 ISSN
ISSN 




-
人脸识别作为计算机视觉领域的重要组成部分,被广泛应用于日常生活中。但普通RGB图像的成像质量依赖于光照条件,这使得在一些缺乏光照的场景很难通过普通相机获取有效信息,如夜间驾驶、监视和跟踪等[1]。随着三维相机的发展,如Kinect,获取高质量三维图像变得更加便捷,基于红外的成像原理,使其对光照变化保持稳定,且每个像素点代表了传感器到目标的距离,能有效地刻画目标的空间信息。通过简单的坐标转化,能实现三维图像到三维点云数据的转变。基于点云的人脸识别有以下两个优势:一是数据本身对光照变化保持稳定,使其能有效地应用于缺乏光照或光照变化大的场景;二是能简单地根据距离信息实现背景分离,减少背景对目标的干扰,使任务能更好地聚焦于对象本身[1]。
文献[2] 提出了Pointnet,该网络解决了点云的无序性以及在深度学习中的应用,有效地通过深度神经网络提取点云的全局特征并应用于点云的分类以及分割任务。文献[3]提出Pointnet++通过点云的空间位置信息对点云分组,实现了点云特征的分层次提取。文献[4]通过融合局部和全局特征提出了PPFNet,该模型丰富了点云特征的表达方式。文献[5]通过X-conv 算子解决了点云在卷积神经网络中的应用。文献[6]基于图卷积网络构建了一个收敛快、计算复杂度低的点云特征提取网络。近年来,更多的网络模型被应用于三维点云,如文献[7]为点云设计了自注意层,并使用这些自注意层来构建语义场景分割和分类等任务的深度学习网络。
随着基于点云的深度学习模型的发展,更多的3D点云被应用于人脸分析任务,文献[8-9]利用Pointnet++提取3D人脸全局特征,实现了高效的人脸姿态估计。文献[10]构建全新的孪生网络用于姿态干扰下的人脸验证。文献[11-12]采用二维特征互补三维点云信息用于人脸识别。文献[13]提出了一个系数成分分析网络用于三维人脸特征提取。文献[14]引入注意力机制结合上下文信息用于面部表情分析。大量基于点云的人脸分析工作取得了突破性进展,但是,由于点云数据自身缺乏细节纹理,如何在面部表情和姿态干扰以及部分遮挡等复杂情况下有效地提取特征或强化关键信息依然是该领域研究的重点。
针对以上问题,本文采用三维点云数据作为输入,构建一个新的深度学习模型用于三维人脸识别。首先将点云数据进行分组,利用一个局部特征描述子获取每组点云的空间几何信息,再利用Pointnet提取局部特征,然后通过最大池化层整合局部特征,获取全局特征。
为增强关键特征的比重,本文采用关键特征强化机制将获取的全局特征映射为特征空间中的概率分布并通过增强系数强化特征的辨识度,从而减少面部表情以及头部姿态等对任务的干扰。由于点云数据本身对光照变化保持稳定,本方法同样适用于缺乏光照或光照变化大的场景。
-
3D点云的本质是一组三维空间中的点构成的几何模型,表示为
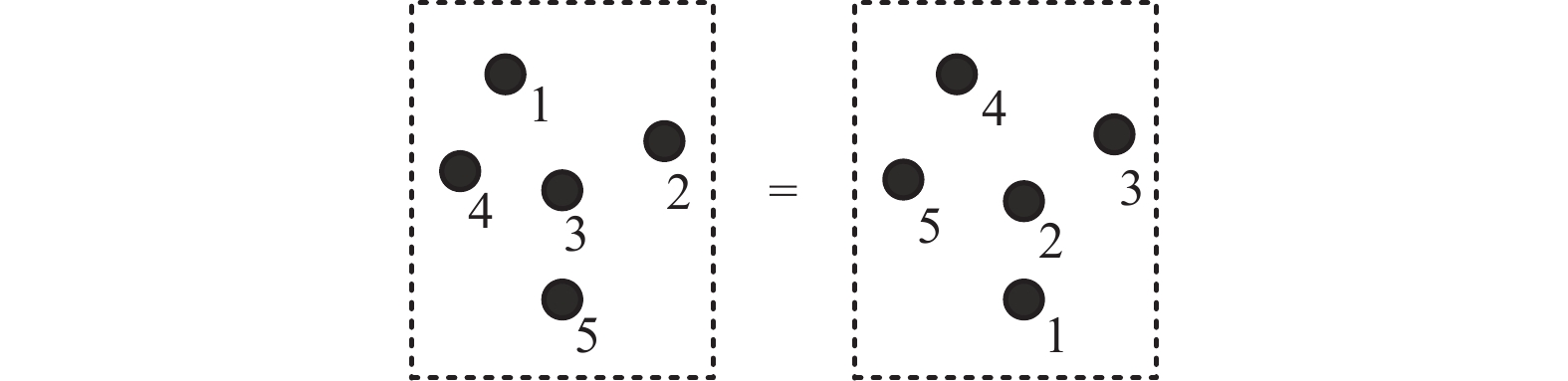
$ n \times ({x_i},\;{y_i},\;{z_i}) $ 的矩阵,其中n为点的数量,$ ({x_i},\;{y_i},\;{z_i}) $ 为点在三维空间的位置坐标。但相同对象特征点的顺序不一定相同,如图1所示,等号左右的特征点构成相同空间几何形状但点的顺序并不一致,因此点云数据不能像规则的二维图像及三维体素一样具有有序的索引序列从而实现权重共享进行卷积操作。解决点云的无序性并进行有效的特征提取是人脸识别任务的关键因素。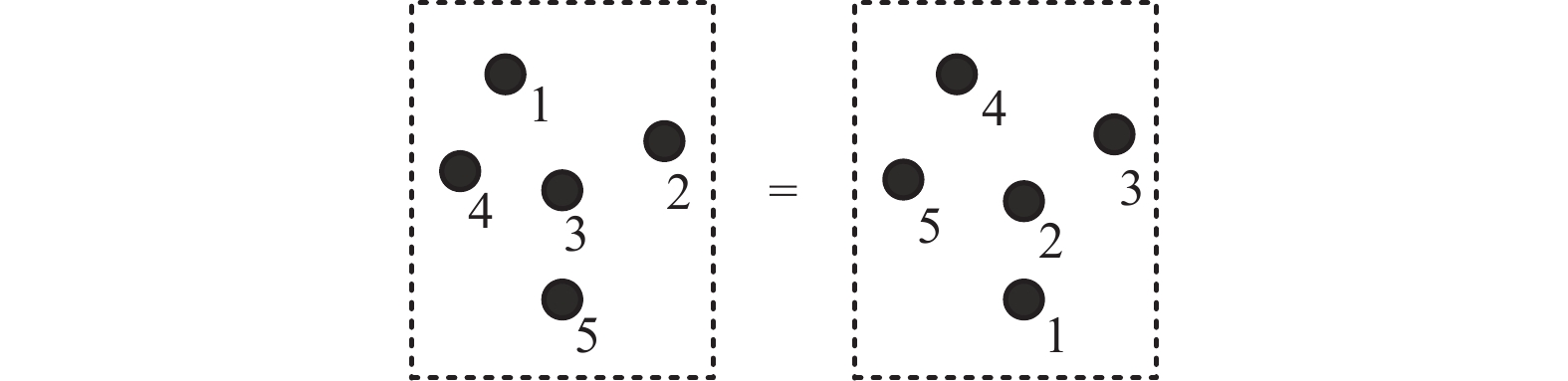
-
为解决点云的无序性以及在深度学习中的应用,文献[2]根据对称函数的思想构建了基于点云的特征提取网络Pointnet。
定义l维空间中的一组点
$ \chi \in {\mathbb{R}^l} $ ,函数$ g:{\mathbb{R}^k} \to {\mathbb{R}^N} $ 是不同特征空间之间的映射,则存在以下定理。假定
$ f:{\chi _{}} \to {\mathbb{R}^M} $ ,$ g:{\mathbb{R}^k} \to {\mathbb{R}^N} $ 均为对称函数(函数映射结果与自变量输入顺序无关),则:式中,
$ h:{\chi _{}} \to {\mathbb{R}^k} $ ,$ \gamma :{\mathbb{R}^N} \to {\mathbb{R}^M} $ 。根据此定理,对于无序点云
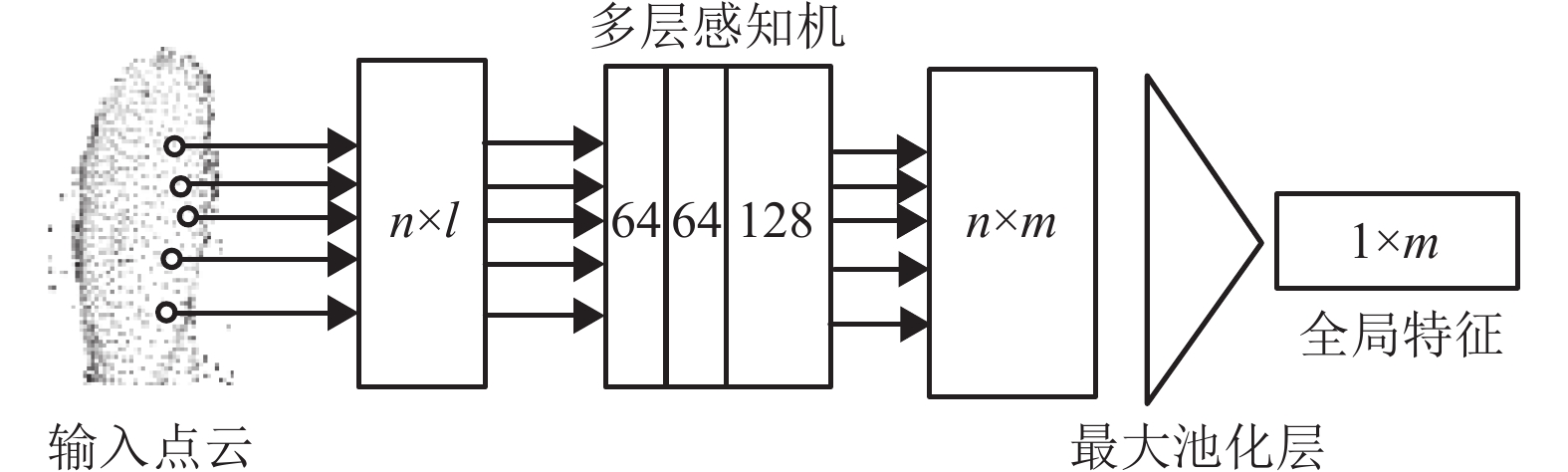
$ \{ {p_1},\;{p_2},\;{p_3},\;\cdots,\;{p_N}\} $ ,为实现$ f:p \to {\mathbb{R}^M} $ 全局特征提取,Pointnet采用多层感知机与最大池化层构建式(1)中右边部分,其网络结构如图2所示。其中n为特征点的数量,l为点的特征维度,多层感知机如式(1)中h函数将每个点通过三层卷积核为1×1(由于点云的无序性,卷积核无法对其周围特征点进行有序索引,只能采用1×1的卷积核对单个特征点进行逐点式的特征提取)的卷积层进行特征提取,输出通道数分别为 64, 64, 128(本文根据文献[8]中的方法,采用两层通道数为64的卷积层对特征点维度进行提升,同时根据FaceNet[15]输出特征维度,将点云映射到特征空间$ {\mathbb{R}^{128}} $ 中)。最大池化层如式(1)中对称函数g取每个特征维度最大值(与特征输入顺序无关)获取点云全局特征。最后根据所需特征维度,将全局特征通过多层感知机映射到特定的特征空间$ {\mathbb{R}^M} $ 中。如上所述,对于不同的人脸点云对象,由于面部轮廓及头部大小不同,其构成的点的数量也不相同,为保证网络具有相同的特征输入维度,本文根据文献[3],采用最远点采样法为每个对象采样固定数量的特征点,即对于输入点集
$ \{ {p_1},\;{p_2},\;\cdots,\;{p_N}\} $ ,随机选取$ {p_i} $ 作为起始点,遍历点集,找到最远点$ {p_{ij}} $ 放入新的点集中,并在剩余点集中再次以$ {p_i} $ 为起始点,迭代以上过程,并获取固定数量的特征点$ \{ {p_{i1}},\;{p_{i2}},\;\cdots,\;{p_{i4096}}\} $ (本文每个对象固定采样4 096个特征点)。相较于随机采样法,最远点采样法能更均匀地对样本进行采样,即采样点能更好地覆盖整个点集。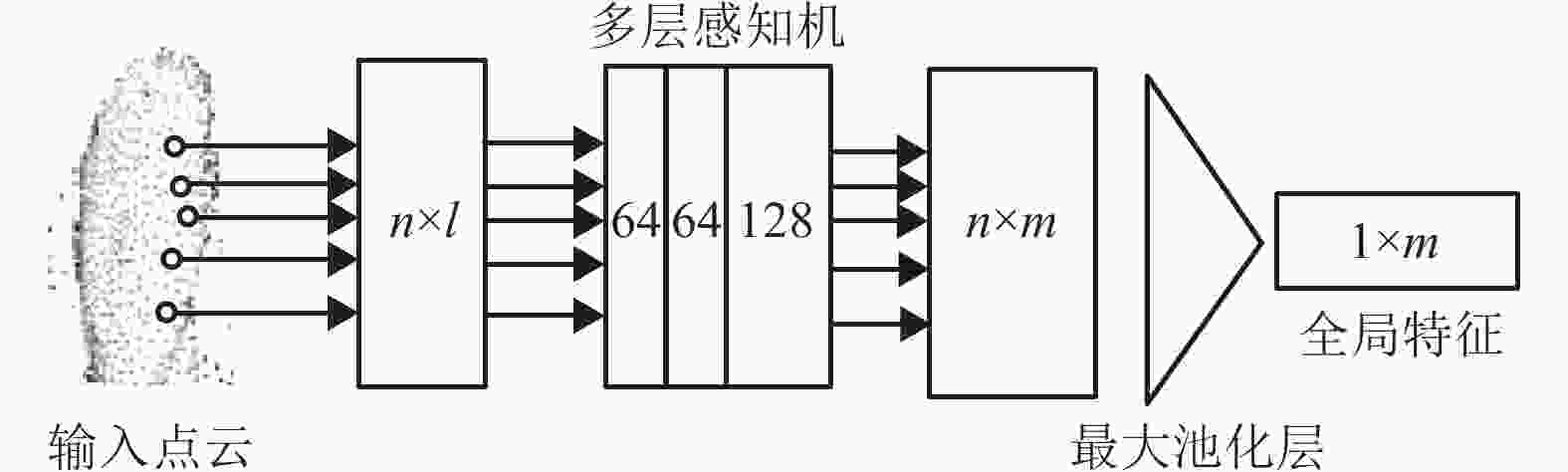
-
相较于普通RGB图像,点云数据缺乏细节纹理,仅靠全局特征很难有效区分不同对象。文献[3]采用区域点簇的位置信息作为局部特征并采用分层采样的方法进行特征提取,该方法能有效应对点云物体的分类与分割任务,但是缺乏对局部特征的描述,因此该方法局部特征的表达非常孱弱,而人脸整体轮廓形状相似,点云的细粒表达(Fine-Grained Representation)是人脸识别任务的关键。相较于文献[3]中的方法,本文根据区域点对的相对位置与法线夹角构造一个四维描述子,该描述子对局部区域内点对间的关系进行手工标记(Hand-Crafted Feature),并组成局部特征描述子对局部区域的几何特征进行细粒表达且该描述子满足平移不变性的要求(采用相对位置与法线夹角)。
$ ({p_i},{p_j}) $ 为局部区域内的一对特征点,其空间几何关系为:式中,d用向量表示两点之间的差值;
$ \left\| \cdot \right\| $ 为欧氏距离;$ {{\boldsymbol{n}}_i} $ 和$ {{\boldsymbol{n}}_j} $ 为该局部区域内点$ {p_i} $ 和$ {p_j} $ 的法向量;$ \angle ( \cdot , \cdot ) $ 表示向量间的夹角:该四维描述子描述了点对间的空间几何特征。在以
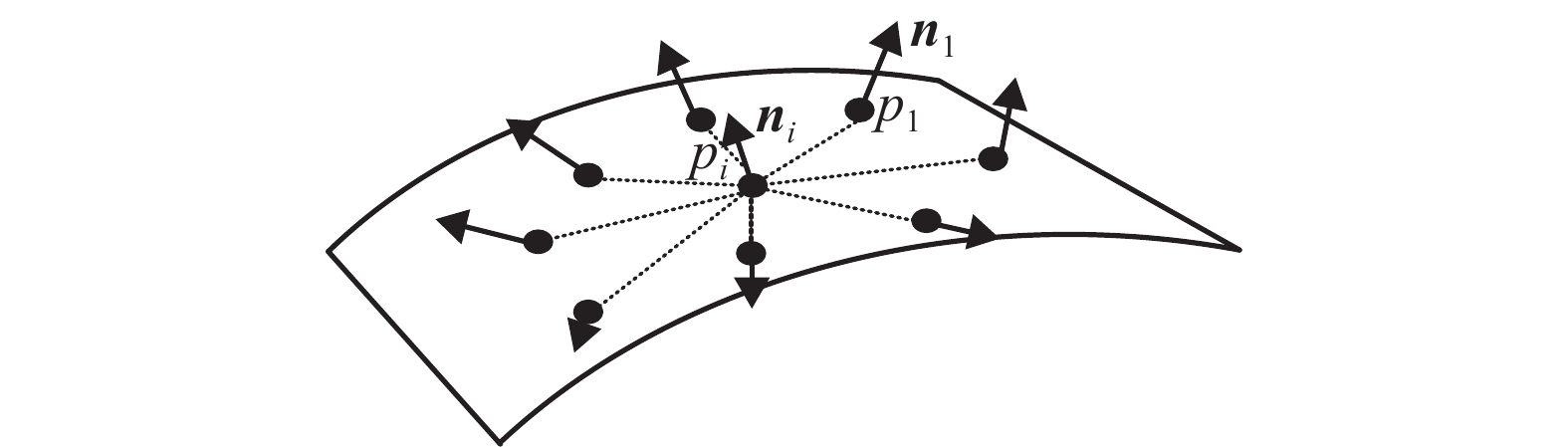
$ {p_i} $ 为中心、k(也被称为局部特征描述子的感受野)为半径的球体内,包含的所有点$ \{ {p_1},\;{p_2},\;{p_3},\;\cdots, {p_j}\} $ 与中心点$ {p_i} $ 构成j个点对,该局部区域的编码方式为:式中,
$ {{\boldsymbol{n}}_j} $ 为点$ {p_j} $ 在该局部区域的法向量,$ {\psi _{ij}} $ 为$ {p_j} $ 与中心点$ {p_i} $ 间的四维特征描述子。如图3所示,$ {F_i} $ 通过以$ {p_i} $ 为球心、k为半径的局部区域的所有点与中点$ {p_i} $ 的空间几何关系描述了该局部区域的空间几何特征。
-
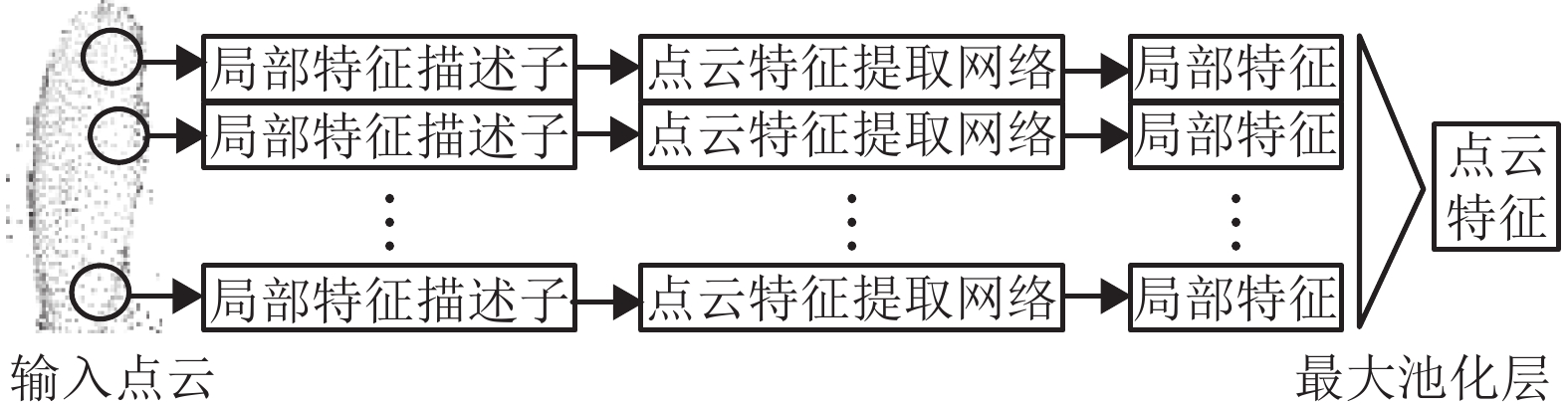
如1.1节所述,每组点云对象通过最远点采样法,均匀地采样
$ {N_1} $ 个特征点$ \{ {p_1},\;{p_2},\;\cdots,\;{p_{{N_1}}}\} $ ,将每个特征点作为中点,以k为半径得到$ {N_1} $ 个局部区域,对每个局部区域根据式(4)的局部特征描述子进行编码,得到一组局部空间几何特征$ \{ {F_1},\;{F_2},\;\cdots,\;{F_{{N_1}}}\} $ ,再对每一个$ {F_{{N_i}}} $ 采用1.1节中的点云特征提取网络进行局部特征提取,并获取一组高维特征空间中的特征$ \{ {f_1},\;{f_2},\;\cdots,\;{f_{{N_1}}}\} $ 。如图4所示,将该组特征送入最大池化层获取该点云对象从局部到全局的特征$ {f_{L{\rm{to}}G}} $ 。由于$ {f_{L{\rm{to}}G}} $ 是通过局部特征整合提取,因此包含了丰富的局部几何信息。
-
理论上,对点云局部区域进行编码并通过最大池化层可获取高维特征
$ {f_{L{\rm{to}}G}} $ 。但实际中,并不是每个维度的特征都对识别任务起相同的作用。如某一维度的特征值较大,则该维度上的特征差异越大,辨识度越高,则称该特征为关键特征;反之,某一维度的特征值越小,则该维度上的特征差异越小,辨识度越低,则称该维度特征为非关键特征[14]。本文提出了一种关键特征增强机制,用于增强关键特征的比重,提高模型识别准确率。该机制的结构如图5所示。首先根据式(5),采用双曲正切函数将特征$ {f_{L{\rm{to}}G}} $ 归一化到[−1, 1],并得到归一化后的特征$ {f_{{\rm{norm}}}} $ 。再根据式(6)和式(7),采用softmax函数将$ {f_{{\rm{norm}}}} $ 映射为0~1的概率分布。式中,
$ {f_{{\rm{en}}}} $ 表征了$ {f_{{\rm{norm}}}} $ 每个维度的特征值在特征空间中的概率分布。如式(7)所示,在特征概率分布$ {f_{{\rm{en}}}} $ 中,较大的特征值其概率值呈指数增长,而较小的特征值其概率值呈指数减小。该方法能有效增强关键特征在概率分布中的辨识度。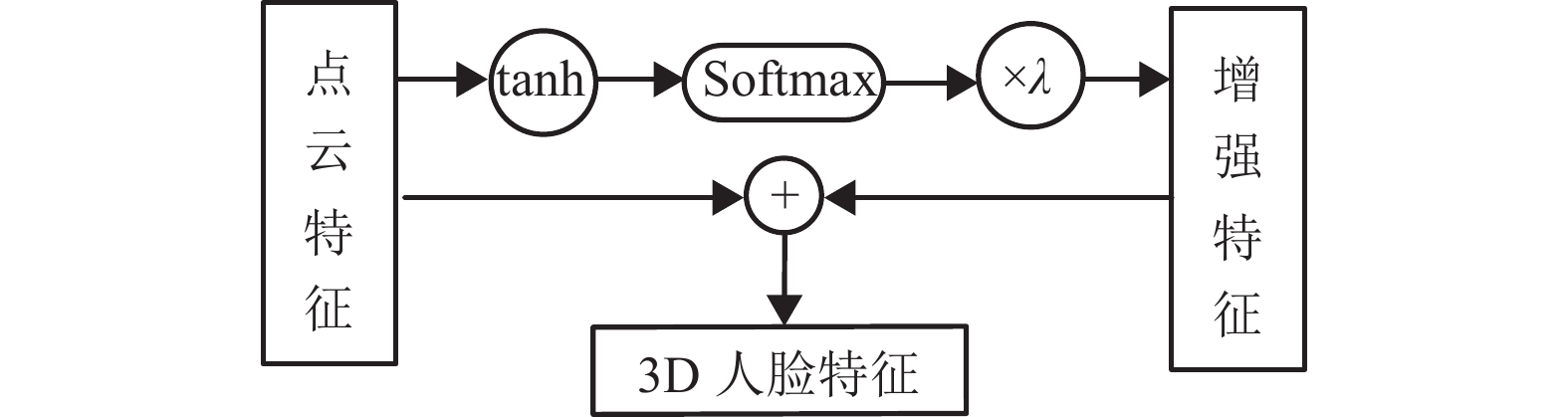
如上所述,
$ {f_{{\rm{norm}}}} $ 为通过深度学习网络提取并归一化后的3D点云特征,$ {f_{{\rm{en}}}} $ 为关键特征通过概率分布增强后的特征。本文通过增强参数$ \lambda $ 将$ {f_{{\rm{en}}}} $ 与$ {f_{{\rm{norm}}}} $ 线性相加,获取增强后的三维人脸特征$ {f_{{\rm{total}}}} $ :如式(8)所示,增强参数
$ \lambda $ 决定了$ {f_{{\rm{en}}}} $ 对点云特征$ {f_{{\rm{norm}}}} $ 的增强程度。文献[15]中,谷歌公司采用卷积神经网络提取特征并引入三元组损失构建了著名的FaceNet网络,用于二维RGB人脸识别。本文采用三维特征
$ {f_{{\rm{total}}}} $ 替换FaceNet中卷积神经网络提取的二维特征,并将其作为该网络的特征嵌入用于三维人脸识别任务。 -
本文在3个数据集上进行实验分析,通过消融实验验证特征增强机制的有效性并测试了
$ \lambda $ 的最优值,最后选取最优值与近几年的先进方法进行实验分析对比。 -
1)CASIA-3D:该数据集由中国科学院自动化研究所模式识别与安全技术研究中心采集创建[16]。CASIA-3D基于Minolta vivid910 3D数字扫描仪采集了123名不同受试者。每名受试者包含37或38张脸部图像,每张RGB图像对应一张3D人脸,其中包含不同的面部表情、头部姿态以及光照强度对样本的影响。该数据集共计4 626个人脸模型。
2)Lock3DFace:文献[17]通过Kinect V2采集了509位受试者的5 671组样本(RGB-D图像)。该数据集主要根据表情变化(FE)、普通面部(NU)、部分遮挡(OC)、头部姿态变化(PS)划分了4个子集,能应用于不同场景下的人脸分析任务。
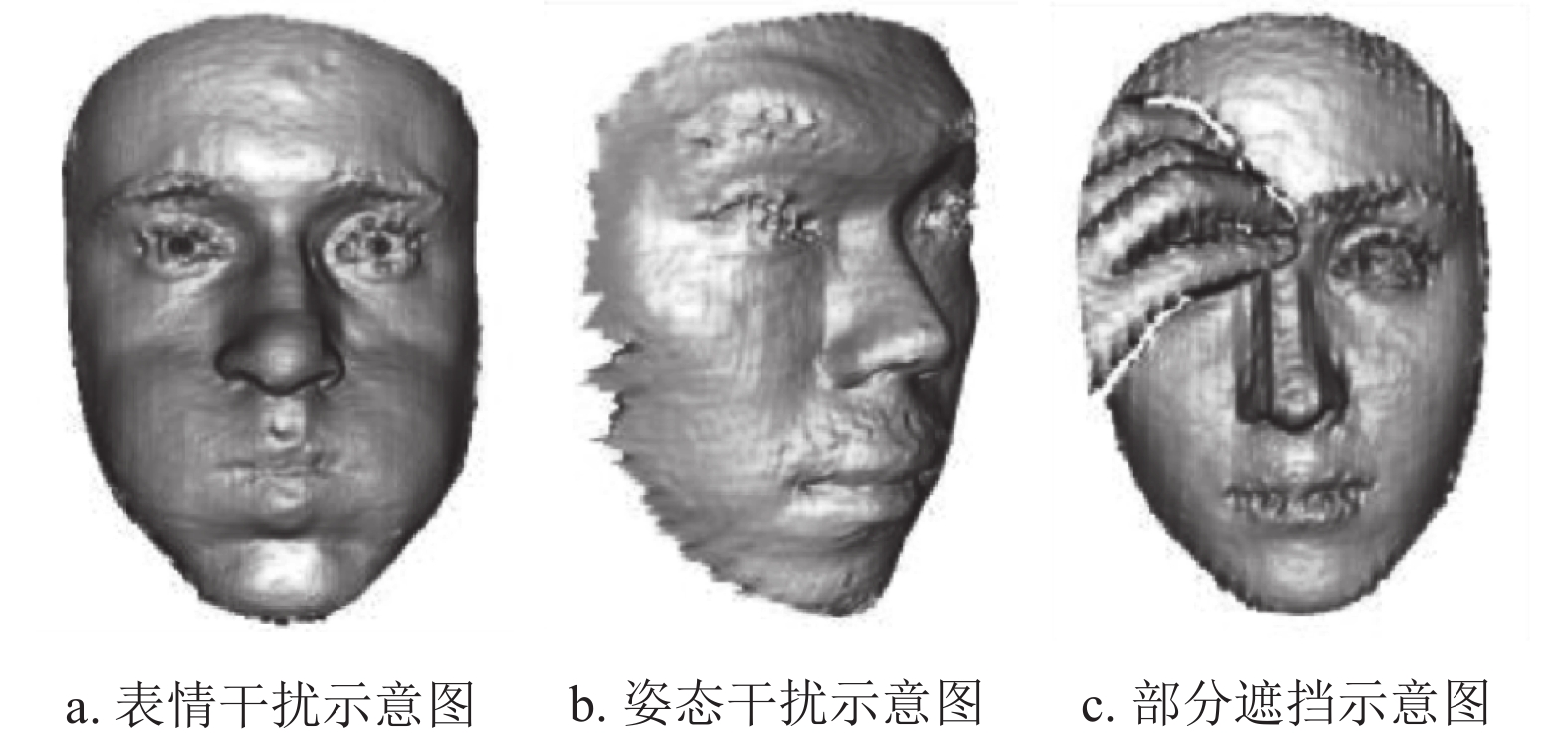
3)Bosphorus:文献[18]为研究多种2D和3D人脸处理任务而创建该数据集,包括表情识别、面部动作检测、面部动作强度估计、不利条件下的人脸识别、可变形人脸建模和3D人脸重建。该数据集基于结构光的3D系统采集了105个受试者共计4666帧面部数据,其中三分之一受试者为职业演员,每位受试者为数据集提供了35种类型的表情。如图6所示,3个子图分别为该数据集上面部表情、头部姿态和部分遮挡下的干扰示意图。
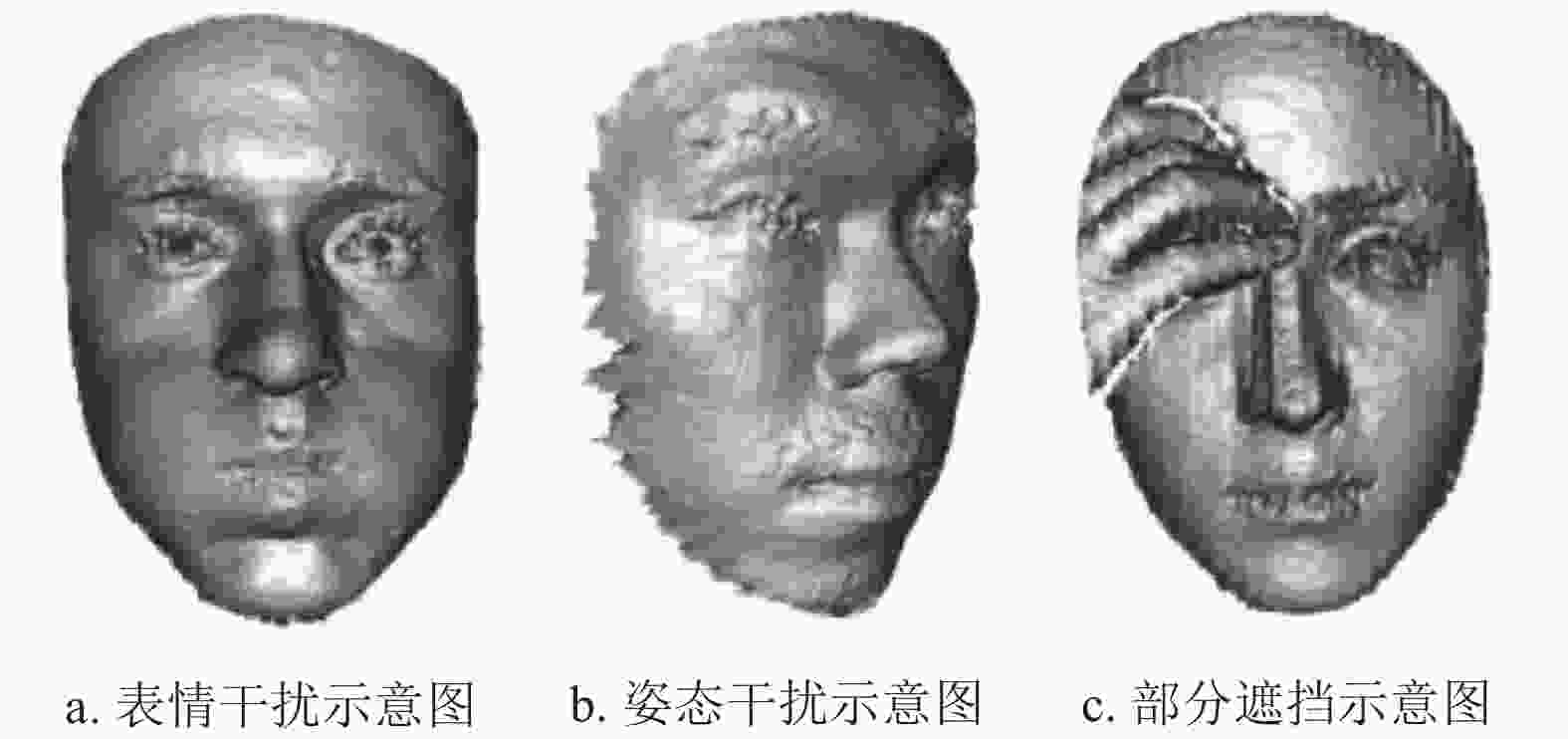
-
如1.2节所述,局部特征描述子通过点对间的四维描述符对以
$ {p_i} $ 球心,k 为半径区域内的点集进行几何特征描述,其中半径 k 的大小决定了局部区域的范围。类似于卷积神经网络中的卷积核,本文将k 定义为局部特征描述子的感受野。而感受野的大小决定了网络对局部特征的感知能力。如表1所示,本节列出了不同感受野在CASIA-3D数据集上的实验结果(为体现网络自身性能,此时将增强参数$ \lambda $ 置0)。感受野k 准确率/% 0.2 86.6 0.4 89.2 0.6 82.7 0.8 77.9 1 73.6 由表1可知,当感受野过小时,网络获取的局部信息过多且细粒程度偏高,导致部分全局特征的丢失;而当感受野偏大时,忽略部分局部特征,同样会影响网络的感知能力。
$ k = 0.4 $ 时,网络准确率最高。因此,本文将0.4设为感受野 k 的固定值,并进行后续实验。 -
根据式(8)所示,参数
$ \lambda $ 决定了特征增强机制对特征的增强程度,$ {f_{{\rm{en}}}} $ 为特征空间中每个维度的概率分布,其值域为(0, 1)。$ {f_{{\rm{norm}}}} $ 为双曲正切函数归一化后的3D点云特征,其值域为[−1, 1]。$ {f_{{\rm{en}}}} $ 与$ {f_{{\rm{norm}}}} $ 在相同的特征空间,但取值范围不同,而增强参数$ \lambda $ 的取值决定了两者的耦合程度,并对模型的性能起着至关重要的作用。通常情况下,可以通过深度学习网络拟合最优参数
$ \lambda $ ,但实际中,网络学习获取的$ \lambda $ 会使$ \lambda {f_{{\rm{en}}}} $ 更拟合于$ {f_{{\rm{norm}}}} $ 的中位数,而$ {f_{{\rm{norm}}}} $ 每个维度的取值在值域空间中差异较大,此时$ \lambda {f_{{\rm{en}}}} $ 并不能起到最优增强作用。因此,本文将$ \lambda $ 设为固定值,通过消融实验在CASIA-3D数据集上探究$ \lambda $ 的最优值,其结果如表2所示。增强参数$ \lambda $ 准确率/% 增强参数$ \lambda $ 准确率/% 0 89.2 55 98.9 5 89.2 60 98.8 10 89.1 65 98.7 15 89.5 70 98.3 20 91.7 75 98.1 25 92.9 80 98.1 30 94.8 85 97.7 35 96.3 90 97.1 40 97.6 95 96.5 45 98.0 100 95.6 根据表2,当
$ \lambda $ 为0时,根据式(8),特征增强机制没有起到作用,仅依靠归一化后的$ {f_{{\rm{norm}}}} $ 作为FaceNet的嵌入特征,此时模型的识别准确率为89.2%,并以此为准线进行实验对比。随着$ \lambda $ 的增大特征增强机制开始作用于$ {f_{{\rm{total}}}} $ ,模型准确率开始提升,当$ \lambda $ 取55时模型准确率达到最大值98.9%,此时$ \lambda {f_{{\rm{en}}}} $ 在特征空间中与$ {f_{{\rm{norm}}}} $ 具有最佳耦合度,为$ {f_{{\rm{total}}}} $ 提供最佳的特征区分度。随着$ \lambda $ 的增大,$ \lambda {f_{{\rm{en}}}} $ 与$ {f_{{\rm{norm}}}} $ 的耦合程度降低,模型性能开始下降。当$ \lambda = 100 $ 时,$ \lambda {f_{{\rm{en}}}} $ 与$ {f_{{\rm{norm}}}} $ 出现数量级差异,此时模型主要依靠特征增强机制的概率分布$ \lambda {f_{{\rm{en}}}} $ 作为FaceNet的嵌入特征,但依然保持了较高的准确率,证明特征增强机制的$ {f_{{\rm{en}}}} $ 能很好地通过概率分布表征点云在高维空间中的差异。为进一步探究增强参数
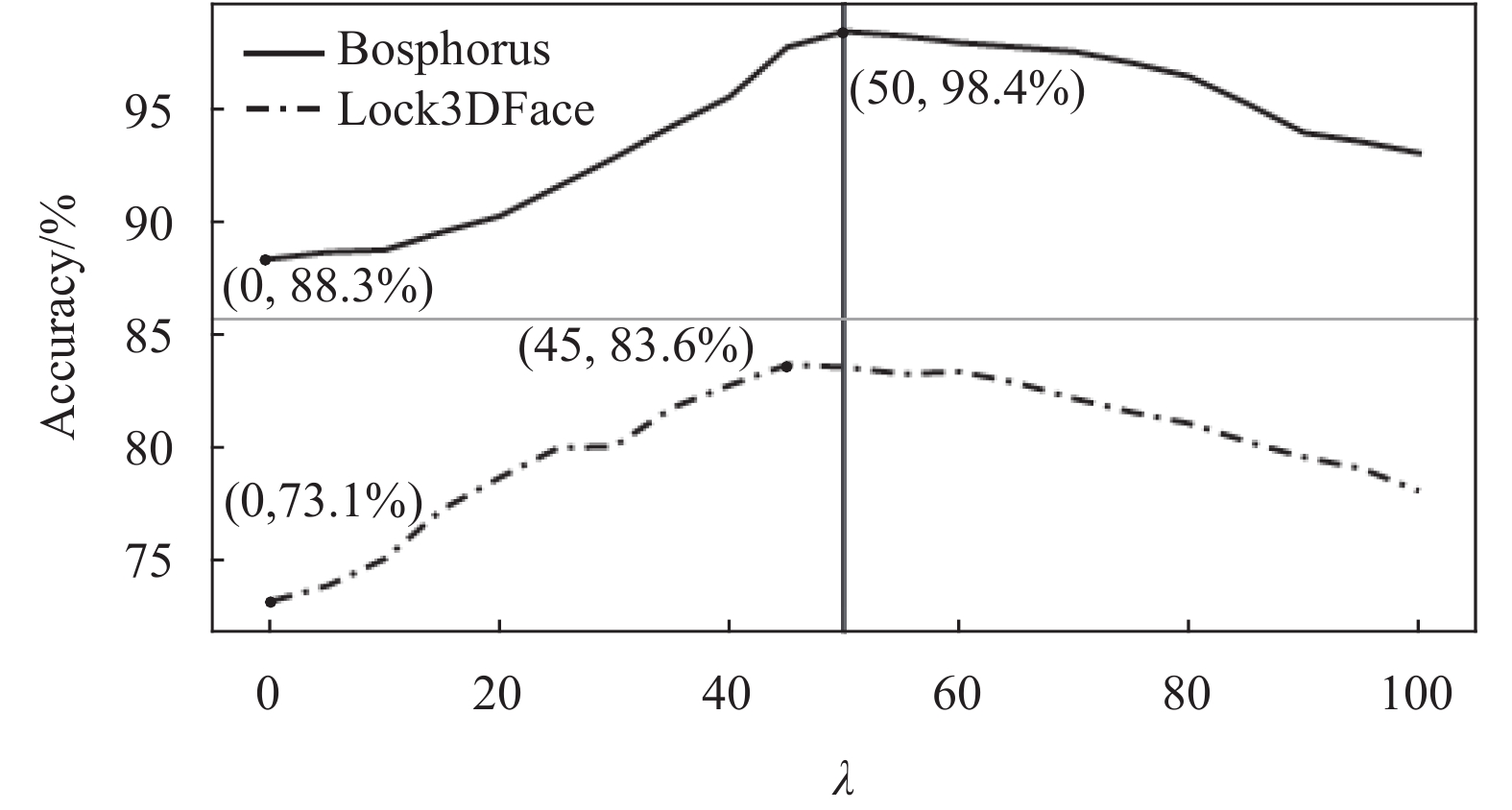
$ \lambda $ 在不同数据集上的性能,本文根据表2的参数设置,在Lock3DFace和Bosphorus数据上进行实验,其准确率变化曲线如图7所示。在 Bosphorus和Lock3DFace数据集上,增强参数$ \lambda $ 分别等于50和45时,准确率最高。在不同数据集上,由于样本分布不同(面部表情、姿态干扰和部分遮挡),不同的$ \lambda $ 会对准确率造成不同的影响。然而,根据表2所示数据以及图7变化曲线分析,当$ \lambda \in [45,60] $ 时,网络准确率达到较为稳定的峰值。这是因为人脸特征整体轮廓相似,不同于2D图像分辨率的差异,点云数据均为空间中的一组点集,其结构简单且数学表达统一。同时,如1.2节所述,本文所采用的局部特征描述子满足平移不变性的要求,点云人脸特征具有一定的相似性,因此,在不同数据集上,$ \lambda $ 在较固定的取值范围内可使网络准确率达到最高。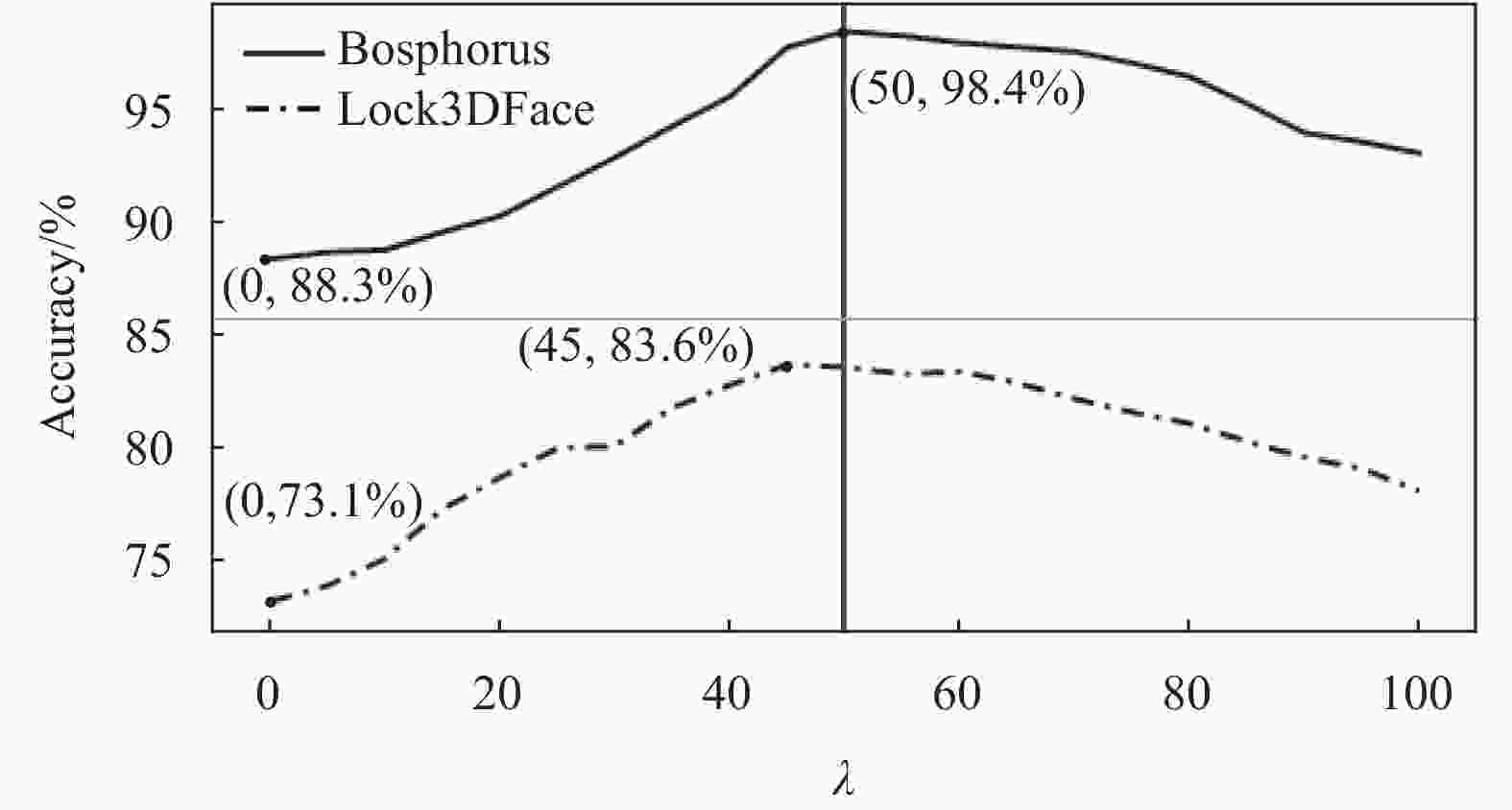
图7列出了
$ \lambda = 0 $ 时,网络在数据集Bosphorus和Lock3DFace上的准确率(此时特征增强机制未起作用),随着$ \lambda $ 增加,网络准确率明显提升,准确率变化曲线证明特征增强机制能有效提升网络对点云特征的鉴别能力。 -
相比于RGB图像,点云数据缺乏细节纹理,为公平对比,本文仅与采用三维数据的方法进行实验对比。
将CASIA-3D数据集按照相同的方式划分,并在正常光照和弱光场景下与近几年的方法进行实验对比,其结果如表3所示。
根据表3所示,在正常光照和缺乏光照的场景下,本文的准确率均高于其他方法,且在弱光条件下,本文的准确率与正常光照下的准确率非常接近,证明本文采用的模型与数据在光照变化条件下具有良好的鲁棒性。
为验证本文方法在更多场景下的性能,本文在Lock3DFace数据集上,根据其对表情变化(FE)、普通面部(NU)、部分遮挡(OC)和头部姿态变化(PS)划分的测试序列进行测试,其结果如表4所示。
如表4所示,本文的方法与文献[23]的方法在面部表情、普通面部、部分遮挡和姿态变化测试序列上,识别准确率均高于其他方法,实验结果证明本文方法能较好地应对表情变化、部分遮挡以及头部姿态变化所带来的影响。与文献[23]的方法相比,本文方法虽然整体准确率低于该方法,但在面部表情变化以及部分遮挡情况,本文方法准确率分别高了0.4%和0.6%,且在其他测试序列下,准确率非常接近。
表5列出了在Bosphorus数据集上的实验对比结果。根据表5所示,在正常光照条件下(数据集中高质量样本),虽然本文方法的准确率略低于文献[13]中的方法,但在弱光条件下(数据集中低质量样本),本文方法的准确率均高于其他方法。由于Bosphorus数据集丰富的样本数据,98.3%的准确率证明了本文方法能较好地应对面部表情、头部姿态和部分遮挡对任务的干扰,且对光照变化保持稳定。
为验证本文方法的时效性,与近几年其他三维头部特征提取网络进行时效对比,其结果如表6所示。由于特征增强机制采用概率分布对点云特征进行增强,并未额外增加网络参数,因此在提升网络鉴别力的同时依然保持了良好的实时性。
与文献[23]相比,在各种场景下,本文准确率与该方法非常接近,但如表6所示,本文方法耗时更短,实时性更好。
综上所述,本文采用三维点云作为输入数据,通过浅层网络提取点云人脸特征,且提出的特征增强机制结构简单、计算复杂度低。简洁的网络结构在提高准确率的同时也保证了良好的实时性。
-
为了解决在光照变化、面部表情、头部姿态和部分遮挡下的人脸识别问题,本文直接采用3D点云作为输入,并引入局部特征描述子和关键特征增强机制提升了特征的辨识度,有效地提高了模型的识别准确率,并保持了良好的实时性。该方法对光照变化保持稳定,可以应用于缺乏光照或光照变化较大的场景,如夜间驾驶认证、夜间检测等。
后期将进一步研究新的算法,提升三维人脸的特征辨识度,并应用于其他复杂情况下的人脸分析任务,如头部检测、姿态估计和人脸验证等。
3D Face Recognition Based on Key Feature Enhancement Mechanism
doi: 10.12178/1001-0548.2023012
- Received Date: 2023-01-06
- Rev Recd Date: 2023-07-02
- Available Online: 2024-04-01
- Publish Date: 2024-03-30
-
Key words:
- 3D face recognition /
- deep learning /
- local feature descriptor /
- feature enhancement /
- point cloud
Abstract: 3D face recognition is an important part of the field of computer vision. Pointnet relies on deep learning to solve the disorder of point clouds and realize the global feature extraction. However, due to the lack of detailed texture of point clouds, it is difficult to realize face recognition in complex situations only by global features. In deal with the above problems, a local feature descriptor is proposed to describe the local spatial geometric features of the point clouds, and a key feature enhancement mechanism is introduced to enhance the key features of the face through the probability distribution, which can reduce the interference of unnecessary features and effectively improve the accuracy of the model. Experiments were carried out on public data sets CASIA-3D, Lock3DFace and Bosphorus. The results show that our method can deal well with the change of expression, partial occlusion and interference of head pose, especially in weak light conditions, compared with RP-Net, the accuracy is improved by 1.1 percent, and the method also has good real-time performance.
| Citation: | WANG Qi, QIAN Weizhong, LEI Hang, WANG Xupeng. 3D Face Recognition Based on Key Feature Enhancement Mechanism[J]. Journal of University of Electronic Science and Technology of China, 2024, 53(2): 252-258. doi: 10.12178/1001-0548.2023012

|








































































































 DownLoad:
DownLoad: