 ISSN
ISSN 




-
低密度奇偶校验(Low Density Parity Check, LDPC)码的性能逼近香农限[1],其译码方法一般采用基于节点置信度更新迭代的算法,这种基于置信度传播的思想是一种逼近香农极限的非常有效的途径[2]。除此之外,准循环LDPC码的并行特性使其能够通过引入少量额外硬件来线性地提高译码器吞吐量[3]。正因为LDPC码的优异性能使得它成为近年来通信及存储领域编码研究的热点。在2016年10月的3GPP会议上确定了将LDPC作为第五代移动通信技术(the Fifth Generation, 5G)的数据信道编码方案[4]。
文献[5-6]采用完全并行结构,实现了上百Gbps级的吞吐量,虽然此结构能够满足5G标准的高速译码需求,但该结构硬件利用效率非常低,且会带来严重的路由阻塞问题。于是人们通常采用硬件利用效率更高的块并行结构,而5G标准规定的基图的行重及列重高度不对称,不同层之间的正交性较差,这就导致了基于块并行结构的译码器不可避免地存在内存访问冲突的问题。
针对内存访问冲突的问题,现有解决方案主要有以下两个。一是尽量避免冲突的发生,具体做法是对层顺序和层内节点进行重新排序[6-7]、分层半并行译码[8]、在流水阶级中插入空闲周期等[9-10]。其中层顺序调换操作会对译码性能产生影响[11],分层半并行译码以较低吞吐量为代价,插入空闲周期会降低吞吐率,因此需尽量避免这些操作。二是降低发生冲突后对译码带来的影响,文献[12]采用一种新的调度方式,当节点是冲突节点时,用一种新的算法进行该节点更新,减小该冲突节点更新值的误差,但这种方法并不能完全解决内存访问冲突问题。
为此本文提出了一种基于帧交错的译码结构,采用多帧交错译码方法,同时最小和计算模块采用多级缓冲机制,结合层内节点重排序算法,能够大幅减少为避免内存访问冲突而设置的空白周期。并采用乒乓机制对初始LLR值进行预缓存,节省初始化所需要的时间。
-
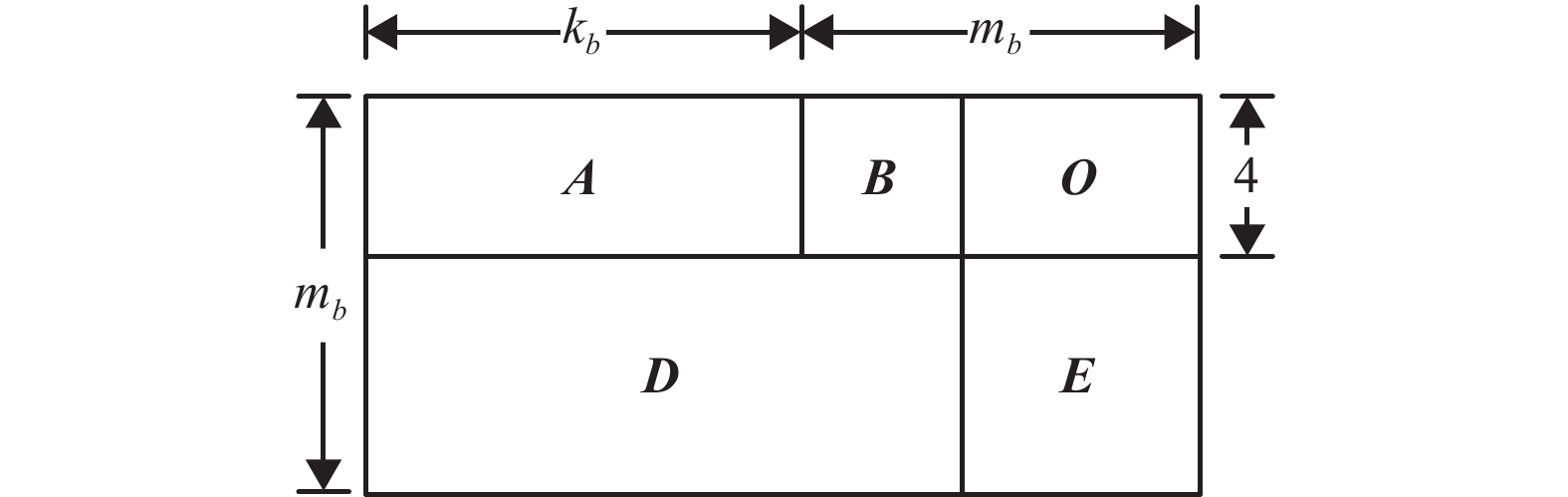
5G 标准采用准循环LDPC(Quasi-cyclic Low Density Parity Check, QC-LDPC)码,其校验矩阵可以用一个基图(Base Graph, BG)和相应的移位因子Z来表示,即基图中每个元素都展开为Z×Z大小的单位矩阵的循环矩阵,移位大小由Z和该元素值确定。特别地,元素“−1”展开为Z×Z的全零矩阵。3GPP会议确定5G LDPC由一个高码率校验矩阵进行码字扩展得到,根据基图可对校验矩阵进行划分,如图1所示。
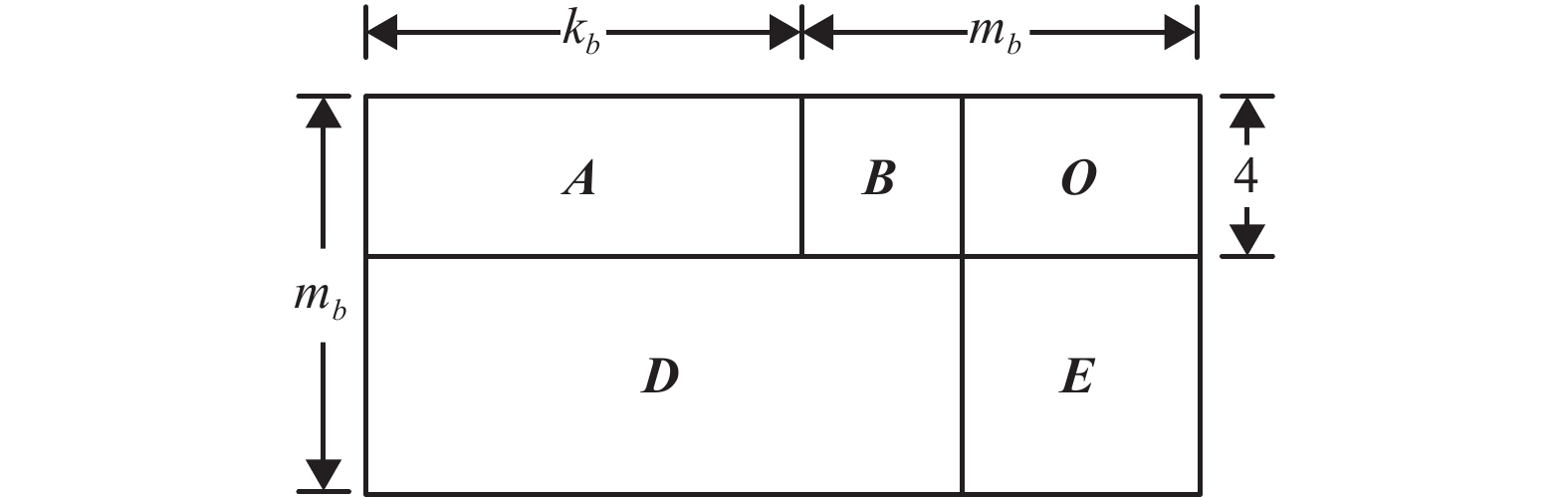
图中A是维度4×kb的密集矩阵,对应信息比特,B是维度4×4的双对角矩阵,对应校验比特,O是维度4×(mb−4)的全零矩阵,D是维度(mb−4)×(kb+4)的稀疏矩阵,E是维度(mb−4)×(mb−4)的单位矩阵。[A,B]构成校验矩阵的核心Hcore。5G标准的校验矩阵通过Hcore扩展得到。
考虑到应用场景的多样性,5G给出了两个基图BG1和BG2以实现不同的码长和码率。表1列出了这两个基图的基本参数。从表中可以看出,两个矩阵的节点度分布不均匀,导致实际实现中存在内存访问冲突问题。
参数 基图 BG1 BG2 尺寸 46×68 42×52 Hcore 4×26 4×14 非零元素 316 197 列重 1~30 1~23 行重 3~19 3~10 -
传统的LDPC迭代译码算法是基于全并行的泛洪调度[13],这种调度方式是以较大的资源消耗来换取较高的吞吐量。为了实现吞吐量和硬件资源的折中,文献[14]提出了分层译码算法,其基本思想是将校验矩阵按行分层,依次更新每层节点的信息,上一层更新的节点信息可以立即用于下一层的更新,其收敛速度是全并行调度的两倍。
在硬件实现中通常以Z行作为一层,由于准循环特性,层内变量节点具有完美的正交性,因此能实现Z个节点并行译码。为了便于表述,本文以一行作为一层,表2对译码过程出现的符号做了详细说明,调制方式为BPSK,在高斯信道下,译码过程如下。
符号 说明 H 校验矩阵 m, n 矩阵行数和列数 l 层序号 t 迭代次序 yj 第j个变量节点的信道消息 σ2 高斯白噪声方差 ci, vj 第i / j个变量/校验节点 $ {N_{{c_i}}} $ 与ci有连接关系的变量节点的集合 $ {N_{{v_j}}} $ 与vj有连接关系的校验节点的集合 $ {N_{{c_i}}}\backslash {v_j} $ 除了vj,其他与ci有连接关系的变量节点的集合 $ {N_{{v_j}}}\backslash {c_i} $ 除了ci,其他与vj有连接关系的校验节点的集合 $L_{{v_j} \to {c_i}}^{(t)}$ 第t次迭代时,vj传递给ci的信息 $L_{{c_i} \to {v_j}}^{(t)}$ 第t次迭代时,ci传递给vj的信息 $ L_j^{(t)}(l) $ 第t次迭代时,vj在第l层更新的后验概率信息 在第一次迭代时,变量节点的后验概率信息根据信道接收的似然信息进行初始化,校验节点信息初始化为零:
初始化完成后开始译码迭代,逐层更新。
1)逐行更新第l层变量节点向校验节点传递的信息:
2)逐行更新第l层校验节点向变量节点传递的信息:
3)更新第l层后验概率:
4)译码结果判决:
令
$ {\boldsymbol{r}} = {[{r_0},{r_1}, \cdots ,{r_n}]^{\rm{T}}} $ ,如果$ {\boldsymbol{Hr}} = 0 $ ,退出迭代,输出r为译码结果,否则返回步骤1)继续迭代,直到达到最大迭代次数。上述译码过程中,最复杂的是步骤2),在实现中通常采用查表法,需要消耗大量硬件资源,因此一般采用低复杂度的归一化最小和算法(Normalized Minimum Sum, NMS):
其中,
$\alpha \in [0.5,1]$ 称为归一化因子。相比于和积译码算法,NMS仅需计算最小值和次小值,在硬件设计中容易实现。 -
传统分层译码结构如图2所示,节点地址存储单元根据校验节点存储变量节点和校验节点的索引值,最小和计算单元和节点更新单元对应上述译码步骤2)和3),判决模块负责对译码结果进行检验,对应步骤4)。

为了提高译码吞吐量,通常采用流水线设计,然而流水线设计常常会导致内存访问冲突问题,主要发生在以下两个方面。
1)当前层在读取节点信息时,上一层的LLR值尚未更新和写入到存储器中,因此当前层无法获得最新的LLR值,即式(3)参与运算的实际是
$ L_j^{(t)}(l - 2) $ 而非$ L_j^{(t)}(l - 1) $ 。节点更新采用了错误的LLR值。2)当前层节点更新还没有完成,下一层的节点最小值就已经准备好,此时节点更新用的是下一层的最小值,即式(7)参与运算的实际是
${M^{(t)}}(i + 1)$ 而非${M^{(t)}}(i)$ 。节点更新采用了错误的最小值。 -
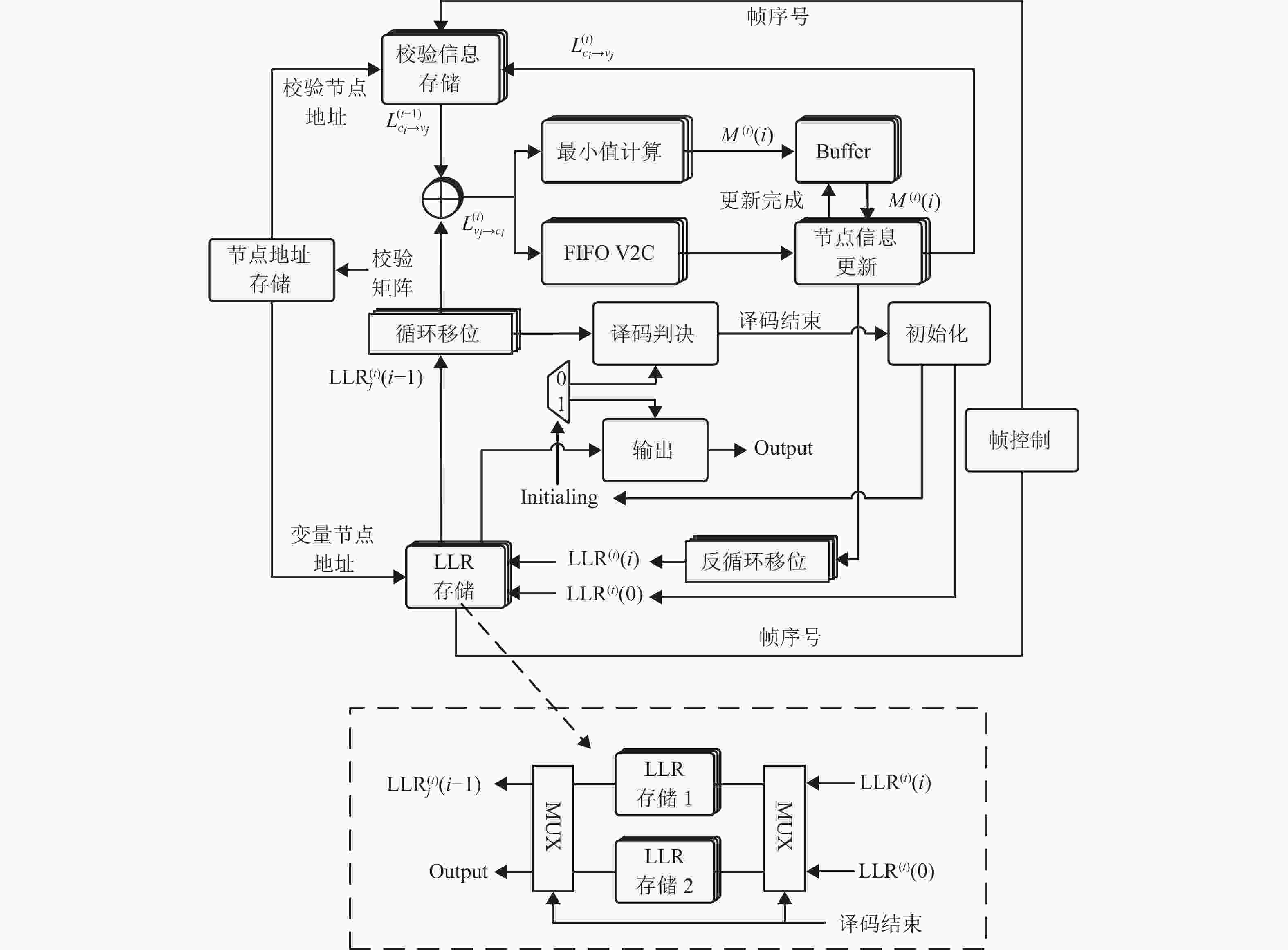
本文提出的帧交错译码结构如图3所示,与传统译码结构相比,该结构主要有以下4点改进。
1) 插入一个帧控制单元,在多帧之间来回切换,根据帧索引信号选择进行译码的存储单元。
2) 采用一个FIFO作为多级缓冲结构,可以缓存多个最小值,当上层节点更新完成时,再将下层最小值从FIFO读出。该操作需要一个时钟周期,相应地增加一个流水阶级。
3) 插入一个译码输出选择器,使译码器可以在进行初始化时同时读出前一帧的译码结果,与传统结构相比,节省了额外用于存储译码结果的资源。
4) 采用乒乓式缓存机制,即将存储器分为两组,分别用于预存初始化信息和当前帧的译码,工作时交替使用,节省初始化信息需要的时间。
-
通常节点更新顺序是按照其在矩阵的位置逐个进行,若同一变量节点在连续两层中出现,其间距太小很容易发生访问冲突,因此有必要对节点进行层内重排序,使得同一变量节点间距足够长,且同一层的节点进行重排序不会影响译码性能。
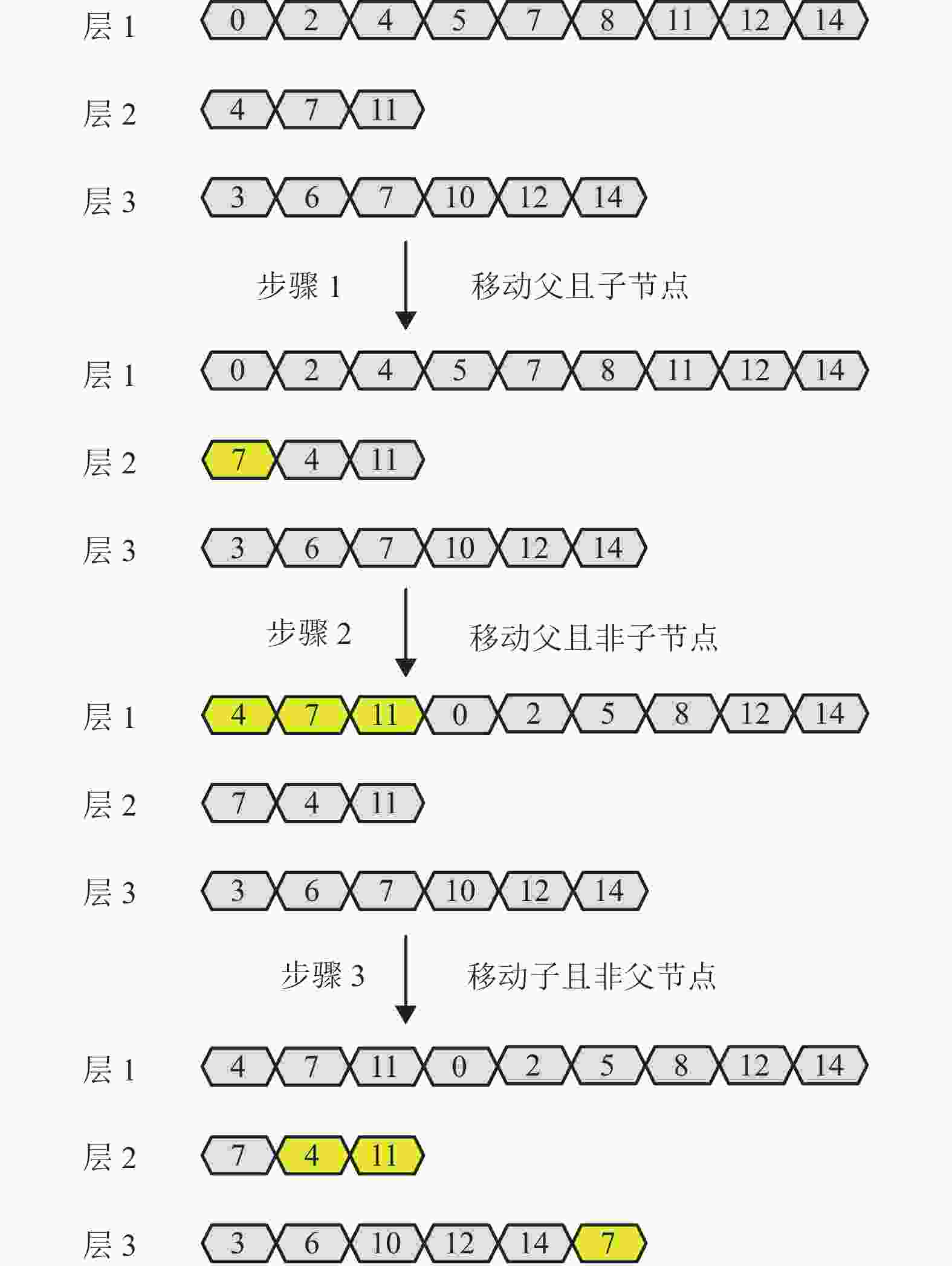
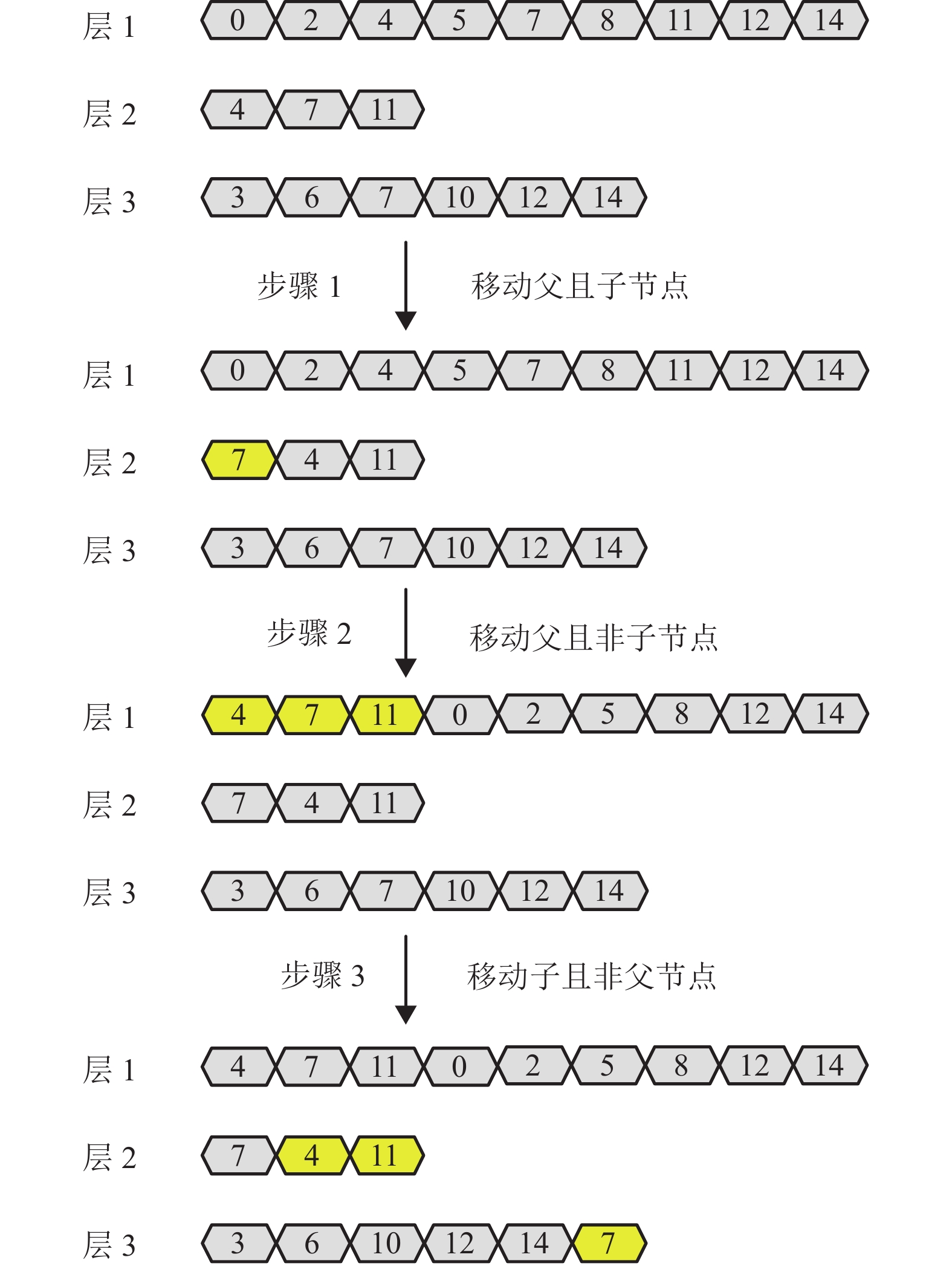
若一个节点在连续两层中同时出现,称它在上一层的节点为父节点,在下一层的节点为子节点。一个节点可以同时是父节点和子节点。动态规划的基本思想是父节点提前更新,子节点推迟读取,使得父节点有足够的时钟周期完成更新。具体规划如算法1所示。
节点的位置关系着该节点在硬件实现中读写的先后顺序,即同一层位置靠左的节点优先读写,图4给出了一个具体的例子,图中黄色标识的节点代表符合移动条件的节点。以序号为7的节点为例,在进行重排序之前,该节点在层1到层2 的间距为6,在层2到层3的距离为4。经过重排序后间距都为8,足够的间距能够有效避免内存访问冲突。
算法 1 层内节点动态规划
for 校验节点每一层 do
for 从右到左每个节点 do
if 该节点同时是父节点和子节点 then
移动该节点至最左端
end if
end for
for从右到左每个节点do
if 该节点是父节点且非子节点 then
移动该节点至最左端
end if
end for
for从左到右每个节点do
if 该节点是子节点且非父节点 then
移动该节点至最右端
end if
end for
end for
-
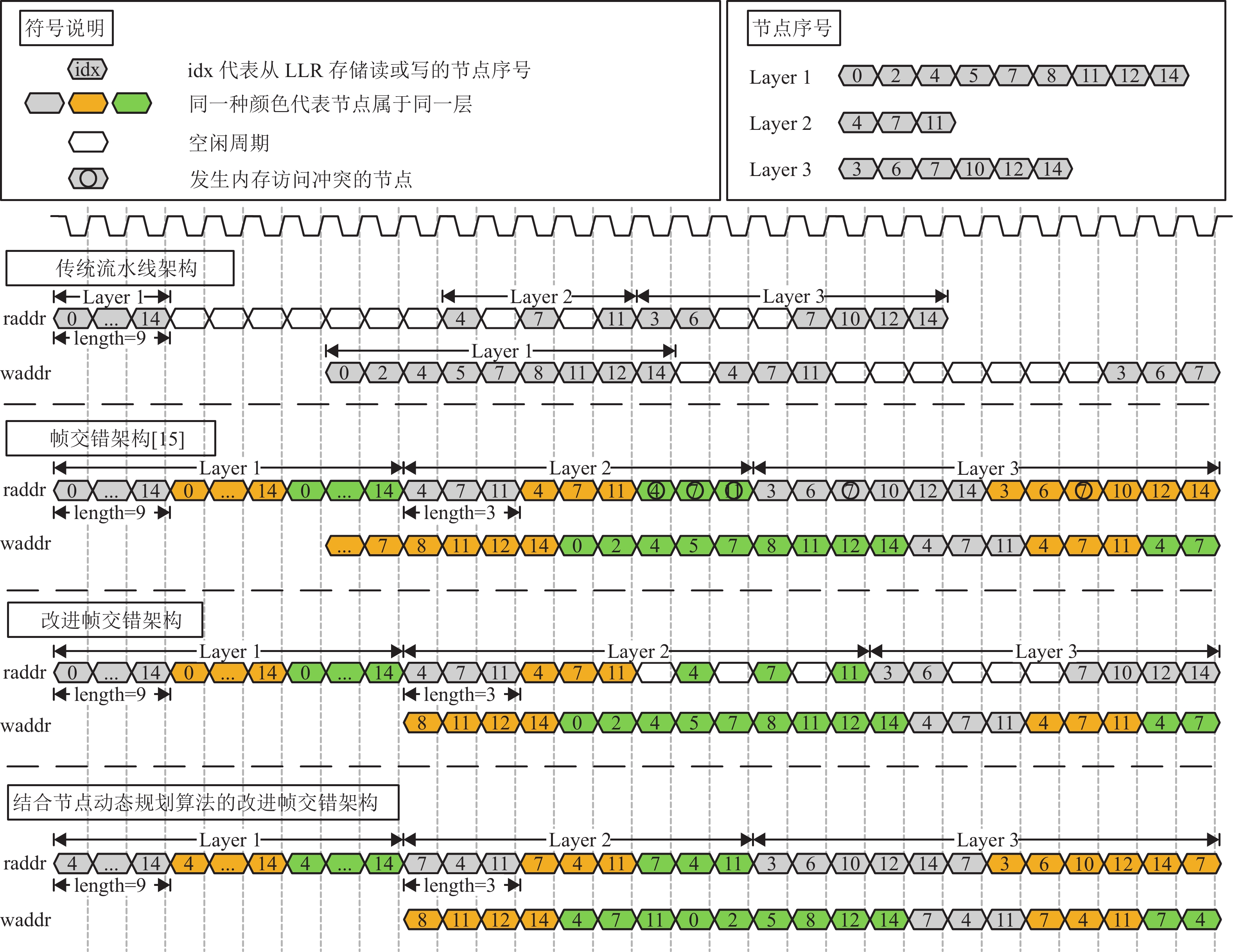
图5展示了在校验矩阵行重高度不对称的情况下,不同译码结构的时序分析。图中主要展示的是节点信息的读和写过程,整个流水结构包括5个流水阶级,在读取完一层节点的5个时钟周期后开始逐个写入节点信息。
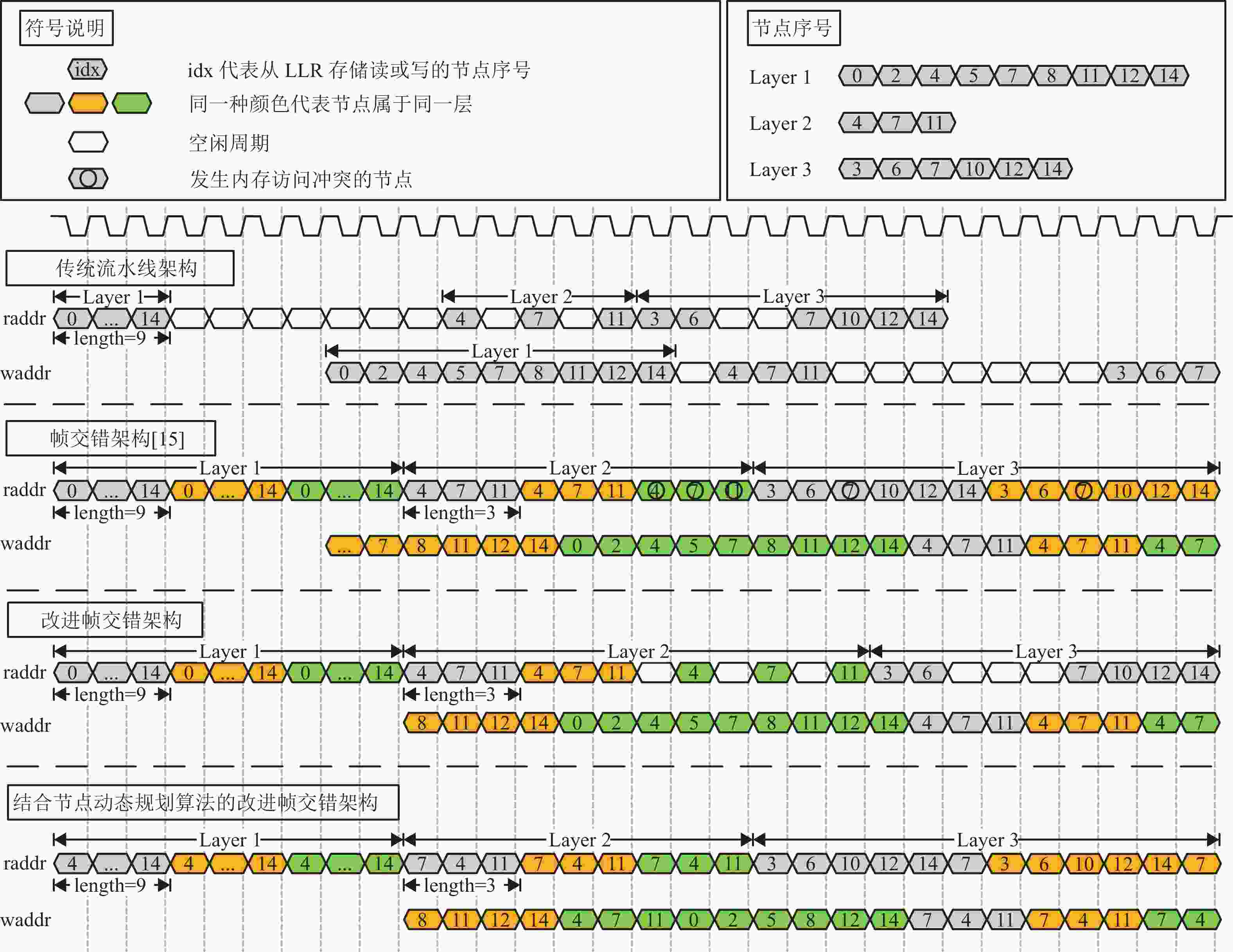
可以看到,在没有采用帧交错结构的情况下,传统译码结构完成一次译码迭代需要插入11个空闲周期。文献[16]提出了简单的帧交错结构,但在行重高度不对称的情况下仍然存在内存访问冲突问题。本文在此基础上做了改进,插入了必要的空闲周期,平均每一帧插入两个空周期,相比传统结构提升了吞吐量。
除了以上对于帧交错结构的改进,结合本文提出节点动态规划问题,能够进一步减少空闲周期的插入,极大地提高吞吐量。
-
本实验选择长度为2176,速率为1/3,基图为BG1的LDPC码,交错帧数为3。根据上述推导,本结构的吞吐量Th为:
式中,Fclk代表译码器工作频率;n代表码字长度;nc代表一次迭代所需要的周期,即基图的非零元数目;
$ {\bar n_l} $ 代表平均迭代次数。为了实验更具有可比性,采用归一化吞吐量进行对比,有:表3对比了本文提出的结构与已有文献在资源利用率和归一化吞吐量的比较,表中量化等级(6,8,6)表示6位初始LLR值,8位变量信息,6位校验信息;HUE表示单位资源的归一化吞吐量。从表中可以看到,虽然现有文献能够实现比本结构更高的吞吐量,但消耗了大量的资源。与已有文献相比,本文提出的结果能显著提高单位资源利用率。
方法 结构 HUE FPGA
开发板码长 量化等级 Fclk
/MHzThnorm
/Mb·s−1Slice
LUTsSlice Registers 36 k BRAMs 干单位LUT
吞吐量/Mb·s−1干单位Registers吞吐量
/Mb·s−1单位BRAMs
吞吐量/Mb·s−1本文帧交错结构 Zynq-7000 (2176, 704) (6,8,6) 250 1721.5 5910
(14.56%)2130
(2.62%)38
(35.51%)291.3 808.21 45.3 混合调度[12] Virtex-7 (26112, 8448) (8,8,6) 261 20900 100929
(23.3%)85431
(9.86%)136.5
(9.3%)207.08
(40.7%)244.64
(230.4%)153.11 灵活帧并行[15] Kintex-7 (10368, 8448) (8,8,6) 160 11740 74373
(73%)46517
(23%)198.5
(30%)157.85
(84.5%)252.38
(220.2%)59.14 全行并行[17] Virtex Ultrascale+ (26112, 8448) (7,7,4) 102.45 29000 1448762
(35.46%)211238
(2.59%)- 20.17
(1344.2%)137.286
(488.7%)- -
本文针对5G LDPC码中行重高度不均匀导致的内存访问冲突问题,提出了一种多帧交错译码结构,结合了节点多级缓冲机制、乒乓机制和节点动态规划算法。该结构能很好地解决内存访问冲突问题,提高吞吐量。未来,将继续优化帧交错译码器结构,主要集中于提高译码器的灵活性和兼容性,支持5G LDPC更多矩阵更多并行度的译码。
Pipeline Design of LDPC Decoder Based on Frame-Interleaving
doi: 10.12178/1001-0548.2023023
- Received Date: 2023-01-16
- Accepted Date: 2023-05-06
- Rev Recd Date: 2023-03-29
- Available Online: 2024-04-01
- Publish Date: 2024-03-30
-
Key words:
- frame-interleaving /
- low density parity check code /
- memory access conflict /
- node reordering
Abstract: The decoder of low density parity check code (LDPC) generally adopts an iterative algorithm based on node confidence update, which can be implemented in parallel and has very high throughput. In this paper, we propose a frame-interleaving decoding structure with high hardware utilization efficiency (HUE) features and develop a dynamic planning method for node reordering within layers, which can solve the memory access conflict problems. Compared with the existing structures, the proposed structure shows more efficiency with respect to hardware utilization.
| Citation: | HAN Guojun, YANG Weize, YE Zhenliang, ZHAI Xiongfei, SHI Zhiping. Pipeline Design of LDPC Decoder Based on Frame-Interleaving[J]. Journal of University of Electronic Science and Technology of China, 2024, 53(2): 194-200. doi: 10.12178/1001-0548.2023023

|











 DownLoad:
DownLoad: