 ISSN
ISSN 





-
现代工程实践和生产经营等领域存在大量的复杂优化问题,如流程制造车间过程控制、复杂工业环境生产调度、航空发动机控制及生物学中的基因网络等[1]。这些问题往往具有非线性、多模态、决策变量之间耦合程度高等特点,传统优化方法求解上述问题的表现并不理想。进化算法为解决此类复杂优化问题提供了新的思路[2-3]。
差分进化[4](differential evolution, DE)算法由于原理简单、控制参数少及鲁棒性高等优点,得到了广泛关注。目前,针对DE算法的改进主要集中在3个方面。1) DE参数的自适应策略研究,由于控制参数对算法性能有重要影响,围绕DE的关键参数如缩放因子
$F$ 、交叉概率${\rm{Cr}}$ 和种群规模${{\rm{NP}}} $ 等产生了大量的研究结果,如SaDE[5]、JADE[6]及SHADE[7]等。2)从变异策略方面对DE算法进行改进,通过参与变异个体选择、差分扰动项、向最优解学习项等的变化产生了如DE/rand/1、DE/best/1、DE/best/2、DE/rand/2、DE/current-to-best/1等大量有代表性的研究成果[8-9]。3)结合其他算法如PSO[10],CMA-ES[11]等,融入其他算法的优点从种群初始化、个体选择、进化过程等方面提升DE的性能。尽管大量DE及其改进算法展现出了良好的性能,然而随着决策变量的增加及决策变量之间存在大量复杂耦合关系,算法的求解性能出现一定程度的下降,甚至部分复杂优化问题的最优解依然没有找到。另一方面,耦合决策变量之间的交互关系没有进行解耦分析以降低问题复杂程度,决策变量间的结构信息也没有得到充分的挖掘和利用,而这些信息往往对降低问题复杂度和指导种群搜索方向有较大帮助[12-13]。
基于以上分析,本文针对决策变量部分可分离复杂优化函数问题,基于“分而治之”思想采用差分分组策略对耦合决策变量进行解耦分组,形成多个没有依赖关系的简单子问题,然后设计一种构造学习策略,利用多个优秀个体的潜在有用信息,以每个子问题的优秀维度组合构造当前种群的最优解,引导种群向构造的最优解学习,提高算法的搜索性能,为解决具有复杂多变量耦合特征的部分可分优化问题提供基于差分进化算法的解决方法。
-
本文引入差分分组(differential grouping, DG2)[14]策略,基于算法SHADE(success-history based adaptive DE)[7]进行改进,以下分别进行介绍。
-
SHADE算法包含初始化、变异、交叉和选择等步骤。首先在问题的可行域中随机产生
${{\rm{NP}}} $ 个$D$ 维向量构成初始种群:变异操作是DE算法的核心操作,目前已有许多经典的变异策略,SHADE算法采用DE/current-to-pbest/1变异策略:
式中,
$t$ 为当前进化代数;$ {r_1} $ 、$ {r_2} $ 随机从$[1,{{\rm{NP}}} ]$ 中选取且与$i$ 互不相等;$F$ 为缩放因子;$ {\boldsymbol{X}}_{{{\rm{pbest}}} }^t $ 随机从${{\rm{NP}}} \times p(p \in [0.11,0.2])$ 个当前种群的最优解中选取。SHADE采用一个外部存档存储保存部分较差的个体以增加种群的多样性。式(2)表明DE/current-to-pbest/1变异策略包含了差分扰动和向优秀解学习两部分,$ F({\boldsymbol{X}}_{r1}^t - {\boldsymbol{X}}_{r2}^t) $ 为扰动项,且$ {\boldsymbol{X}}_{r2}^t $ 从外部存档和当前种群的合集中随机选取。$ F({\boldsymbol{X}}_{{{\rm{pbest}}} }^t - {\boldsymbol{X}}_i^t) $ 为向当前优秀解学习项。如果变异向量$ V_i^t $ 超出问题的可行域,则执行以下操作:交叉操作将变异向量和父代向量进行交叉,形成实验向量:
式中,
$ {{\rm{Cr}}} $ 是交叉概率;$ {j_{{\rm{rand}}}} $ 从$ \left[ {1,{D} } \right] $ 之间随机选取。然后从目标向量和实验向量中选择适应度较小(以最小化问题为例)的个体进入下一代种群,如下所示:参数控制机制对算法的搜索性能起着至关重要的作用,SHADE采用一种基于成功历史的自适应策略,将进化过程中成功的
$H$ 个缩放因子$F$ 和交叉概率$ {{\rm{Cr}}} $ 保存在${M_{{{{\rm{Cr}}}}}}$ 和${M_F}$ 中以供选择。参数$F$ 服从柯西分布$C({\mu _F},0.1)$ ,${\mu _F}$ 的初值为0.5,更新如下:式中,
${S_F}$ 为子代成功取代父代时参数$F$ 的集合,$ {\rm{mea}}{{\rm{n}}_L}({S_F}) $ 为Lehmer均值。类似地,交叉概率$ {{\rm{Cr}}} $ 服从正态分布$N({\mu _{{{{{\rm{Cr}}}}} }},0.1)$ ,${\mu _{{{{{\rm{Cr}}}}} }}$ 的初值为0.5,更新如下:式中,
${S_{ {\rm{Cr}}}}$ 为子代成功取代父代时参数${{\rm{Cr}}}$ 的集合;${{{\rm{mean}}} _A}({S_{ {\rm{Cr}} }})$ 为算术平均。 -
基于“分而治之(divide-and-conquer)”的思想,分组是进化算法解决复杂函数优化问题的一种重要策略,该策略将复杂问题划分为多个相对简单的子问题。有效的分组策略可以解耦多个存在交互关系的决策变量,最小化不同子问题之间的依赖关系[15]。
函数
$f({\boldsymbol{X}}):{\mathbb{R}^n} \to \mathbb{R}$ 是部分可分离问题,当且仅当:式中,
${\boldsymbol{X}} = ({x_1},{x_2}, \cdots, {x_n})$ 是$n$ 维决策向量;${{\boldsymbol{X}}_1}, {{\boldsymbol{X}}_2}, \cdots, {{\boldsymbol{X}}_m}$ 是向量$ {\boldsymbol{X}} $ 的不相交子向量,$2 \leqslant m \leqslant n$ 。函数
$f({\boldsymbol{X}})$ 满足如下条件则称之为部分加性可分离:差分分组方法检测决策变量之间的交互关系,如果存在交互则将其分在一组,否则被分在不同的组,如果一个决策变量与其他所有变量都不存在交互,则该变量为独立变量。分组方法定义如下。
$f({\boldsymbol{X}})$ 是部分加性可分离函数,$ \forall a,{b_1},{b_2},{x_p},{x_q} \in \mathbb{R} $ ,$ a,{b_1} \ne {b_2} $ ,$ \delta \in \mathbb{R} $ ,$ \delta \ne 0 $ ,如果以下式子成立,则${x_p}$ 和${x_q}$ 存在交互关系,是不可分决策变量。否则,
${x_p}$ 和${x_q}$ 为可分离决策变量。 -
CLSHADE的核心步骤主要包含3部分:分组、构造学习策略及SHADE。首先对复杂问题通过差分分组检测决策变量间的耦合关系,将原始问题分解为多个相互独立的分组。然后基于母体算法SHADE通过构造学习策略提高其搜索能力。算法总体框架如图1所示。
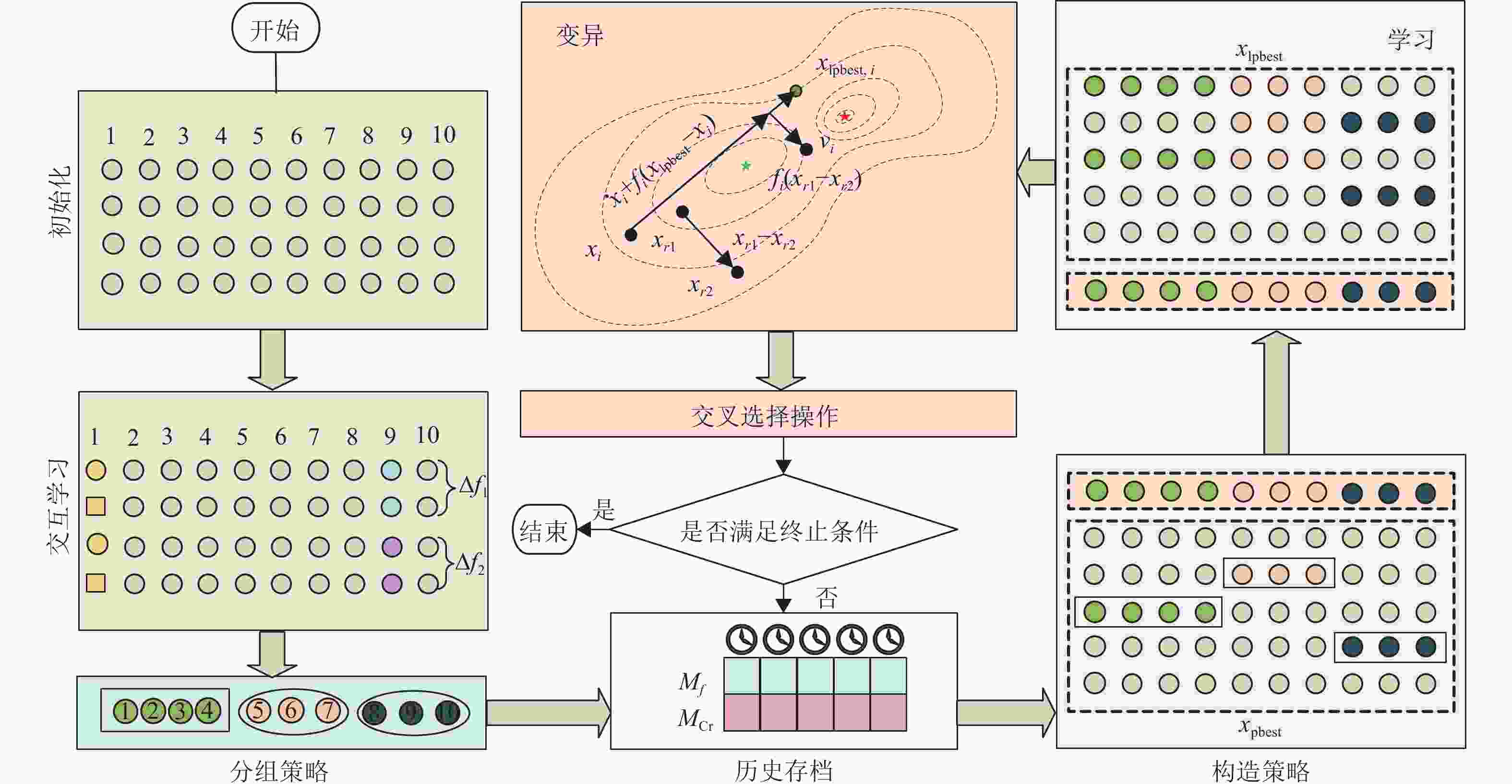
-
问题分组策略检查每个决策变量与其他决策变量之间是否存在交互关系,循环上述过程直到完成所有变量之间交互关系的判断,具体如算法1所示。其中
$f({\boldsymbol{X}})$ 为目标函数,$ {x^{{\rm{min}}}} $ 和$ {x^{{\rm{max}}}} $ 为决策变量上下界,${{\rm{ones}}} (1,D)$ 函数用于生成$D$ 维全1向量。为判断决策向量的第
$i$ 维和第$j$ 维是否存在交互,初始化两个决策向量${{\boldsymbol{x}}_1}$ 和${{\boldsymbol{x}}_2}$ ,${{\boldsymbol{x}}_1}$ 初始化为决策变量下界,${{\boldsymbol{x}}_2}$ 除第$j$ 维初始化为上界外,其他维度和${{\boldsymbol{x}}_1}$ 一样初始化为下界,然后根据式(10)和(11)计算$ {\varDelta _1} $ 和$ {\varDelta _2} $ ,根据既定阈值$\varepsilon $ 判断交互关系$ (\varepsilon = {10^{ - 3}}) $ ,最后输出决策变量分组结果。算法1 分组算法DG
输入:
$f({\boldsymbol{X}})$ 输出:分组结果
${{\rm{groups}}} $ 初始化:
$S \leftarrow \{ 1,2, \cdots ,D\} $ ,${{\rm{sep}}} \leftarrow \{ \} $ ,${{\rm{groups}}} \leftarrow \{ \} $ For
$i \in S$ do${{\rm{group}}} \leftarrow \{ i\}$ For
$j \in S \wedge i \ne j$ do${{\boldsymbol{x}}_1} \leftarrow {x^{{\rm{min}}}} \times {{\rm{ones}}} (1,D)$ ,${{\boldsymbol{x}}_2} \leftarrow {{\boldsymbol{x}}_1}$ ${{\boldsymbol{x}}_2}(i) \leftarrow {x^{{\rm{max}}}}$ ,${\varDelta _1} = f({{\boldsymbol{x}}_1} - {{\boldsymbol{x}}_2})$ ${{\boldsymbol{x}}_1}(j) \leftarrow 0$ ,${{\boldsymbol{x}}_2}(j) \leftarrow 0$ ,${\varDelta _2} = f({{\boldsymbol{x}}_1} - {{\boldsymbol{x}}_2})$ //初始化并根据式(10)~式(11)计算
$\varDelta $ If
$\left| {{\varDelta _1} - {\varDelta _2}} \right| > \varepsilon $ then${\text{group}} \leftarrow {{\rm{group}}} \cup \{ j\}$ //如果相关则放入一组
End
End
$S \leftarrow S - {{\rm{group}}}$ //相关则从$S$ 中移除If
${{\rm{length}}} ({{\rm{group}}} ) = 1$ Then$ {{\rm{seps}}} \leftarrow {{\rm{seps}}} \cup {{\rm{group}}} $ //保存独立变量Else
${{\rm{groups}}} \leftarrow {{\rm{groups}}} \cup {{\rm{group}}}$ //在
${{\rm{groups}}} $ 中加入新识别的分组End
End
${{\rm{groups}}} \leftarrow {{\rm{groups}}} \cup \{ {{\rm{seps}}} \} $ //输出结果 -
变异策略是DE算法的核心操作,DE/best/1、DE/best/2以及SHADE采用的DE/current-to-best/1都向当前种群的优秀解
$ {\boldsymbol{X}}_{{{\rm{pbest}}} }^t $ 学习,利用$ {\boldsymbol{X}}_{{{\rm{pbest}}} }^t $ 中潜在的有用信息引导种群的搜索。然而,$ {\boldsymbol{X}}_{{{\rm{pbest}}} }^t $ 有可能存在部分维度优秀,部分维度一般的情况。一个简单的例子,假设给定一个最小化优化函数$ f(x) = {({x_1} - {x_2})^2} + {({x_3} - {x_4})^2} $ ,$ x \in {[0,1]^4} $ ,基于交互关系决策变量显然可以分为两组$\{ {x_1},{x_2}\} $ ,$\{ {x_3},{x_4}\} $ 。对于3个$ {\boldsymbol{X}}_{{{\rm{pbest}}} }^t $ :$(0.8,0.4,0.6,0.4)$ ,$(0.6,0.4,0.8,0.4)$ 和$(0.6,0.4,0.6,0.4)$ ,前两个解都在部分分组维度上优秀,而第三个解在全部分组维度上优秀,最终最优解为$(0.6,0.4,0.6,0.4)$ 。得益于分组结构,构造一个
$ {\boldsymbol{X}}_{{{\rm{cpbest}}} }^t $ ,组合多个个体不同分组维度的优秀信息,具体如下:式中,
$ {\boldsymbol{X}}_{{{\rm{pbest}}} ,{{i}}}^t $ 为第$i$ 个分组的优秀解。新的变异策略结合DE/current-to-best/1策略和构造学习策略(constructive learning strategy, CLS),如下所示:式中,
$ {\boldsymbol{X}}_{{{\rm{lpbest}}} }^t $ 以概率$ {{{{Pc}}} _i} $ 向构造的$ {\boldsymbol{X}}_{{{\rm{cpbest}}} }^t $ 学习,如:式(15)为学习概率
$ {{{{Pc}}} _{{i}}} $ 的定义,其中,$ \varphi $ 为学习因子;${{{{\rm{ps}}}}} $ 为$ {\boldsymbol{X}}_{{{\rm{pbest}}} }^t $ 的数量;${{\rm{rand}}} $ 是$[0,1]$ 之间的随机数。可以看出$ {{{{Pc}}} _{{i}}} $ 单调递增,是考虑到随着进化过程的推进,$ {\boldsymbol{X}}_{{{\rm{cpbest}}} }^t $ 逐步向问题最优解区域靠近,因此在进化后期比进化前期赋予相对较高的学习概率。考虑到学习因子$ \varphi $ 对算法性能的影响,因此在本文实验部分和其他重要参数一起进行正交实验分析。构造学习策略具体流程如算法2所示。算法2 构造学习策略CLS
输入:
$f({\boldsymbol{X}})$ ,${{\rm{groups}}} = \{ {{{\rm{group}}} _1},{{{\rm{group}}} _2}, \cdots ,{{{\rm{group}}} _m}\}$ 输出:
$ {{\boldsymbol{X}}_{{{\rm{lpbest}}} }} $ For
$i = 1:{{\rm{ps}}}$ do //构造${{\boldsymbol{X}}_{{{\rm{cpbest}}} ,{\rm{i}}}}$ 过程For
$j = 1:m$ do$\tau = {{\rm{groups}}} (j)$ //第$j$ 个分组${{\rm{ind}}} _1^j = \left\lceil {{{\rm{rand}}} (0,1) \times {{\rm{ps}}} } \right\rceil$ ${{\rm{ind}}} _2^j = \left\lceil {{{\rm{rand}}} (0,1) \times {{\rm{ps}}} } \right\rceil$ //向上取整If
$f({{\boldsymbol{X}}_{{{\rm{pbest}}} }}({{\rm{ind}}} _1^j)) \leqslant f({{\boldsymbol{X}}_{{{\rm{pbest}}} }}({{\rm{ind}}} _2^j))$ ${\boldsymbol{X}}_{{{\rm{cpbest}}} ,{\rm{i}}}^\tau = {{\boldsymbol{X}}_{{{\rm{pbest}}} }}({{\rm{ind}}} _1^j)$ Else
${\boldsymbol{X}}_{{{\rm{cpbest}}} ,{\rm{i}}}^\tau = {{\boldsymbol{X}}_{{{\rm{pbest}}} }}({{\rm{ind}}} _2^j)$ End
End
End //基于分组构造最优解
For
$i = 1:{{\rm{ps}}}$ do //${\boldsymbol{X}}_{{{\rm{lpbest}}} ,{{i}}}^t$ 的生成For
$j = 1:m$ do$\tau = {{\rm{groups}}} (j)$ If
${{\rm{rand}}} < {{{{Pc}}} _{{i}}}$ ${\boldsymbol{X}}_{{{\rm{lpbest}}} ,{{i}}}^\tau = {\boldsymbol{X}}_{{{\rm{cpbest}}} ,{{i}}}^\tau$ Else
${\boldsymbol{X}}_{{{\rm{lpbest}}} ,{{i}}}^\tau = {\boldsymbol{X}}_{{{\rm{pbest}}} ,{{i}}}^\tau$ End
End
End //向构造的最优解学习
-
CLSHADE首先采用算法1对问题分组,然后在SHADE算法中使用算法2设计的构造策略迭代寻优,具体流程如算法3所示。
算法3 CLSHADE
输入:
$f({\boldsymbol{X}})$ ,维数$D$ 输出:最优解
${{\boldsymbol{X}}_{{{\rm{best}}} }}$ 初始化:
${{\rm{NP}}} = 18D$ ;${{\boldsymbol{X}}^0} = ({\boldsymbol{X}}_1^0,{\boldsymbol{X}}_2^0, \cdots ,{\boldsymbol{X}}_{{{\rm{NP}}} }^0)$ ;$t = 0$ $H = 5$ ;${M_{{{{{\rm{Cr}}}}} ,{{i}}}} = 0.5$ ,${M_{{{F}},{{i}}}} = 0.5$ ;${{\rm{groups}}} = {{\rm{DG}}} (f({\boldsymbol{X}}),{{\boldsymbol{X}}^0})$ //采用算法1进行分组Repeat
${S_{{{\rm{CR}}} }} = \phi$ ,${S_F} = \phi $ ${{\boldsymbol{X}}_{{{\rm{lpbest}}} }} = {{\rm{CLS}}} (f({\boldsymbol{X}}),{{\rm{groups}}} )$ //采用算法2实施构造学习
For
$i = 1:{{\rm{NP}}}$ do$k = {{\rm{rand}}} [1,H]$ //从历史存档中随机选择${{{\rm{CR}}} _i} = {{{\rm{rand}}n} _i}({M_{{{\rm{Cr}}} ,{{k}}}},0.1)$ ${F_i} = {{{\rm{rand}}c} _i}({M_{{{{F}}} ,{{k}}}},0.1)$ ${p_i} = {{\rm{rand}}} [{p_{\min }},0.2]$ 采用式(13)进行变异操作
采用式(4)进行交叉操作
采用式(5)进行选择操作
End
更新
${M_{{{{{\rm{Cr}}}}} ,{{k}}}}$ ,${M_{{{{F}}} ,{{k}}}}$ $t{\text{ + + }}$ //迭代次数递增Until 达到算法终止条件
-
本文实验环境为:Windows 10操作系统;Intel (R) Core (TM) i7-6700 CPU @ 3.40 GHz处理器;8 GB内存;基于MATLAB实现。比较算法的控制参数按照相应文献的建议进行设置。选取CEC 2017[16]标准测试集的变量部分可分函数并在10D、30D上采用相同的评价准则进行实验。经过实验发现CEC 2017标准测试函数
${f_1} \sim {f_{20}}$ 为部分变量部分可分函数,因此选用${f_1} \sim {f_{20}}$ 作为测试函数。CLSHADE算法有3个关键的参数:变异因子
${M_F}$ 、交叉概率${M_{{\rm{Cr}}}}$ 和学习因子$\varphi $ ,其初始取值的设定对算法的性能有重要影响,本文采用实验设计方法DOE(design of experiment)[17]分析其对算法性能的影响并最终确定相应的初始取值。表1为每个参数的水平值设置。参数 水平 1 2 3 4 $ M_{F} $ 0.3 0.5 0.7 0.9 ${M_{ {{{{\rm{Cr}}}}} } }$ 0.3 0.5 0.7 0.9 $\varphi$ 0.35 0.45 0.55 0.65 表1参数的所有可能组合数为
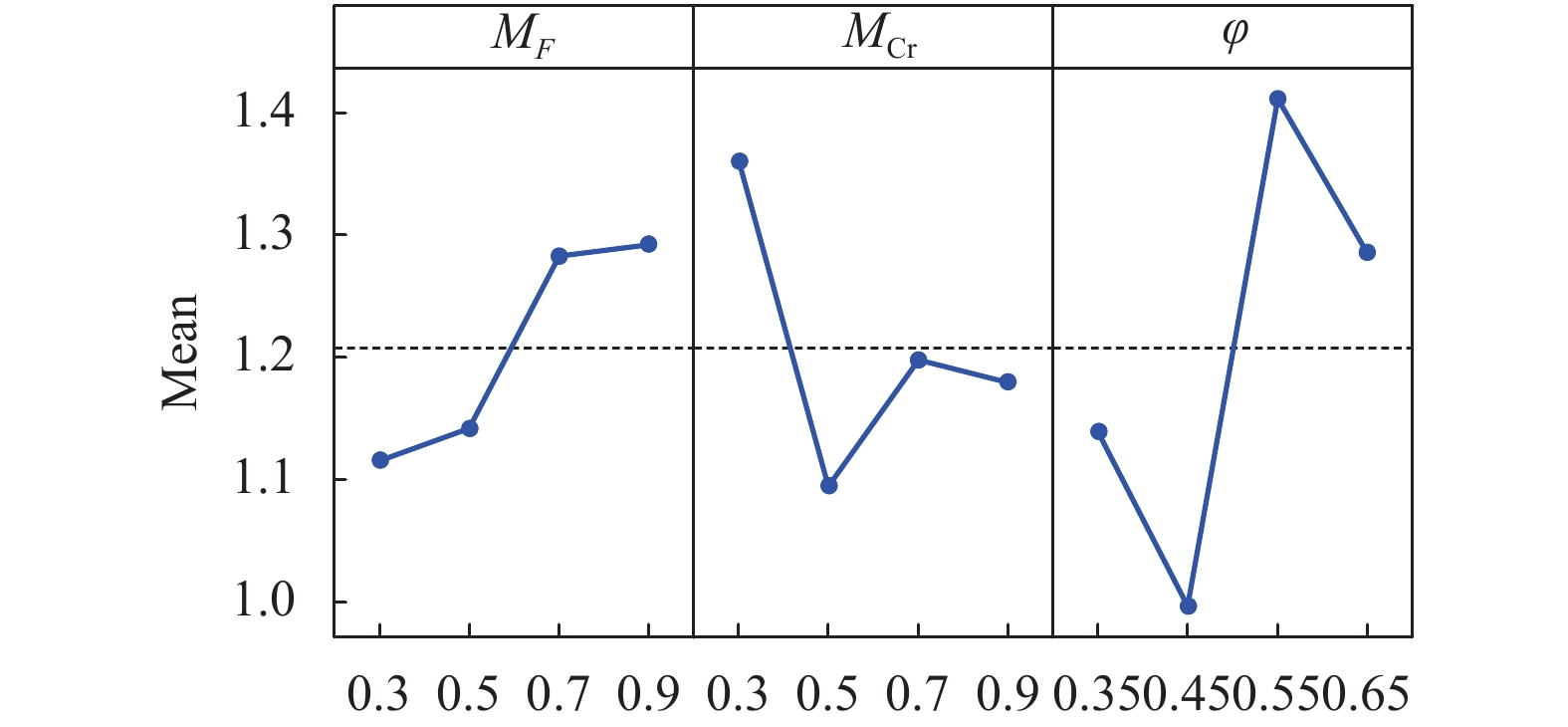
$4 \times 4 \times 4=64$ ,每个参数组合独立运行10次以确保实验具有统计学意义。对实验结果进行多元方差分析(multivariate analysis of variance, MANOVA),结果如表2所示。从表2可以看出,参数
$\varphi $ 对应的F-ratio最大,即参数$\varphi $ 对CLSHADE的平均性能影响最大。 由于算法两个参数之间的$p$ 值大于0.05,所以CLSHADE中两个参数之间没有交互作用。参数主效应图如图2所示,因此选取参数取值组合:${M_F} = 0.3$ ,${M_{{{{{\rm{Cr}}}}} }} = 0.5$ ,$\varphi = 0.45$ 。其他CLSHADE算法中涉及的所有其他非关键参数都与SHADE保持一致。Source Sum of
squaresDegrees of
freedomMean Square F-ratio p-value ${M_F}$ 0.410 3 0.137 0.43 0.7303 ${M_{ { { {{\rm{Cr}}} } } } }$ 0.591 3 0.197 0.63 0.6045 $\varphi $ 1.549 3 0.516 1.64 0.2033 ${M_F}*{M_{ { { {{\rm{Cr}}} } } } }$ 2.780 9 0.309 0.98 0.4771 ${M_F}*\varphi $ 2.259 9 0.251 0.8 0.6216 ${M_{ {{\rm{Cr}}} } }*\varphi$ 0.782 9 0.868 0.28 0.9760 Error 8.498 27 0.315 Total 16.869 63 ${{\boldsymbol{X}}_{{{\rm{pbest}}} }}$ $ {x_1} $ $ {x_2} $ $ {x_3} $ $ {x_4} $ $ {x_5} $ $ {x_6} $ $F({\boldsymbol{x}})$ 1 −43.67 26.11 −28.75 −79.55 −38.51 71.29 535.73 2 −22.06 −4.18 49.64 −13.93 19.72 0.24 538.07 3 −32.94 18.91 −28.04 −14.42 22.07 83.43 540.03 4 37.80 70.86 −60.65 −26.23 49.67 12.95 541.39 5 −68.07 −39.78 −27.09 −42.74 25.82 74.39 541.48 6 23.36 83.11 −8.96 −97.31 17.70 31.17 541.90 7 10.48 16.73 38.69 38.44 13.00 −37.07 542.02 8 −21.81 18.78 27.74 −42.74 −3.60 28.81 545.09 9 −87.73 60.57 16.15 41.29 −35.96 −8.70 545.45 10 −40.63 98.65 72.85 31.97 34.68 −24.68 546.14 11 −15.94 −33.65 24.52 −62.09 −24.69 −22.56 547.46 12 24.66 −46.47 20.06 -64.49 44.71 14.16 547.82 $ {{\boldsymbol{X}}_{{{\rm{lpbest}}} }} $ 23.36 83.11 20.06 −64.49 44.71 14.16 512.49 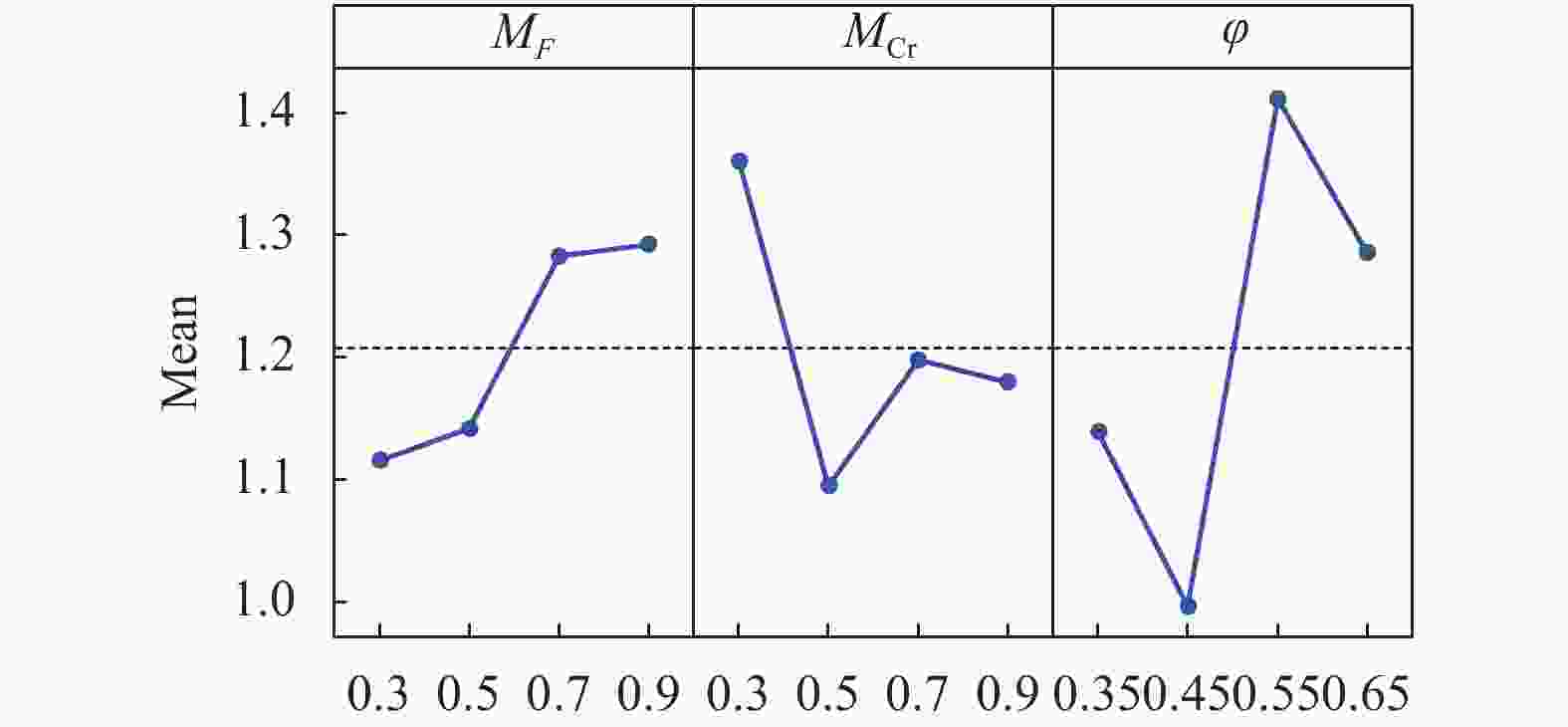
-
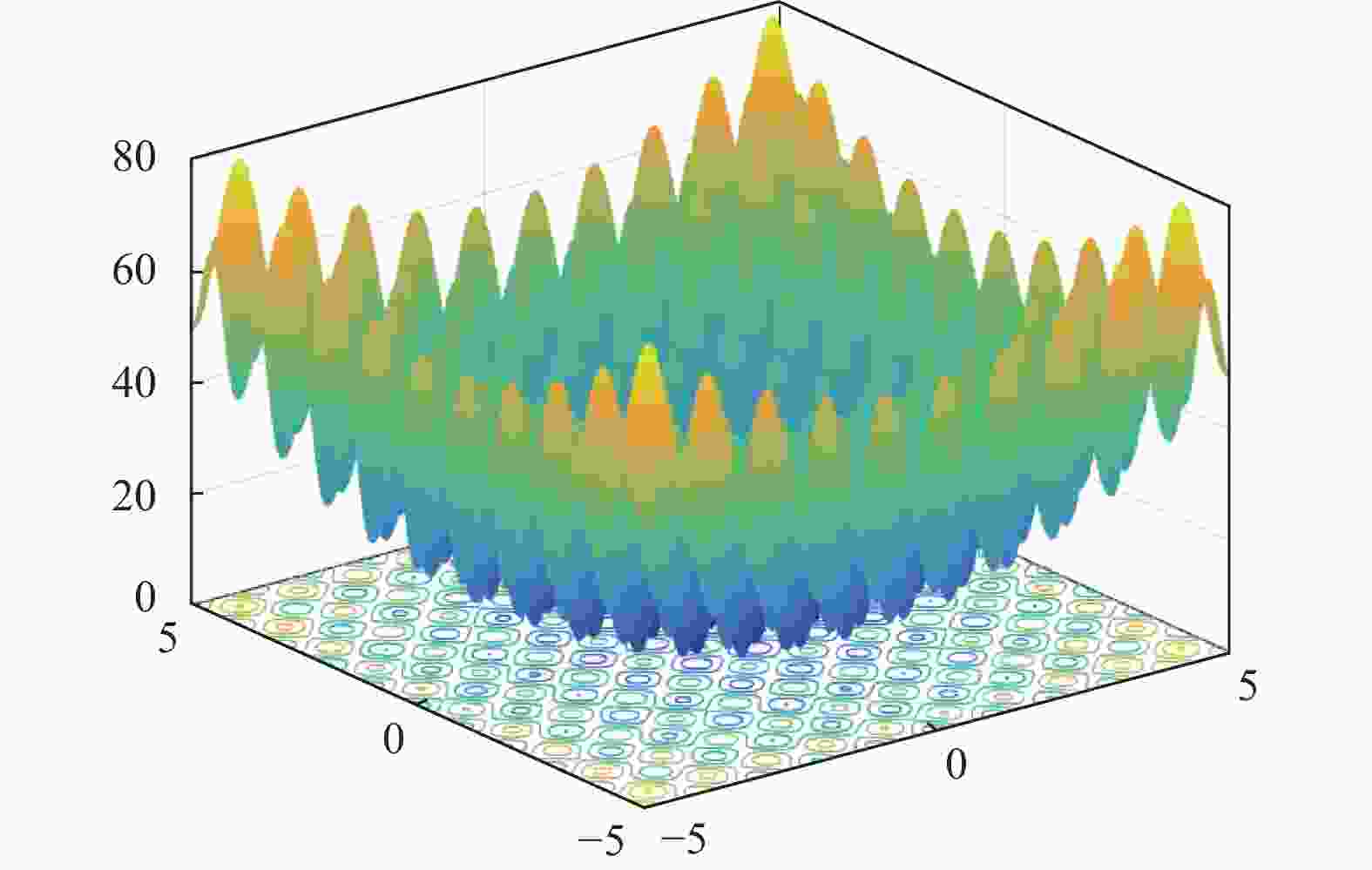
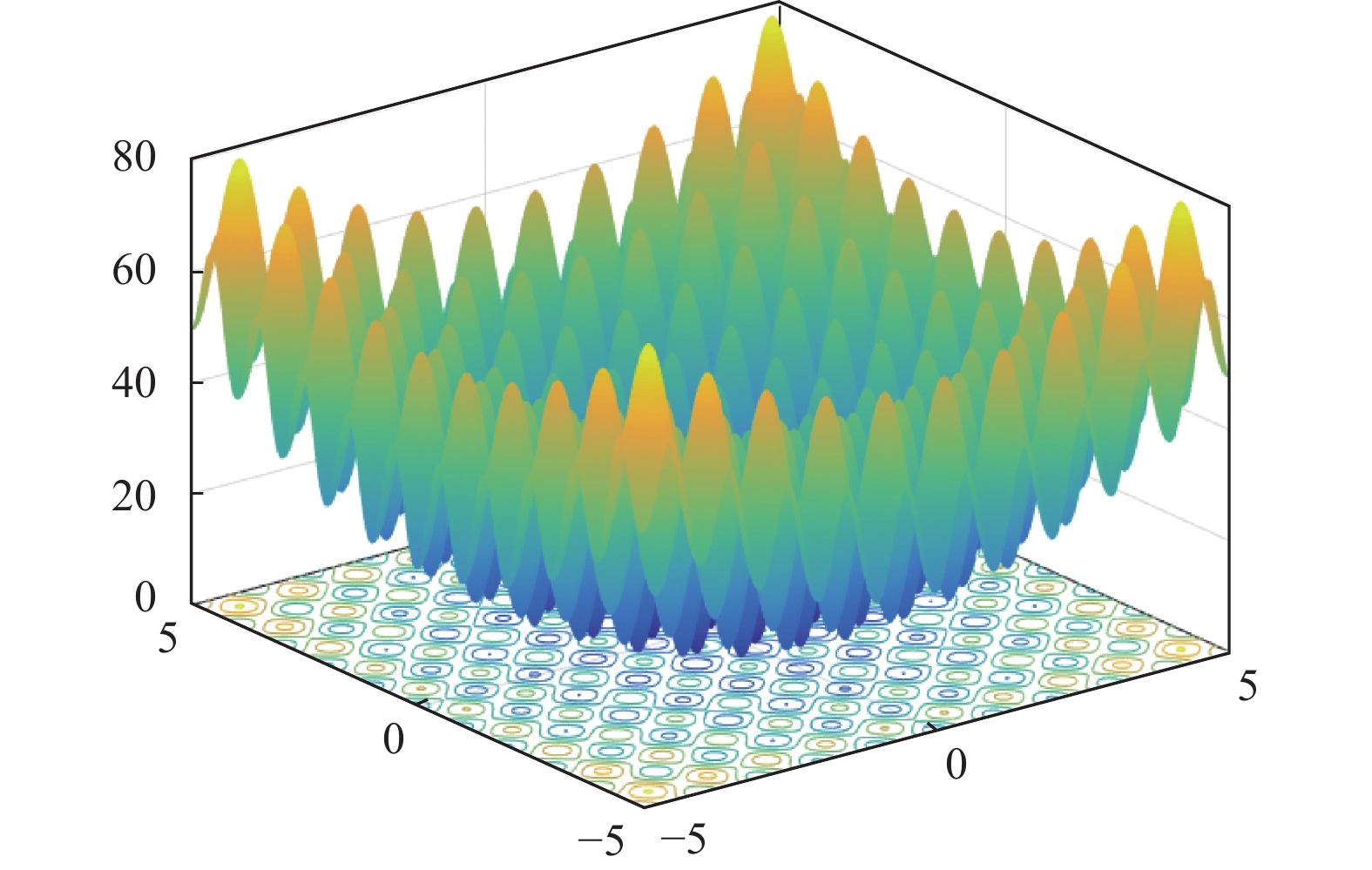
为通过具体函数观察CLSHADE的运行机制,以求解CEC 2017测试集的
${F_5}({\boldsymbol{x}})$ (shifted and rotated rastrigin’s function)函数为例进行说明。从图3所示Rastrigin’s函数的适应度地形图可以看出,该函数具有多模及多个局部最优等复杂特性。CEC 2017对其进行旋转平移定义如下:
以
$D = 6$ 为例,其旋转矩阵${\boldsymbol{M}}$ 和平移向量${\boldsymbol{o}}$ 分别为:采用算法1进行对Rastrigin’s函数进行分组,共分为3个组,分别是
${{{\rm{group}}} _1} = \{ {x_1},{x_2}\} $ ,${{{\rm{group}}} _2} = \{ {x_3},{x_6}\} $ ,${{{\rm{group}}} _3} = \{ {x_4},{x_5}\} $ 。采用构造学习策略后$F({\boldsymbol{x}})$ 的值如表3所示,显然得到了一个更有潜力的优秀解,从而加快了算法的收敛速度,并提高了解的精度。 -
为验证CLSHADE算法的性能,选取SHADE[7]、AMECoDEs[18]、HS-ES[19]和EBLSHADE[20]作为比较算法。所有实验在每个测试问题上独立运行51次,计算均值和标准差(Meanstd),实验结果如表4(10维)和表5(30维)所示。
表4列出了10维问题的实验结果,可以看出所有算法在
$ {f_1} \sim {f_4}、{f_9} $ 等5个函数上都找到了相同的最优解,在其余15个函数上CLSHADE有7个函数的结果优于其他算法,3个函数和部分其他算法找到相同的最优解,在其余函数如${f_5}、{f_{13}}$ 和${f_{19}}$ 上,CLSHADE也与求解性能最优算法的结果没有显著性差异。综上所述,CLSHADE在10维问题上的总体表现优于其他对比算法。Func SHADEMeanstd AMECoDEsMeanstd HS-ESMeanstd EBLSHADEMeanstd CLSHADEMeanstd 1 0.00E+000.00E+00 0.00E+000.00E+00 0.00E+000.00E+00 0.00E+000.00E+00 0.00E+000.00E+00 2 0.00E+000.00E+00 0.00E+000.00E+00 0.00E+000.00E+00 0.00E+000.00E+00 0.00E+000.00E+00 3 0.00E+000.00E+00 0.00E+000.00E+00 0.00E+000.00E+00 0.00E+000.00E+00 0.00E+000.00E+00 4 0.00E+000.00E+00 0.00E+000.00E+00 0.00E+000.00E+00 0.00E+000.00E+00 0.00E+000.00E+00 5 2.05E+008.06E−01 7.14E+002.85E+00 5.66E−017.24E−01 1.97E+007.83E−01 7.70E−017.70E−01 6 0.00E+000.00E+00 4.60E−063.42E−06 0.00E+000.00E+00 0.00E+000.00E+00 0.00E+000.00E+00 7 1.20E+015.69E−01 1.65E+012.77E+00 1.13E+017.82E−01 1.19E+014.66E−01 1.06E+011.06E+01 8 2.19E+008.45E−01 6.52E+002.74E+00 6.83E−017.57E−01 2.24E+007.92E−01 1.68E−011.68E−01 9 0.00E+000.00E+00 0.00E+000.00E+00 0.00E+000.00E+00 0.00E+000.00E+00 0.00E+000.00E+00 10 1.26E+012.38E+01 1.58E+021.24E+02 1.13E+021.49E+02 8.47E+007.94E+00 4.67E−014.67E−01 11 0.00E+000.00E+00 1.03E+009.58E−01 1.81E+008.55E+00 1.20E−038.56E−03 0.00E+000.00E+00 12 1.45E+013.98E+01 1.25E+013.67E+01 2.88E+015.94E+01 2.45E−011.80E−01 9.52E+009.52E+00 13 3.08E+002.31E+00 4.31E+001.98E+00 3.32E+002.46E+00 3.26E+002.29E+00 3.13E+003.13E+00 14 1.93E−021.29E−01 1.75E+001.38E+00 5.11E+001.84E+01 3.08E−031.64E−02 9.35E−049.35E−04 15 5.52E−031.91E−02 1.20E−013.00E−01 6.13E−016.26E−01 6.67E−021.60E−01 2.53E−022.53E−02 16 1.25E−011.65E−01 6.04E−011.53E+00 5.10E+003.04E+01 1.66E−012.11E−01 7.51E−027.51E−02 17 8.89E−031.43E−02 1.27E+008.30E−01 1.39E+011.15E+01 1.63E−024.96E−02 3.20E−033.20E−03 18 7.61E−021.66E−01 6.05E−022.36E−01 4.48E−011.85E−01 7.53E−021.47E−01 5.40E−025.40E−02 19 6.03E−053.30E−04 3.59E−024.41E−02 8.79E−014.49E+00 1.02E−087.31E−08 4.85E−084.85E−08 20 0.00E+000.00E+00 8.68E−021.94E−01 1.31E+019.60E+00 0.00E+000.00E+00 0.00E+000.00E+00 表5为30维问题的实验结果,所有算法在函数
$ {f_1} \sim {f_3} $ 、$ {f_9} $ 上取得相同的最优解,在$ {f_6} $ 上CLSHADE和HS-ES、EBLSHADE都获得最优解,在剩余的15个函数中,CLSHADE在10个函数上优于其他算法,3个函数上与表现最优算法接近。总体来说,CLSHADE在30维问题上表现优秀。Func SHADEMeanstd AMECoDEsMeanstd HS-ESMeanstd EBLSHADEMeanstd CLSHADEMeanstd 1 0.00E+000.00E+00 0.00E+000.00E+00 0.00E+000.00E+00 0.00E+000.00E+00 0.00E+000.00E+00 2 0.00E+000.00E+00 0.00E+000.00E+00 0.00E+000.00E+00 0.00E+000.00E+00 0.00E+000.00E+00 3 0.00E+000.00E+00 0.00E+000.00E+00 0.00E+000.00E+00 0.00E+000.00E+00 0.00E+000.00E+00 4 5.87E+017.78E−01 5.89E+011.32E+00 5.29E+001.20E+01 5.86E+010.00E+00 5.86E+010.00E+00 5 5.81E+001.16E+00 2.80E+011.07E+01 8.29E+003.18E+00 5.48E+001.23E+00 2.84E+009.01E−01 6 6.71E−104.79E−09 1.07E−083.72E−08 0.00E+000.00E+00 0.00E+000.00E+00 0.00E+000.00E+00 7 3.71E+019.51E−01 5.63E+019.29E+00 4.07E+016.57E+00 3.63E+019.61E−01 3.47E+016.11E−01 8 6.37E+001.17E+00 2.60E+011.13E+01 7.96E+002.29E+00 6.07E+001.44E+00 3.19E+008.40E−01 9 0.00E+000.00E+00 0.00E+000.00E+00 0.00E+000.00E+00 0.00E+000.00E+00 0.00E+000.00E+00 10 1.21E+031.85E+02 1.60E+035.33E+02 9.90E+023.88E+02 1.07E+031.56E+02 5.99E+021.11E+02 11 1.67E+012.41E+01 2.16E+012.41E+01 1.59E+012.42E+01 1.93E+012.62E+01 1.45E+012.22E+01 12 9.68E+023.57E+02 9.47E+023.45E+02 3.46E+018.72E+01 8.16E+022.98E+02 9.32E+022.99E+02 13 1.33E+015.19E+00 2.11E+018.54E+00 1.53E+014.30E+00 1.15E+016.46E+00 1.32E+014.84E+00 14 5.88E+008.83E+00 2.35E+018.05E+00 1.43E+019.95E+00 8.92E+009.69E+00 3.97E+007.28E+00 15 1.97E+001.48E+00 6.31E+003.04E+00 3.60E+003.28E+00 1.46E+001.09E+00 1.24E+009.96E−01 16 2.06E+014.03E+00 4.75E+022.07E+02 2.38E+021.66E+02 1.41E+012.98E+00 2.19E+014.71E+00 17 2.37E+016.26E+00 3.06E+014.55E+01 3.53E+016.28E+01 2.19E+015.57E+00 1.48E+013.04E+00 18 1.97E+014.74E+00 2.59E+016.39E+00 1.93E+014.96E+00 1.91E+015.27E+00 1.85E+016.38E+00 19 1.65E+007.67E−01 4.68E+001.53E+00 4.06E+002.49E+00 1.80E+009.36E−01 1.99E+008.61E−01 20 2.17E+015.88E+00 2.76E+011.98E+01 1.67E+027.53E+01 1.81E+016.52E+00 1.76E+014.30E+00 -
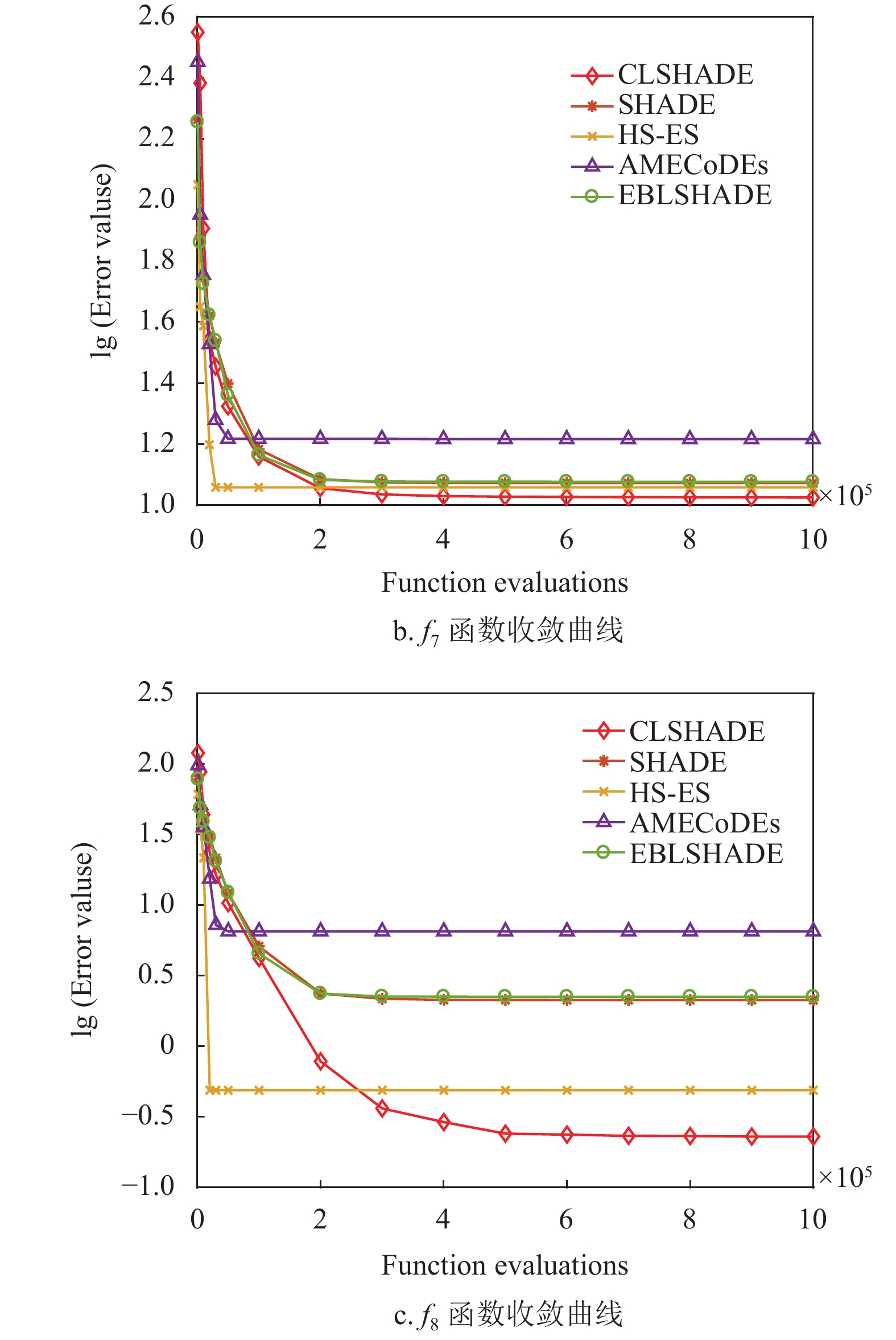
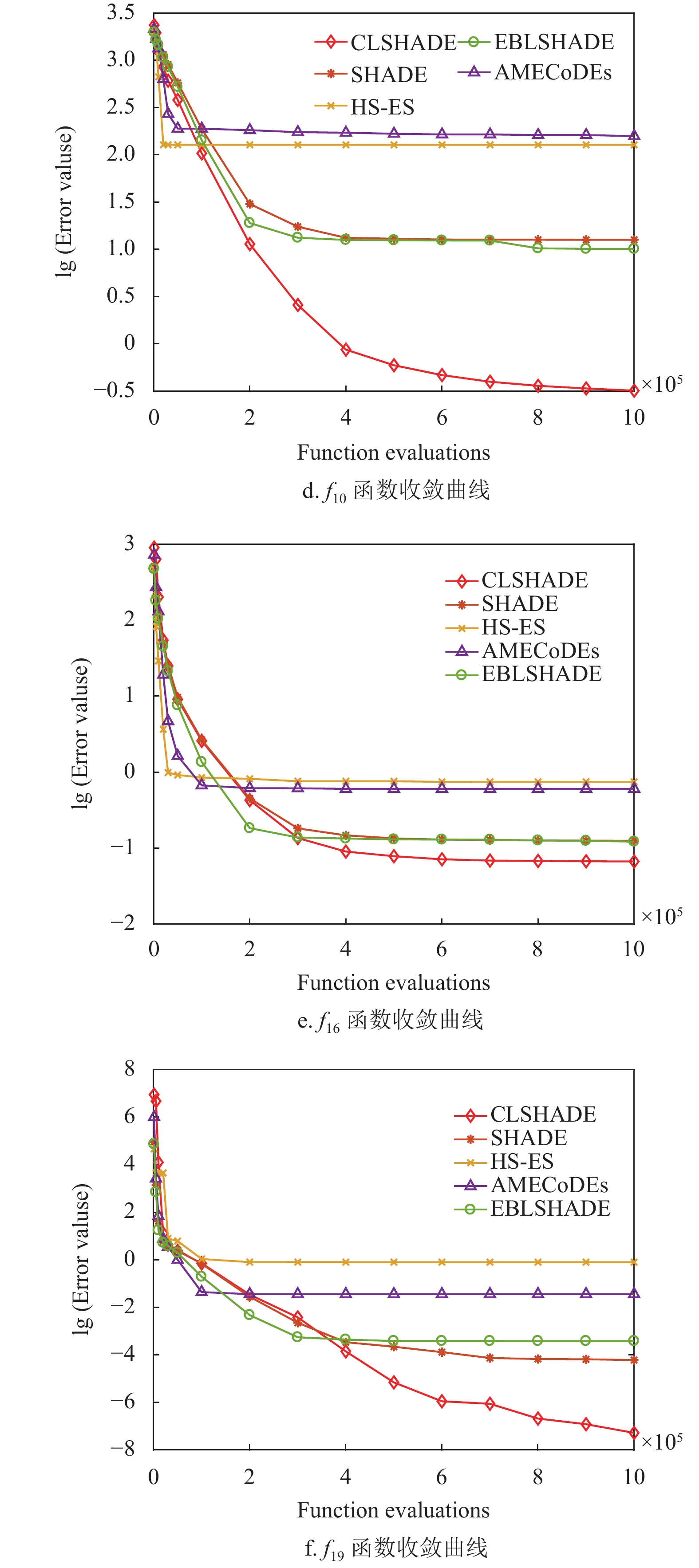
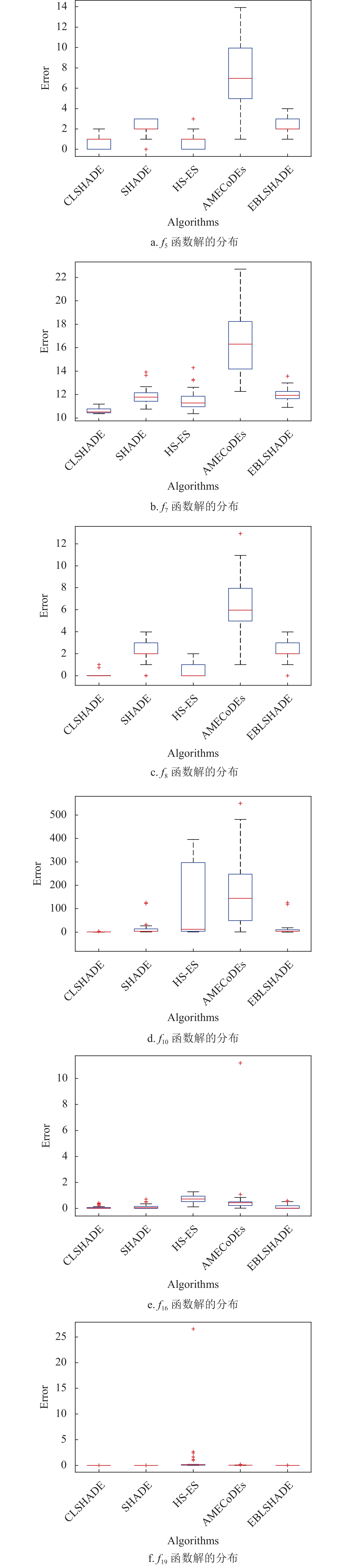
为进一步比较和分析所有算法的性能,本文以10维问题为例,通过收敛图观察算法的搜索过程(收敛性),通过盒图考察最优解的分布情况(稳定性),最后用Wilcoxon检验分析算法的统计学特性,结果如图4~图5及表6所示。
图4列出了部分函数的收敛图,可以看出CLSHADE算法与其他算法在进化前期与其他算法收敛速度接近。但是随着进化迭代次数的增加,构造的
$ {{\boldsymbol{X}}}_{{\rm{cpbest}}}^t $ 更接近最优解所在的区域,其引导搜索的作用更加明显,因此算法执行后期收敛速度加快并且解的精度也有明显的提升,如图中函数${f_8}$ 、${f_{10}}$ 、${f_{16}}$ 及${f_{19}}$ 等所示。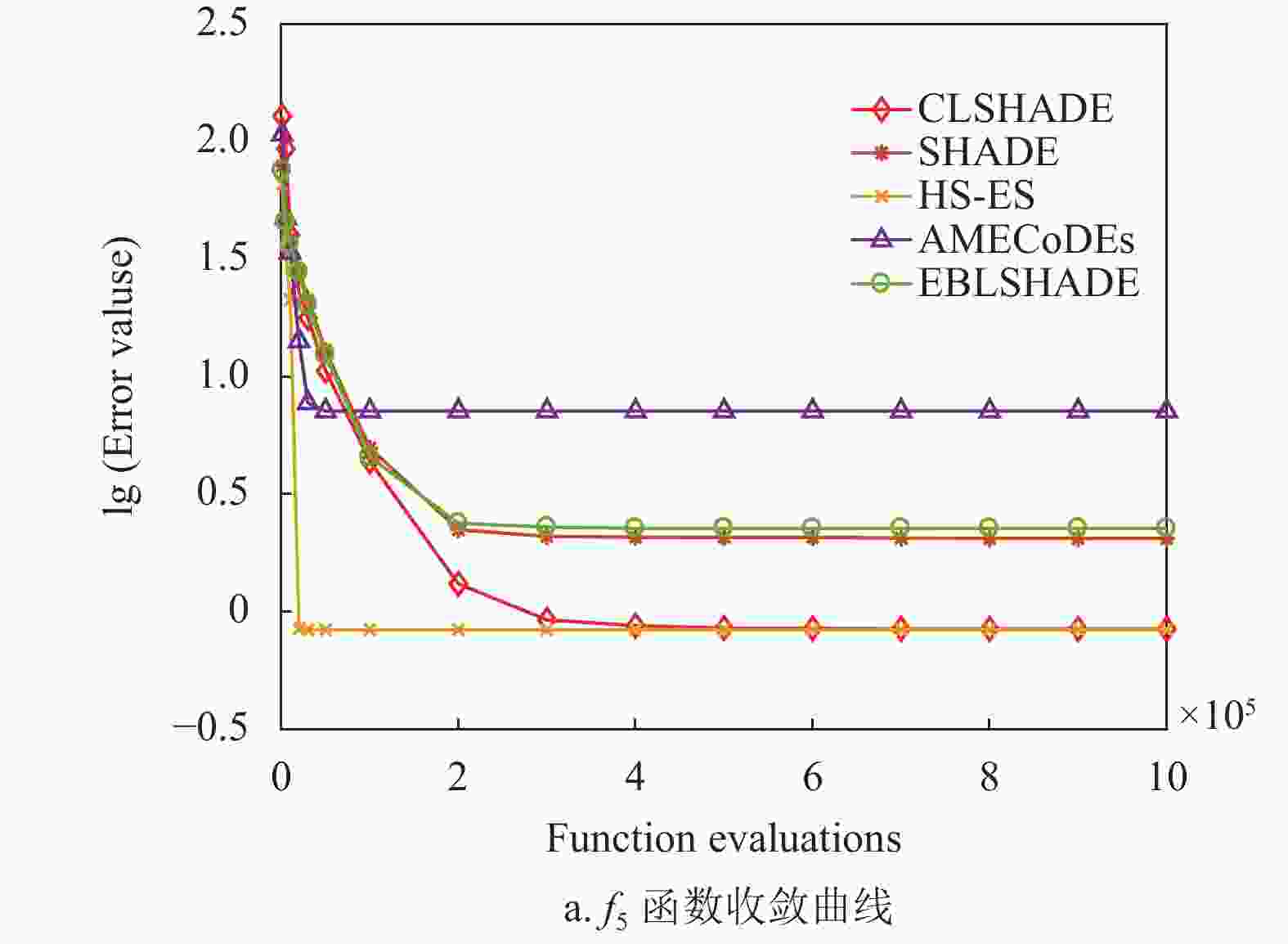

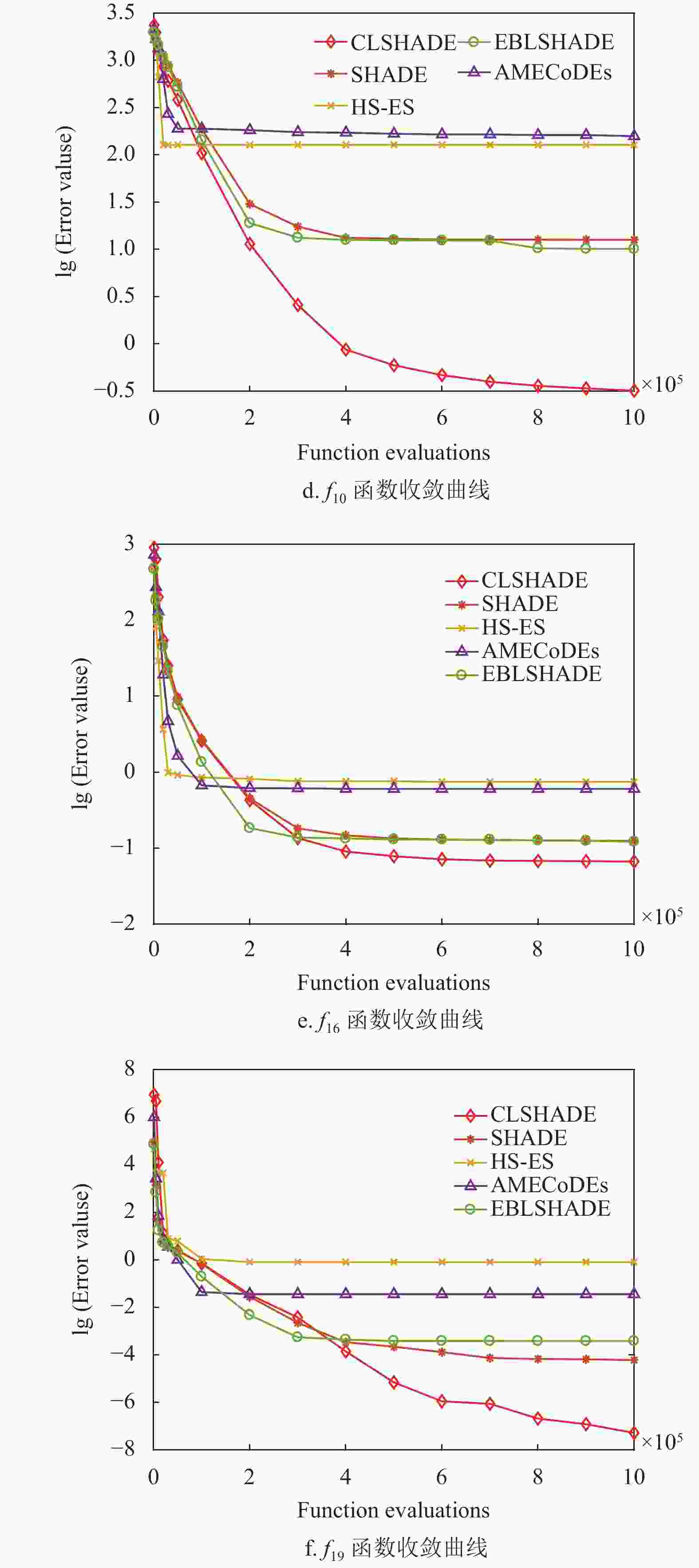
图5反映了与图4对应函数各算法最优解的分布情况,可以看出CLSHADE算法在函数
${f_7}$ 、${f_8}$ 和${f_{10}}$ 上具有良好的分布特性,表现优秀;在函数${f_5}$ 、${f_{16}}$ 和${f_{19}}$ 上与其他优秀算法表现相当,解的分布都比较集中,具有良好的稳定性。表6为CLSHADE与其他算法在显著性水平为0.05和0.1下的Wilcoxon非参数检验结果,可以看出在所有10维问题上CLSHADE与其他算法存在显著差异,都优于其他对比算法。在30维问题上,CLSHADE显著优于SHADE和AMECoDEs,当显著水平为0.1时优于HS-ES算法,其他情况下虽然不存在显著性差异,但从
$R - $ 值明显大于$R + $ 也可以得出CLSHADE优于其他算法。因此,从统计学的角度来说,CLSHADE总体表现优于其他对比算法。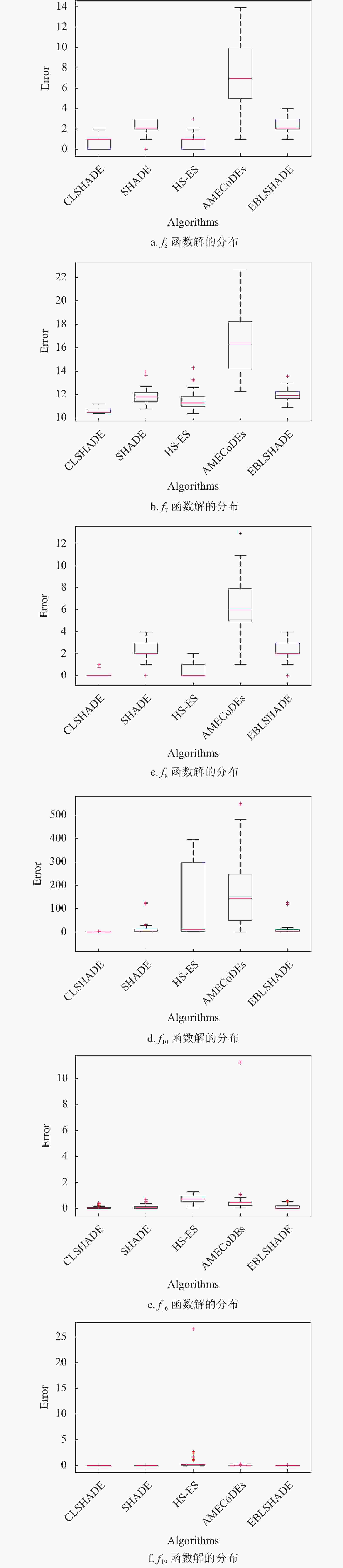
$维$ CLSHADE vs R+ R− Z p-value $\alpha = 0.1$ $\alpha = 0.05$ 10 SHADE 17.00 74.00 −1.992 0.046 Yes Yes AMECoDEs 0.00 120.00 −3.408 0.001 Yes Yes HS-ES 1.00 104.00 −3.233 0.001 Yes Yes EBLSHADE 26.00 79.00 −1.664 0.096 Yes Yes 30 SHADE 11.00 125.00 −2.948 0.003 Yes Yes AMECoDEs 0.00 136.00 −3.516 0.000 Yes Yes HS-ES 26.00 94.00 −1.931 0.053 Yes No EBLSHADE 32.00 73.00 −1.287 0.198 No No -
本文提出了一种基于构造学习的差分进化算法求解变量部分可分函数优化问题,采用差分分组技术揭示决策变量的底层交互结构和形成子成分并进行解耦分组;通过构造学习策略利用问题潜在的结构知识构造最优解并向其学习提升算法的寻优性能。在CEC 2017部分可分测试函数上的实验结果表明,本文算法在解的精度、收敛性和稳定性等方面均表现突出。
A Constructive Learning Differential Evolution Algorithm for Partially Separable Function Optimization Problems
doi: 10.12178/1001-0548.2022082
- Received Date: 2022-03-21
- Accepted Date: 2023-01-21
- Rev Recd Date: 2022-04-10
- Available Online: 2023-05-26
- Publish Date: 2023-05-28
-
Key words:
- constructive learning strategy /
- differential evolution /
- differential grouping /
- partially separable problems
Abstract: The dependence among decision variables in complex optimization problems leads to the appearance of a large number of local optimal solutions in the fitness landscape of functions, which are difficult to be solved by classical evolutionary algorithms. In this paper, a constructive learning success-history based adaptive differential evolution (CLSHADE) algorithm is proposed to solve partially separable function optimization problems. Firstly, CLSHADE uses the differential grouping technology (DG) to reduce the complexity of a complex problem by dividing it into multiple sub-problems. Then, a constructive learning strategy, based on the grouping structure, is designed. It learns from the constructed optimal solution in a certain probability to guide the search direction and improve the search performance of the CLSHADE. The experimental results on the partially separable function of CEC 2017 demonstrate the effectiveness of the CLSHADE.
| Citation: | CHEN Zuohan, CAO Jie, ZHAO Fuqing, ZHANG Jianlin. A Constructive Learning Differential Evolution Algorithm for Partially Separable Function Optimization Problems[J]. Journal of University of Electronic Science and Technology of China, 2023, 52(3): 413-422. doi: 10.12178/1001-0548.2022082

|












































































































































































































 DownLoad:
DownLoad: