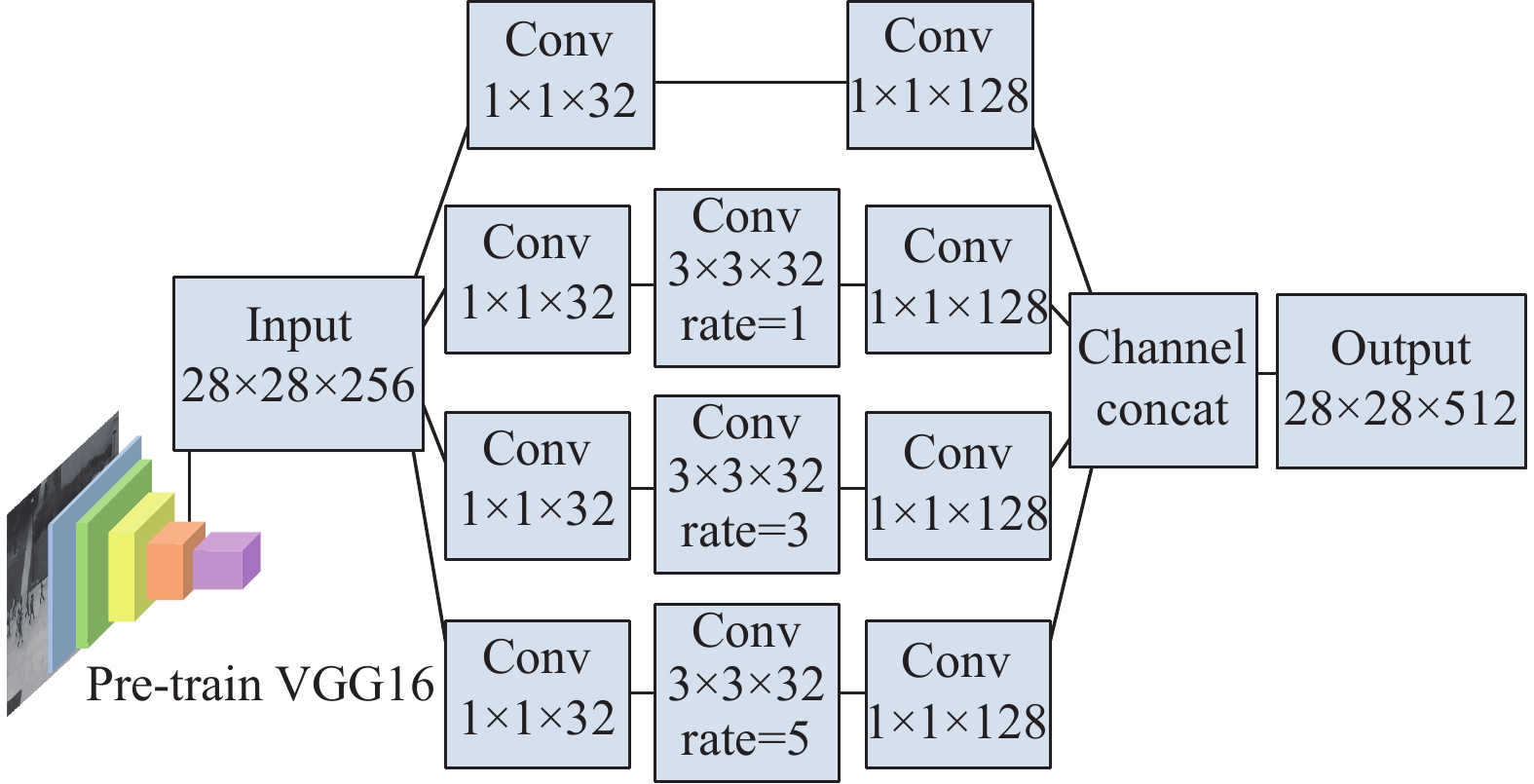
为了编码尽可能多的空间信息,使用空洞卷积网络构建一种多尺度特征融合模块,以获得包含输入视频帧的全局−局部信息的特征图。
由于视频帧中存在不同大小的对象,所以不同大小感受野的信息在异常事件检测中非常重要,而空洞卷积[11]可以通过调整膨胀率来获得不同大小感受野的特征语义,因此本文利用空洞卷积设计了一种具有多分支结构的多尺度特征融合模块,用于提取视频的多尺度特征,其结构如图1所示。输入的视频帧首先经过一个预训练的VGG16网络进行特征提取,取VGG16第三个池化层的输出作为多分支结构的输入。输入的特征图被送入4个不同的分支中进行处理。第一个分支用于保留原始特征信息,其余3个分支通过具有不同膨胀率的空洞卷积提取多尺度特征。第二、第三、第四分支的膨胀率分别为1、3、5,则其卷积核对应的感受野分别为
$ 3 \times 3 $ 、$ 7 \times 7 $ 、$ 11 \times 11 $ 。由于空洞卷积的存在,可以在不做池化损失信息的情况下,增大特征图的感受野,让卷积的输出包含较丰富的信息。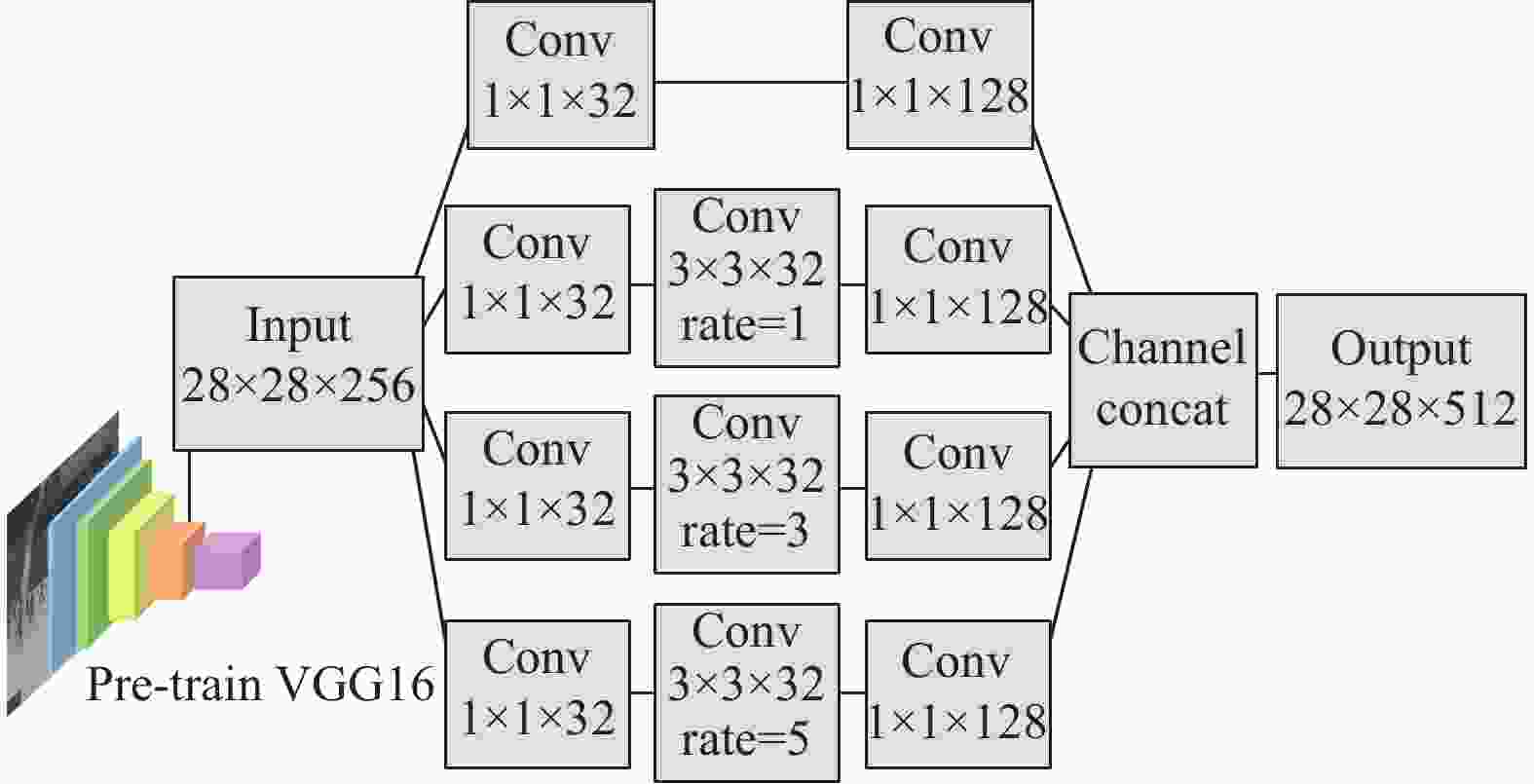
在4个分支中,小膨胀率的卷积核有利于提取视频帧中小物体的特征,而大膨胀率的卷积核有助于提取视频帧中大物体的特征。本文在空洞卷积的前后增加了1×1的卷积来调整特征图的通道数,以减少模型的参数量和运算量。最后,将4个分支的特征图在通道上进行拼接,获得一个包含全局−局部信息的特征表示
$ U $ 。 -
在视频异常事件检测中,监控摄像头通常是固定的,因此画面中可能存在大量静止的区域。异常事件通常发生在运动变化的前景物体上,因此希望网络能够重点关注运动变化的前景物体。在特征图中,不同的通道包含着不同的语义信息,有的通道包含着静止的背景信息,有的通道包含着变化的前景信息。为了减少背景信息对检测的影响,强调当前帧中重要的前景物体的信息,本文引入通道注意力机制。通道注意力通过计算各个通道中包含的信息以及通道之间的关系生成通道的权重,并将权重赋予其对应的通道。本文基于SENet设计了一种轻量化通道注意力模型,包含挤压、激活、重新分配权重3个步骤,其结构如图2所示。其中,挤压(squeeze)是通过在输入特征图的每个通道上执行全局平均池化得到特征图的全局压缩特征向量;激活(excitation)是通过两组1×1卷积、批正则化、激活函数获得输入特征图中每个通道的权值;重新分配权重操作(reassign weights)是将权值对输入的特征进行加权。
首先在挤压操作中,输入特征图
$ U $ 经过全局平均池化从$ H \times W $ 的大小池化成一个一维向量,该过程可表示为:式中,
$ {U}_{c}(i,j) $ 表示输入特征$ U $ 的第$ c $ 个通道$ (i,j) $ 位置上的空间信息;$ {F_{{\text{sq}}}}\left( {{{{U}}_c}} \right) $ 表示挤压操作;$ {z_c} $ 表示空间描述符。
挤压操作之后是激活操作,现有的通道注意力机制通常使用全连接层来计算通道之间的关系和权重,这无疑会增加运算的复杂度并且可能会导致过拟合。本文使用两个1×1的卷积来替换全连接层,以减少运算量。在每一个卷积层之后使用批正则化层进行正则化,以重新调整数据的分布,保证训练过程中梯度的有效性。在两个批正则化后面,分别使用ReLU和Hard-sigmoid函数作为激活函数。激活操作可表示为:
式中,
$ {\boldsymbol{z}} $ 表示经过挤压后得到的一维向量;$ {{\boldsymbol{W}}_1} $ 和$ {{\boldsymbol{W}}_2} $ 分别表示两个卷积层的权重;$ N $ 表示批正则化;$ \sigma $ 和$ \delta $ 分别表示hard-sigmoid激活函数和ReLU激活函数;$ {F_{{\text{ex}}}}({\boldsymbol{z}}) $ 表示激活操作;$ {\boldsymbol{S}} $ 表示通道注意力权值,为一维向量,维度等于输入特征图的通道数512。权值中某个维度的值越高,表明其对应的通道的重要性越高。最后,在重新分配权重中,将输入特征图
$ U $ 与通道权重相乘,强调输入特征图中重要的通道信息。重新调整通道权重:
式中,
$ {S_c} $ 表示第$ c $ 个通道的注意力权重;$ {U_c} $ 表示输入的第$ c $ 个通道的特征图;${F_{{\text{scale}}}}({{U}},{\boldsymbol{S}})$ 表示重新调整权重操作;$ {F_{{\text{att}}}} $ 表示进行注意力计算后的通道注意力特征图。 -
正常事件状态变化比较平稳,可以预测,而异常事件状态通常会出现突变,不可预测。因此可以通过比较某帧的预测特征和真实特征来判断事件是否异常。
监控视频是由一系列关联性很强的视频帧组成,为了充分利用视频帧之间的时间信息,本文构建了深度特征预测模块。该模块根据历史时刻的特征图预测当前时刻的特征图。将经过注意力模块后获得的连续5个历史时刻的特征图在通道上进行拼接,组成深度特征预测模块的输入
$ {X^t} $ 。由于输入的特征图通道数较高,因此本文设计了一个仅包含1×1卷积核、ReLU激活函数的特征预测模块,该模块由编码器、解码器组成,其具体结构如表1所示。Layer Filter/Stride Activation function Conv1 (1×1×512)/1 ReLU Conv2 (1×1×256)/1 ReLU Conv3 (1×1×128)/1 − Conv4 (1×1×256)/1 ReLU 在深度特征预测模块中,编码器计算不同时刻特征图之间的关系,并将其映射到一个低维空间中,解码器根据低维空间中的特征预测当前时刻的特征图。预测特征图与真实特征图之间的差异将被用于异常判断。
训练时,在仅包含正常数据样本的训练集中对网络进行训练,最小化预测特征与真实特征之间的欧式距离来对整个网络进行训练:
式中,
$ F_{{\text{Pred}}}^t $ 表示当前时刻预测特征图;$ {\phi ^t} $ 表示当前时刻VGG16第三个池化层输出特征图。在测试时,根据当前时刻VGG16提取的特征图与预测特征图之间的差异来进行异常判断,计算预测特征图与VGG16第三个池化层输出特征图之间的欧式距离,若误差大于设定的阈值
$ \alpha $ ,则说明输入的视频片段中存在异常。公式为:式中,
$ {s_t} $ 表示测试时当前时刻的异常得分。 -
UCSD数据集通过学校里固定在较高位置上俯瞰人行道的摄像机获得,本文仅使用Ped2进行实验。Ped2中含有骑自行车、滑旱冰、小汽车等异常事件,共有16个训练视频样本和12个测试视频样本。
UMN数据集包含3个不同的场景和11个视频片段,训练集包含3300帧,测试集包含4439帧。其异常事件主要包括人群单方面跑动、人群四散等。
-
使用的深度学习训练框架为Pytorch,所有的实验都基于NVIDIA RTX2080Ti。将输入的视频帧大小调整到224×224以满足vgg16的输入标准。训练时使用随机梯度下降法进行参数优化,学习率设置为1×10−4,并在训练100轮后将其降低至1×10−5。选取帧级别的ROC曲线及ROC曲线下面积AUC作为异常行为的评价指标,在该评估方法中,只要当前帧中存在异常特征,则立即判断该视频帧为异常帧。
-
为了证明多尺度特征融合的有效性,在基线网络U-Net[1]的瓶颈层中添加多尺度模块来进行消融实验。
实验中修改U-Net的输入为单个视频帧,输入视频帧经过一系列的卷积层进行特征提取,利用反卷积和跳转连接进行图像重建。计算重建图像与输入图像的欧式距离来判断输入视频帧是否存在异常。在评价指标上,对比了平均正常得分和平均异常得分之差
$ {\varDelta _s} $ ,$ {\varDelta _s} $ 的值越大,模型对正常事件和异常事件的区分能力越强,从而说明特征在异常事件检测中的可分性越好。实验结果如表2所示,与基线网络相比,使用多尺度特征融合后平均正常得分与平均异常得分的差值更大,这说明在U-Net的瓶颈层添加的多尺度模块编码了更多的空间特征,解码器可以利用更多的特征来对图像进行重建。因此添加了多尺度模块的基线网络可以获得更好的效果。方法 数据集 Ped2 UMN U-Net 0.435 0.362 U-Net with Multi-scale feature fusion module 0.468 0.395 -
为了证明所提出的通道注意力的有效性,本文在结合了多尺度特征的基线网络上进行通道注意力的实验。实验首先在基线网络U-Net上添加多尺度特征融合模块,其次在多尺度特征融合模块后面添加通道注意力进行对比实验。与前一节的实验评价方法一样,对比平均正常得分与平均异常得分之间的差值。
实验结果如表3所示。由实验结果可知,在不使用注意力的情况下,网络对特征图中的所有通道同等看待,容易受到浅层特征中噪声以及背景等因素的干扰,因此获得的检测效果较差。而在多尺度特征融合模块后面添加注意力机制后,正常得分与异常得分之间的差值变大,这表明通道注意力可以有效地减少背景冗余信息,增加运动变化的前景物体信息在特征图中的权重。此外,在SENet中使用多层感知机来计算不同通道间的关系来获取各个通道的权重,这不可避免地容易造成过拟合,使得检测效果下降,而本文利用两个1×1的卷积来替换多层感知机,并在其后面添加批正则化来保证训练过程中梯度的有效性,避免了过拟合的现象,同时减少了模型的参数量,因此获得的实验结果较好。
方法 数据集 Ped2 UMN Without channel-wise attention 0.468 0.395 With SENet 0.493 0.413 With proposed attention module 0.502 0.429 -
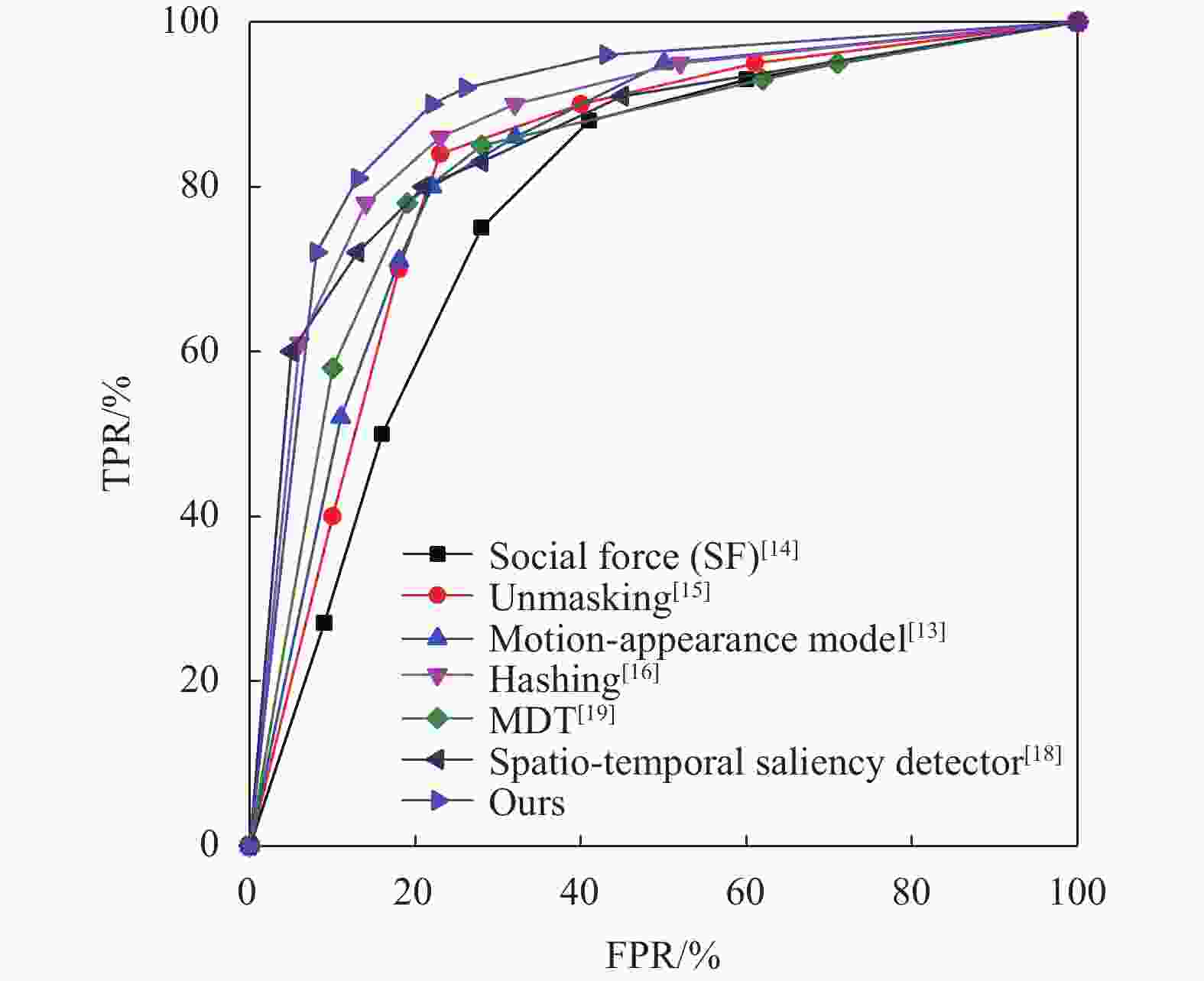
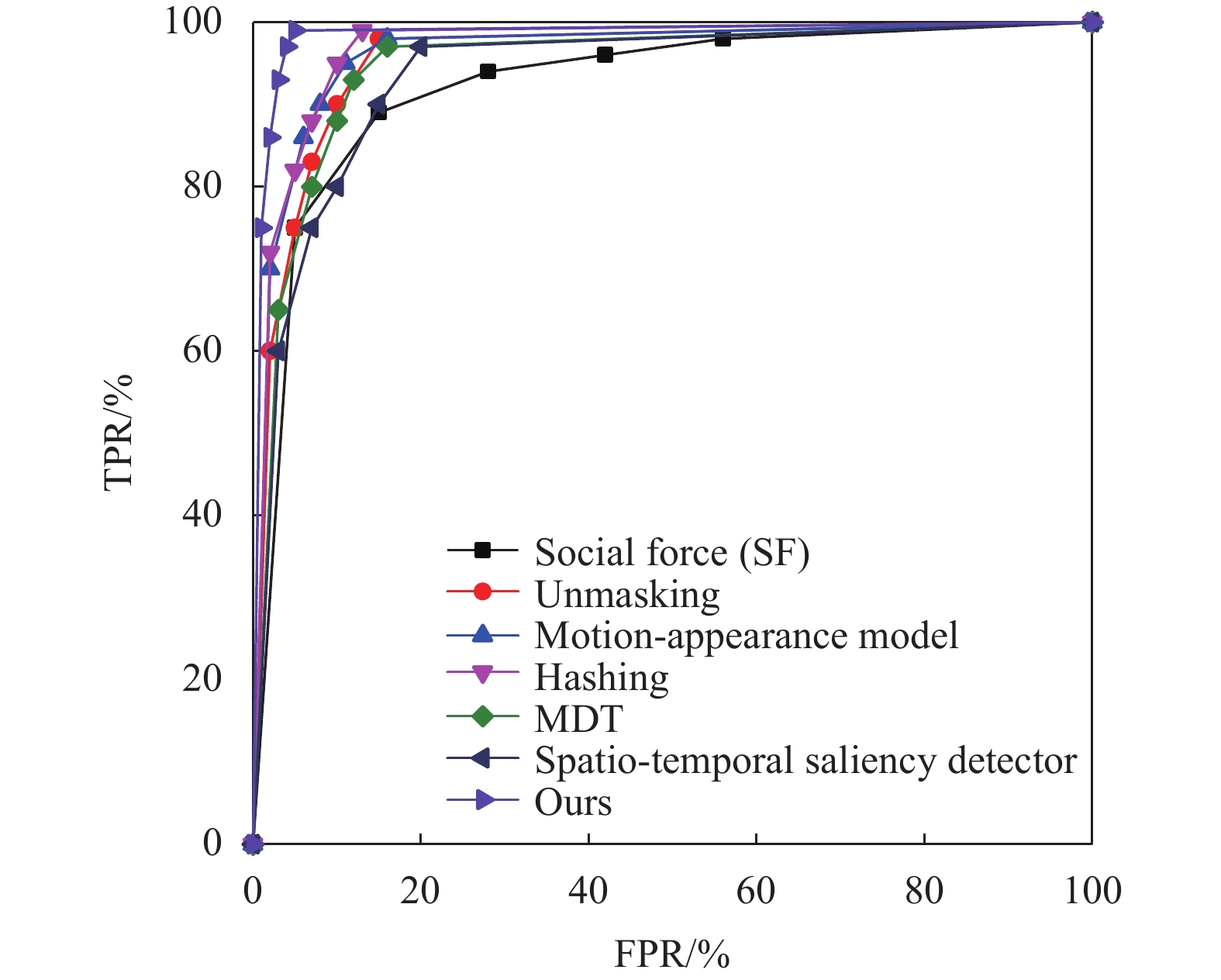
在帧级别的评估方法下,将提出的方法与已有方法在Ped2数据集上进行对比,其中包括基于手工特征的方法以及基于深度学习的方法[13-18]。在异常检测中,将异常判断的阈值设置为0.1、0.2、0.3、0.5、0.8,可以计算出5组不同的假阳率(false positive rate, FPR)和真阳率(true positive rate, TPR)。以FPR为横坐标,TPR为纵坐标,绘制出ROC曲线,ROC曲线下的面积即为AUC,面积越大,则检测的效果越好。
在Ped2数据集上的实验结果(ROC曲线)如图3所示,本文方法在帧级别下,获得了最好的效果。Social Fore[14] 仅使用了手工特征的方法,因此其得到的帧级别AUC仅为0.556。文献[13]将外观特征和运动特征结合起来,帧级别下AUC提升至0.850,但其遗漏了时间信息。其他方法如Unmasking[15]、Hashing[16]、spatiotemporal saliency detector[18]以及文献[19]使用使用MDT(mixtures of dynamic textures)方法在帧级别下AUC分别获得了0.822、0.910、0.877、0.875的检测效果。以上方法的数据均来自于文献原文。本文方法由于考虑了视频中全局−局部特征,并充分利用了时间信息,因此获得了更好的检测效果,帧级别下AUC达到了0.925。
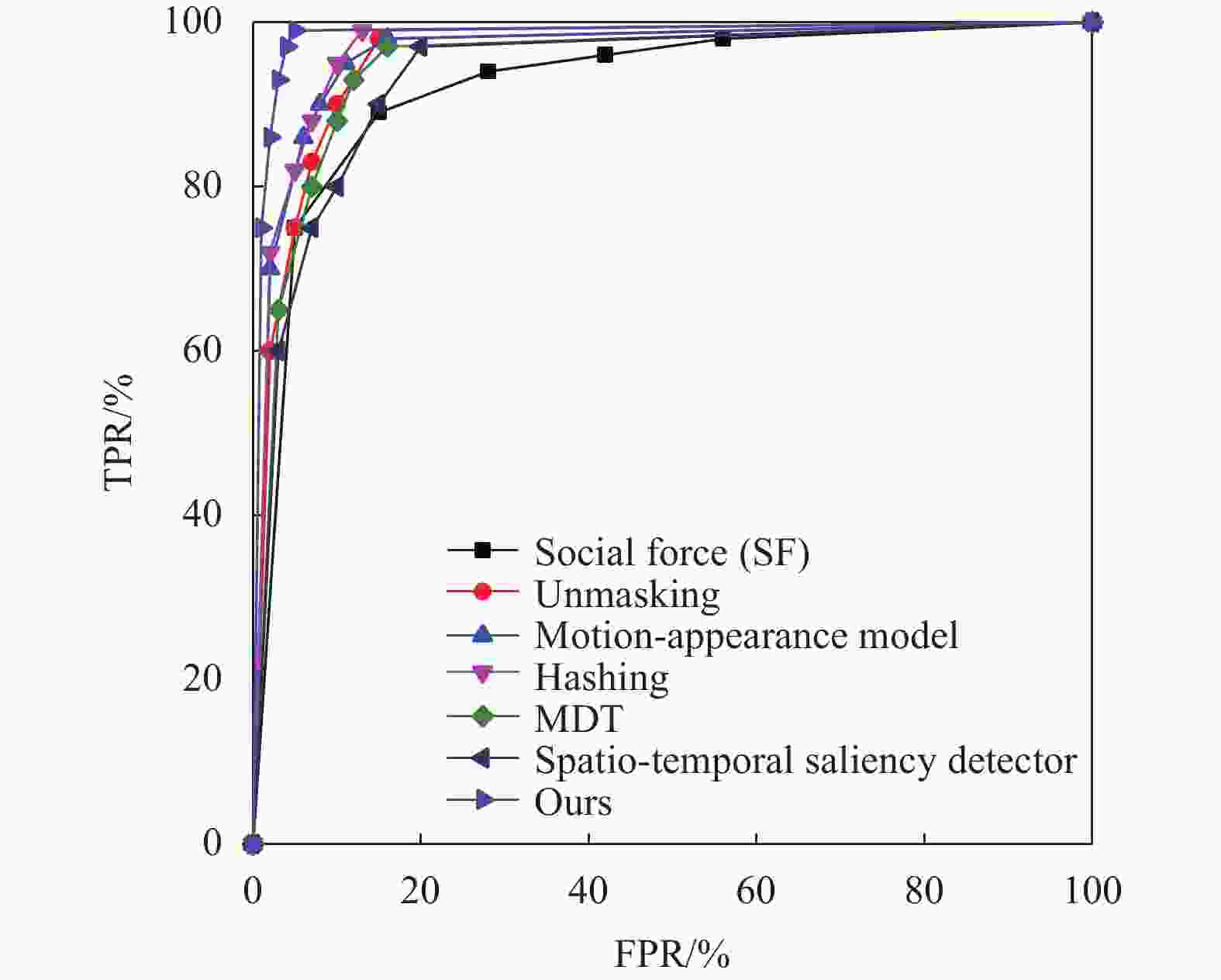
在UMN数据集上验证本文方法,并将所得的结果与上面的方法进行帧级别ROC比较,结果(ROC曲线)如图4所示。本文方法同样获得了最好的结果,帧级别AUC达到了0.991。基于手工特征的方法Social Fore[14] 获得的帧级别AUC为0.96,将外观特征与运动特征相结合的方法Motion-appearance model[13]获得的帧级别AUC为0.983;将Unmasking迁移至异常事件检测的方法[15]获得的帧级别AUC为0.951;基于Hashing filter[16]的方法,基于spatiotemporal saliency detector[18]的方法以及文献[19]的方法分别获得的帧级别AUC为0.987、0.938、0.961。
-
本文提出了一种充分利用视频中多尺度信息和时间信息的异常事件检测网络,该网络不仅关注视频中的全局−局部信息,还考虑了空间−时间信息。该网络利用空洞卷积获取多个不同大小的感受野的信息并进行融合以获得整个视频帧的全局−局部表示,并且引入一种轻量化通道注意力机制,通过计算特征图中不同通道所含信息的重要程度,提升重要通道的权重,抑制背景和噪声等干扰因素的影响。最后,为了充分利用时间信息,使用自编码器编码历史时刻的特征序列并预测当前时刻的特征,预测特征与真实特征之间的误差将被用于异常判断。在两个基准数据集上与几种方法进行了对比实验,实验结果证明了本文方法的有效性。
Abnormal Event Detection Based on Multi-Scale Features Prediction
doi: 10.12178/1001-0548.2021333
- Received Date: 2021-11-10
- Accepted Date: 2022-01-01
- Rev Recd Date: 2022-04-11
- Available Online: 2022-07-11
- Publish Date: 2022-07-09
-
Key words:
- abnormal event detection /
- channel-wise attention /
- feature prediction /
- multi-scale feature
Abstract: A novel method for abnormal event detection is proposed based on multi-scale feature prediction. Firstly, dilated convolution network is used to extract the features of different size receptive fields and fuse them so that address the objects of different scale in video frame. Secondly, a lightweight channel-wise attention module is applied to reduce the impact of background information. Finally, in order to make full use of the context information between video frames, a deep feature prediction module is applied to predict the features of the current moment based on the features of the historical moment, and the prediction error is used for abnormality judgment. Experiments were performed on the two benchmark data sets of USCD Ped2 and UMN to test and evaluate the proposed method. The experiments results show that the proposed method is more effective than other state-of-the-art methods.
| Citation: | WANG Jun. Abnormal Event Detection Based on Multi-Scale Features Prediction[J]. Journal of University of Electronic Science and Technology of China, 2022, 51(4): 586-591. doi: 10.12178/1001-0548.2021333

|





































 DownLoad:
DownLoad: