 ISSN
ISSN 




-
随着居民生活水平的提高,用户对于电力供应的稳定性和吞吐量需求越来越高[1]。快速增长的用电需求带来的是复杂的电力资源调度和管理问题,而准确预测用户负荷对能源优化调度和管理有着非常重要的作用。
用户负荷预测,是指从已知的电力系统、经济、社会、气象等情况出发,通过对历史数据的分析和研究,考虑不确定性因素的影响,对未来用户负荷做出预先估计和推测[2-3]。用户负荷预测包括长期、中期和短期预测,一般将几小时到一周内的预测称为短期预测,中长期预测是指数周到未来几年这样较长时间的用户负荷预测[4]。短期负荷预测一直是研究热点,随着科技的发展以及用户用电需求的增加,短期用户负荷预测研究方法已从传统的回归过渡到了深度学习,预测精度已实现了显著提升[5-7],本文同样聚焦于短期负荷预测。
传统用户负荷预测方法主要为线性回归和时间序列回归分析法。线性回归方法通过分析大量的相关变量和负荷数据的对应关系,并建立相应的数学模型得到相关变量和负荷数据的内在联系,从而对负荷数据进行预测[8]。该方法在确定的参数下可以快速地对负荷数据进行预测,缺点是难以确定一个精准的模型描述相关变量和负荷数据之间的关系[9]。时间序列回归方法将用户历史负荷数据看作一个与时间有关的变量,构建回归模型来预测未来负荷数据的趋势,如AR,MA,ARIMA等回归模型[10-12]。
现代智能优化算法包括传统的机器学习算法和深度学习算法。传统机器学习算法可以解决非线性和高维中的分类和回归问题[13],如支持向量机、决策树、贝叶斯算法、K近邻算法(K-nearest neighbors, KNN)、随机森林算法。其中森林算法通过构造多个决策树对同一个问题进行决策,并对样本和特征进行随机的选取,研究发现随机森林模型呈现出更准确的预测效果[14]。
深度随机森林实际上是级联过程,即利用前一层次预测的结果和输入特征相连接构成新的输入特征,可以达到和神经网络同等优秀的模型,并且计算开销小、超参数少、效率高[15]。文献[16]发现深度森林算法的负荷预测结果比传统机器学习算法预测结果更准,但并没有深入研究和对比其他深度学习算法的预测结果,同时没有分析参数对预测结果的影响。
与深度随机森林网络模型不同,深度神经网络模型主要通过模拟人脑神经元的工作过程建立多层网络模型,通过对数据的学习进行预测。神经网络具有很强的学习能力和容错率,但需要大量的数据和算力才能训练好一个模型。文献[17]利用深度神经网络对用户短期负荷进行预测,研究结果表明深度神经网络比浅层神经网络和传统机器学习算法预测得更准确。文献[18]发现长短记忆循环神经网络(long short-term memory, LSTM)比传统机器学习算法预测得更准确。
此外,学者们还相继提出了结合多种算法的混合模型,如基于随机森林和LSTM算法的混合算法[19]、LGBM-XGB-MLP混合算法[20]以及混合ARIMA回归模型和LSTM循环神经网络模型算法[21]。尽管混合算法通常表现出较好的预测结果,但训练时间较长。大量研究揭示深度森林网络不仅训练时间短,同时预测效果也很好。虽然已有研究发现深度森林算法比传统机器学习算法能更准确地预测用户负荷,但是否比其他深度学习算法预测得更准确尚不清楚,同时也没有深入分析参数的影响[16]。
本文通过网络爬虫获取天气数据,并与2020年金华市企业负荷数据相结合,对用户负荷进行预测。采用深度随机森林算法,不仅与传统机器学习算法进行对比,也与多个深度学习算法进行了对比,同时也分析了各算法的参数对预测结果的影响。
-
用户负荷数据为金华市中小企业2020年1月1日—2020年12月31日全年366天的数据,数据包括供电单位、供电所、户名、用户地址、台区、终端局号、是否高危用户、受电容量(kVA)、电压等级(kV)以及每小时的功率(kW)。用户数量每天约3500户,找出全年都在数据集中的用户用于研究和预测用户负荷。
用户负荷与天气之间存在较强的关联,但上述数据中并不包含天气数据。为此,通过python网络爬虫,获取了相应的天气数据。天气数据包括日期、温度、天气、风力风向、空气质量信息。
-
1) 天气数据预处理。把最高温和最低温去掉摄氏度符号得到数值数据。天气、风力风向、空气质量指数3个特征,根据类别进行数值化处理。如天气有3类,那么将它们分别转换为0,1,2。同理,风力风向有两类,分别转换为0和1。空气质量指数只有一类,用数值0代替。
2) 用户负荷数据预处理。找出全年都在数据集中的用户,最后剩2449个。对于缺失的用户功率/负荷数据,采用后一个小时的数据进行填充。因为供电所、用户地址、台区、终端局号对预测结果没有影响,因此仅利用是否高危用户、受电容量、电压等级以及每小时的功率/负荷数据。
考虑到数据中数值的差异性,对数据进行标准化处理:
式中,
$ {x_{ij}} $ 代表第$ i $ 个特征的第$ j $ 个值;$ {\bar x_{ij}} $ 为标准化后的值;$ \mu ({x_i}) $ 和$ \sigma ({x_i}) $ 分别为第$ i $ 个特征$ {x_i} $ 的均值和标准差。 -
负荷预测误差指的是用户负荷的真实值和预测模型得到的预测值之间的差值,为了评估预测准确度,本文使用4种常用的回归预测评估指标:RMSE(均方根误差)、MAE(平均绝对误差)、R2(决定系数)、MAPE(平均绝对百分误差)。
1) RMSE用于衡量真实值和预测值之间的偏差,受异常值的影响较大,其公式如下:
2) MAE表示真实值和预测值的绝对误差的平均值,其公式如下:
3) R2表示回归模型的拟合程度,反应了预测值有多少百分比能用输入值描述,该值为0~1之间的数值,值越大拟合程度越好:
4) MAPE表示真实值与预测值误差的百分比:
式中,n为样本数量;
$ {y_i} $ 为真实值;$ {\hat y_i} $ 为预测值;$ \bar y $ 为样本真实值的平均值。RMSE、MAE对异常值敏感,通常使用R2来表示模型的拟合程度,采用MAPE来表示预测的误差,综合以上4个指标进行负荷预测误差的评价,更能体现模型的真实效果。 -
将金华市天气数据和用户历史负荷数据相结合,对用户负荷进行预测。把用户前1天负荷数据和天气数据作为输入特征,将当天用户负荷作为输出值,即365天的数据用于训练,最后1天的数据用于测试。输入数据为天气数据、受电容量、电压等级,输出数据为用户每小时对应的用电负荷数据。由于爬取的天气数据没有每小时的信息,将这一天的天气数据复制24份,即每小时的天气数据一致,从而构造出相同维度的输入特征。
为了对比深度随机森林算法的预测结果的准确度,本文引用几个经典的机器学习算法,包括SVM算法、KNN算法、Bayes算法、随机森林算法、以及BP和LSTM等深度神经网络算法。
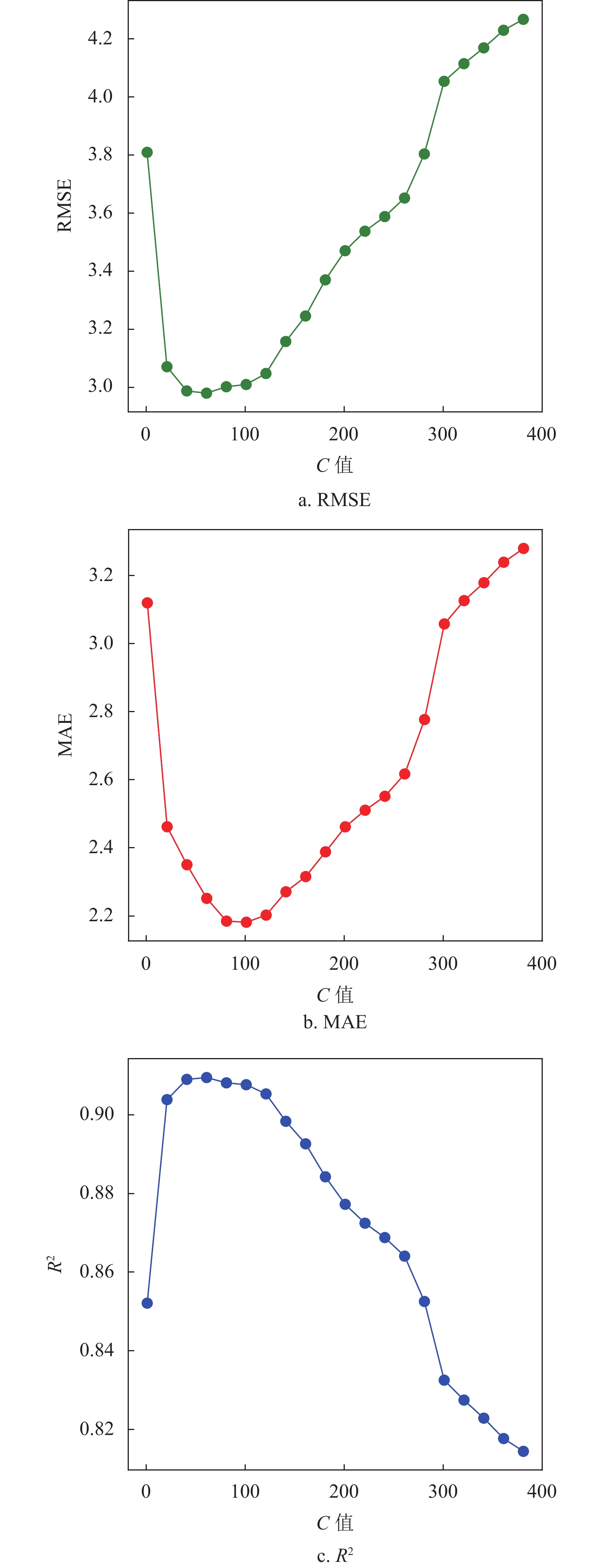
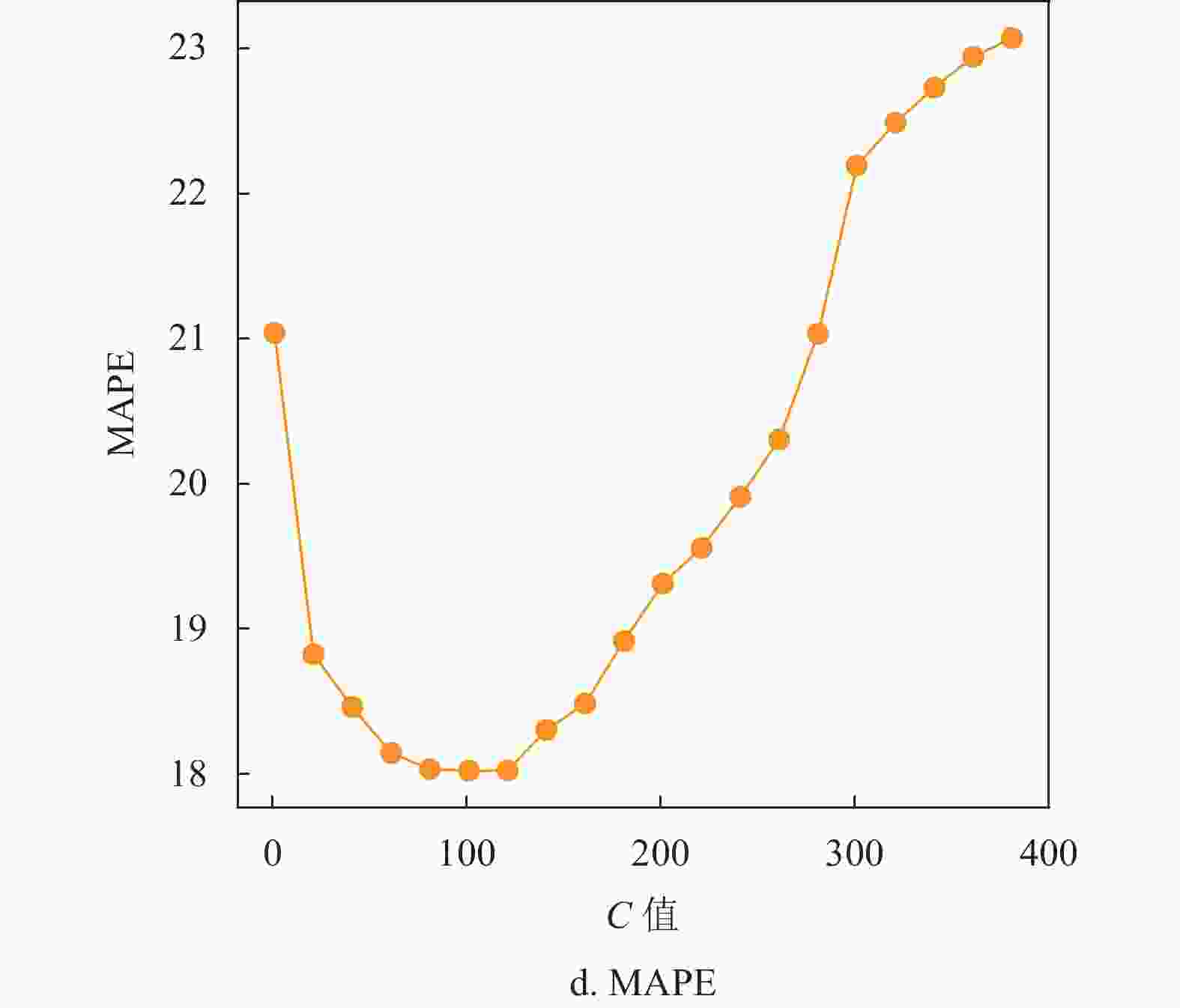
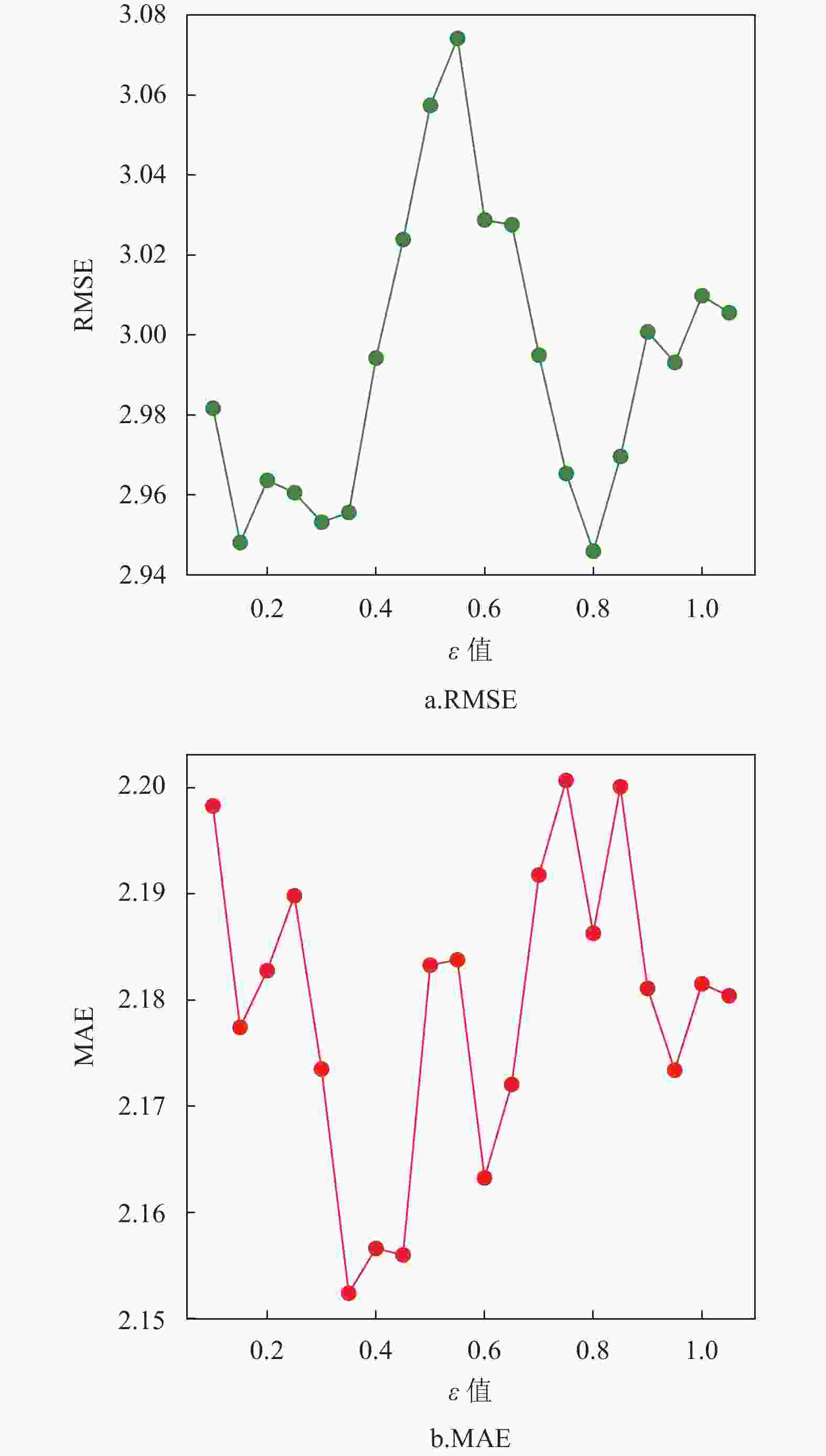
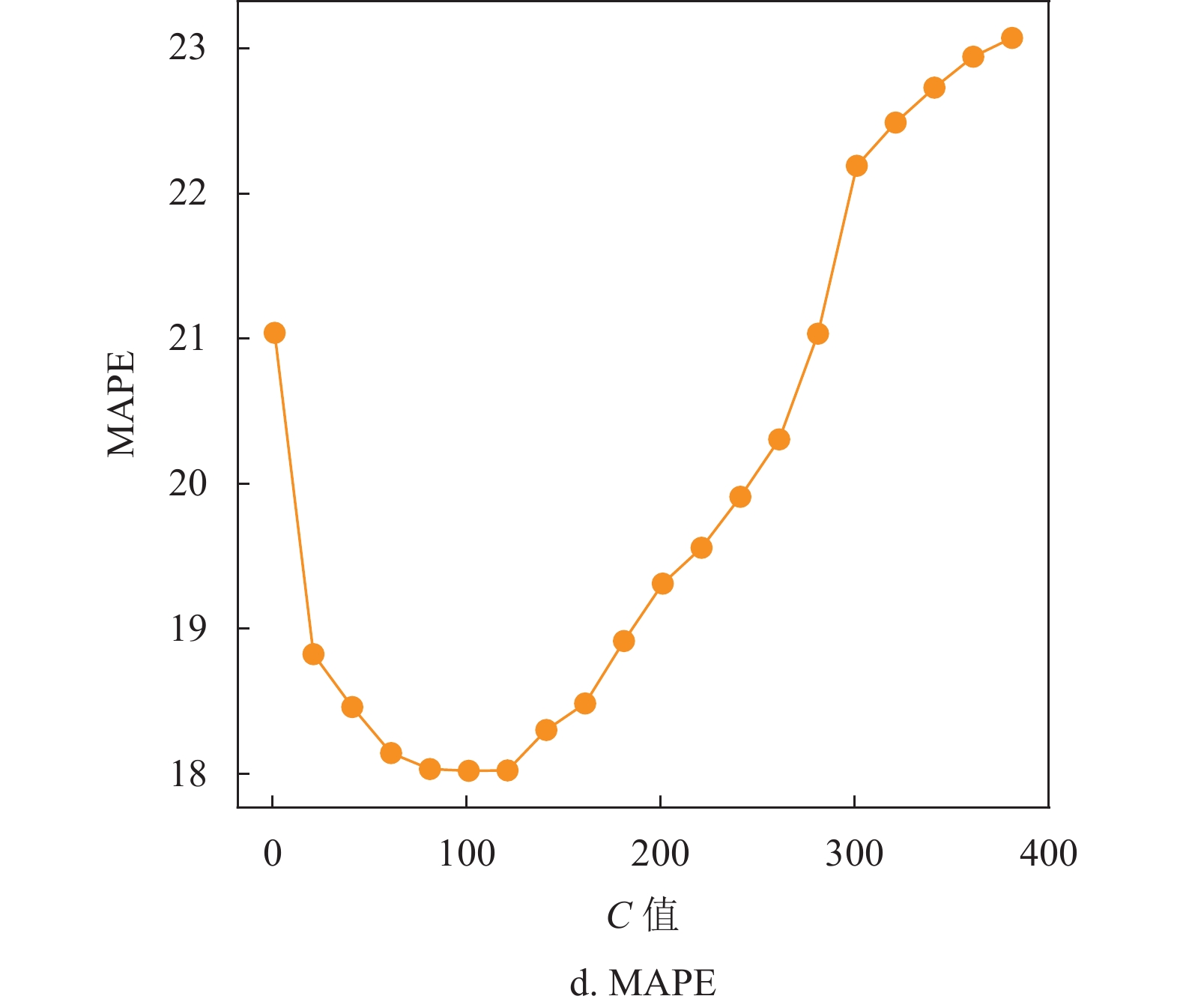
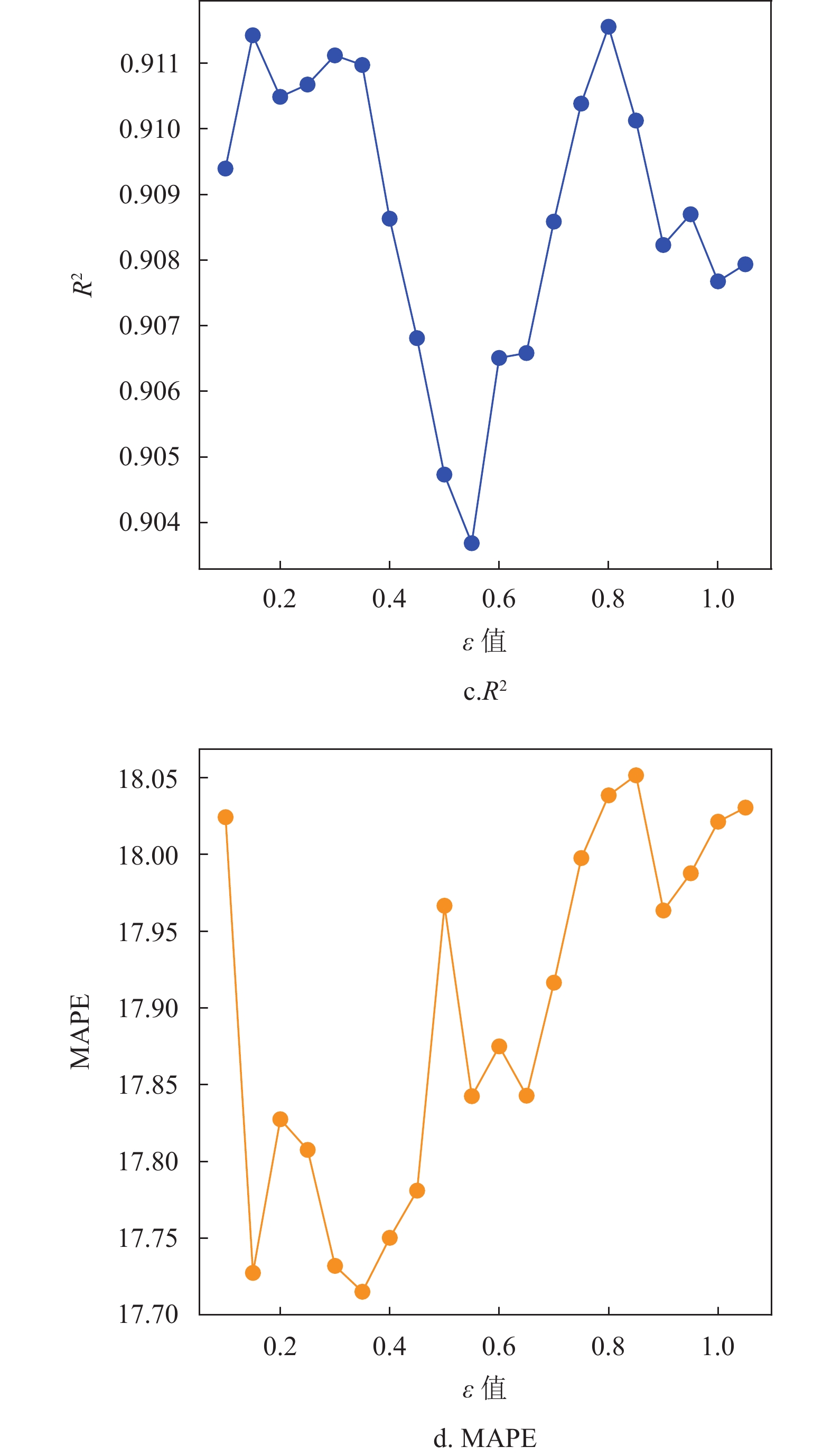
对于SVM回归算法,本文选取高斯核函数作为SVM中的核函数,高斯核函数在处理较高维度的问题上有优异表现,相比于其他核函数有更高的泛用性。图1显示了不同松弛变量C值评价指标的变化,图2显示了不同容忍偏差
$ \varepsilon $ 值评价指标的变化。可以看出,当C值在100附近时4种评估指标预测效果几乎都达到最优,$ \varepsilon >$ 0.35时评价指标呈抖动下降或上升,在部分指标上甚至优于取0.35的情况,在$ \varepsilon< $ 0.35时明显差于取0.35的情况。通过研究不同松弛变量C值和不同容忍偏差$ \varepsilon $ 值评价指标的变化,发现选取C约为100,$ \varepsilon $ 值约为0.35时SVM算法表现出最优的预测结果,此时相应的4个指标值分别为RMSE=2.955,MAE=2.152,R2=0.911,MAPE=17.715。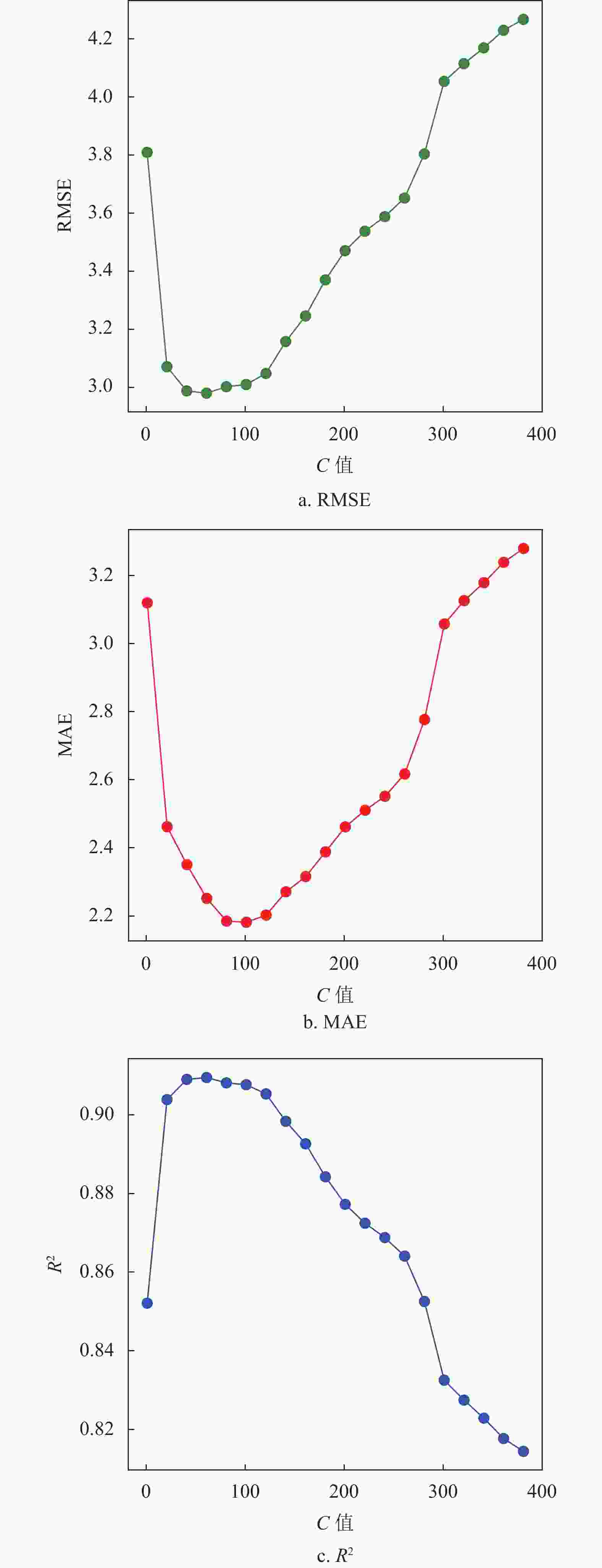
对于KNN算法,本文通过研究不同的参数k的用户负荷预测结果,发现k=6为最佳k参数取值,此时相应的4个指标值分别为RMSE=3.298,MAE=2.728,R2=0.899,MAPE=20.531。

对于贝叶斯岭回归算法,学习率参数
$ \alpha $ 和正则化参数$ \lambda $ 采用默认值$ {10^{ - 6}} $ ,4个指标的预测结果分别为RMSE=4.306,MAE=3.561,R2=0.811,MAPE=23.186。深度神经网络以神经元为基本单元,深度随机森林以随机森林为基本单元,整体结构又采取神经网络的结构,不仅有随机森林算力成本低的优点,而且有神经网络强大的特征提取能力。
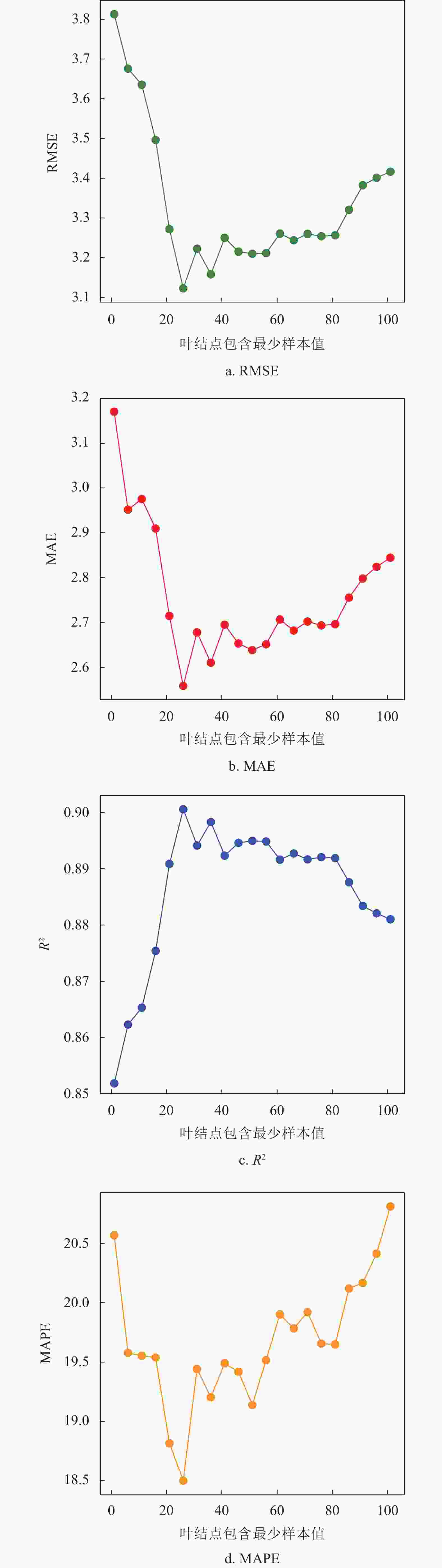
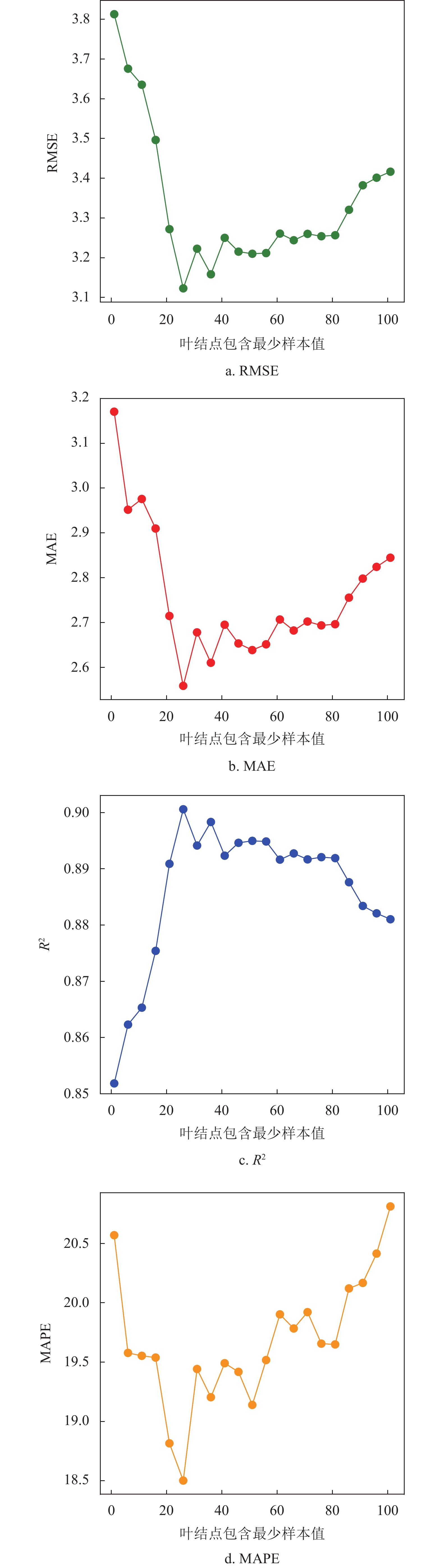
本文分别利用随机森林和深度随机森林对用户负荷做出预测。首先设置随机森林内决策树的数量为200颗,改变叶子节点包含样本的最小数,预测结果如图3所示。
基于随机森林的用户负荷预测,当超参数叶结点包含最小样本为25左右为最佳,设置深度随机森林每层两个,每个随机森林由100颗决策树构成,预测结果如表1所示。从表中看出深度随机森林预测结果相对更加准确。
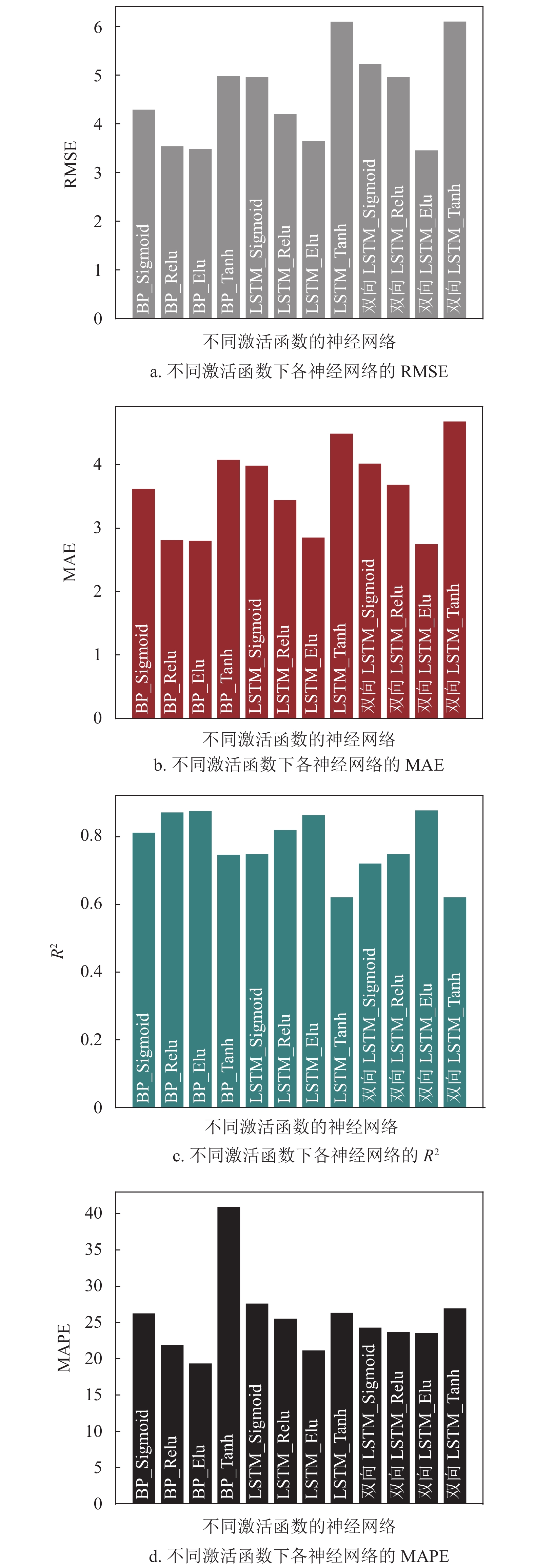
模型名称 RMSE MAE R2 MAPE 随机森林 3.123 2.559 0.901 18.502 深度随机森林 2.818 1.878 0.919 14.390 为了对比其他深度学习算法的预测结果,分别采用深度BP神经网络、LSTM和双向LSTM循环神经网络对用户负荷进行预测。本文采取4层神经网络结构,包含一个输入层、两个隐藏层、一个输出层,其中隐藏层每层由64个神经元组成,并分别采取Sigmoid、Relu、Elu、Tanh作为激活函数进行对比,在前向传播时随机使用80%的神经元,防止神经网络出现过拟合的现象,以MSE作为损失函数,并采用adam函数优化器对每次训练进行优化,每次训练随机采用80%的训练集数据,共循环训练100次,不同激活函数下预测结果如图4所示,表2为相应的预测结果值。
通过表2可以看出,LSTM在本实验的数据集上并没有表现出很好的预测效果,反而结构较为简单的BP神经网络表现更好。相比于其他激活函数,如Sigmoid函数和Tanh函数,当使用Elu激活函数时预测结果更准确。Sigmoid函数和Tanh函数属于软饱和函数,可能会出现梯度消失的现象,因此表现较差。尽管本文中LSTM预测用户负荷的表现不如BP,但采用双向LSTM激活函数为Elu时,除了MAPE较差外,其他指标都表现出了最好的预测性能。
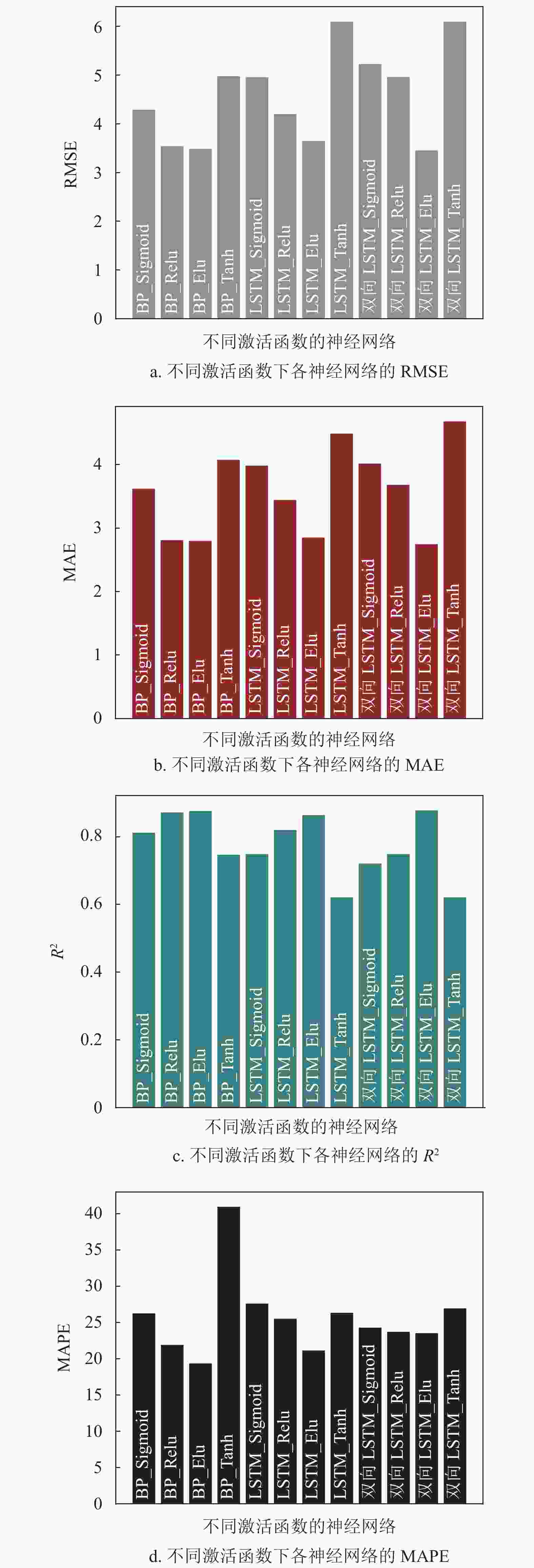
模型名称 激活函数 RMSE MAE R2 MAPE BP Sigmoid 4.292 3.618 0.812 26.271 BP Relu 3.543 2.810 0.872 21.928 BP Elu 3.489 2.800 0.876 19.378 BP Tanh 4.978 4.074 0.747 40.964 LSTM Sigmoid 4.959 3.982 0.749 27.632 LSTM Relu 4.200 3.441 0.820 25.540 LSTM Elu 3.647 2.850 0.864 21.157 LSTM Tanh 6.100 4.486 0.621 26.361 双向LSTM Sigmoid 5.229 4.014 0.721 24.310 双向LSTM Relu 4.964 3.681 0.749 23.726 双向LSTM Elu 3.458 2.747 0.878 23.541 双向LSTM Tanh 6.102 4.679 0.621 26.958 最后,整体对比了上述几种机器学习算法的预测结果,如表3所示。可以看出,在均方根误差上仅有Bayes岭回归模型有较大误差,其余模型都有不错的表现,尤其是SVM回归和深度随机森林效果最佳;在平均绝对误差上,可以明显看出Bayes岭回归模型相较于其他模型误差更大,此外,SVM回归和深度随机森林效果远优于其他模型;在R2上,各模型均有不错的表现,其中SVM回归、随机森林、深度随机森林的分数超过0.9分,略优于其他模型;在平均绝对百分误差上仍是SVM回归、深度随机森林模型效果最好,Bayes岭回归和双向LSTM神经网络较差。此外,也对比了各种算法的训练时长,从表中可以看出岭回归和KNN算法训练时长非常短,神经网络算法训练时长较长,深度随机森林算法训练时间居中。电脑配置为:Inter(R) Core(TM) i7-7700 CPU,3.6 GHz,16 G RAM,64位Win10操作系统。
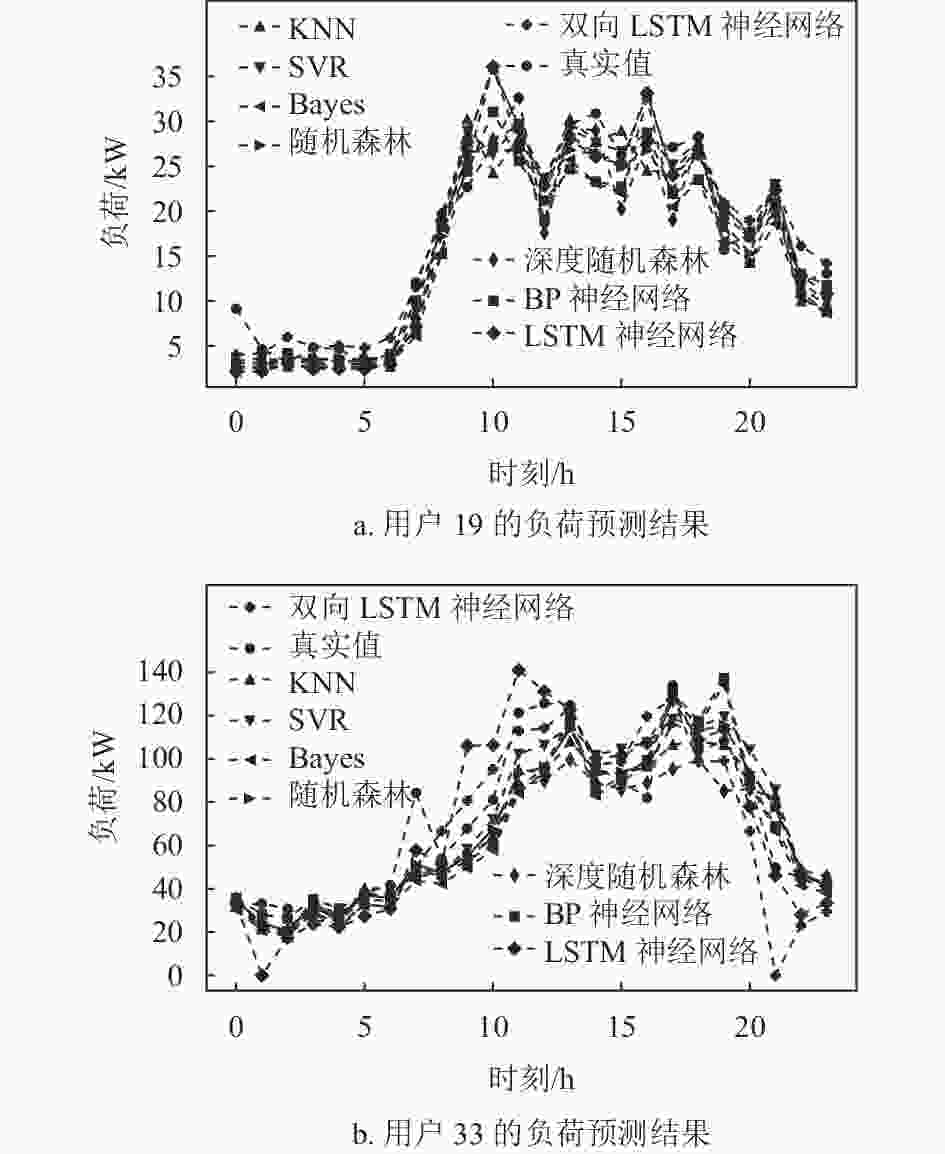
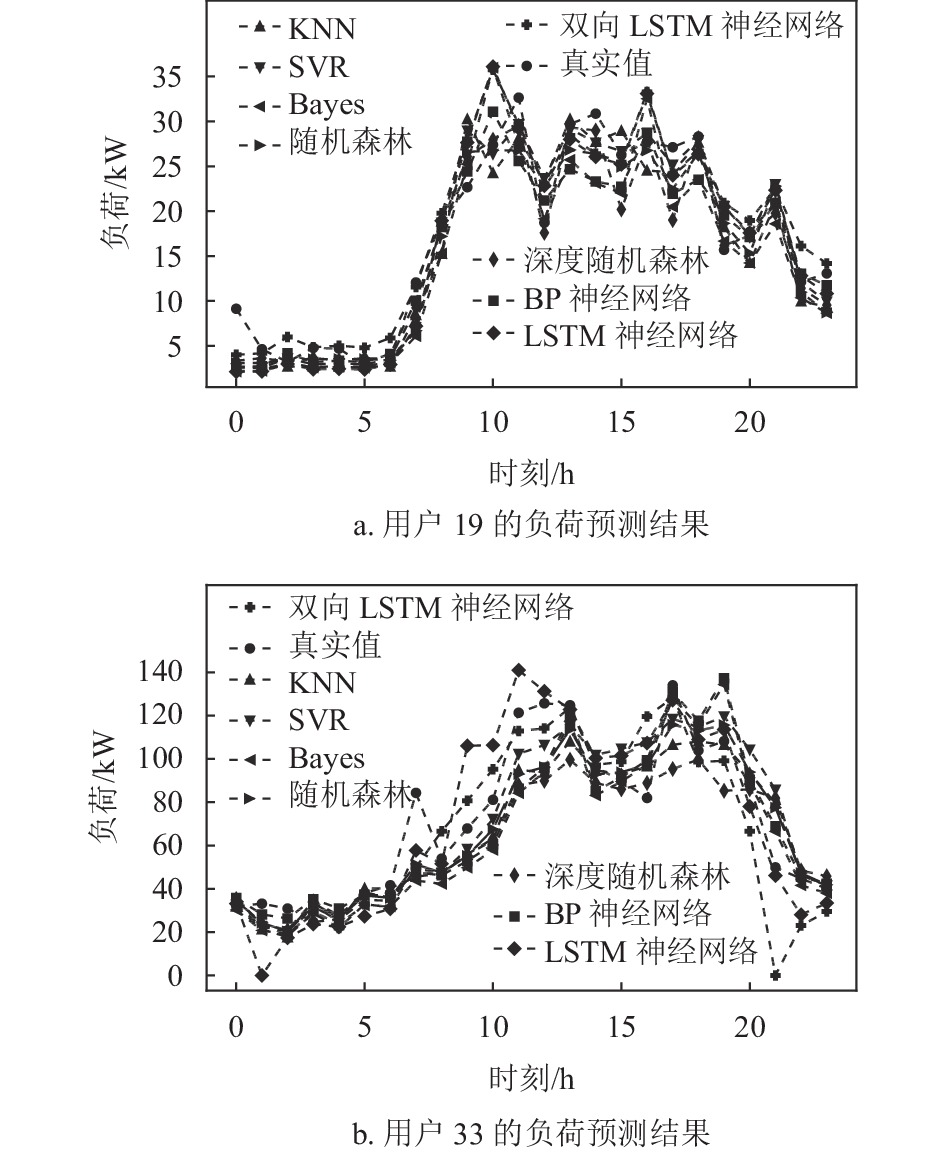
模型名称 RMSE MAE R2 MAPE 时长/s SVM回归 2.955 2.152 0.911 17.715 4.8 KNN算法 3.298 2.728 0.889 20.531 0.3 Bayes岭回归 4.306 3.561 0.811 23.186 0.1 随机森林 3.123 2.559 0.901 18.502 2.2 深度随机森林 2.818 1.878 0.919 14.390 4.7 BP神经网络 3.489 2.800 0.876 19.378 8.4 LSTM 3.647 2.85 0.864 21.157 21.4 双向LSTM 3.458 2.747 0.878 23.541 73.1 为了展示各种算法的预测结果与时间的变化关系,选择了两个用户,并在图5中给出了真实值和算法的预测值之间的关系。从图中看出白天负荷波动较大,尤其是8:00-20:00之间,此外,各类算法的预测趋势与真实值基本一致,难以看出哪种算法更准确,因此还需借助上述几个指标进行评估。
最后,为了研究本文算法的短期预测效果,给出了预测后3天和后5天的用户负荷的结果,如表4所示。
模型名称 后3天;后5天 RMSE MAE R2 MAPE SVR回归 4.060;4.938 2.779;3.426 0.861;0.794 35.653;54.923 Knn算法 4.600;4.392 3.344;3.349 0.821;0.837 39.541;52.813 Bayes岭回归 5.539;5.819 3.968;4.232 0.741;0.715 52.073;75.965 随机森林 4.398;4.859 3.194;3.612 0.837;0.801 45.540;75.610 深度随机森林 4.0468;4.448 2.846;3.206 0.862;0.833 30.724;46.691 BP神经网络 4.787;6.998 3.288;4.924 0.807;0.587 40.51;65.081 LSTM 7.472;9.614 5.804;6.891 0.761;0.726 53.801;62.126 双向LSTM 5.505;6.363 3.599;4.558 0.716;0.659 47.558;78.369 综上所述,在本实验数据集上深度随机森林效果最佳,其次是SVM回归和随机森林。Bayes岭回归各方面表现最差,不适用于本实验数据集的用户负荷预测。
-
本文以金华市用户负荷数据为例,通过爬取以及分析金华市天气信息和用户负荷数据,并借助RMSE、MAE、R2、MAPE这4个评价指标,使用深度随机森林算法对用户负荷进行预测。通过与其他多种预测算法结果对比,发现深度随机森林算法表现出更好的预测效果。
尽管本文爬取的天气数据没有每小时的信息,却能较好地预测用户负荷。如果能挖掘出每小时的天气数据,应该能得到更好的预测结果。不少研究发现混合多个机器学习算法有望获得更好的预测准确率,这也是我们下一步的研究方向。此外,如果将用户按行业分类,对每个行业分别训练和预测可能会提升预测结果。 最后,本文仅研究了用户在全年都有的数据,忽略了新用户稀疏数据的影响,采用对抗网络模型[22]可以较好地解决这个问题。
Short-Term User Load Forecasting Based on Deep Random Forest: Take Jinhua City as an Example
doi: 10.12178/1001-0548.2022172
- Received Date: 2022-06-06
- Accepted Date: 2023-02-01
- Rev Recd Date: 2022-10-27
- Available Online: 2023-05-26
- Publish Date: 2023-05-28
-
Key words:
- deep random forest algorithm /
- machine learning /
- short-term load forecasting /
- weather information
Abstract: By crawling weather data and combining with user load data in Jinhua City, a deep random forest algorithm is introduced to implement short-term user load forecasting. With four evaluation indicators, by comparing the support vector regression algorithm, the K-nearest neighbor algorithm, the Bayesian ridge regression algorithm, the random forest algorithm, and several neural network algorithms, it is found that the deep random forest algorithm has the best performance, and followed by the support vector regression. However, the neural network algorithm performed mediocre on this dataset.
| Citation: | HU Zhaolong, HU Junjian, PENG Hao, HAN Jianmin, ZHU Xiangbin, DING Zhiguo. Short-Term User Load Forecasting Based on Deep Random Forest: Take Jinhua City as an Example[J]. Journal of University of Electronic Science and Technology of China, 2023, 52(3): 430-437. doi: 10.12178/1001-0548.2022172

|





















 DownLoad:
DownLoad: