 ISSN
ISSN 





-
推荐算法在近些年发展非常迅速[1],受到各行各业的关注,尤其是电商行业,十分依赖于推荐算法的应用,以此来提升目标用户的粘性和体验。随着信息量的增长,推荐算法也成为应对信息过载的主要手段,可以有效帮助用户从海量数据中筛选出目标项目,并且预测接下来有可能交互的对象。
早期的推荐算法是根据用户或物品间的相似性达到推荐的目的[2],但算法效果并不理想。实际上,用户的交互行为在大多数情况下是动态的,且会随着时间的推移而不断改变。因此,如何对用户的行为进行单独建模并挖掘其潜在兴趣成为推荐算法的研究热点。序列推荐是一种能够根据用户的历史行为来动态捕捉用户行为特征的重要推荐算法,通过输入一个用户交互序列来预测用户下一步的行为。传统序列推荐算法在训练模型时会遵循监督学习范式,通过引入一个或多个负样本,使用贝叶斯个性化排名(Bayesian personalized ranking, BPR)损失函数[3]来优化算法。但监督学习会将注意力重点放在样本标注与训练数据之间的关系对结果产生的影响上,比较依赖数据标注的准确性[4]。而且在对用户交互序列建模时也很容易受到噪声数据的影响,使得模型非常脆弱,无法做到精准推荐。
针对上述问题,本文提出一种基于对比学习与傅里叶变换的自注意力序列推荐算法CSFTRec,通过训练方法的转变与噪声数据的消除提高算法性能。首先,通过傅里叶变换在序列数据进入编码器(Encoder)之前过滤噪声。同时,引入两种数据增强方式处理序列数据,将原始序列与增强序列同时作为自注意力层的输入。最后,通过改进的对比损失函数计算损失值。在8个公开数据集上的实验证明,本文算法相比于目前的主流推荐算法,能有效提高推荐结果的准确性。
-
现有的序列推荐算法可以通过其对用户偏好建模的类型分为3种。
1)基于短期偏好的序列推荐算法,以马尔科夫链推荐为代表,低阶的马尔科夫链[5]是根据当前交互项,预测用户的下一交互项。高阶马尔科夫链[6]在低阶的基础上增加能够对目标项产生影响的交互项个数,但当用户交互序列较长时依然无法有效捕捉交互项之间的依赖关系,所以无法体现用户的长期偏好。卷积神经网络也被应用于处理用户的交互序列[7],效果相较于马尔科夫链略有提升,但核心思想还是对用户的短期偏好进行建模,算法依然存在局限性。
2)循环神经网络(recurrent neural network, RNN)是一类专门处理序列数据的神经网络,通过RNN构建的序列推荐算法[8]能够从全局的角度考虑整个交互序列,以对用户的长期偏好进行建模。在RNN的基础上,又拓展出基于长短期记忆(long short-term memory, LSTM)[9]和基于门控循环单元(gated recurrent unit, GRU)的网络。这两种网络有更多的参数和更好的性能,适合构建大型推荐网络,也可以有效预防模型的过拟合。此外,记忆网络(memory networks, MemNN)[10]也可以用来对用户长期偏好建模,通过引入一个外部存储器来保存序列与下一个交互项之间的依赖关系。MemNN相较于RNN系列网络,能有效降低算法的存储和计算压力。
3)此外,还有诸多模型综合考虑了长短期偏好对算法的影响。图神经网络(graph neural networks, GNN)[11]在序列推荐中使用有向图表示用户的交互序列,图中的一个节点就表示一个交互对象,将每个序列映射为图中的一条路径。GNN有着较强的可扩展性,如融入上下文增强的GCE-GNN[12]和融入多重加权图的FGNN[13],分别从不同角度对GNN在推荐算法中的应用做出完善。但GNN存在信息丢失问题,后续也提出了LESSR[14]等一系列模型去处理信息丢失。注意力机制也是一种比较流行的基于长短期偏好建模的序列处理算法,早期应用于机器翻译任务中[15]。NARM[16]则是使用普通注意力机制完成推荐任务,其强调输入的各部分对输出的影响程度不同,NARM的成功也使得注意力机制在推荐算法中广泛应用。本文选取自注意力机制作为序列推荐算法的核心,本文所提方法主要基于对比学习和自注意力机制。
-
对比学习任务主要可以分为3个阶段。第一阶段通过一系列对原始数据的处理,得出增强数据,这种处理也被称为数据增强。第二阶段通过Encoder对训练数据进行学习,Encoder主要用于提取数据特征。第三阶段对不同的数据特征进行对比学习,比较不同特征之间的相似程度。
对比学习使用数据本身的特征信息来指导学习,在计算机视觉(computer vision, CV)以及自然语言处理(natural language processing, NLP)领域得到广泛应用,其更注重于算法前后的逻辑设计,而很少去对Encoder部分做直接优化,甚至在部分对比学习任务中,并没有对Encoder类型进行明确规定,可以随意替换不同的Encoder完成不同领域的对比学习任务[17]。如ImageNet等任务中,对比学习的表现完全可以媲美传统的监督学习方法,而且还有提升的潜力[18]。
对比学习将原始数据和增强数据两两组合成为样本对,增强后的数据相较于原始数据称为正样本
${x^ + }$ ,不同组合的增强数据可以相互成为负样本${x^ - }$ ,利用Encoder$f\left( \cdot \right)$ 提取出数据的特征表示。对比学习目标则是通过不断修正正负样本之间的距离${\rm{score}}\left( \cdot \right)$ ,最终得出一个能够做到目标项和正样本之间距离尽可能近,和负样本之间距离尽可能远的模型:对比学习通常有多个负样本,若设负样本个数为k,则对比损失函数InfoNCE[19]为:
式中,
$g\left( \cdot \right)$ 为相似度函数,如余弦相似度;$\tau $ 是超参数温度系数,温度越高,样本的分布会相对平滑。通过优化InfoNCE可以提高相似样本之间的相似性,降低两个不相似样本之间的相似性。 -
对于序列模型来说,处理数据时很难做到尽可能多地考虑数据前后的语义信息,从而导致训练出的序列模型效果很不理想。如在词性标注任务当中,当同一个词出现在一个句子的不同位置时,传统的序列模型无法做到准确区分不同位置的词性区别,会直接给予相同的词性标注[20],即使通过一些特殊方法,能够将有限的上下文信息考虑进去,也会在很大程度上增加模型的参数数量,提升模型的训练成本。
而自注意力机制能够准确地揭示出句子中不同单词之间的语法和语义信息。并且从对比实验结果来看,自注意力机制的模型效果要远超于传统的CNN或RNN,并且对于序列推荐问题效果也不错,如基于自注意力机制的序列推荐算法SASRec[21]。注意力计算被定义为:
式中,Q代表一次查询;K和V是键值对;d表示K的维度大小。直观地说,Q、K、V表示3个矩阵,由输入数据通过一个全连接网络或者核大小为1的卷积层得到。但当输入维度较大时,点乘会导致数据剧烈增大,且通过softmax函数后可得到的梯度又过小,因此需要将Q与K的转置的乘积再乘以d的平方根的倒数,最后通过softmax层与矩阵V相乘,得到注意力得分。
-
由于自注意力机制(SASRec)对序列模型强大的表示能力和特征提取能力,本文提出一种基于对比学习与傅里叶变换的自注意力推荐算法CSFTRec,该算法由3部分组成,如图1所示。
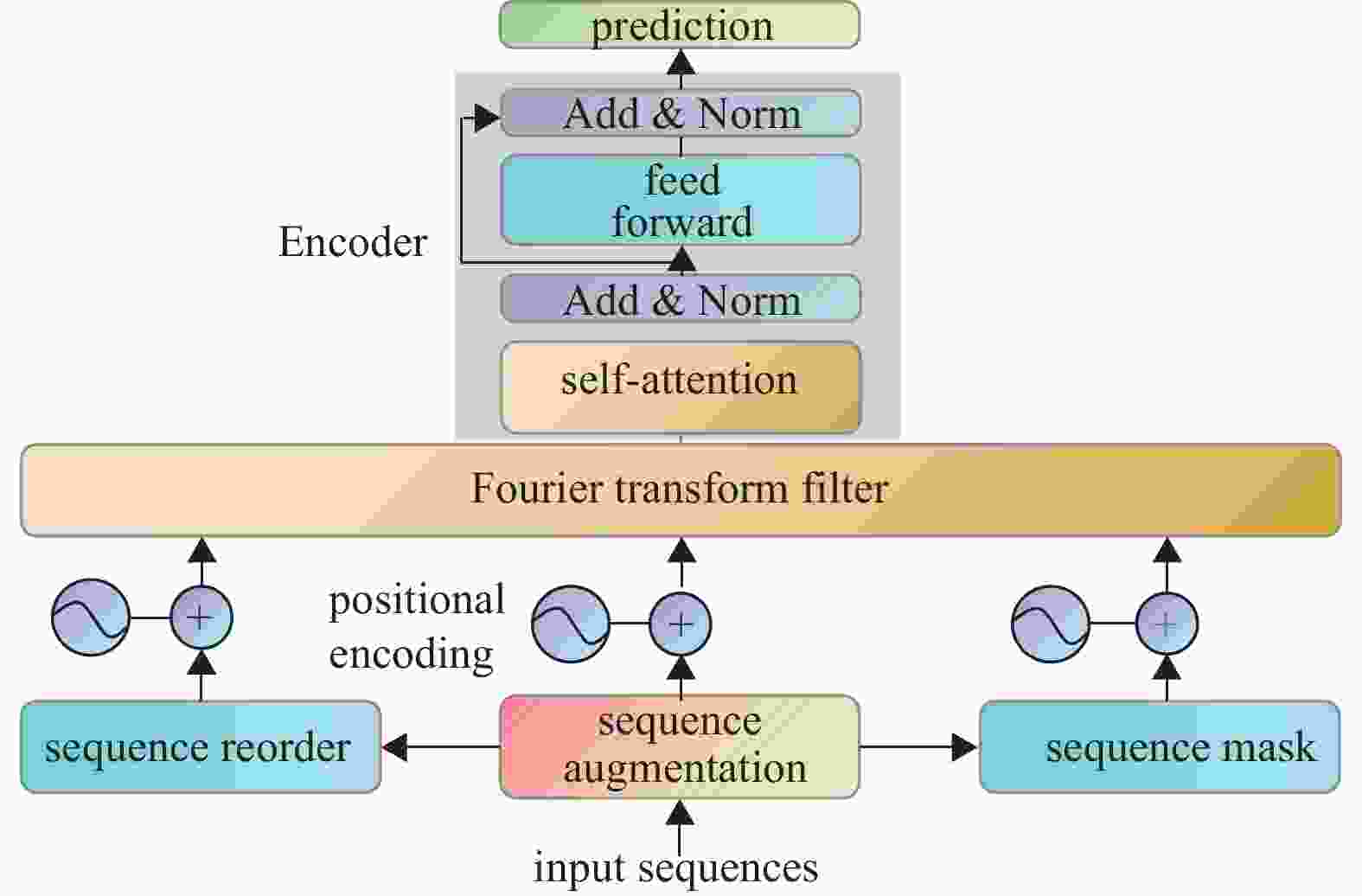
首先,使用两种数据增强方式对原始序列进行处理。同时,在序列数据进入Encoder前,为其添加位置编码,用以表示不同交互项之间的位置关系。
其次,对原始数据和增强数据进行降噪处理,傅里叶变换则是这一步的重要工具,通过FFT将交互序列信号由时域转换到频域,过滤噪音信号之后,再通过IFFT将信号从频域转换到Encoder可处理的时域。
最后,引入一种Context-Context语境对比损失函数[22],使其能够与InfoNCE损失联合完成对比学习任务,综合考虑用户交互序列中各种有可能会影响到目标结果的特征因素,以此来提高推荐算法的准确性。
-
在CV领域,不同的数据增强方式对不同的任务起到的作用也不尽相同,如SimCLR[23],通过对比现有的数据增强方法得出,并不是每一种数据增强都能对学习任务起到促进作用[24]。对比学习下的序列推荐依然遵循这一道理,本文采用遮盖和置换[25]两种增强方法。有实践表明,这两种方法可以在做到数据增强的同时,有效防止过拟合现象,增强模型的鲁棒性。
遮盖增强是使用一个特殊值随机遮盖用户交互序列中的一个或部分交互项,使其在与原始数据的对比学习中,能够让Encoder将更多的注意力放在未被遮盖的部分,其增强过程可以表示为:
对于给定长度为N的序列
${S_t}$ ,首先从Beta分布中随机抽取一个数值${p_1}$ ,用以计算掩盖位置${n_1}$ ,然后将特殊值mask覆盖在掩盖位置上完成数据增强。置换与遮盖相似,区别在于置换是进行位置交换操作,其增强过程可表示为:上述两种方法在使用中通过随机选择的方式对原始数据进行增强。
-
研究发现不论是水文学[26]、地震学[27]还是人类行为学[28],自然界和人类行为的低频信号通常是有意义的周期性特征,而高频信号却无法表现出这一特性。也有研究表明,在序列推荐算法中,模型往往更受益于低频信号[29],站在这一角度去看待用户交互序列,可以将其理解为是用户在某一特定场景下所释放出的信号表示,而这种信号表示在一定程度上反映了用户行为的周期性特征,这样就可以使用数字信号处理中的方法和工具对用户的信号表示进行处理,达到降噪的目的。
现给定一个用户交互序列矩阵
${{\boldsymbol{F}}^l} \in {\mathbb{R}^{n \times d}}$ ,其中$l$ 表示训练批次中的一个样例,将其通过快速傅里叶变换转换至频域:式中,
${X^l}$ 是${{\boldsymbol{F}}^l}$ 的复数形式张量表示;$f\left( \cdot \right)$ 是快速傅里叶变换。然后将其与滤波器${\boldsymbol{W}} \in {\mathbb{C}^{n \times d}}$ 相乘,通过$W$ 来调整张量中的信号表示:最后使用快速傅里叶逆变换对过滤后的序列进行处理,将其由频域转换至时域:
式中,
${f^{ - 1}}\left( \cdot \right)$ 为快速傅里叶逆变换,同时为了缓解梯度消失和训练不稳定的问题,在模型中再加一层LayerNorm[30]和Dropout[31]: -
传统的监督学习序列推荐算法大多会采用BPR作为训练目标,将推荐问题看作是一个Ranking问题,推荐效果的好坏,表现为用户的期待项在Ranking中的位置是否靠前。而事实也证明BPR算法在推荐领域很有成效,通过引入一个负样本,基于大量的正负样本对,根据贝叶斯后验来解决推荐问题:
该损失函数可以使目标项相比于负样本有更大概率获得更高的Ranking分数。实际上,BPR算法也可以被推广为一种特殊的InfoNCE损失函数:
这样推广的前提条件是公式中只允许存在一个负样本,以及InfoNCE中的温度系数
$\tau $ 恒等于1。这表明BPR与InfoNCE在一定程度上具有内在联系。将推广后的InfoNCE进一步优化得出:式中,k是负样本个数,相比于普通BPR算法,该损失可以在完成对比任务的同时适应多个负样本的情况。此外,如果先不考虑经过处理的增强序列,两个具有相同目标的普通序列是否具有潜在的相似性,以及这种相似性是否能对学习任务提供帮助,即使他们从表面上看起来可能完全不相同,这些都是在对比学习任务中需要着重考虑的问题,但BPR和InfoNCE都只考虑到了相似序列。而Context-Context损失则可以解决这一问题,可以将有着相似意图的序列表达尽可能拉近距离。为了优化这一目标,将所有有着相同目标的序列以及其增强序列放在同一集合中,集合中的每一个元素可以互相设置为正样本,由此得到一个新的对比学习任务:
式中,
$l\left( \cdot \right)$ 是用来计算两个相似序列之间的对比损失,为了完成上述的两种对比学习任务,可以将其联合进行训练:式中,
$\gamma $ 用来控制Context-Context损失的学习权重;$\lambda $ 是L2规范化系数。 -
在Amazon、Yelp、MovieLens、Gowalla上选取8个数据集进行实验,其中Amazon选择BaBy、Beauty、Movies、Toys、Food这5个不同种类生成的子数据集,均采用5-core版本。Yelp由于数据量过大,选取2018年之后的数据。MovieLens选择1M版本。表1给出每个数据集交互序列、交互项、稀疏性的相关信息。
DataSet Sequences Items Sparsity/% Baby 19445 7011 99.91 Beauty 22363 12068 99.94 Movies and TV 2088620 186349 99.99 Toys and Games 1342911 283394 99.99 Grocery and Gourmet Food 14684 8687 99.90 Yelp-2018 104072 54034 99.92 ML-1M 6040 3704 95.58 Gowalla 76894 304440 99.77 -
由于CSFTRec的损失函数是在BPR的基础上进一步进行推导得出的,所以采用Top-K推荐的召回命中率(hit ratio, HR)和归一化累积增益(normalized discounted cummulative gain, NDCG)作为模型评价指标[32]:
式中,
$I\left( \cdot \right)$ 是一个判别函数,会根据是否满足条件返回0和1。指标HR和NDCG越大,代表推荐结果越准确,算法效果越好。 -
为了探明对比学习任务下的推荐算法和基于傅里叶变换的噪声过滤是否具有成效,现将实验分为3组。第一组选取SASRec、FMLP-Rec以及没有过滤模块的CSFTRec+作为基准模型,主要用于探究过滤器模块对模型的具体影响,其中FMLP-Rec是在SASRec上添加了自学习过滤器。第二组选择BPRMF、POP、ComiRec[33]、FPMC[34]、GRU4Rec[35]作为基准模型。第三组选择SASRec、BERT4Rec[36]、TISASRec[37]为基准模型,这3个模型是以自注意力机制为核心的推荐算法,BERT4Rec和TISASRec是在SASRec的基础上进行了一定的改进,其中BERT4Rec引入了双向Transformer编码器,TISASRec引入了对于序列时间间隔的编码。上述实验全部基于Python3.8以及Pytorch1.8.1框架进行实现,运行环境为RTX 3090(24 GB)、15核AMD EPYC 7543 32-Core Processor以及80 GB内存。模型均使用Adam优化器,学习率统一设置为1×10−4,每个模型均不进行预训练。
-
表2为过滤器模块对算法的影响,可见FMLP-Rec和CSFTRec相较于基础模型在增加过滤器模块后性能方面有所提升,即使去除过滤器模块,对比学习下的联合训练任务在大部分情况下也要表现的更好。此外,表3为4个模型的时间性能对比,在增加过滤器模块后,必然会增加迭代时间,但CSFTRec的迭代速度要快于普通SASRec和FMLP-Rec,这是由于新的对比学习损失加快了整体损失的计算,而单纯的BPR损失要花费更多的时间。
DataSets Methods Metric HR@5 HR@10 NDCG@5 NDCG@10 Yelp SASRec 0.368 5 0.498 2 0.259 9 0.301 8 FMLP-Rec 0.360 7 0.493 9 0.253 4 0.296 4 CSFTRec+ 0.378 0 0.515 0 0.263 2 0.307 5 CSFTRec 0.382 4 0.521 1 0.268 0 0.312 8 MovieLens SASRec 0.702 0 0.805 0 0.550 2 0.583 8 FMLP-Rec 0.713 9 0.809 8 0.562 0 0.593 1 CSFTRec+ 0.703 8 0.798 3 0.553 5 0.584 4 CSFTRec 0.715 4 0.812 9 0.566 8 0.598 6 Food SASRec 0.385 5 0.474 2 0.287 6 0.316 4 FMLP-Rec 0.396 3 0.483 7 0.300 4 0.328 7 CSFTRec+ 0.404 9 0.489 9 0.310 7 0.338 3 CSFTRec 0.401 7 0.479 9 0.309 1 0.335 1 Gowalla SASRec 0.617 4 0.738 5 0.477 1 0.516 3 FMLP-Rec 0.618 2 0.737 2 0.478 4 0.517 0 CSFTRec+ 0.642 3 0.749 8 0.500 3 0.535 2 CSFTRec 0.669 8 0.776 3 0.524 1 0.558 8 Movies SASRec 0.694 9 0.781 6 0.572 9 0.601 2 FMLP-Rec 0.691 0 0.775 9 0.571 3 0.598 9 CSFTRec+ 0.707 6 0.786 9 0.595 4 0.621 2 CSFTRec 0.704 8 0.793 1 0.595 5 0.620 3 算法 数据集 Gowalla Yelp2018 ML-1M SASRec 188 41 40 FMLP-Rec 240 53 52 CSFTRec 120 34 26 CSFTRec+ 90 23 20 基于表4和表5的结果,可以得出非序列推荐算法性能明显要更差一些,这表明序列推荐算法在对比学习任务的Encoder选择中应该有比较高的优先级。其次,SASRec、TISASRec、BERT4Rec这3个模型在每个数据集上的表现均强于传统的RNN架构算法和基于马尔科夫链的推荐算法,这是由于自注意力机制的编码器具有更多的参数,可以更好的捕获序列特征。CSFTRec在大部分情况下要表现出更强的性能,且训练过程中投入的数据越多,CSFTRec的性能提升越高,这是由于对比学习过程中使用了数据增强,虽然所有模型在同样的数据集上进行训练,但CSFTRec实际上要比监督学习任务的训练数据更多。
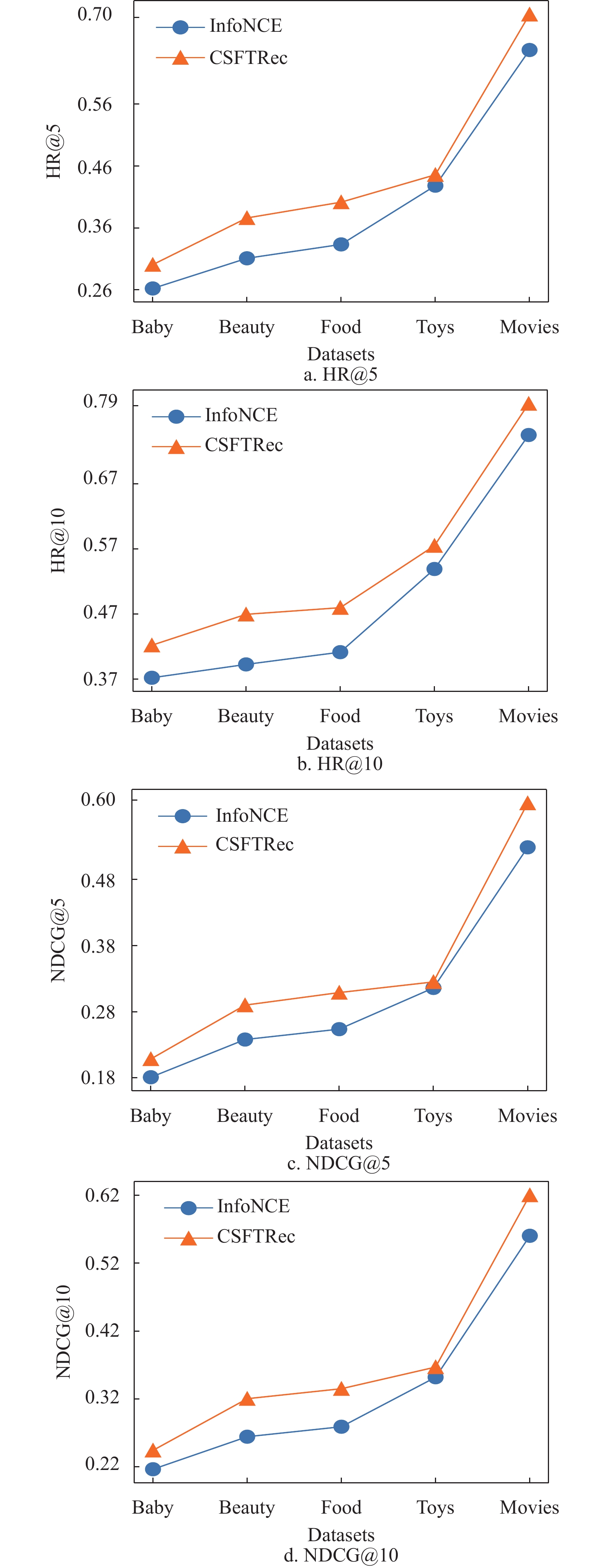
DataSets Methods Metric HR@5 HR@10 NDCG@5 NDCG@10 Baby POP 0.204 6 0.314 4 0.131 9 0.167 1 BPRMF 0.229 1 0.339 8 0.151 2 0.186 8 FPMC 0.260 6 0.371 4 0.181 2 0.216 8 ComiRec 0.267 9 0.388 5 0.180 0 0.218 9 GRU4Rec 0.291 9 0.415 8 0.197 9 0.237 9 CSFTRec 0.300 8 0.422 2 0.208 7 0.244 3 Beauty POP 0.173 5 0.290 0 0.114 1 0.151 6 BPRMF 0.363 6 0.464 9 0.264 3 0.2971 FPMC 0.344 8 0.428 6 0.264 8 0.291 6 ComiRec 0.367 5 0.479 0 0.264 6 0.300 8 GRU4Rec 0.326 8 0.438 3 0.234 2 0.270 1 CSFTRec 0.376 2 0.469 7 0.290 1 0.320 4 Food POP 0.206 5 0.334 7 0.130 1 0.171 3 BPRMF 0.354 7 0.460 9 0.248 4 0.282 9 FPMC 0.359 1 0.438 1 0.279 6 0.305 1 ComiRec 0.366 3 0.474 4 0.259 6 0.294 7 GRU4Rec 0.362 6 0.472 4 0.257 8 0.293 3 CSFTRec 0.401 7 0.479 9 0.309 1 0.335 1 Toys POP 0.338 5 0.408 3 0.276 6 0.299 1 BPRMF 0.376 0 0.460 1 0.281 9 0.309 2 FPMC 0.405 1 0.491 0 0.315 1 0.342 9 ComiRec 0.437 6 0.527 7 0.338 0 0.367 2 GRU4Rec 0.395 8 0.513 3 0.284 9 0.323 0 CSFTRec 0.445 9 0.575 1 0.325 2 0.367 0 Movies POP 0.635 3 0.757 1 0.500 7 0.540 2 BPRMF 0.456 0 0.563 1 0.373 9 0.452 3 FPMC 0.630 0 0.746 1 0.498 3 0.536 0 ComiRec 0.661 3 0.770 4 0.524 1 0.559 5 GRU4Rec 0.601 3 0.734 5 0.451 5 0.494 7 CSFTRec 0.704 8 0.793 1 0.595 5 0.620 3 DataSets Methods Metric HR@5 HR@10 NDCG@5 NDCG@10 Baby SASRec 0.290 8 0.409 9 0.202 9 0.241 3 FMLP-Rec 0.282 8 0.393 1 0.196 6 0.232 1 CSFTRec+ 0.297 1 0.417 9 0.205 3 0.247 7 CSFTRec 0.300 8 0.422 2 0.208 7 0.244 3 Beauty SASRec 0.367 3 0.460 1 0.277 6 0.307 5 FMLP-Rec 0.371 1 0.464 4 0.281 0 0.311 0 CSFTRec+ 0.368 3 0.459 2 0.280 1 0.309 8 CSFTRec 0.376 2 0.469 7 0.290 1 0.320 4 Food SASRec 0.385 5 0.474 2 0.287 6 0.316 4 FMLP-Rec 0.390 2 0.482 0 0.293 6 0.322 5 CSFTRec+ 0.389 2 0.477 4 0.293 8 0.322 3 CSFTRec 0.401 7 0.479 9 0.309 1 0.335 1 Toys SASRec 0.368 3 0.450 5 0.290 4 0.316 9 FMLP-Rec 0.406 2 0.488 8 0.320 6 0.347 3 CSFTRec+ 0.419 3 0.510 2 0.323 3 0.352 8 CSFTRec 0.445 9 0.575 1 0.325 2 0.367 0 Movies SASRec 0.694 9 0.781 6 0.572 9 0.601 2 FMLP-Rec 0.708 4 0.785 6 0.580 6 0.609 4 CSFTRec+ 0.701 1 0.790 8 0.578 1 0.607 2 CSFTRec 0.704 8 0.793 1 0.595 5 0.620 3 此外,图2为CSFTRec与InfoNCE的训练结果比较,明显可见InfoNCE的效果不如引入了Context-Context损失的联合训练任务,且CSFTRec有着更快的收敛速度,这要归功于序列进入Encoder之前的噪声过滤,使得自注意力机制能够更快的学习到序列特征,而不会过多的关注那些无意义的干扰。

-
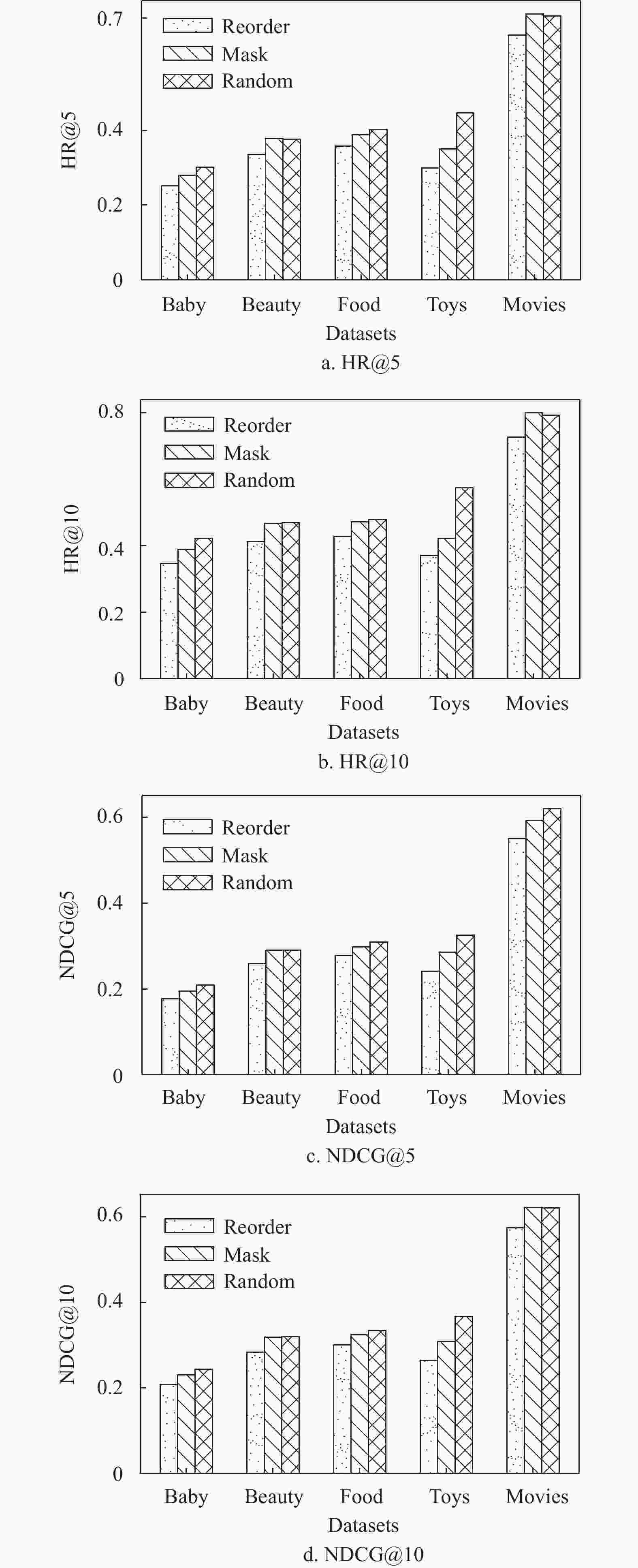
为了使CSFTRec的性能进一步提升,探究了不同的超参数对CSFTRec产生的影响。在无监督学习任务中,数据增强的方式是否合理会直接影响到模型的最终效果,因此将本文所提到的两种数据增强方式单独应用到CSFTRec中,将其在5个数据集上的表现与使用随机数据增强的CSFTRec进行对比。如图3所示,可以明显看出掩盖方式在每个数据集上的表现都要强于置换,这是由于掩盖会使自注意力机制去重点学习序列数据当中未被掩盖部分的序列特征,多次的随机掩盖,会使序列的每一个子序列特征可以被充分学习到,所以会有一个较好的性能表现。但从另一个方面来看,使用了混合数据增强方式的CSFTRec表现却又不输于掩盖,也就是说置换并没有拉低CSFTRec的性能,反而使其在大多数数据集上的表现要比随机掩盖更强,这也证明了使用两种数据增强方式混合处理数据的可行性。
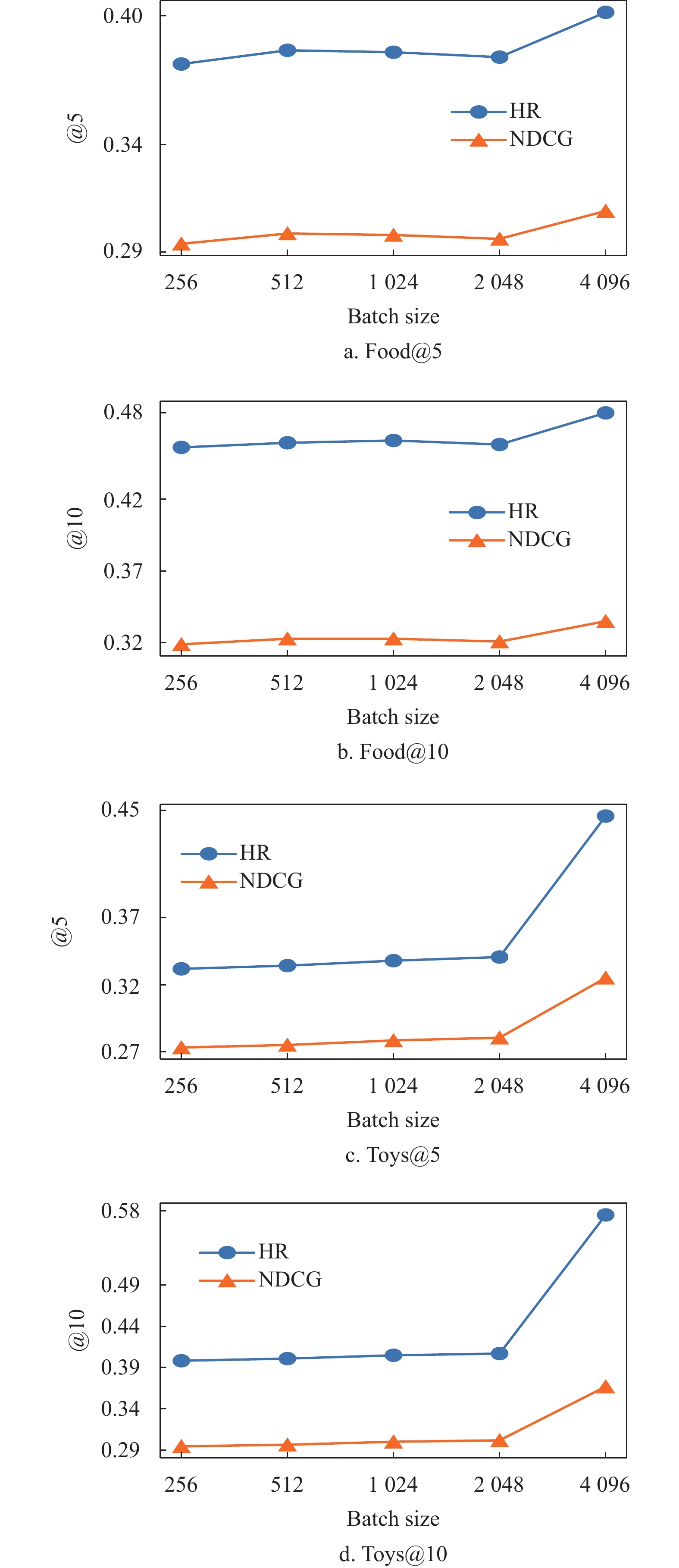
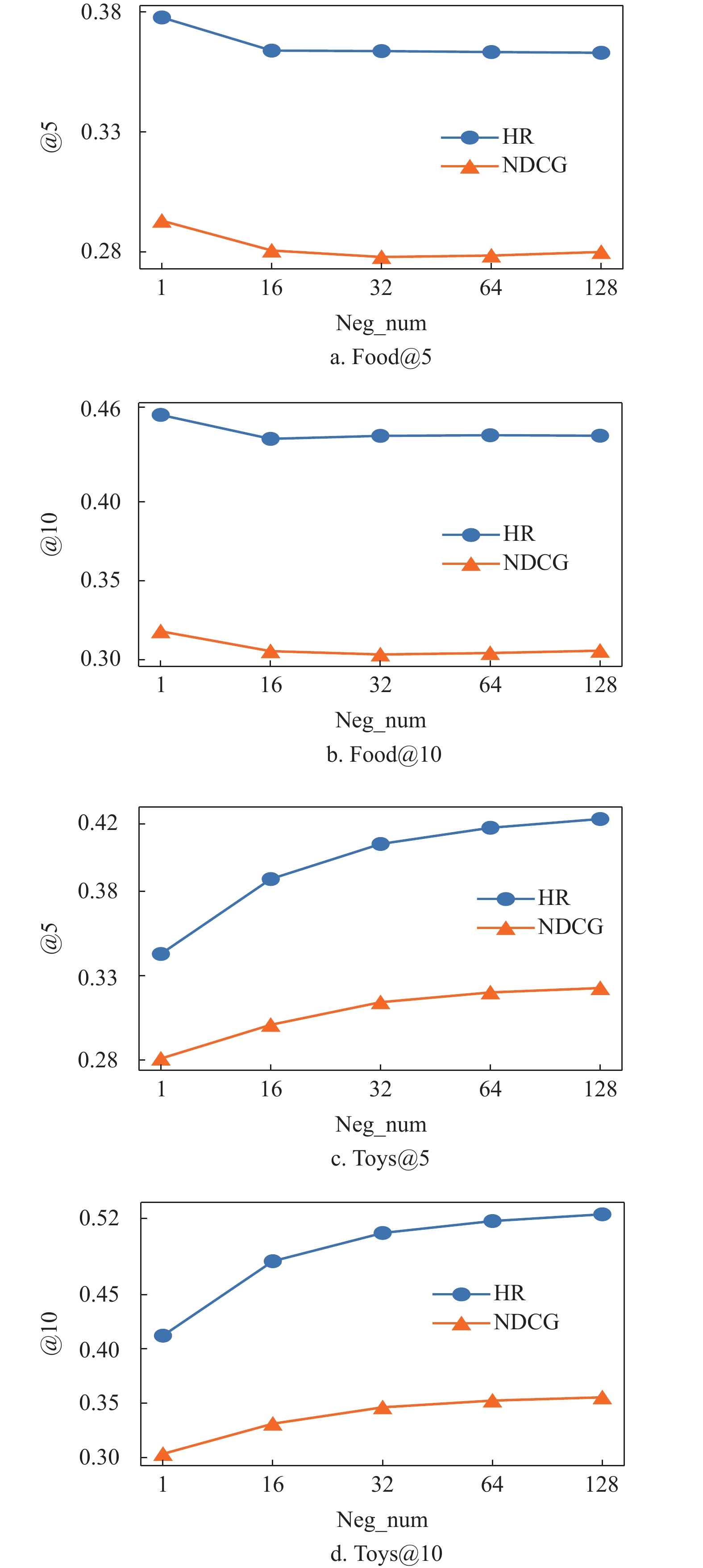
此外,在Food和Toys两个数据集上研究了BatchSize和负样本个数对模型的影响。图4为不同的BatchSize对CSFTRec的影响,可以看到CSFTRec更受益于较大的BatchSize,这是由于在Context-Context损失中,较大的训练Batch会提高多个序列共享一个目标的概率,从而使得CSFTRec有更好的表现。在图5中,随着负样本个数的增加,两个数据集上的表现大不相同。在小数据集上,只保留一个负样本可以最大化模型性能,但在大数据集上,模型却又受益于更多的负样本,这是由于联合训练任务在数据较少时更依赖于Context-Context损失,在数据较多时,才会逐渐从对比损失中获得训练增益。
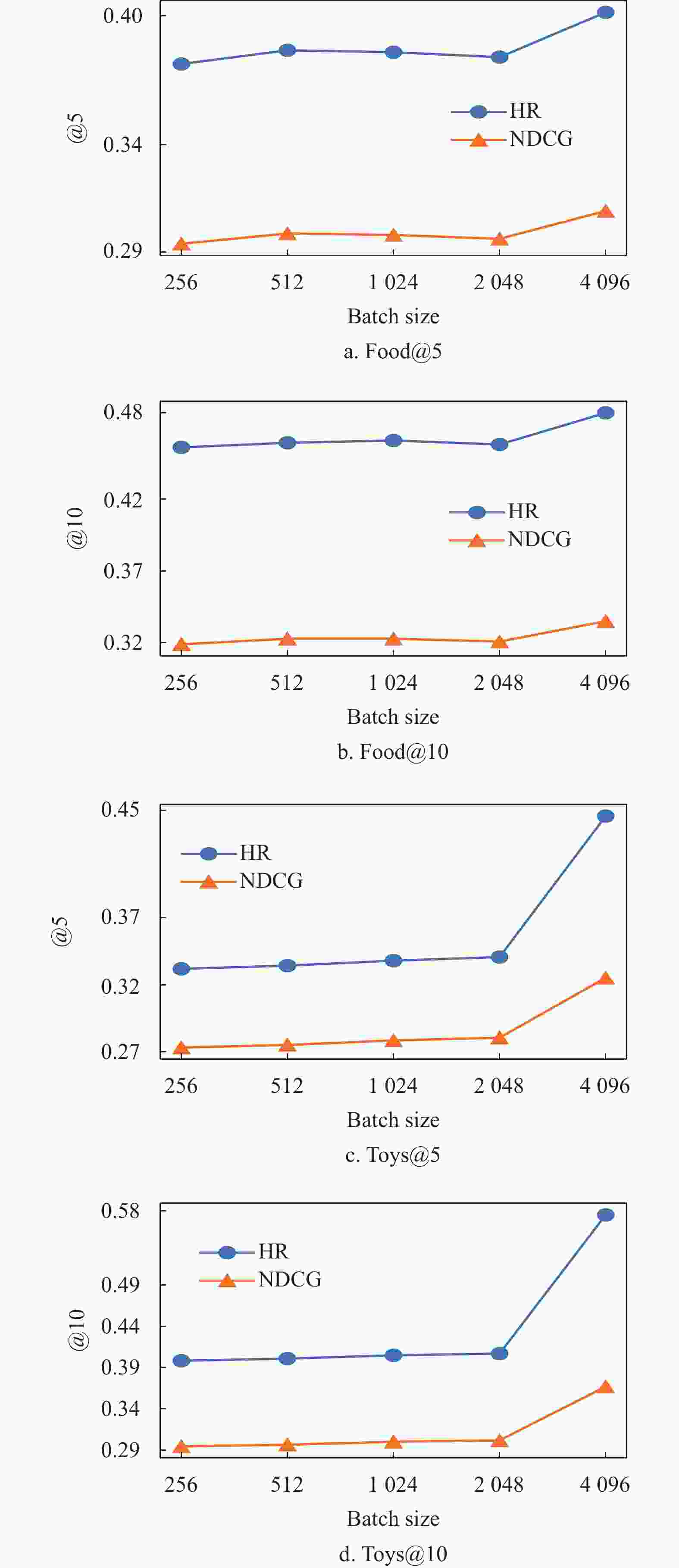
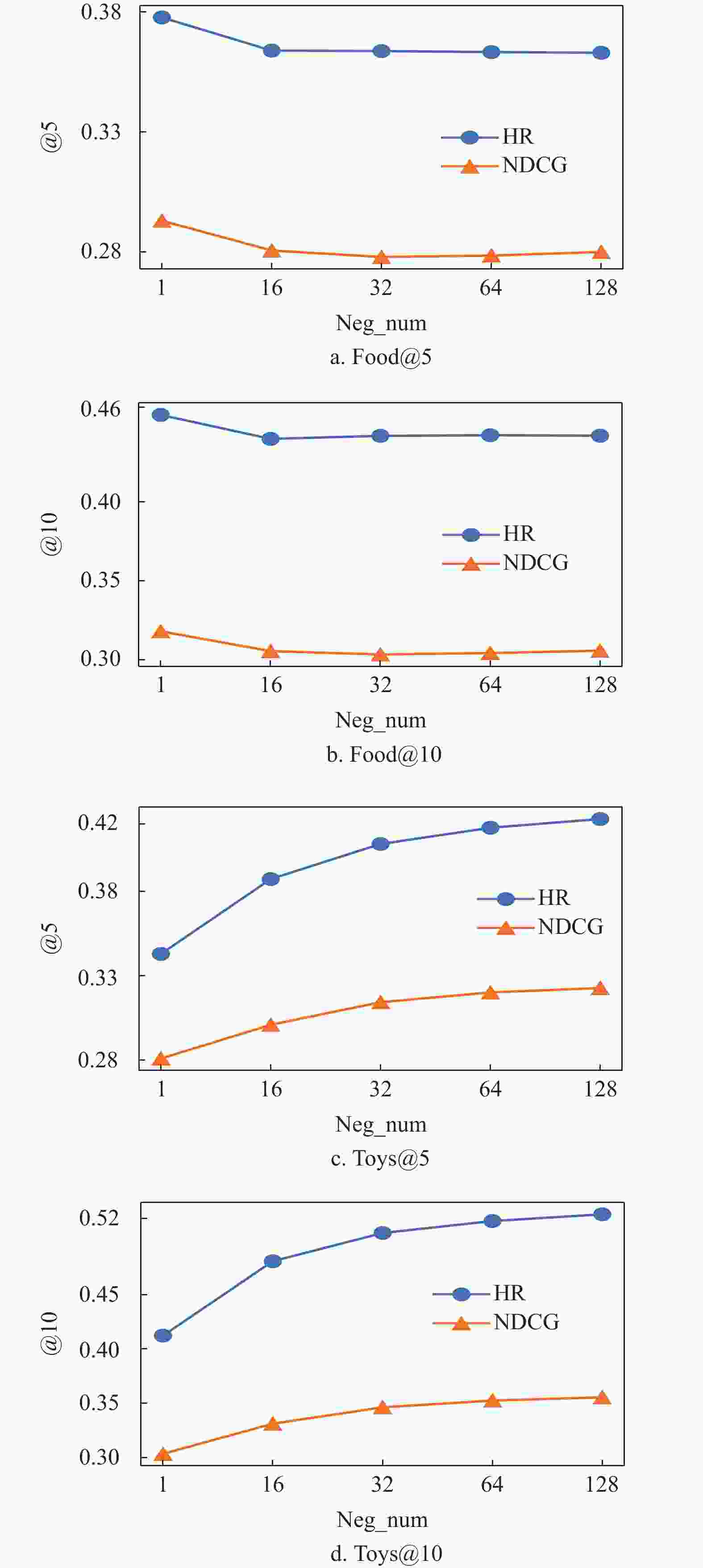
总体而言,在对比学习任务中,不论是数据增强方式还是BatchSize和负样本个数均会对模型有较明显的影响,如果选择了合理的参数配置,就可以保证模型逐渐收敛并获得一个较好的模型表现。
-
序列推荐算法的研究有着广泛的应用背景和实用性。针对现有序列推荐算法在对序列数据进行特征建模时容易受到噪声数据的影响,且传统的对比损失在推荐任务中表现不佳的问题,本文基于自注意力机制的编码器,使用傅里叶变换对序列数据进行噪声过滤,最大化编码器对序列数据的特征捕获能力,通过进一步引入Context-Context损失与由BPR推广的对比损失联合训练,提高推荐算法的性能。最后在5个亚马逊工业数据集上进行实验并与当下流行的算法模型进行对比,验证了本文所提出的序列推荐算法拥有较好的性能,对于对比学习在推荐算法领域中的应用有着重要意义。
Sequence Recommendation Based on Contrast Learning and Fourier Transform
doi: 10.12178/1001-0548.2022164
- Received Date: 2022-05-31
- Accepted Date: 2023-02-01
- Rev Recd Date: 2022-09-21
- Available Online: 2023-09-06
- Publish Date: 2023-07-07
-
Key words:
- contrastive learning /
- recommender algorithm /
- sequential recommendation /
- self-attention mechanism
Abstract: This paper proposes a sequence recommendation algorithm based on self-attention mechanism and Fourier transform, named CSFTRec. By filtering the noise in the original data, this algorithm maximizes the feature capturing ability of the self-attention mechanism on the sequence data. According to the characteristics of contrast learning, a new contrast loss is introduced on the basis of Bayesian personalized ranking for joint training, which can shorten the distance between different similar sequences. Experiments on eight public data sets show that CSFTRec converges faster and improves the recommendation accuracy by 3% to 5%, which indicates that CSFTRec is more suitable for processing sequence data.
| Citation: | ZHANG Shaodong, YANG Xingyao, YU Jiong, LI Ziyang, LIU Yansong. Sequence Recommendation Based on Contrast Learning and Fourier Transform[J]. Journal of University of Electronic Science and Technology of China, 2023, 52(4): 610-619. doi: 10.12178/1001-0548.2022164

|
























 DownLoad:
DownLoad: