 ISSN
ISSN 




-
语义分割技术作为计算机视觉的一部分,目的是为图像中的每个像素分配类别标签,被广泛应用于工业自动化[1]、医疗图像[2]等场景解析领域。尤其在面向自动驾驶的城市交通场景中,高效的语义分割模型可以对道路做出实时场景解析,为路径规划、避让行人障碍等提供有效的辅助信息。然而真实应用场景中往往要求语义分割网络同时具有较高的分割精度和较快的计算速度,这对语义分割的准确性和实时性均提出较高的要求,因此亟需研究出一种能够在分割精度和计算成本之间实现较好权衡的语义分割算法。
现有的提高语义分割准确度的策略大多是加大网络的深度,以期获得更加丰富的图像特征信息。目前分割效果较好的语义分割网络,如SegNet[3]、DeepLabV3+[4]、RefineNet[5]等都有较高的准确率。但这些网络算法具有较大的模型参数量和较高的计算复杂度,进而影响分割效率。为了将语义分割技术实现落地应用并获得实时处理图像信息的效果,轻量级神经网络设计成为实时语义分割任务的一个重要研究目标。
现有的轻量级网络如ENet[6]、ERFNet[7]、LEDNet[8]、CGNet[9]、DABNet[10]、FRNet[11]等的参数量都已经控制在1 MB以下。其中,ENet和SegNet是两大经典的轻量化模型,通过采用非对称的编解码结构和通道裁剪策略,SegNet的参数量仅为0.36M,而ERFNet利用非瓶颈残差结构并将标准卷积替换为非对称卷积,降低参数量的同时获得很好的分割精度。而Xception[12]使用深度可分离卷积替代标准卷积,增加网络深度的同时还减少了参数量。在Xception的基础上,MobileNet[13]引入深度可分离卷积和残差模块来实现模型的压缩和推理的加速,减少卷积操作带来的参数量和计算量的同时保持较好的分割性能。相较之下,ShuffleNet[14]运用通道混洗的策略,通过转置、分组卷积、通道乱序的方法来促进信息流动,精简模块的同时提高计算效率。尽管以上网络在参数量方面较小,并保证一定的分割精度,但仍然难以满足真实场景中的应用需求[15]。
此外,为了降低特征的维度并保留有效信息,现有的大多数语义分割网络均采用下采样池化操作,如最大池化、平均池化、随机池化等。但池化操作往往会使得图像分辨率下降,导致图像特征信息丢失。尽管已有研究者对池化操作的特征信息丢失问题进行改进,如采用带步长的卷积替代池化操作或采用低通滤波去除高频特征之后再进行下采样操作[16],但此类操作或增加计算量,或影响网络的特征表达能力。而离散小波变换(DWT)以其强大的时频分析能力,被广泛应用于信号与图像处理领域[17]。随着深度学习的不断发展,越来越多的研究也将其应用于卷积神经网络(CNN)的优化中。如,将DWT应用到编-解码器中,降低参数量的同时提高网络的运算速度[18];或将其结合残差网络,利用小波变换提高图像的恢复能力[19];或者,将其与注意力机制结合,加强对不同频率分量的特征注意力[20]。然而,现有的小波变换与CNN的组合方法并未充分发挥其多通道分频的优势,仍然具有较大的改进空间。
综合以上分析,本文提出了一个联合多连接特征编解码与小波池化的轻量级语义分割网络,简称称MLWP-Net(Multi-Link Wavelet-Pooled Network),包括:轻量化的逐步特征融合模块(Progressive Feature Fusion, PFF);基于小波变换理论的低频混合小波池化操作(Low-frequency-mixed Wavelet Pooling, LWP),用于实现高效的下采样操作;以及多分支并行空洞卷积解码器(Multi-branch Parallel Dilated Convolutional Decoder, MPDCD)。经大量实验验证,MLWP-Net具有计算复杂度低且分割精度高的优点。
-
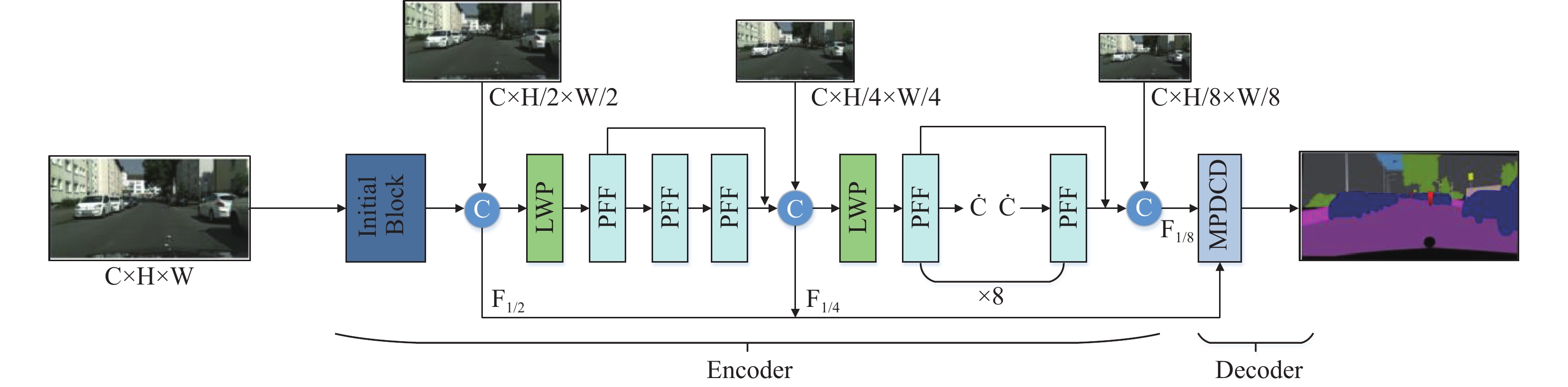
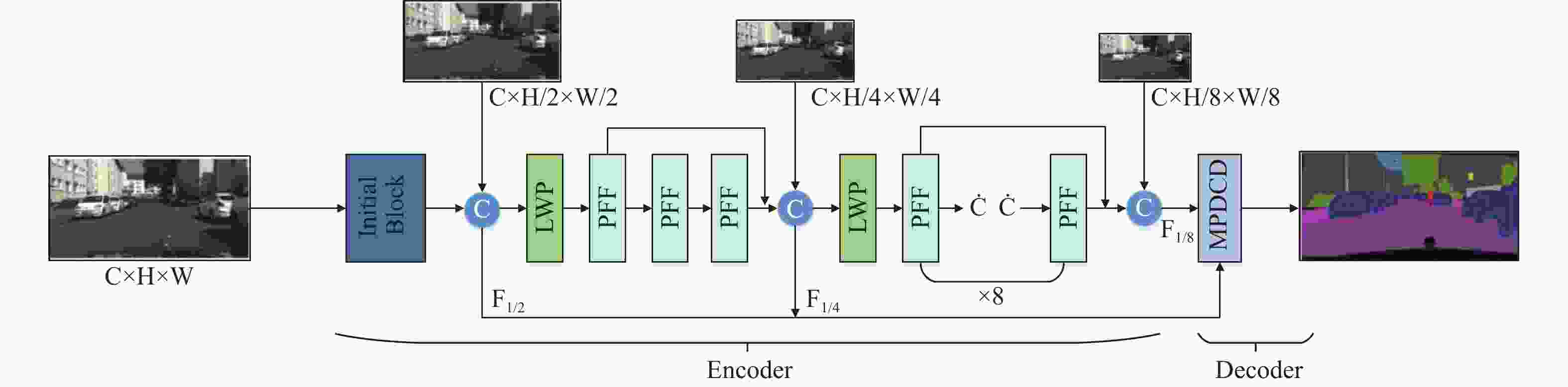
本文提出的基于编码器-解码器框架的MLWP-Net整体网络结构如图1所示。其中,编码器的主要组成包括初始标准卷积模块(Initial Block)、逐步特征融合(PFF)瓶颈结构以及低频混合小波池化(LWP)模块,解码器主要由MPDCD构成。其中,初始标准卷积模块用于对原始图像特征信息的提取;拼接(Concat)操作将不同分辨率的原始输入图像与不同卷积层的特征图进行拼接。本文所提的MLWP-Net基于多连接思想从不同深度的网络中获得不同尺度的特征和上下文信息,结合离散小波变换原理实现小波池化,在降低特征图分辨率的同时尽可能减少信息丢失,扩大网络通道数,并在解码时同样基于多连接思想接入主干网络不同层级的特征信息进行多分支特征融合,实现了对图像的准确分割解码。
-
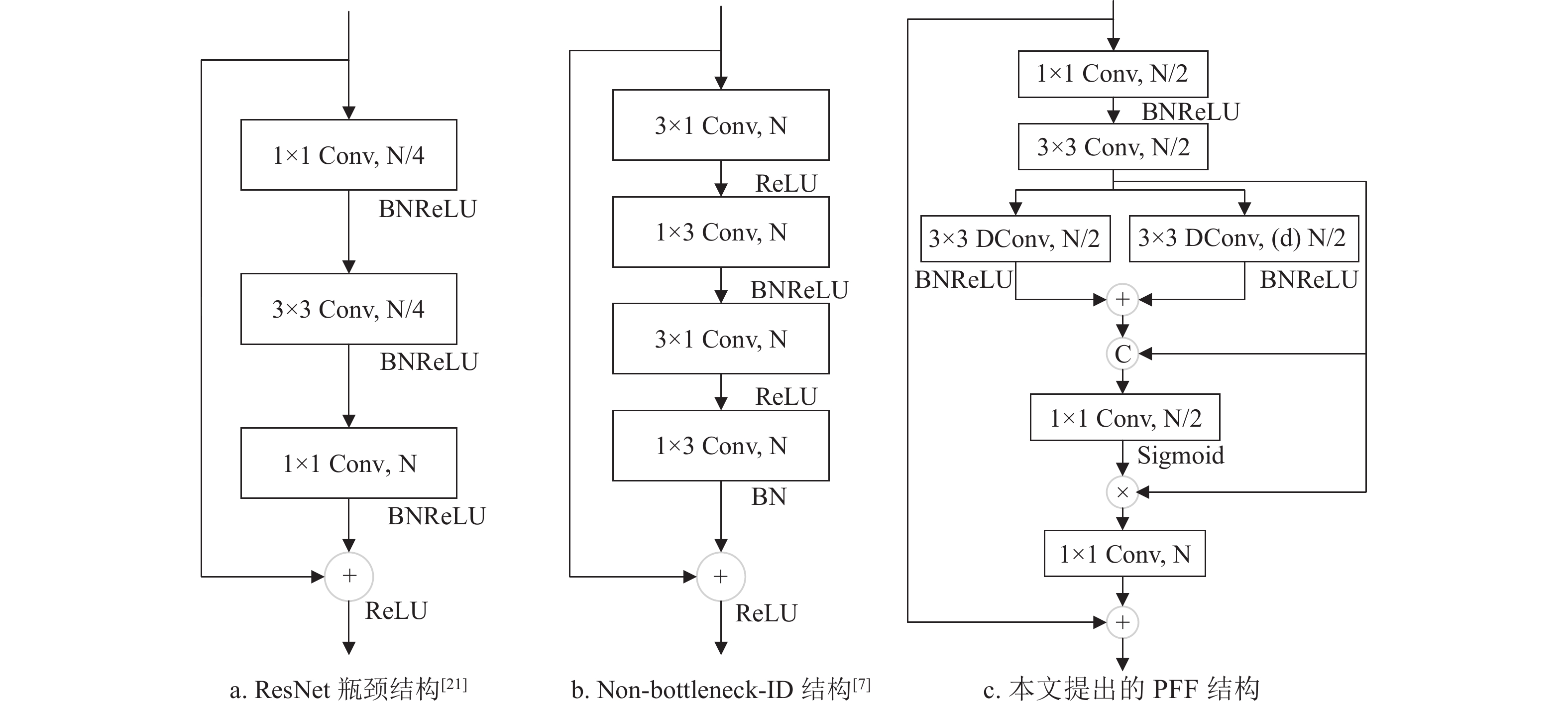
现存语义分割网络中存在网络整体参数量较大、计算复杂度高、计算速度慢等诸多问题,且随着网络模型深度的加深会带来网络退化问题(如图2a中ResNet[21]),或者,网络模型整体参数量虽小且计算速度快,但其特征提取能力不足(如图2b所示的Non-bottleneck-1D结构[7]),因此,大多数现有网络模型难以在分割准确性、计算速度、参数量三者之间实现较好的权衡。
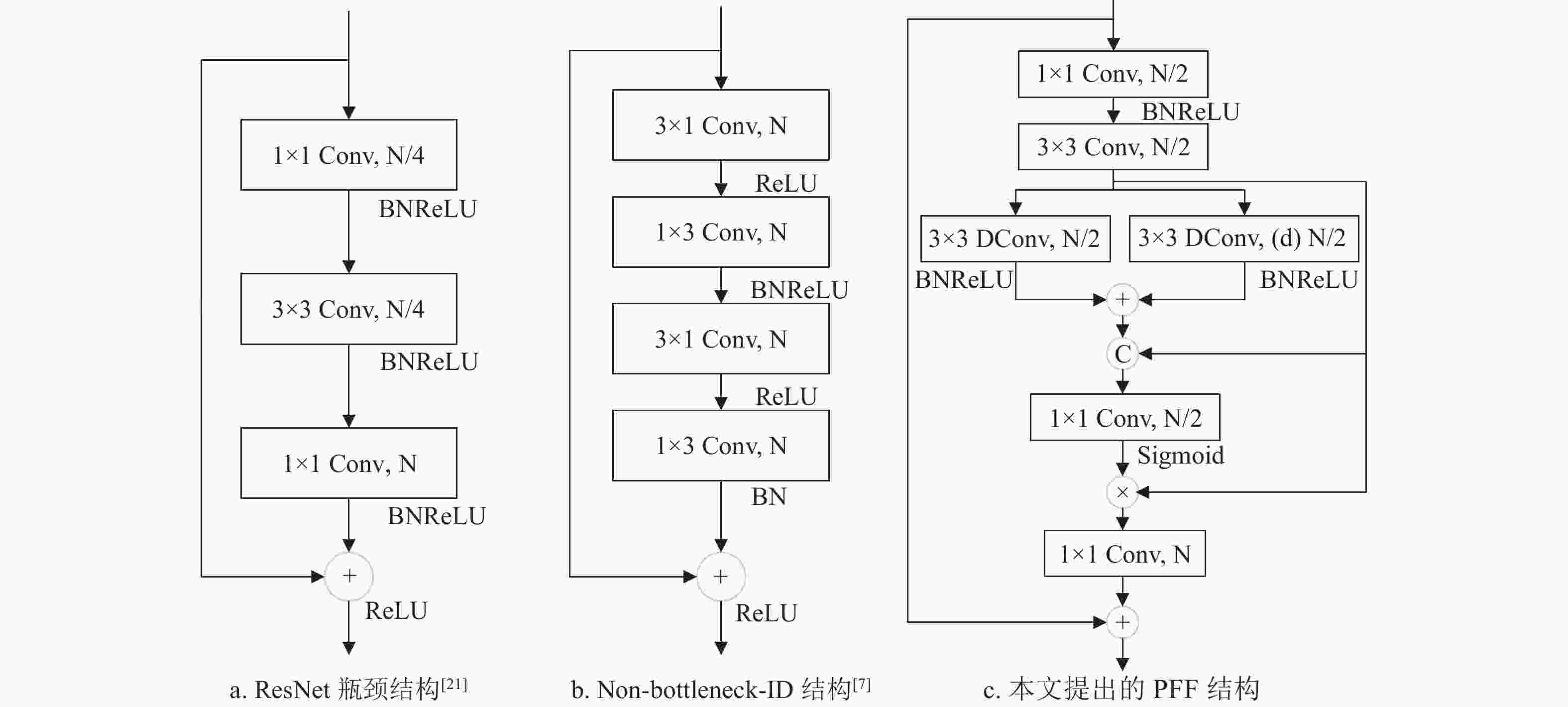
本文利用深度可分离卷积、空洞卷积和通道压缩策略设计了一个轻量级逐步特征融合的特征提取瓶颈结构PFF,如图2c所示,以获得更高的分割精度、更快的推理速度和更低的计算复杂度。不同于图2b的Non-bottleneck-1D在输入端使用1×3和3×1卷积模块代替一个标准3×3的卷积模块,本文首先在输入端应用1×1卷积来进行通道压缩,从而减少计算量,然后运用3×3标准卷积来提取局部特征信息,再用两个并行特征提取分支获取多尺度上下文特征信息,并将3×3卷积之后获取的局部信息与并行分支获取的多尺度上下文Concat起来,从而弥补由于网络层数加深带来的特征信息丢失问题,并且并行分支中的其中一条支路采用带有空洞率(d=3,5,7,9)的3×3深度可分离卷积,增加了网络的深度并扩大网络的感受野。通过1×1卷积将通道再次压缩至1/2后,利用Sigmoid计算通道注意力权重大小,与3×3标准卷积后的特征图进行乘积运算,聚合网络学习到的局部特征信息和多尺度特征信息,并筛选出重要的上下文特征信息。最后利用1×1卷积恢复通道数,与图2a中ResNet的瓶颈结构相似,MLWP-Net也利用残差结构补充原始输入图像的上下文信息,从而解决网络深度加深带来的退化问题,提高特征表达能力。
相较于现存其他特征提取模块而言,本文设计的逐步特征融合PFF模块在结构上使用多连接策略,可对局部信息和多尺度上下文信息进行有效聚合,从而提高语义分割网络的特征提取能力;且该模块使用通道压缩策略,实现模型的轻量化。
-
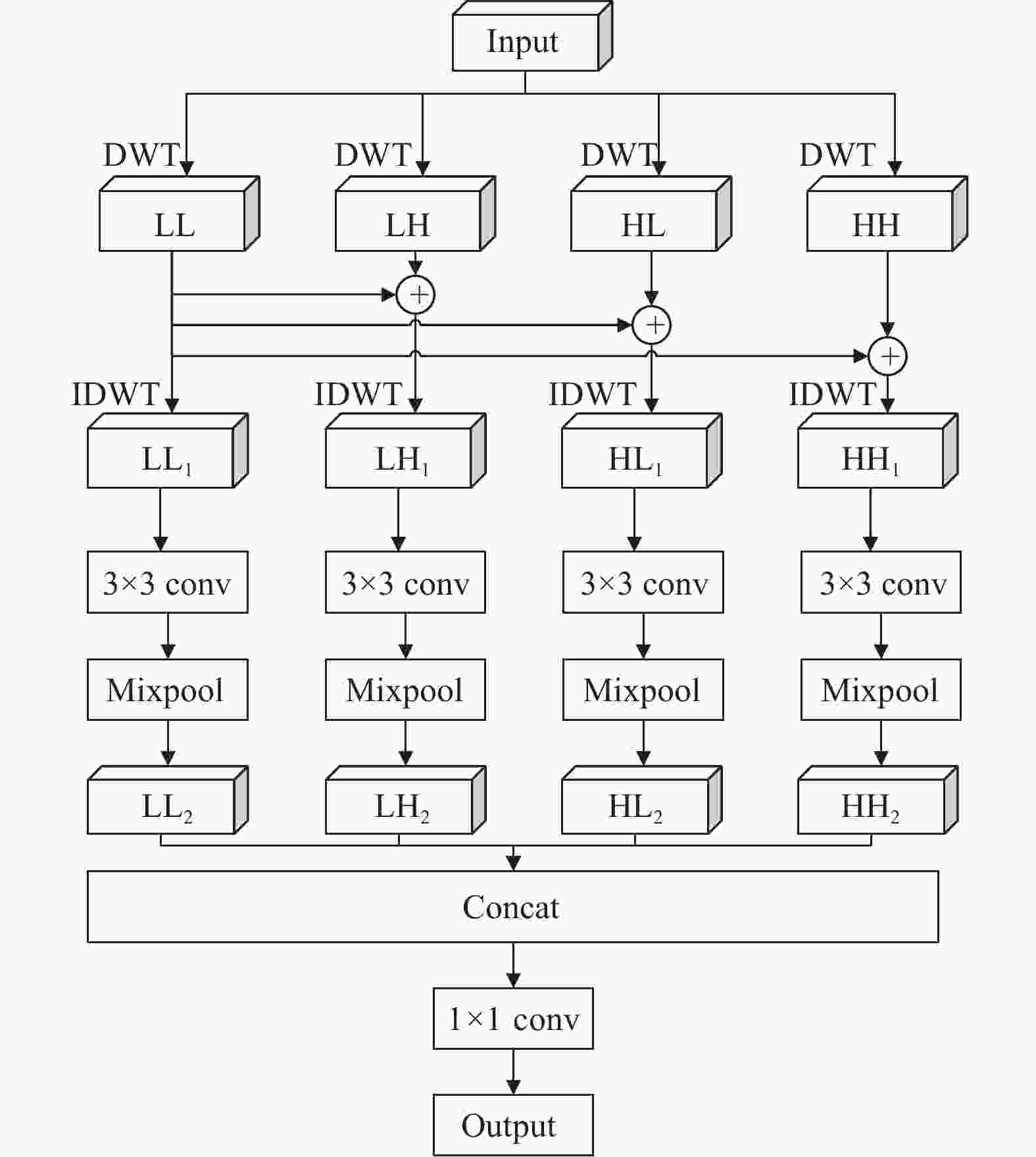
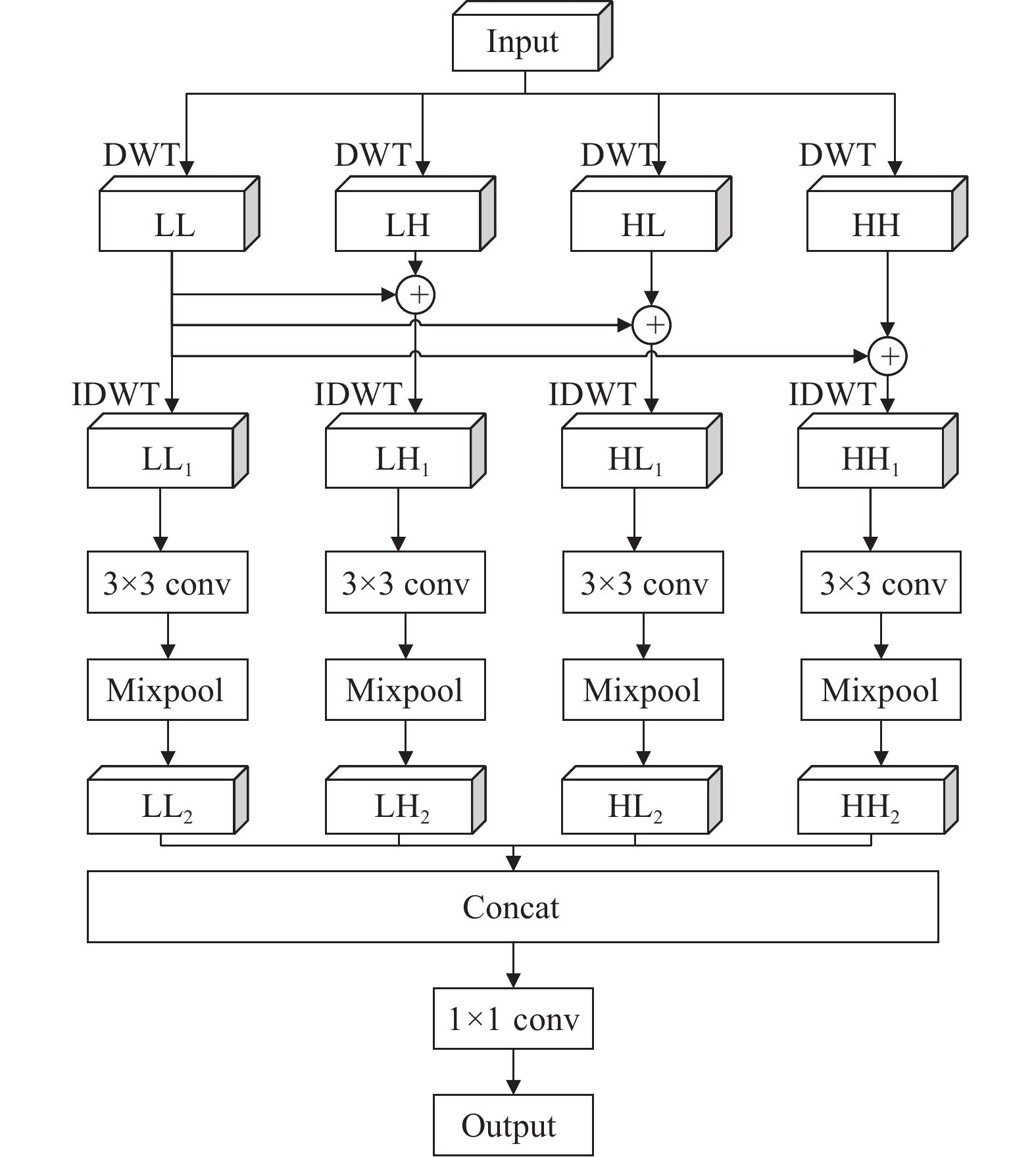
在特征提取过程中,产生的误差主要来源于两个方面:池化区域大小受限造成的估计值方差增大和卷积层参数误差造成估计均值的偏移。平均池化能够通过计算池化区域内的平均值,更多地保留图像的背景信息,从而减小第一种误差;最大池化能够通过计算池化区域内的最大值并记录该最大值所在输入数据中的位置,从而减小第二种误差,通常用于提取特征纹理或者高频边缘细节。然而上述两种直接下采样的池化操作均忽略了高频特征信息和低频特征信息在空间域与通道域的位置分布差异,容易造成在频域特征间的混叠效应[22],而且还会导致图像中部分特征信息丢失或弱化,小波变换是在傅里叶的基础上发展而来,可以扩展到时频域进行图像分析,离散小波变换可以捕获特征图的频率和位置信息,有利于保留纹理细节。
为了充分利用特征图的低频图像信息和高频边缘信息。本文采用Haar小波基函数进行多分支的低频混合小波池化,实现下采样效果。Haar小波基函数作为具备紧支性的正交小波函数,其正交性有利于对图像特征的精确重构;其对称性使得小波滤波呈线性相位,有利于提高网络的推理速度;且Haar小波计算复杂度低,不会对网络实时性造成太大影响。因此,本文充分结合小波变换的优势,利用不同频率特征信息,从空间域和通道域两个维度减少传统下采样操作导致的信息丢失问题,设计了一个高效的低频混合小波池化模块(Low-Frequency-Mixed Wavelet Pooling, LWP),如图3所示。首先在空间域上对输入特征图进行离散小波变换(DWT)处理,将其分解为低频系数LL(主要图像信息)、水平方向的高频系数HL、垂直方向的高频系数LH和对角方向的高频系数HH(细节图像信息)。然后,将低频系数LL分别与3个高频系数叠加后,再通过逆小波变换IDWT实现信息重构,即对相应空间域维度上的特征信息进行更新,分别获得重构系数LL1、LH1、HL1、HH1。此外,为了能够结合最大池化与平均池化的优点并减小图像特征尺寸,每类重构特征分别采取3×3卷积fconv3x3进行特征学习后再进行混合池化操作,得到新的重构系数LL2、LH2、HL2、HH2。由于分组重构过程每类特征都包含了低频特征,即在空间域上具有一定的空间特征信息,从而减少了后面卷积操作和池化操作造成的信息损失。最后,将4类特征拼接起来并通过1×1卷积fconv1x1恢复其通道数,得到最终经过小波分组重构和池化操作之后的特征输出,完成下采样操作,4个并行分支的计算过程为:
-
基于以上两个高效的逐步特征融合模块PFF和低频混合小波池化LWP模块,本文构建了一个有效融合多层次特征信息的编码器,实现轻量化且高精度特征提取。
如图1所示,在编码器初始阶段,MLWP-Net使用3个3×3标准卷积对原始图像进行预处理,其中为了改变原始输入图像的尺寸大小。经过初始阶段提取的特征图像与原始输入的1/2分辨率图像进行特征融合Concat,保持初始阶段提取的图像特征并补充细节信息,从而提高分割能力;使用LWP对输出特征图进行下采样操作,在降低特征图尺寸的同时尽可能保留全部特征信息。再使用3个PFF模块进行多尺度上下文特征信息提取,然后对输出特征图与原始输入的1/4分辨率图像和首个PFF的输出图像进行第二次特征融合,从而弥补不同网络深度的特征信息。为了进一步压缩模型,再次使用LWP对特征图进行下采样,并将经过下采样后的特征图输入到8个PFF模块中,进一步提取深层次的特征信息。最后,将最后一个PFF的输出特征图像与原始输入的1/8分辨率图像和第一个PFF的输出图像进行第三次融合,从而获得编码器的最终输出结果。
-
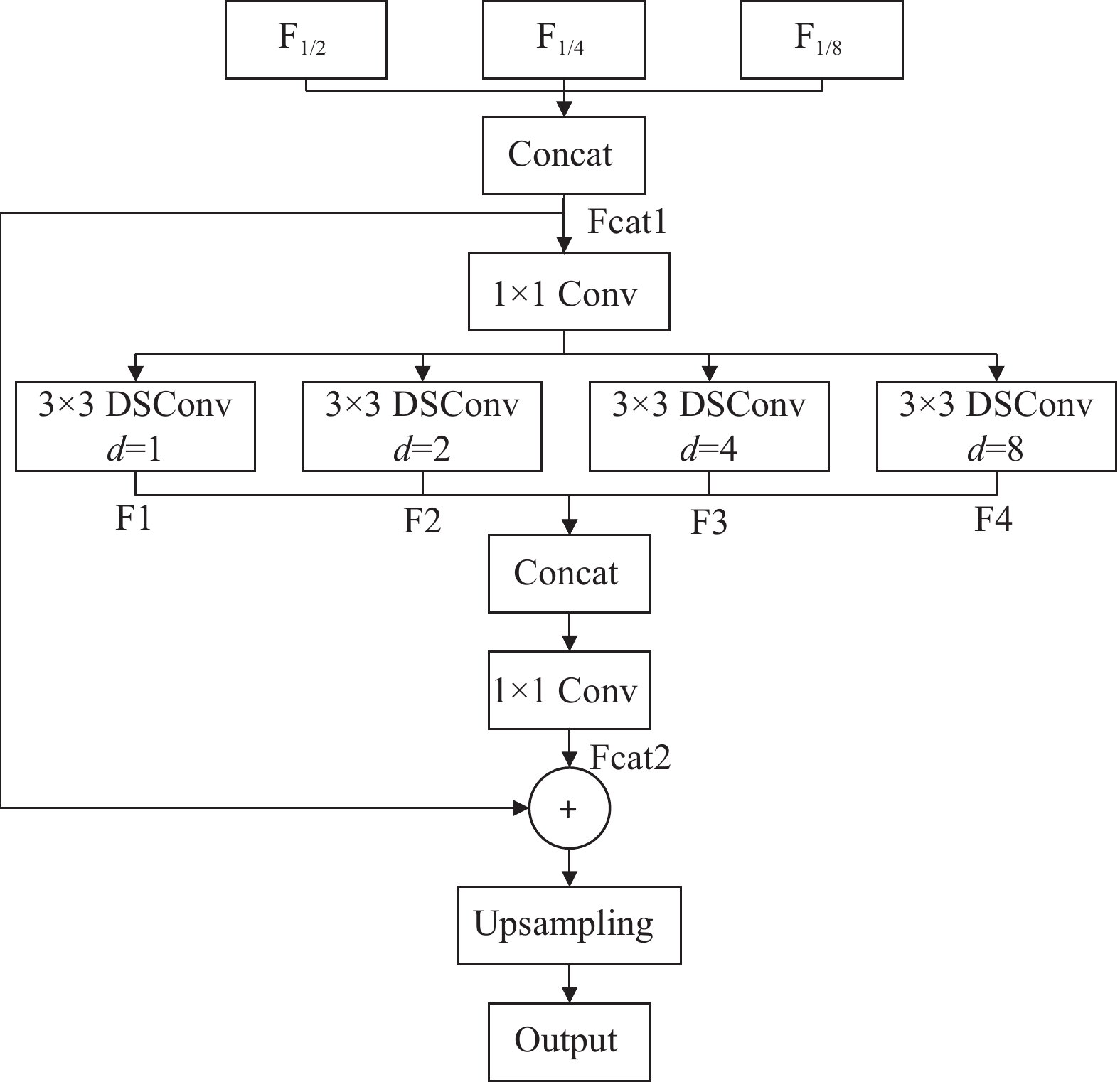
为了更有效地融合不同层级网络的特征信息,利用编码器所提取到的特征信息来指导像素级分类,从而完成解码,本文设计了一种多分支并行的空洞卷积解码器(MPDCD),如图4所示。
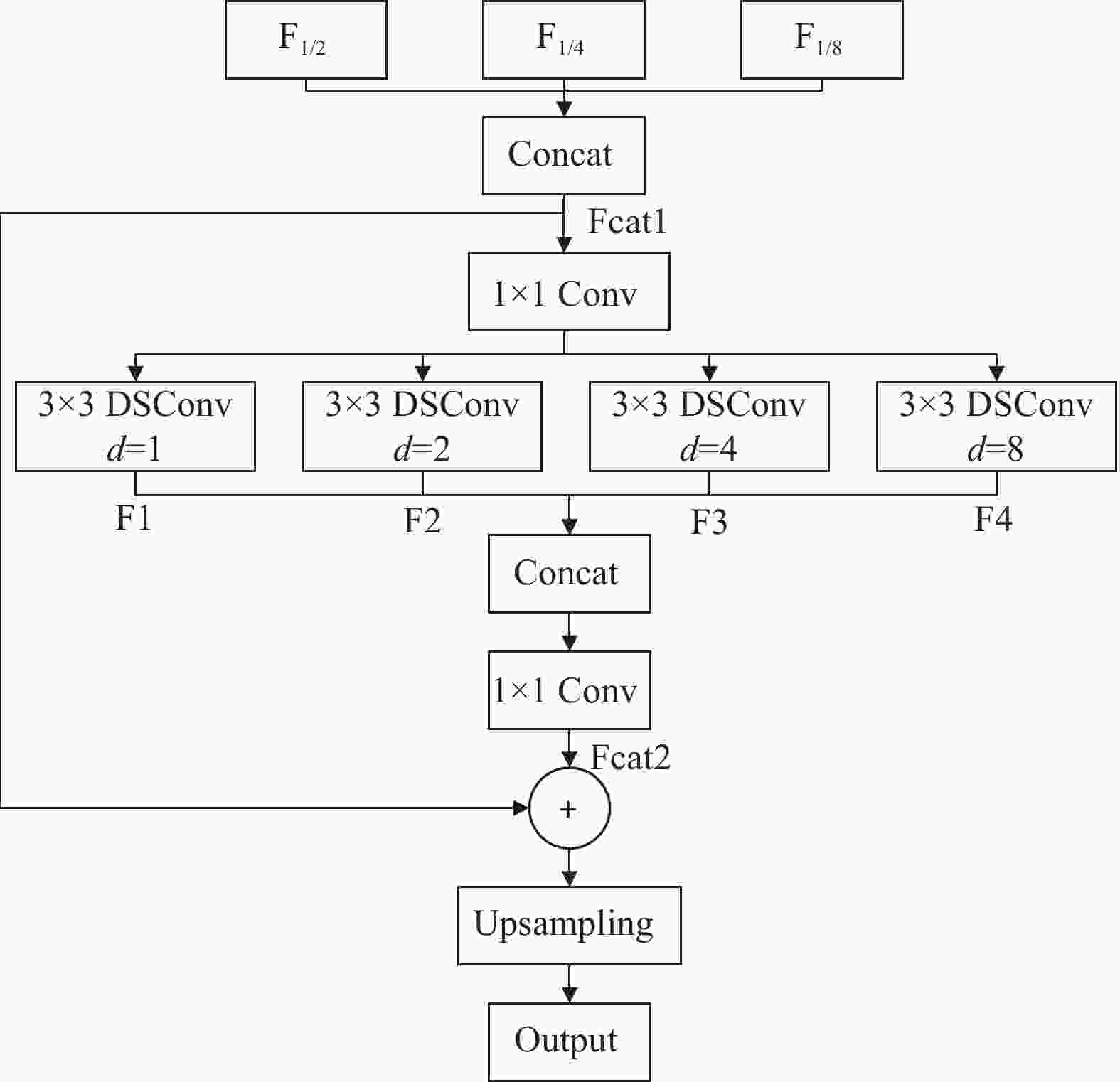
相较于DeepLab网络中的空洞空间池化金字塔 (Atrous Spatial Pyramid Pooling, ASPP)[23]模块而言,ASPP只利用编码器中最后一个输出特征图进行解码,MPDCD将主干网络中多个层级的特征输出F1/2、F1/4、F1/8融合后作为输入Fcat1,其次运用1×1卷积fconv1x1实现通道混洗,加强不同通道间的信息交流,并采用多分支扩展的方式,利用不同空洞率(d=1,2,4,8)的深度可分离卷积fDSConv再次进行特征学习,其中较小空洞率的深度可分离卷积有利于对小目标的识别,较大空洞率的深度可分离卷积能够在保持特征图尺寸不变的情况下增大特征感受野,从而完成多尺度上下文信息结合,得到多分支扩展融合后的输出Fcat2。为了进一步提高特征图恢复精度,再次结合3个不同层级的特征融合,共同指导图像特征信息的恢复,最后利用上采样操作将其恢复至原始输入图像的尺寸。经过MPDCD解码后,生成最终的预测结果y,计算过程为:
式中,F1/2、F1/4、F1/8分别为主干网络中编码器不同层级的输出特征;F1、F2、F3、F4分别为经过不同空洞率的深度可分离卷积之后的输出特征结果。
-
本次实验使用无人驾驶环境下的公开数据集Cityscapes[24]和CamVid[25]进行实验。Cityscapes数据集是一个大型城市道路场景语义分割数据集,该数据集由5 000张像素级标注图像组成,图像分辨率为1 024×2 048,包含19个类别,其中训练集为2 975张图像,验证集为500张图像,测试集为1 525张图像。CamVid数据集是一个从驾驶汽车角度拍摄的交通场景数据集,共计701张图像,图像分辨率为720×960,包含11个类别,其中训练集为367张图像,验证集为101张图像,测试集为233张图像。
-
本文提出的MLWP-Net均在CUDA11.4的Pytorch深度学习框架下使用单个RTX3090 GPU进行训练和测试。训练时,采用的优化策略为基于动量的批随机梯度下降,动量momentum设置为0.9,权重衰减为1.0×10−4,初始学习率为4.5×10−2,Power系数为0.9,使用交叉熵损失函数计算损失。训练过程中不采用其他预训练模型,对输入图像使用随机镜像和随机尺度方式进行预处理,基于Cityscapes测试集的实验使用512×1 024分辨率的图像;基于CamVid测试集的实验使用360×480分辨率的图像。
-
为了验证所提MLWP-Net以及各个模块的有效性,本文设计了多个与模块对应的消融实验,并基于Cityscapes数据集,将MLWP-Net与现有的实时性语义分割网络进行对比。记录由不同模块构成的骨干网络的分割精度(mIoU)、浮点运算量(GFLOPs)以及参数量(Params),实验结果如表1所示。
-
为了验证所提多连接逐步特征融合的瓶颈模块PFF的有效性,本文将ResNet的瓶颈模块、ERFNet的Non-bt-1D模块以及本文MLWP-Net的PFF模块分别作为编码器的主要特征提取模块,并基于Cityscapes验证集中分辨率为512×1 024的图像进行实验对比。编码器的输出结果仍然采用MLWP-Net的解码器进行解码。
从表1中可以看出,ResNet以最低0.57 MB的参数量实现了60.4%的分割精度,但其浮点计算量却较高,分割精度难以满足真实道路场景的应用需要。而Non-bt-1D受限于其非瓶颈结构,相比Bottleneck构成的骨干网而言,其参数量增加了0.42 MB,但其分割精度却提升到了71.8%。而由PFF模块构成的MLWP-Net网络相比Bottleneck构成的骨干网仅以0.2 MB不到的参数量提升了13.1%的分割精度;相比Non-bt-1D构成的骨干网而言,PFF模块不仅拥有更低的参数量和更少的计算复杂度,还实现了近2%的分割精度提高。以上消融实验表明,由PFF模块构成的骨干网络具有轻量化、更低计算复杂度和更强的特征提取能力的优点,满足于真实道路场景下的语义分割应用需求。
-
为了验证本文所提的低频混合小波池化模块LWP在图像下采样过程的有效性,将LWP分别应用到ERFNet、DABNet、ESNet中替代传统下采样DownSample模块,记录不同网络在使用LWP替换原有下采样操作前后网络评价指标的变化情况,实验结果如表2所示。
从表2中可以看出,不同网络在使用LWP操作后,虽然浮点计算量有轻微的上升,但各个网络的参数量均有所下降,且分割精度均有不同程度的提高。具体地,在使用LWP操作后,ERFNet、DABNet、ESNet在分割精度上分别增加了4.8%、0.5%、1.3%的mIoU。以上消融实验结果表明,低频混合小波池化模块不仅能够抑制传统下采样操作导致的信息丢失问题,并且能够实现分割精度的提高,同时还可以方便地将LWP嵌入到多种不同结构的卷积神经网络中,证实了该操作的有效性和通用性。
-
为了验证所提MPDCD解码器的图像特征恢复能力。本文将MPDCD解码器分别应用到CGNet、FRNet中替代网络原有解码器,分别记录不同网络使用MPDCD解码器前后在Cityscapes验证集上的分割精度、浮点计算量、参数量的变化情况,实验结果如表3所示。
从表3中可以看出,CGNet和FRNet在使用MPDCD解码器替代网络原有解码器后,其网络参数量均基本保持不变,而mIoU却有较大提升,分别增加了5.3%和0.7%。相比较而言,虽然多分支空洞卷积结构会增加部分计算复杂度,但网络分割精度却有较大提升,证明了MPDCD解码器能够提升不同网络对分割目标的空间信息特征恢复能力,具有轻量化、高准确率的优点。
-
小波基函数的选用需要结合信号本身的特点及其对网络分割精度、推理速度的影响。为了选取合适的小波基函数,本文分别针对不同的离散小波基函数进行实验对比。
从表4中可以看到,在网络其他条件均相同的情况下,所选用的Haar小波基函数能够使网络在CamVid数据集上实现68.2%的mIoU,而选用db1、rbio1.1、bior1.1小波基函数的网络实现分割精度分别为67.86%、67.38%、67.24%mIoU。Haar小波是具有紧支性和对称性的正交小波函数,其正交性有利于对图像特征信息的重构,且对称性有利于提高网络算法的推理速度。以上消融实验结果证明本文选用Haar小波作为基函数能够使网络在分割精度上更具优势。
Method 正交性 对称性 紧支性 Speed(fps) mIoU/% Haar 有 对称 有 95 68.2 db1 有 近似对称 有 94.8 67.8 rbio1.1 无 对称 无 95.3 67.4 bior1.1 无 不对称 有 92.1 67.6 -
为了检验MLWP-Net的整体性能,本文将其与其他轻量化实时性语义分割网络在Cityscapes数据集和CamVid数据集上进行性能对比,结果见表5和表6所示。
Method Pretrain Input Size mIoU/% Params/MB Speed/fps SegNet[3] ImageNet 360×640 56.1 29.5 38.2 RefineNet[5] ImageNet 512×1024 73.6 118.1 9.1 SQNet[27] ImageNet 512×1024 59.8 16.3 25.7 BiseNetV2[28] No 512×1024 73.6 6.2 51.0 ENet[6] No 512×1024 58.3 0.36 27.4 ERFNet[7] No 512×1024 68.0 2.1 41.9 LEDNet[8] No 512×1024 69.2 0.95 59.6 CGNet[9] No 512×1024 64.8 0.49 65.6 DABNet[10] No 512×1024 70.1 0.76 102 FRNet[11] No 512×1024 70.4 1.01 127 ESNet[26] No 512×1024 70.7 1.66 63.0 EDANet[29] No 512×1024 67.3 0.68 105.5 ESPNet[30] No 512×1024 60.3 0.36 146.0 ContextNet[31] No 1024×2048 66.1 0.85 57.7 Fast-SCNN[32] No 1024×2048 68.0 1.1 67.1 DFANet[33] ImageNet 1024×1024 71.3 7.8 100 LRNNet[34] No 512×1024 72.2 0.68 71 AGLNet[35] No 512×1024 71.3 1.12 52 DDPNet[36] No 768×1536 74.0 2.52 85.4 CSRNet-light[38] ResNet18 512×1024 74.0 —— 56 LETNet[39] No 512×1024 72.8 0.95 150 MLWP-Net (ours) No 512×1024 74.1 0.74 85.6 可以看出,在没有任何预训练的情况下,当输入图像分辨率为512×1024时,MLWP-Net仅以0.74 MB的参数量在Cityscapes数据集上实现了74.1%的分割精度;当输入图像分辨率为360×480时,MLWP-Net仅以0.74 MB的参数量在CamVid数据集上实现了最高68.2%的分割精度,其分割效果优于其他网络。MLWP-Net以更少的参数量实现了更高的分割精度。同时,作为轻量化网络,MLWP-Net的推理速度也远远超过实时性分割网络的要求。
Method Pretrain Input Size mIoU/% Params/MB Speed/fps SegNet[3] ImageNet 360×480 55.6 29.5 49.8 ENet[6] No 360×480 51.3 0.36 105.7 LEDNet[8] No 360×480 66.6 0.95 109.6 CGNet[9] No 360×480 65.6 0.50 112 DABNet[10] No 360×480 66.4 0.76 117 EDANet[29] No 360×480 66.4 0.68 232.2 ESPNet[30] No 360×480 55.6 0.36 297.6 DFANet[33] No 720×960 64.7 7.8 120.0 LRNNet[34] No 360×480 67.6 0.67 83 DDPNet[36] No 360×480 67.3 1.1 — MLWP-Net(ours) No 360×480 68.2 0.74 95 此外,本文不仅对多个网络在Cityscapes数据集上进行分割精度、参数量和推理速度对比,还列出了多个网络在Cityscapes测试集中每个类别对应的mIoU,如表7所示。从表7中可以看出,相比其他网络,MLWP-Net对于道路(Roa)、人行道(Sid)、墙面(Bui)等14种物体类别均达到最高的分割精度,这表明MLWP-Net中利用其多连接的逐步特征融合模块PFF和多分支空洞卷积特征融合解码器MPDCD能够进一步加强对图像语义信息的提取能力和对图像中细小目标空间细节的恢复能力,MLWP-Net对该数据集内的卡车和自行车等类别的分割效果相对现有最佳模型有微小的下降,但仍然具有可比拟的分割精度。
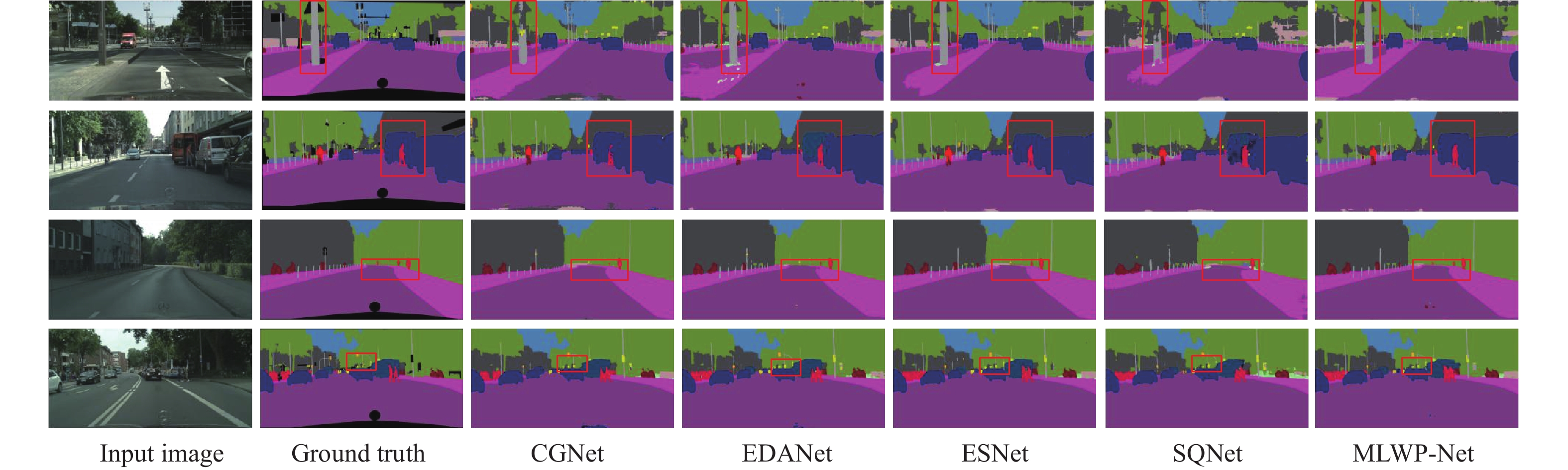
为了更加直观地探究和评价MLWP-Net网络对城市交通道路场景的分割效果,本文选择有代表性的轻量化实时性网络CGNet、EDANet、ESNet、SQNet与MLWP-Net的可视化分割效果进行比较与分析。本文在在Cityscapes数据集随机抽取了4张样本图像进行了分割效果的细节对比,如图5所示。图5第一行场景和第四行场景中,MLWP-Net精确地定位柱子和交通灯的边界并进行分割,相比其他网络更加准确地实现了分割边界的连续性和分割的准确性,这得益于本文提出的多连接逐步特征融合瓶颈模块PFF,有利于对图像边缘上下文信息进行准确提取;第二行场景中,其余网络模型虽然分割出卡车和人,但其交界处出现了误分类和分割不连续的问题,而MLWP-Net不仅能够正确地将不同类别分割,且不会受到不同类别的影响。这依赖于MPDCD解码器的多尺度特性,能够充分利用不同尺度上下文信息进行类别分割,这对复杂场景下的语义分割有较大的提升效果。从图5第三行场景中可以看到远处的人物很小且人行道很长,太小的目标和太长的目标都容易给分割增加难度,与其他模型分割的细节对比可以看出,MLWP-Net不仅能够分割出很长的人行道,对细小的人物也能够实现准确分割。随着图像分辨率下降,下采样操作容易造成信息丢失,而本文采用的LWP操作能尽可能减少信息丢失的同时完成下采样操作,从而实现对远处细小的人物的准确分割。
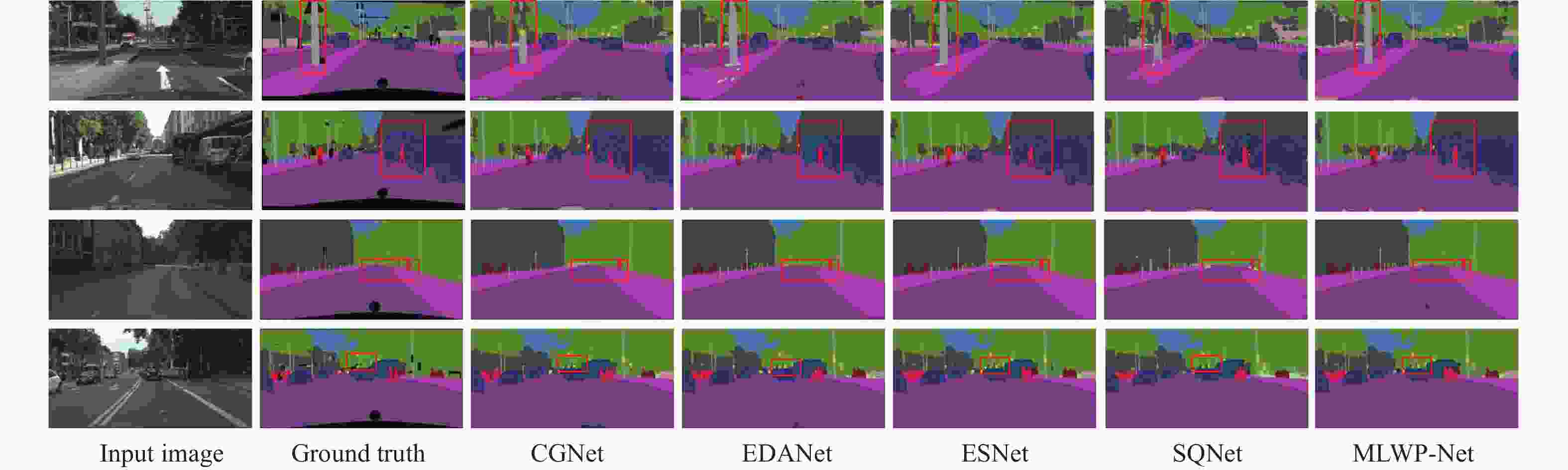
Method Roa Sid Bui Wal Fen Pol TLi TSi Veg Ter Sky Ped Rid Car Tru Bus Tra Mot Bic Class Cat SegNet[3] 96.4 73.2 84.0 28.4 29.0 35.7 39.8 45.1 87.0 63.8 91.8 62.8 42.8 89.3 38.1 43.1 44.1 35.8 51.9 57.0 79.1 ENet[6] 96.3 74.2 75.0 32.2 33.2 43.4 34.1 44.0 88.6 61.4 90.6 65.5 38.4 90.6 36.9 50.5 48.1 38.8 55.4 58.3 80.4 ERFNet[7] 97.2 80.0 89.5 41.6 45.3 56.4 60.5 64.6 91.4 68.7 94.2 76.1 56.4 92.4 45.7 60.6 27.0 48.7 61.8 66.3 85.2 LEDNet[8] 98.1 79.5 91.6 47.7 49.9 62.8 61.3 72.8 92.6 61.2 94.9 76.2 53.7 90.9 64.4 64.0 52.7 44.4 71.6 70.6 87.1 CGNet[9] 95.5 78.7 88.1 40.0 43.0 54.1 59.8 63.9 89.6 67.6 92.9 74.9 54.9 90.2 44.1 59.5 25.2 47.3 60.2 64.8 85.7 DABNet[10] 97.9 82.0 90.6 45.5 50.1 59.3 63.5 67.7 91.8 70.1 92.8 78.1 57.8 93.7 52.8 63.7 56.0 51.3 66.8 70.1 87.0 ESNet[26] 98.1 80.4 92.4 48.3 49.2 61.5 62.5 72.3 92.5 61.5 94.4 76.6 53.2 94.4 62.5 74.3 52.4 45.5 71.4 70.7 87.4 SQNet[27] 96.9 75.4 87.9 31.6 35.7 50.9 52.0 61.7 90.9 65.8 93.0 73.8 42.6 91.5 18.8 41.2 33.3 34.0 59.9 59.8 84.3 EDANet[29] 97.8 80.6 89.5 42.0 46.0 52.3 59.8 65.0 91.4 68.7 93.6 75.7 54.3 92.4 40.9 58.7 56.0 50.2 64.0 67.3 85.8 ESPNet[30] 97.0 77.5 76.2 35.0 36.1 45.0 35.6 46.3 90.8 63.2 92.6 67.0 40.9 92.3 38.1 52.5 50.1 41.8 57.2 60.3 82.2 LAANet[37] 97.9 82.9 91.0 47.5 51.5 59.3 66.0 70.3 92.3 69.9 94.7 81.8 61.4 94.2 58.6 74.5 55.1 54.3 69.4 73.6 88.4 MLWP-Net(ours) 98.1 83.4 91.7 55.4 52.5 62.1 67.1 71.8 92.7 70.0 95.0 83.1 63.3 94.7 60.2 75.7 62.5 56.9 71.3 74.1 89.0 综合以上可视化结果分析,本文所提MLWP-Net能够尽可能实现分割边缘的准确性和连续性,进而实现对细小目标和连续大目标的准确分割,取得了较好的分割效果。
-
本文提出了一种渐进式特征融合与低频混合小波池化结合的轻量化语义分割网络MLWP-Net,解决了现有语义分割网络中存在的特征信息提取不足和网络参数量较大等问题。一方面,在编码器端主要设计了轻量化的多连接逐步特征融合PFF模块和通用型的低频混合小波池化LWP操作,应用前者实现了上下文信息的有效聚合,从而高效地提取图像特征;应用后者解决了现有网络中下采样操作导致的特征信息丢失问题,高效地完成下采样操作,并可插入其他分割网络中作下采样操作。另一方面,提出了多分支空洞卷积特征融合MPDCD解码器,有效结合多尺度上下文特征实现图像空间信息的高效恢复。
与现存流行的实时语义分割网络对比,MLWP-Net在保证高精度的前提下,大幅度减少了模型参数量,对移动终端领域有很好的应用前景,尤其适用于对准确性和时效性要求较高的自动驾驶中的道路场景分割任务中。
Lightweight Semantic Segmentation by Combining Multi-Link Feature Codec with Wavelet Pooling
doi: 10.12178/1001-0548.2023124
- Received Date: 2023-04-25
- Rev Recd Date: 2023-11-11
- Available Online: 2024-04-30
-
Key words:
- real-time semantic segmentation /
- lightweight neural network /
- multi-link feature fusion /
- wavelet pooling /
- multi-branch dilated convolution
Abstract: Semantic segmentation is currently one of the basic technologies in the field of scene understanding. Existing semantic segmentation networks usually result in complex structures, a large number of parameters, excessive loss of image feature information, and low computational efficiency. To address these problems, this work proposes a lightweight semantic segmentation network named MLWP-Net (Multi-Link Wavelet-Pooled Network) which combines features with multiple connections and wavelet pooling based on the encoder-decoder framework and discrete wavelet transform (DWT). In the encoding phase, a lightweight feature extraction bottleneck was designed by combining with the depthwise separable convolution, dilated convolution, and channel compression, using a multi-link strategy to fuse multi-level features; besides, a low-frequency-mixed wavelet pooling operation was employed to replace the traditional downsampling operation for effectively reducing the information loss during the encoding process. In the decoding stage, a multi-branch parallel dilated convolutional decoder is designed to fuse multiple features linked to the different layers in the encoder to recover the image resolution in parallel. The experimental results show that our MLWP-Net achieves 74.1% and 68.2% mIoU segmentation accuracy on the datasets of Cityscapes and Camvid with only 0.74M parameters, which demonstrates its effectiveness for semantic segmentation.
| Citation: | YI Qingming, WANG Yu, SHI Min, LUO Aiwen. Lightweight Semantic Segmentation by Combining Multi-Link Feature Codec with Wavelet Pooling[J]. Journal of University of Electronic Science and Technology of China. doi: 10.12178/1001-0548.2023124

|

 DownLoad:
DownLoad: