 ISSN
ISSN 





-
随着各应用领域的数据量呈爆炸式增长,物理世界、人类社会和网络空间中的数据不断连接和融合,催生了大数据时代的到来[1]。大数据时代给人们的生活和工作带来了无限的发展机遇,也引发了前所未有的挑战。一方面,通过对大数据的挖掘与分析,可以发现其中隐含的有价值的数据和信息;另一方面,大数据类型、结构、模式以及关系的复杂性是大数据区别于传统数据的根本所在,必将会带来不可预测的不确定性问题[2-3]。不确定性因素给处理大数据算法的准确性、高效性、安全性、鲁棒性带来了巨大挑战[4]。高效、安全、准确处理大数据所具有的复杂性和不确定性问题已经成为大数据知识发现的前提和关键。
现有的计算策略(如采样[5]、降维[6]、分治、特征提取[7]、分布式计算等)在处理具有复杂结构、超高维的大数据问题上需要消耗大量的计算资源。近年来兴起的增量学习[8] (Incremental Learning)通过处理连续传入的信息流实现新旧知识的整合、优化,进一步节约计算资源;粒计算[9] (Granular Computing) 通过将大数据中的信息粒化,将合适的粒度颗粒作为处理对象从而缩减数据规模,提高了解决大数据问题的质量和效率。然而,数据本身的不确定性和处理数据过程中的不确定性,不可避免地会导致这些计算策略的性能大大降低。值得注意的是,模糊集理论已经成为表示数据本身和处理数据过程中的各种不确定性的重要工具[10-11]:一方面,通过建立模糊规则减少原始数据中的不确定性[12];另一方面,直觉模糊集 (Intuitionistic Fuzzy Set, IFS) [13-14]引入犹豫度表示现实世界中的犹豫边界,能够更好地将存在于海量数据和各种类型数据转换中的不确定性以及模型学习计算中的不确定性定量、准确地描述。
量子计算是一种结合量子力学处理信息的方式,利用量子比特的存储能力和并行计算能力来提高处理大数据的计算效率,在处理大数据所具有的复杂性和不确定问题上有更大优势[15-16]。然而量子系统容易受到噪声干扰,这些噪声会影响量子比特和量子线路从而降低量子机器学习算法的性能[17]。在达到理想的纠错效果之前,参数化量子线路 (Parameterized-Quantum Circuit, PQC) 是一种实现量子算法和展示量子优势的具体方法,通过使用量子−经典混合系统找到问题的近似解[18-19]。
本文将“不确定性问题 + 直觉模糊集理论 + 量子计算”交叉融合,利用直觉模糊集理论易于刻画具有不确定性问题的优势,将大数据所具有的不确定性问题模糊化;引入量子计算理论,将模糊信息(即不确定性问题模糊化后的信息)量子化;以量子态作为信息处理单元,构建基于直觉模糊集理论的量子模糊信息管理数学模型(简称量子模糊信息管理数学模型),并给出了与此模型相关基础问题的定义。
-
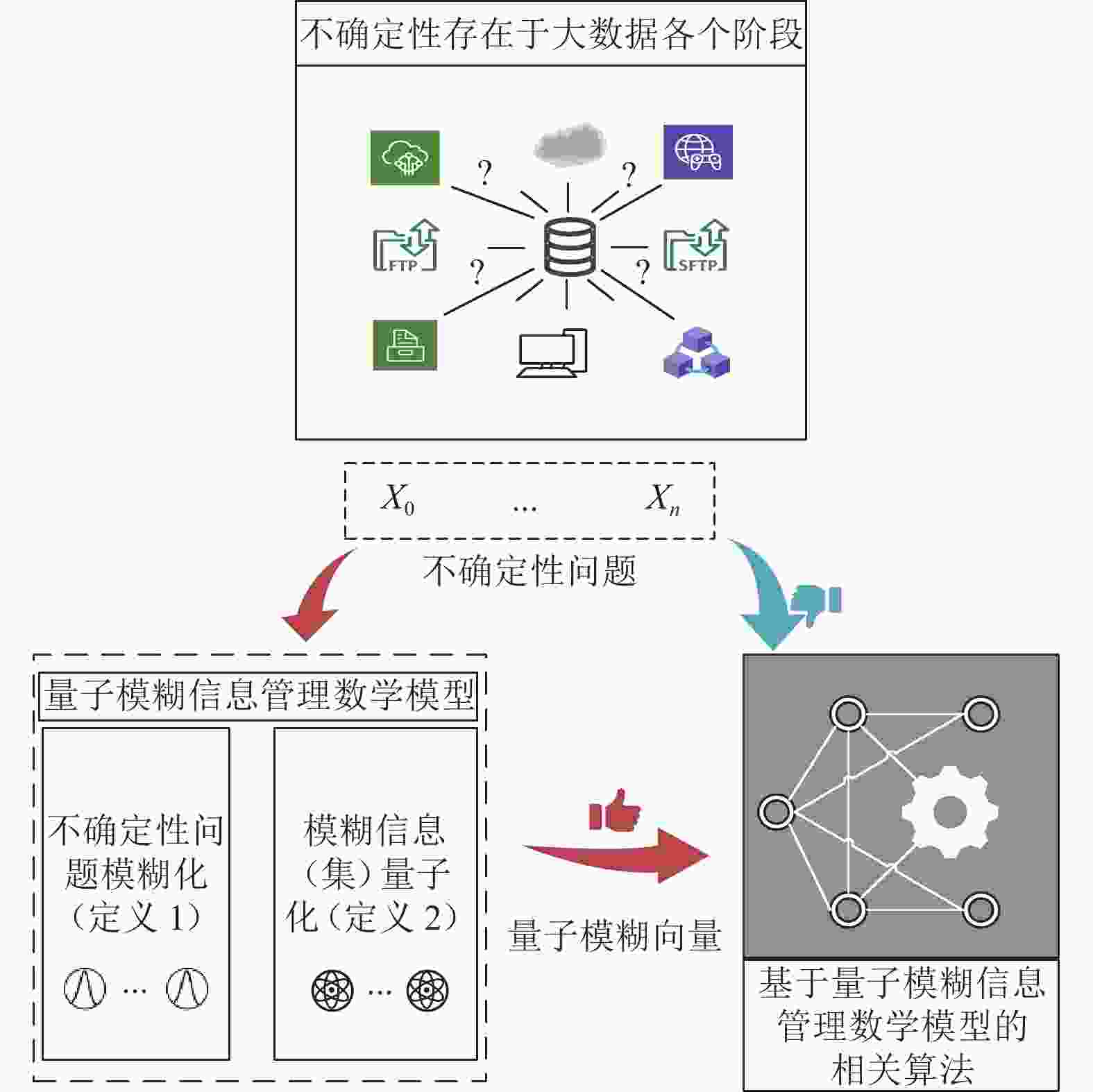
不确定性存在于大数据处理的各个阶段,简单的将数据作为量子机器学习算法的输入,不利于挖掘、分析出大数据所蕴含的信息。
为了高效处理大数据所具有的复杂性和不确定性问题,本文提出构建基于直觉模糊集理论的量子模糊信息管理数学模型,如图1所示,其具体思路:首先,通过直觉模糊集描述系统中的不确定元素,利用直觉模糊集中的隶属度、非隶属度和犹豫度来描述数据的不确定性,生成直觉模糊样本(即不确定性问题模糊化);然后,将直觉模糊样本编码为量子态得到量子模糊向量(即模糊信息量子化);最后,将量子模糊向量作为基于量子模糊信息管理数学模型的相关算法的输入。
-
设
$X$ 为量子模糊信息管理数学模型所研究的问题域,${x_i}(i = 1,2,\cdots, n)$ 表示所研究问题域中的不确定性元素。定义 1 不确定性问题模糊化:设
$X$ 为非空集合,$X$ 上的一个直觉模糊集定义为[21]:式中,
${\mu _A}({x_i}):X \to [0,1]$ ;${\nu _A}({x_i}):X \to [0,1]$ ,对$\forall {x_i} \in X$ ,有$0 \leqslant {\mu _A}({x_i}) + {\nu _A}({x_i}) \leqslant 1$ ,${\mu _A}({x_i})$ 为${x_i}$ 对直觉模糊集$A$ 的隶属度,${\nu _A}({x_i})$ 为${x_i}$ 对直觉模糊集$A$ 的非隶属度。由于专家在对不确定元素分配隶属函数时会犹豫,直觉模糊集$A$ 中用犹豫度表示这种犹豫程度:${\pi _A}({x_i}) = 1 - {\mu _A}({x_i}) - {\nu _A}({x_i})$ ,${\pi _A}({x_i})$ 为${x_i}$ 对直觉模糊集$A$ 的犹豫度,也称为直觉模糊指数。 -
定义 2 模糊信息(集)量子化(隶属度函数量子化):设
${x_i}$ 为问题域中的第$i$ 个元素,描述${x_i}$ 与直觉模糊集$A$ 的关系(即隶属于$A$ ,非隶属于$A$ ,犹豫于$A$ ),可以用量子态(称为量子模糊信息)表示为:式中,
$ {\chi _1} = \sqrt {{\mu _A}({x_i})} $ ,${\chi _2} = \sqrt {{\nu _A}({x_i})} $ ,$ {\chi _3} = $ $ \sqrt {{\pi _A}({x_i})} $ ,$ {\chi _1}^2 + {\chi _2}^2 + {\chi _3}^2 = 1 $ ,$|k\rangle $ 是第$k$ 个计算基态。若把
$X$ 中的所有不确定性元素$ {x_i}(i = 1,2,\cdots, n) \in X$ 量子化,则整个问题域$X$ 量子化后的量子态可以表示为:式中,不失一般性,将
$ |j\rangle $ 中的基态表示为$ |0\rangle $ ,$ |1\rangle $ ,$ |2\rangle $ ,则${\beta _j} = \displaystyle\prod\limits_{i = 1}^n {h({j_i})} $ ,$h({j_i}) = \left\{ {\begin{array}{*{20}{c}} {\sqrt {{\mu _A}({x_i})} ,{j_i} = 0} \\ {\sqrt {{\nu _A}({x_i})} ,{j_i} = 1} \\ {\sqrt {{\pi _A}({x_i})} ,{j_i} = 2} \end{array}} \right.$ 。则式(3)可以表示为:式中,
$ {({\beta _j})^2} = {\left( {\displaystyle\prod\limits_{i = 1}^n {h({j_i})} } \right)^2} = {h^2}({j_1}) {h^2}({j_2}) $ $ \cdots {h^2}({j_n})$ 。问题域$X$ 与直觉模糊集$A$ 中的不确定性元素分为3种情况。1)当
$j = 1$ 时,即$|j\rangle $ 中所有态为$|0\rangle $ ,${({\beta _1})^2} = \displaystyle\prod\limits_{i = 1}^n {{\mu _A}({x_n})} $ ,${({\beta _1})^2}$ 是问题域$X$ 中所有元素都隶属于直觉模糊集$A$ 的程度,${({\beta _1})^2}$ 越大,问题域$X$ 隶属于直觉模糊集$A$ 的程度越大。2)当
$j = \dfrac{{{3^n} - 1}}{2} + 1$ 时,即$|j\rangle $ 中所有态为$|1\rangle $ ,${\Big( {{\beta _{\tfrac{{{3^n} - 1}}{2} + 1}}} \Big)^2} = \displaystyle\prod\limits_{i = 1}^n {{\nu _A}({x_i})}$ ,${\Big( {{\beta _{\tfrac{{{3^n} - 1}}{2} + 1}}} \Big)^2}$ 是问题域$X$ 中所有元素都不隶属于直觉模糊集$A$ 的程度,${\Big( {{\beta _{\tfrac{{{3^n} - 1}}{2} + 1}}} \Big)^2}$ 越大,问题域不隶属于直觉模糊集$A$ 的程度越大。3)当
$j = {3^n}$ 时,即$|j\rangle $ 中所有态为$|2\rangle $ ,$ {\left( {{\beta _{{3^n}}}} \right)^2} = \displaystyle\prod\limits_{i = 1}^n {{\pi _A}({x_i})} $ ,$ {\left( {{\beta _{{3^n}}}} \right)^2} $ 是问题域$X$ 中所有元素都犹豫于直觉模糊集$A$ 的程度,$ {\left( {{\beta _{{3^n}}}} \right)^2} $ 越大,问题域犹豫于直觉模糊集$A$ 的程度越大。因此,对于量子态
$|\alpha {\rangle _X} = \displaystyle\sum\limits_{j = 1}^{{3^n}} {{\beta _j}} |j\rangle $ ,如果$ j \to 1 $ ,可以判定问题域$X$ 隶属于直觉模糊集$A$ ;如果$ j \to \dfrac{{{3^n} - 1}}{2}{\text{ + }}1 $ ,可以判定问题域$X$ 不隶属于直觉模糊集$A$ ;如果$ j \to {3^n} $ ,可以判定问题域$X$ 犹豫于直觉模糊集$A$ 。由定义1和定义2可知,借助于直觉模糊集理论,把
$X$ 中具有不确定性问题的元素$ {x_i}(i = 1,2,\cdots $ $ ,n) $ 用模糊直觉理论的隶属度、非隶属度和犹豫度来描述(不确定性问题模糊化),比较客观地反映了不确定性元素的实际情况;同时结合量子计算处理复杂性和不确定性问题的高效率优势,将不确定性问题模糊化后的信息量子化,从而建立量子模糊信息管理数学模型。 -
定义 3 量子模糊向量:假定问题域
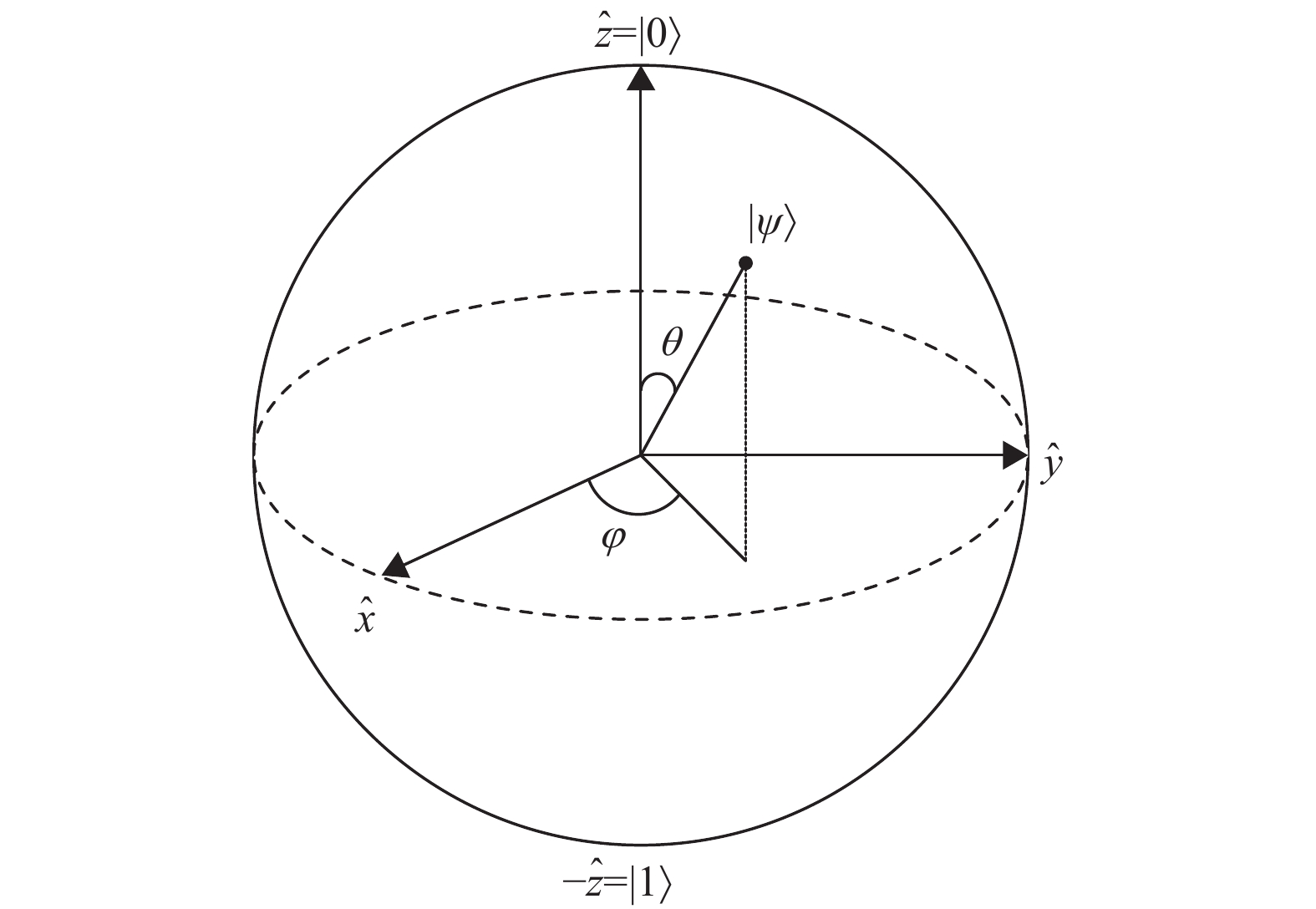
$X$ 中的第$j$ 个不确定元素为${x_j}$ ,且${\mu _A}({x_j})$ 为${x_j}$ 对直觉模糊集$A$ 的隶属度,${\nu _A}({x_j})$ 为${x_j}$ 对直觉模糊集$A$ 的非隶属度,${\pi _A}({x_j})$ 为${x_j}$ 对直觉模糊集$A$ 的犹豫度。则不确定元素${x_j}$ 量子化后的量子态用向量表示为:$ ( \sqrt {{\mu _A}({x_j})} ,\sqrt {{\nu _A}({x_j})} , \sqrt {{\pi _A}({x_j})} ) = (\cos {\phi _j} \sin {\theta _j}, $ $ \sin {\phi _j} \sin {\theta _j},\cos {\theta _j}) = ({x_j},{y_j},{z_j}) $ ,且$ {\mu _A}({x_j}) + $ $ {\nu _A}({x_j}) + {\pi _A}({x_j}) = {x_j}^2 + {y_j}^2 + {z_j}^2 = 1 $ 。实际上,量子模糊向量是三维球面上的任意一点。为了更有效地描述量子化后的模糊信息,利用密度矩阵来表示不确定元素
${x_j}$ 的量子模糊信息,则使用密度矩阵表示${x_j}$ 的量子模糊信息为:式中,
$ {\psi _A} = (\cos {\phi _j} - {\rm{i}}\sin {\phi _j}) \sin {\theta _j} $ ;$ {\psi _B} = (\cos {\phi _j} $ $ + i\sin {\phi _j}) \times \sin {\theta _j} $ ;${\sigma _x}$ ,${\sigma _y}$ ,${\sigma _z}$ 分别表示PauliX,PauliY和PauliZ矩阵。此时,量子模糊信息可以表示为:式中,
$0 \leqslant {\theta _j} \leqslant {\text π} $ ,$0 \leqslant {\phi _j} \leqslant 2 {\text π}$ 。对应量子态的Bloch球,如图2所示。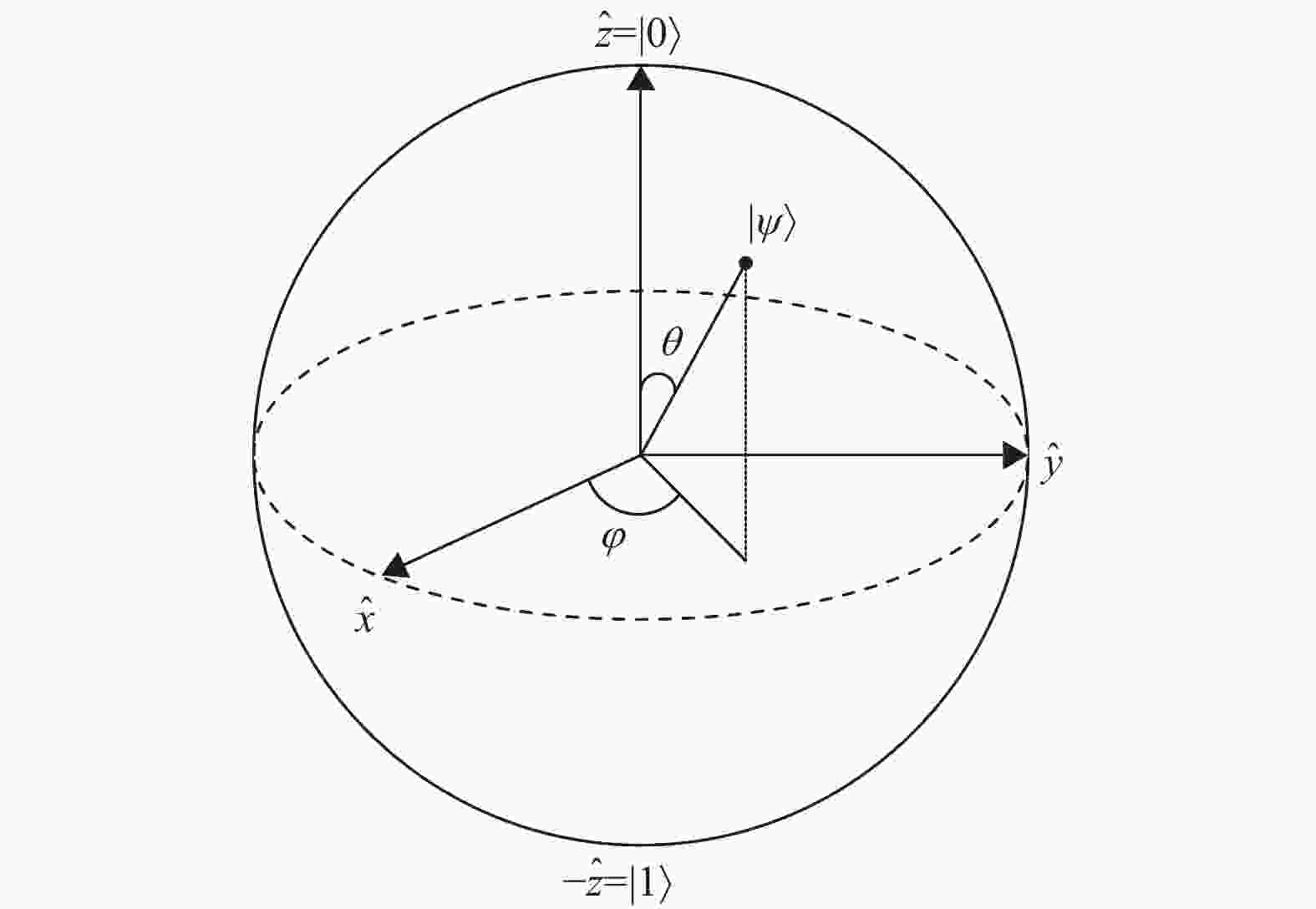
若
$X$ 中所有不确定元素转换成量子模糊信息后,可通过计算$ \cos \dfrac{{{\theta _j}}}{2} $ 和$ {{\rm{e}}^{i{\phi _j}}} \sin \dfrac{{{\theta _j}}}{2} $ 得到量子模糊信息的隶属函数如下:特别地,当犹豫度
${\pi _A}({x_j}) = {(\cos {\theta _j})^2} = 0$ ,即${\theta _j} = \dfrac{{\text π}}{2}$ 时,直觉模糊集就退化成Zadeh模糊集,则有:式中,
$ | + \rangle = \dfrac{{\sqrt 2 }}{2} (|0\rangle + |1\rangle ) $ ,$ | - \rangle = \dfrac{{\sqrt 2 }}{2} (|0\rangle - |1\rangle ) $ 。此时,可以通过计算角度$ {\phi _j} $ ,求得隶属度$ {\mu _A}({x_j}) = ( $ $ \cos {\phi _j}\sin {\theta _j}{)^2} $ 和非隶属度$ \nu {}_A({x_j}) = (\sin {\phi _j}\sin {\theta _j} $ $ {)^2} $ 。 -
定义 4 量子模糊信息熵:根据定义2,假设问题域
$X$ 中不确定元素${x_j}(j = 1,2,\cdots,n)$ 转换成量子模糊信息后可表示为$ {\rho _j} = |{\psi _j}\rangle \langle {\psi _j}| $ ,$ |{\psi _j}\rangle = \cos \dfrac{{{\theta _j}}}{2} $ $ |0\rangle + {{\rm{e}}^{i{\phi _j}}} \sin \dfrac{{{\theta _j}}}{2}|1\rangle $ ,则不确定性元素${x_j}$ 的量子模糊信息熵表示为:式中,若
$ {\lambda _{j,x}} $ 是$ {{\boldsymbol{\rho }}_j} $ 的特征值,则量子模糊信息熵的定义重新描述为:定义5 量子模糊信息熵:设
$ {\rho _i} $ 和$ {\rho _j} $ 是量子模糊信息中的密度算子,$ {\rho _i} $ 相对于$ {\rho _j} $ 的量子模糊信息相对熵定义为:量子相对熵是区分两个量子状态之间的度量,量子模糊信息相对熵将量子相对熵扩展到量子模糊信息领域。
-
定义 6 量子模糊集之间的迹距离:设
$B$ 和$C$ 是给定问题域$X$ 上的直觉模糊子集,将$B$ 和$C$ 中所有不确定元素量子化后得到量子态$ {\rho _B} $ 和$ {\rho _C} $ ,则量子模糊集之间的迹距离定义为:衡量两个量子状态有多接近,除了用迹距离作为距离度量,还可以采用保真度作为度量方法。
定义 7 量子模糊集之间的保真度:设
$B$ 和$C$ 是给定问题域$X$ 上的直觉模糊子集,将$B$ 和$C$ 中所有不确定元素量子化后得到量子态$ {\rho _B} $ 和$ {\rho _C} $ ,则量子模糊集之间的保真度定义为:在式(12)和式(13)中,
$ {\rho _{_B}} = |\alpha {\rangle _B}\langle \alpha {|_B} $ ,$ {\rho _{_C}} = |\alpha {\rangle _C}\langle \alpha {|_C} $ 。其中,$ |\alpha {\rangle _B} = \displaystyle\sum\limits_{j = 1}^{{3^{(B,n)}}} {{\beta _j}} |j\rangle $ ,$ |\alpha {\rangle _C} = \displaystyle\sum\limits_{j = 1}^{{3^{(C,n)}}} {{\beta _j}} |j\rangle $ ,$ (B,n) $ 与$ (C,n) $ 表示$B$ 和$C$ 中的不确定元素的个数。除了使用迹距离与保真度度量量子模糊集之间的距离,还可以使用Swap-test量子电路衡量量子态
$ {\rho _{_B}} $ 和$ {\rho _{_C}} $ 之间的相似程度[20],如图3所示。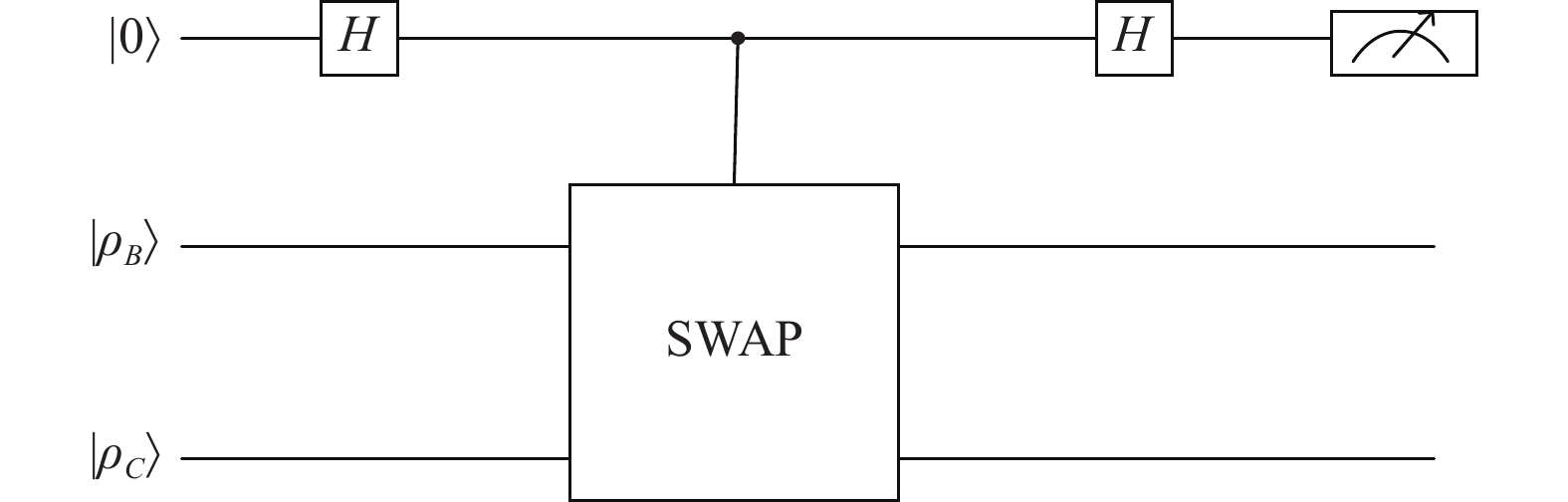
-
为了验证量子模糊信息管理数学模型的可行性、合理性和有效性,使用Iris数据集[21]在Pennylane[22]量子计算框架下进行实验。具体来说,基于量子模糊信息管理数学模型构建混合量子−经典模糊神经网络,通过模糊层将数据进行模糊化处理,减少数据中的不确定性;同时将数据编码为量子态(量子模糊向量)作为量子神经网络的输入。实验表明,基于量子模糊信息管理数学模型的量子模糊神经网络面对不确定性数据时的性能优于量子神经网络。
-
由于量子计算模拟环境使用的资源较多,在本实验中选取数据集中的前100个样本(即山鸢尾与杂色鸢尾)打乱后进行实验,选择30%的样本作为测试集,验证算法的准确性。对于数据的不确定性模拟,随机选取Iris数据集中的部分样本添加一定大小的噪声扰动。噪声样本中每个特征值都会根据扰动大小发生改变。本文选择噪声样本数量为
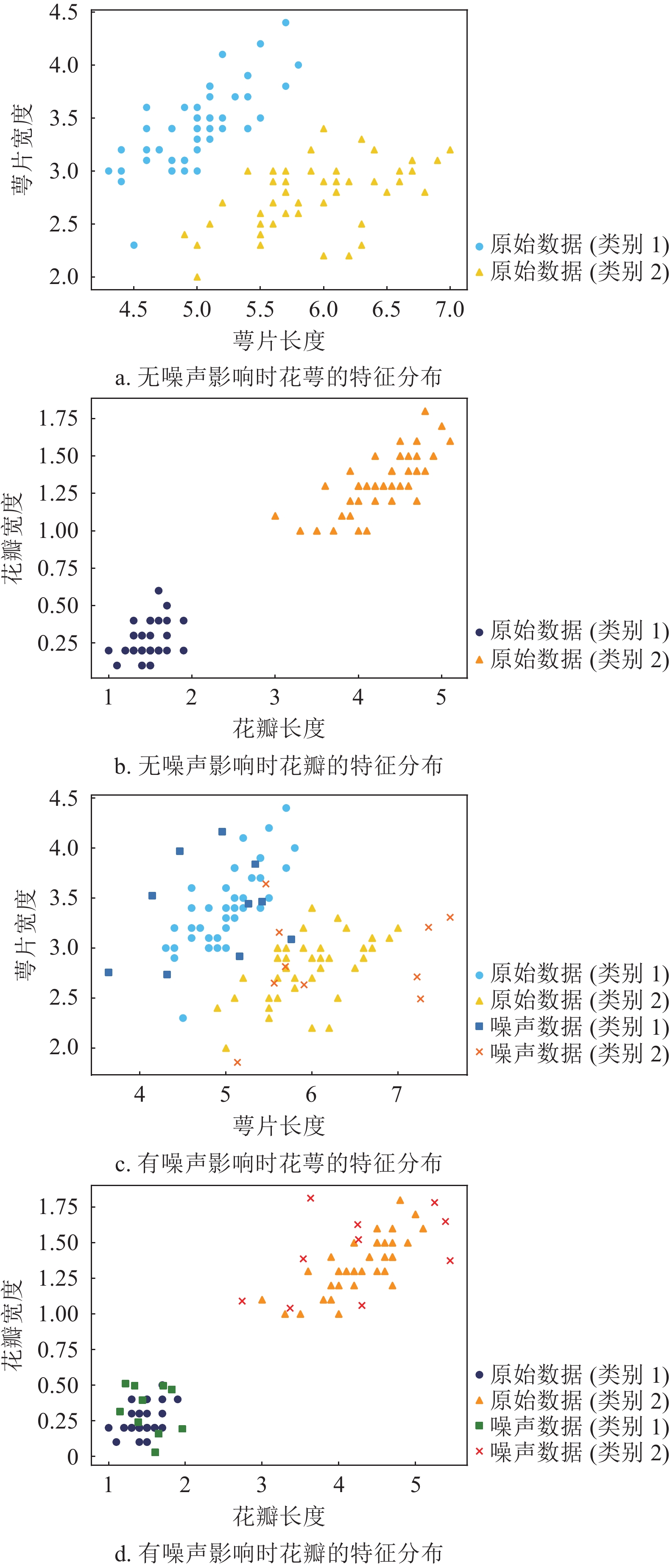
${\text{\{ }}10,15,20,25,30,35,40,45{\text{\} }}$ 、扰动大小为$ \{ 0.1, 0.2, 0.3,0.4,0.5\} $ 进行实验。图4展示了随机选择30个噪声样本,噪声扰动大小为0.2时,噪声对数据的影响。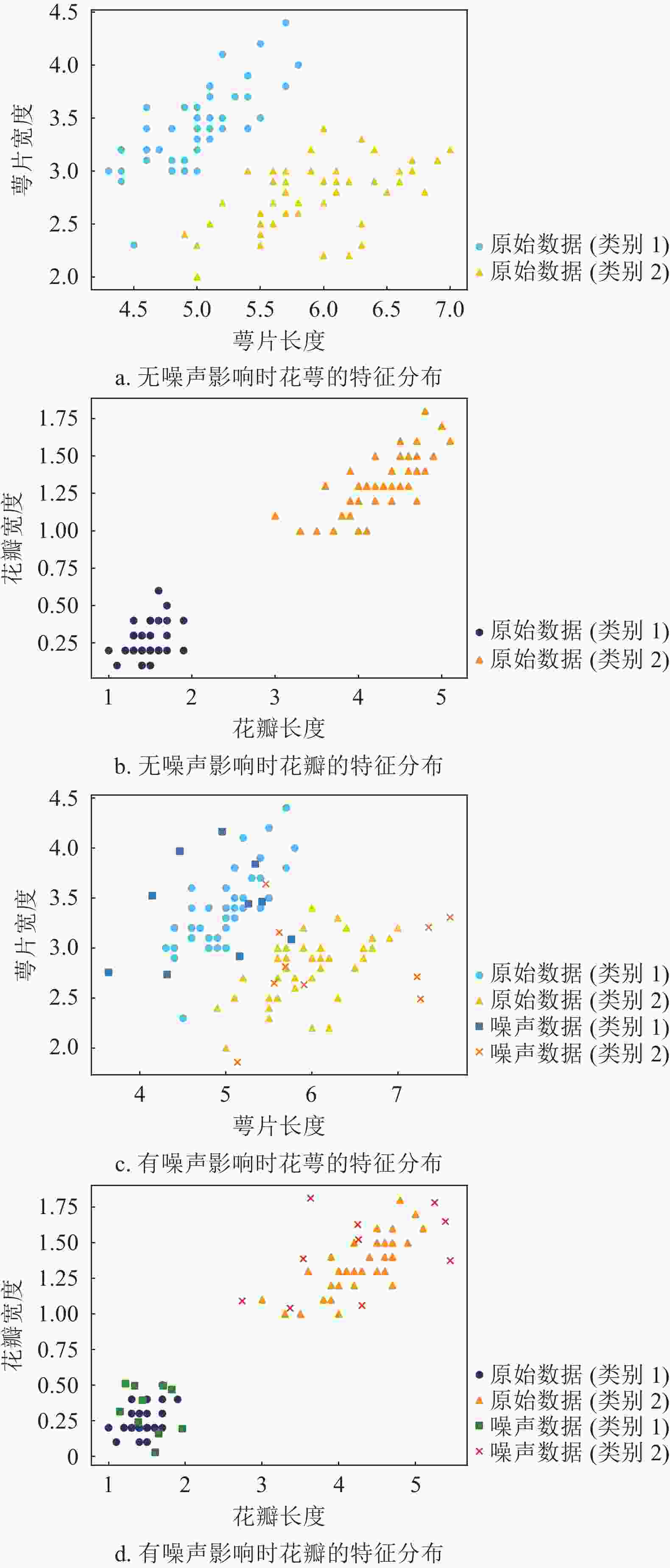
-
正如前文所述,对于不确定性的数据,模型首先需要通过隶属度、非隶属度和犹豫度来描述数据的不确定性。根据文献[4,23],本实验使用高斯函数作为隶属度函数,将输入变量进行直觉模糊化处理,结合实际情况将模型中的直觉指数(即犹豫度)设置为0.1。模糊化操作的最后一步是将所有特征的隶属度进行AND模糊逻辑运算。之后,模型需要将模糊化后的数据转化为量子态。根据定义2,本文采用振幅编码[24-25]将模糊样本编码成量子态(量子模糊向量)作为量子神经网络的输入。
采用文献[24]提出的量子神经网络电路模型作为比较基准,量子神经网络中用于训练的线路称为ansatz。采用StronglyEntanglingLayers[24]作为ansatz线路,层数设置为5层,在数值模拟中通过parameter-shift rule[26-27]获得量子线路中的梯度值,量子线路中的参数更新借助Pennylane Tensorflow 插件,将量子电路转换为Kears层并添加到经典层中。对于整个混合量子−经典模糊神经网络,迭代轮次为30,批量大小设置为5,采用交叉熵作为损失函数,利用Adam自适应优化器[28]进行优化,学习率为0.01。为公平比较量子模糊信息管理数学模型的有效性,将未进行模糊化操作的数据直接作为量子神经网络[24]的输入,量子神经网络的结构以及参数设置与混合量子−经典模糊神经网络相同。
-
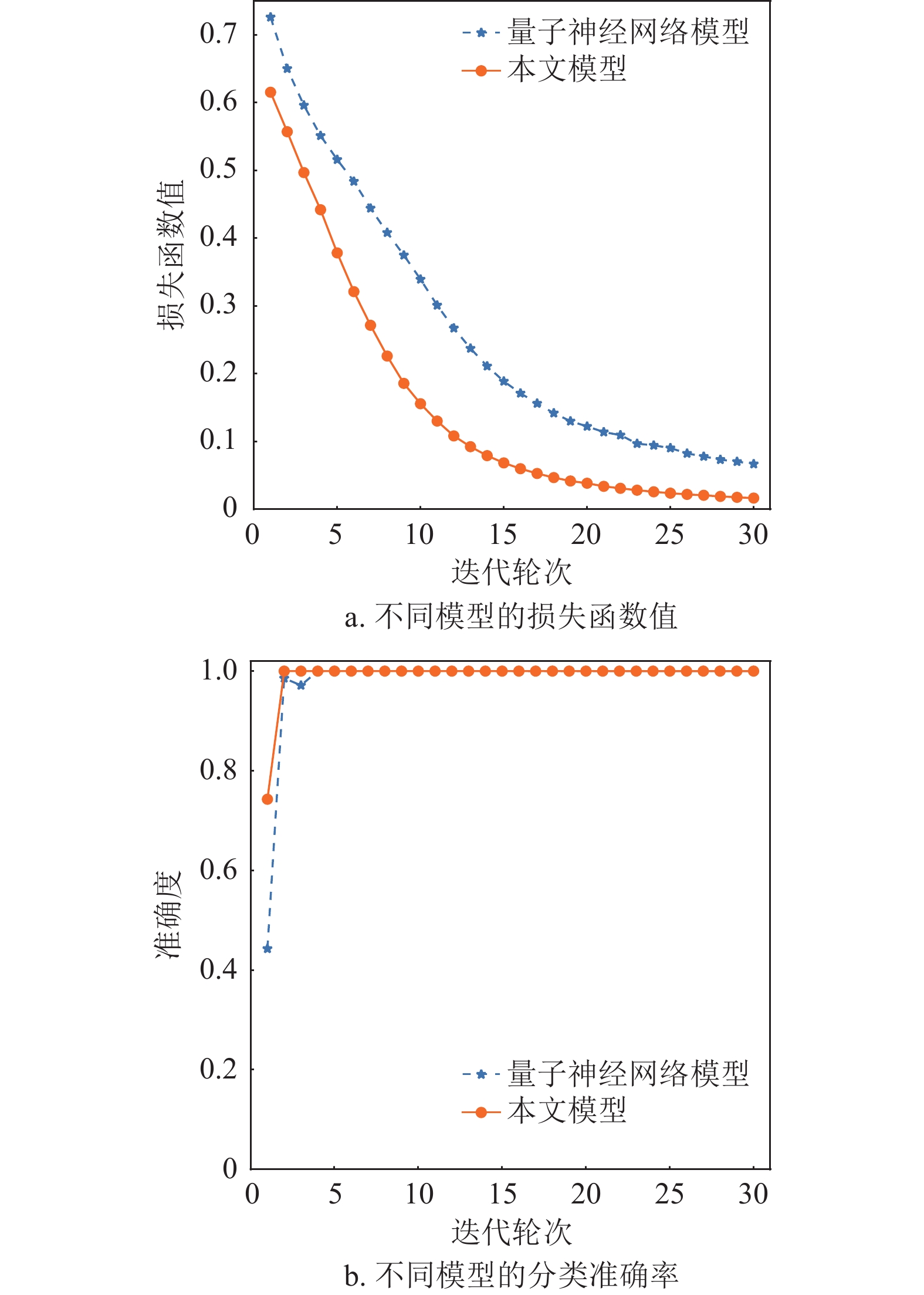
采用量子模糊信息管理数学模型建模后的量子模糊神经网络模型与纯量子神经网络模型在未受噪声干扰影响下的训练结果如图5所示。
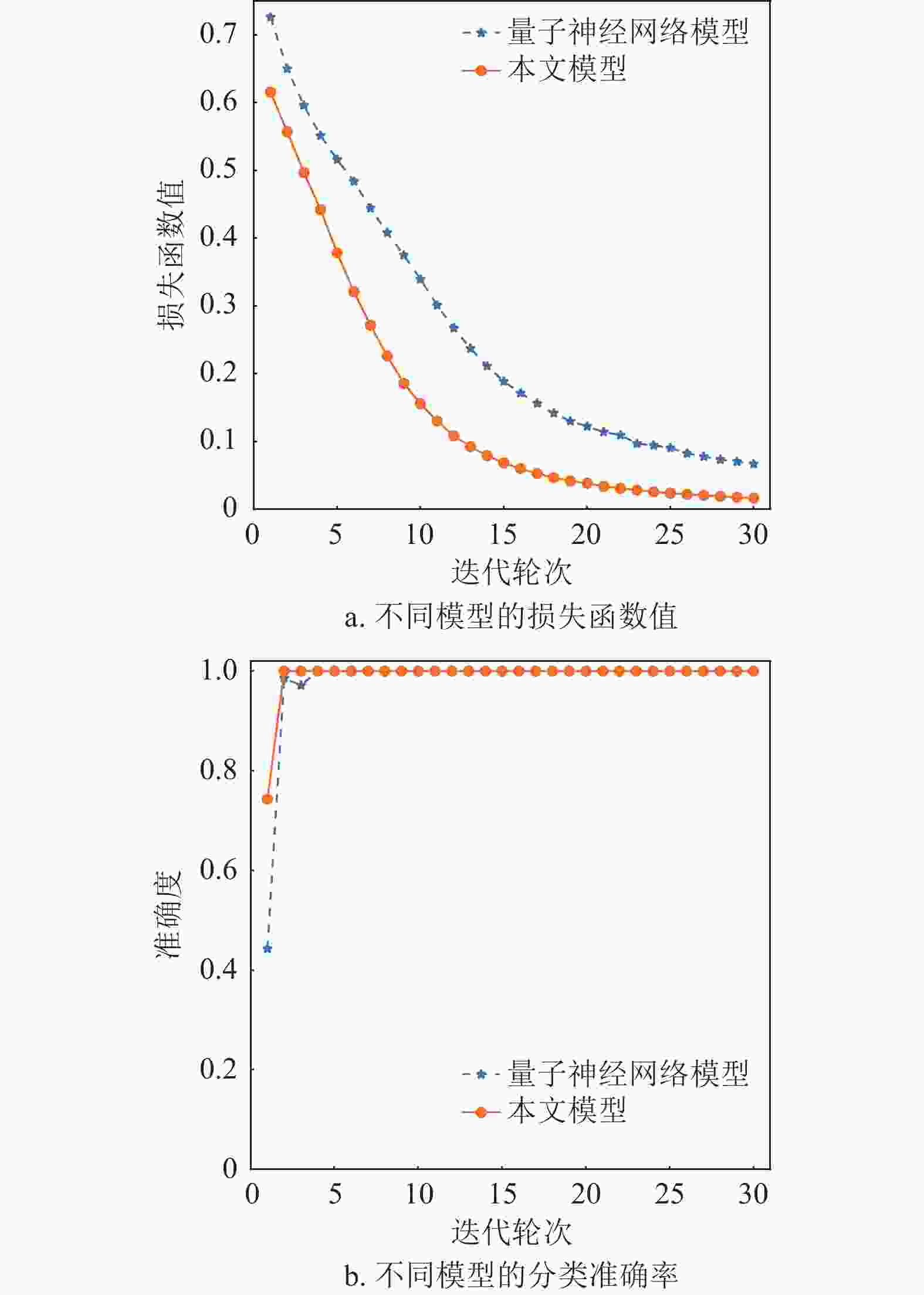
在未添加噪声样本时,两种模型在Iris分类任务中表现出色,准确率达到100%。但随着噪声样本数量以及噪声扰动的增加,未经过量子模糊信息管理数学模型建模的量子神经网络准确率不断降低,而本文模型几乎不受噪声干扰,面对数据中的不确定性因素有更好的性能表现。
噪声样本
数量噪声扰动大小 0.1 0.2 0.3 0.4 0.5 10 98.34±1.66 98.34±1.66 94.50±2.17 94.50±2.17 92.92±1.24 15 91.66±2.41 92.67±1.83 90.56±1.10 91.67±1.66 92.46±0.79 20 91.25±0.41 94.16±2.17 94.50±2.17 94.50±2.17 91.67±1.66 25 94.50±2.17 94.50±2.17 93.09±1.41 89.17±2..67 88.33±1.66 30 90.83±0.83 91.25±1.66 91.08±1.01 90.41±1.26 88.75±0.42 35 86.67±3.33 85.00±1.67 86.67±3.33 86.25±0.42 86.67±2.08 40 91.67±1.66 91.67±1.66 91.67±1.66 91.67±1.66 91.67±1.66 45 88.75±2.92 89.17±2.50 88.87±0.27 87.91±0.42 85.54±2.37 噪声样本
数量噪声扰动大小 0.1 0.2 0.3 0.4 0.5 10 100 100 100 100 100 15 100 100 100 100 100 20 100 100 100 100 100 25 100 100 100 99.90±0.03 99.87±0.20 30 100 100 100 99.93±0.02 100 35 100 100 100 99.83±0.12 99.50±0.33 40 100 100 100 99.80±0.05 99.34±0.83 45 100 100 98.34±1.66 98.34±1.66 99.17±0.83 -
针对如何高效、准确处理大数据所具有的复杂性、不确定性问题,本文提出了基于直觉模糊集理论的量子模糊信息管理数学模型。一方面,借助直觉模糊集理论直观、定量、准确地反映大数据中不确定元素的实际情况;另一方面,结合量子计算在处理复杂性和不确定性问题上具有高效率的优势,建立起了实际可行的量子模糊信息管理数学模型。在此基础上,对相关基础问题进行了研究与分析。最后,仿真实验表明,面对不确定性环境,利用量子模糊信息管理数学模型建模后有更好的性能表现。在一定程度上说明将“不确定性问题 + 直觉模糊集理论 + 量子计算”进行交叉融合研究是可行的,为研究量子模糊人工智能算法奠定了理论和实践基础。
Research on Mathematical Model of Quantum Fuzzy Information Management
doi: 10.12178/1001-0548.2022355
- Received Date: 2022-10-21
- Rev Recd Date: 2022-12-30
- Available Online: 2024-04-01
- Publish Date: 2024-03-30
-
Key words:
- big data /
- quantum computing /
- intuitionistic fuzzy set theory /
- quantum model information management /
- quantum fuzzy neural networks
Abstract: In order to efficiently deal with the complexity and uncertainty of big data, this paper integrates “uncertainty problem + intuitionistic fuzzy set theory + quantum computing”, to build a quantum fuzzy information management mathematical model based on intuitionistic fuzzy set theory. To verify the feasibility, rationality and validity of this model, a simulation experiment of quantum fuzzy neural network based on parameterized quantum circuit is designed under uncertainty environment. The experimental results show that the quantum fuzzy neural network based on this model can more objectively, accurately and comprehensively reflect the knowledge information contained in each object in the uncertainty problem, and improve the accuracy of the algorithm processing big data.
| Citation: | ZHANG Shibin, HUANG Chenyi, LI Xiaoyu, ZHENG Fangcong, LI Chuang, LIU Zhaolin, YANG Yongxi. Research on Mathematical Model of Quantum Fuzzy Information Management[J]. Journal of University of Electronic Science and Technology of China, 2024, 53(2): 284-290. doi: 10.12178/1001-0548.2022355

|






































































































































































 DownLoad:
DownLoad: