 ISSN
ISSN 





-
近年来,盲源分离理论在无线通信领域中的应用受到了国内外学者的广泛关注[1-4]。盲源分离是指仅从观测混合信号中分离或提取期望的源信号和辨识混合矩阵。在盲源分离技术的辅助下,无线通信系统中频繁使用的导频序列可以免除或减少,进而提高系统的频谱效率;同时在先验信息缺乏的情况下,如信道未知或不可预知干扰,也能成功地分离出源信号信息,提高系统源信号恢复的鲁棒性。因此,研究无线通信盲分离方面的问题具有重要意义。
本文关注欠定盲源分离中欠定盲辨识问题,它对于实现欠定中的源信号恢复是至关重要的一步。现有的欠定盲辨识算法可以大致分为两大类,第一类是基于源信号稀疏性的聚类算法[4, 5],需要假设信源是稀疏性的或可以通过一些预处理线性变换得到稀疏源信号,如短时傅里叶变换、小波变换等。典型的代表性算法是degenerate unmixing estimation technique (DUET)算法和time frequency ratio of mixtures (TIFROM)算法[4-5]。这类算法依据观测混合信号稀疏化后的散点图特点,利用聚类算法穷举搜索来估计混合向量空间,从算法复杂度看,代价较高,尤其当观测通道数大于2时,实现比较困难。而且源的稀疏性要求一定程度上限制了此类算法的在实际中的应用范围。第二类算法是基于统计特征代数结构的张量分解[6-10],这类算法借助张量模型分解的唯一性特性,不需要源的稀疏性约束,应用范围更广。此类算法的一般原则是,首先基于统计特征建立一系列核函数,接着利用核函数堆叠三阶张量模型,最后利用平行因子分解求混合矩阵。典型的代表算法有基于二阶协方差的second-order covariance based blind identification of undertetermined mixtures (SOBIUM)[6]算法和基于四阶累积量的fourth-order cumulant based blind identification of undertetermined mixtures (FOBIUM)[7]算法。对于上述算法的核函数建立,由于四阶累积量的估计较为复杂,且需要较长的采样才能更好地提取统计信息;而二阶协方差又失去了四阶累积量抗噪声性。实际中为了更好地提取统计信息需要建立大量的核函数,再利用平行因子分解,其实现的复杂度较高。
基于提取更优的统计信息和降低上述算法的复杂度两方面考虑,本文提出了两个新的策略。一方面,基于一种新的统计方式建立核函数,即广义协方差[11-12],能够更好地从采样的数据中提取统计信息,它不仅含高阶的统计信息,而且维持着二阶协方差简单的二维数值结构。另一方面,借助塔克(Tucker)张量分解[8, 13]用于估计混合矩阵,原来构建的张量模型被压缩为一个低维的核张量,再进行基于交替最小二乘的平行因子分解估计混合矩阵,可以有效地减少计算量和运行时间,降低算法的复杂度。理论分析和仿真实验证明了提出的算法generalized covariance based blind identification of undertetermined mixtures (GCBIUM)与SOBIUM和FOBIUM算法相比,在计算复杂度和辨识性能上具有更好的竞争优势。
HTML
-
考虑P个窄带统计独立信源的含噪声混合,由N个传感器组成的天线阵列接收。接收混合信号可以表示为[6-7]:
式中,随机向量$ \mathit{\boldsymbol{x}}(t)\in {{C}^{N}} $表示传感器阵列观测的混合信号;C表示复数域;随机向量$ \mathit{\boldsymbol{s}}(t)\in {{C}^{P}} $表示源信号;sp(t)表示st的第p分量;A表示N×P维的混合矩阵,描述了信源被传感器接收的信道传输特性;ap表示混合矩阵的第p个列向量;nt表示零均值复高斯。盲辨识的目的是指从观测的混合信号xt中估计出混合矩阵A。当观测的传感器数目少于观测的信源数,即N < P时,是一种在无线通信中比较重要的接收模型,也是现今盲源分离问题的热点和难点问题。
-
定义:设随机变量$ \mathit{\boldsymbol{x}}\in {{C}^{N}} $,映射函数$ {{\mathit{\boldsymbol{g}}}_{1}}(\cdot ):{{C}^{N}}\to {{C}^{{{N}_{1}}}} $和$ {{\mathit{\boldsymbol{g}}}_{2}}(\cdot ):{{C}^{N}}\to {{C}^{{{N}_{2}}}} $,g1(x)和g2(x)关于x在任意处理点$ \mathit{\boldsymbol{ }}\!\!\tau\!\!\rm{ }\in {{C}^{N}} $的广义互协方差定义为[11]:
当对于相同的映射函数即广义自相关函数表示为:
式(2)中的$ {{\mathrm{ }\!\!\eta\!\!\text{ }}_{\mathrm{x}}}[\mathrm{g}(\mathrm{x});\mathrm{ }\!\!\tau\!\!\text{ }] $为广义均值,定义为:
式中,E[·]表示期望;(·)H共轭转置运算。当处理点取为0向量时,广义协方差和广义均值即为常规的协方差和均值,和它们具有相似的性质。当g(x)=x时,广义协方差矩阵与x的第二广义特征函数在处理点τ的Hessian矩阵相同。下面给出两个需要用到的广义协方差性质[11]。
1) 线性变换
设$ \mathit{\boldsymbol{A}}\in {{C}^{N\times P}} $和$ \mathit{\boldsymbol{n}}\in {{C}^{N}} $是线性变换矩阵和向量,$ \mathit{\boldsymbol{s}}\in {{C}^{P}} $为随机变量,如果存在线性变换x=As+n,那么有广义协方差矩阵:
2)独立性
如果$ \mathit{\boldsymbol{s}}\in {{C}^{P}} $统计独立,对所有存在的处理点τ,$是一个对角矩阵。
-
根据前面广义协方差矩阵的性质,可以建立起核函数,表示混合矩阵与观察混合信号的广义协方差矩阵间的关系,即:
为了书写的简洁性又不失一般性,括号中省略了随机变量,即式与式是相同的,且$ {\mathit{\boldsymbol{ \boldsymbol{\varPsi} }}_\mathit{\boldsymbol{s}}}({\mathit{\boldsymbol{A}}^{\rm{H}}}\mathit{\boldsymbol{\tau }}) $是对角矩阵。考虑使用K个不同处理点$ {\mathit{\boldsymbol{\tau }}_1}, {\mathit{\boldsymbol{\tau }}_2}, \cdots, {\mathit{\boldsymbol{\tau }}_K} $的核函数提取统计信息,用于建立张量分解模型,表示为:
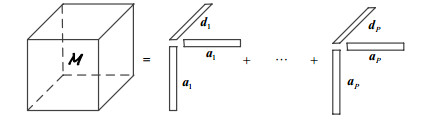
将式中的$ \mathit{\boldsymbol{ \boldsymbol{\varPsi} }}_\mathit{\boldsymbol{x}}^1, \mathit{\boldsymbol{ \boldsymbol{\varPsi} }}_\mathit{\boldsymbol{x}}^2, \cdots, \mathit{\boldsymbol{ \boldsymbol{\varPsi} }}_\mathit{\boldsymbol{x}}^K $堆叠为张量$\mathit{\boldsymbol{\mathcal{M}}} \in {C^{N \times N \times K}}$,其中张量的元素值表示为$ {(\mathit{\boldsymbol{\mathcal{M}}})_{ijk}} \buildrel \Delta \over = {(\mathit{\boldsymbol{ \boldsymbol{\varPsi} }}_\mathit{\boldsymbol{x}}^k)_{ij}} $,i=1, 2, …N,j=1, 2, …N,k=1, 2, …K。定义矩阵$\mathit{\boldsymbol{D}} \in {C^{K \times P}}$,其元素值,p=1, 2, …P,表示矩阵D的第k行第p列的元素是对角矩阵$ {\mathit{\boldsymbol{ \boldsymbol{\varPsi} }}_\mathit{\boldsymbol{s}}}\left( {{\mathit{\boldsymbol{A}}^{\rm{H}}}{\mathit{\boldsymbol{\tau }}_k}} \right) $的第p个元素。$ \mathit{\boldsymbol{\mathcal{M}}} $的张量分解表示为:
进一步可以表示向量外积形式:
式中,aip是混合矩阵A的元素;(·)*表示共轭;°表示向量外积;{ap}和{dp}分别是A和D的列向量。式是张量$\mathit{\boldsymbol{\mathcal{M}}}$分解为p个秩1分量之和,称为平行因子分解(parallel factor model, PARAFAC)或规范/标准分解(canonical decomposition, CP)[6-7, 13],张量规范分解如图 1所示。式中,各个秩1分量是由不同的信源对$\mathit{\boldsymbol{\mathcal{M}}}$的成分组成。对于张量信源分离意味着计算式的分解形式,只要保证其是唯一性的分解,就可以辨识混合矩阵。张量分解的唯一性条件需要矩阵的Kruskal秩概念[6],即矩阵存在任意的最大k列使其独立的线性无关组。式的唯一性分解条件,当且仅当满足下列秩条件[6]:

式中,k(·)示矩阵的Kruskal秩。标准的计算式的分解方法是交替最小二乘(altenating least squares, ALS)算法,即最优化代价函数:
为了保证分解算法具有强健的性能,不论是基于协方差矩阵或四阶累积量,还是本文所提的广义协方差建立核函数构建张量$ \mathit{\boldsymbol{\mathcal{M}}} $,为了聚集更多的统计信息,K的取值一般较大。但是,较大的K值会导致计算量过高,提高了复杂度,收敛速度降低。
为了保证统计信息的完善和降低复杂度,本文首先用Tucker分解将张量$ \mathit{\boldsymbol{\mathcal{M}}} $压缩成一个核张量,再进行标准的CP分解。Tucker分解相当于三维的主成分分析,可以保证信息的完整性,不影响分离效果,可以降低计算复杂度。
Tucker分解中,由广义协方差矩阵$ {\mathit{\boldsymbol{ \boldsymbol{\varPsi} }}_\mathit{\boldsymbol{x}}}({\mathit{\boldsymbol{\tau }}_k}) $组成的张量$ \mathit{\boldsymbol{\mathcal{M}}} $被压缩。因为混合矩阵A是列满秩的,广义协方差矩阵$ {\mathit{\boldsymbol{ \boldsymbol{\varPsi} }}_s}({\mathit{\boldsymbol{A}}^{\rm{H}}}{\mathit{\boldsymbol{\tau }}_k}) $是对角的,张量$ \mathit{\boldsymbol{\mathcal{M}}} $按某个维度展开的模1、模2和模3矩阵分别表示为、和。矩阵Mn的秩称为张量$ \mathit{\boldsymbol{\mathcal{M}}} $的n-秩(n=1, 2, 3),其中M1和M2的秩表示为:
记$ {\rm{ran}}{{\rm{k}}_3}(\mathit{\boldsymbol{\mathcal{M}}}) = {\rm{rank}}({\mathit{\boldsymbol{M}}_3}) = L $,L≤K,则$ \mathit{\boldsymbol{\mathcal{M}}} $是一个秩-(N, N,L)张量。因而,张量$ \mathit{\boldsymbol{\mathcal{M}}} $的塔克分解称为Tucker-1分解,如图 2所示,可以表示为:

式中,×n(n=1, 2, 3)表示张量的模n乘[6, 13];$ \mathit{\boldsymbol{\mathcal{T}}} \in {C^{N \times N \times L}} $称为核张量;I是N×N的单位矩阵;$ \mathit{\boldsymbol{G}} \in {C^{K \times L}} $的每列是酉正交向量,可以等价于一个二维的主成分分析,因为:
式中,是核张量$ \mathit{\boldsymbol{\mathcal{T}}} $的模3矩阵。包含了M3的L个左奇异向量。因为K>L且G是列酉正交矩阵,得出:
因此核张量可以表示为:
因为式的Tucker分解的第一和第二因子矩阵是单位矩阵,因此核张量$ \mathcal{T} $也是一个对称张量。
同张量$ \mathcal{M} $与式的分解形式相似,核张量$ \mathcal{T} $的规范分解如图 3所示,表示为:
式中,${{\mathit{\boldsymbol{\tilde a}}}_p}$和${{\mathit{\boldsymbol{\tilde d}}}_p}$分别表示矩阵$ {\mathit{\boldsymbol{\tilde A}}} $和$ {\mathit{\boldsymbol{\tilde D}}} $的第p列,通过核张量求出了矩阵$ {\mathit{\boldsymbol{\tilde A}}} $,然而为了辨识混合矩阵A,需要从$ {\mathit{\boldsymbol{\tilde A}}} $中解压缩出A。注意到Tucker-1分解是固定第一和第二因子矩阵是单位矩阵,所以可以简化解压缩直接还原得到混合矩阵[8]:

-
一方面,考虑核函数来自不同的统计代数结构。本文所提的GCBIUM算法和经典的SOBIUM算法都是来自二维的代数结构,分别是广义协方差和协方差。FOBIUM来自四维的代数结构,即累积量。因此从核函数观点看,GCBIUM算法和SOBIUM算法具有相当的复杂度,FOBIUM复杂度较高。
另一方面,考虑标准CP分解和Tucker分解。对于张量,执行CP标准分解,交替最小二乘的每次迭代的复杂度为$ O(3PK{N^2} + NK{P^2} + {N^2}{P^2}) $。然而,张量的Tucker分解,通过对其模3矩阵M3的奇异值分解,复杂度为O(N6)。压缩后的核张量的分解,使用交替最小二乘的每次迭代的复杂度为$ O(3PL{N^2} + NL{P^2} + {N^2}{P^2}) $。
值得注意的是,为了聚集充分的统计信息,3种算法中,K值一般较大,然而通过Tucker压缩后,核张量秩中L比K小了很多。而且Tucker压缩的处理只需一次奇异值分解,相对于交替最小二乘则需要多次的迭代达到收敛,单次的奇异值分解相对多次的迭代可以不计,降低了计算复杂度。如张量$ \mathit{\boldsymbol{\mathcal{M}}} $具有5×5×100维数,即K=100,压缩的核张量$ \mathit{\boldsymbol{\mathcal{T}}} $具有5×5×8维数,即L=8,因此复杂度降低了。从上述分析可知,提出的算法较SOBIUM和FOBIUM降低了计算复杂度。
2.1. 广义协方差相关理论
2.2. Tucker分解求混合矩阵

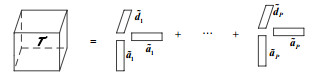
2.3. 复杂度分析
-
为了说明提出算法的有效性,采用计算机仿真分析加以说明。为了比较性能,考虑SOBIUM和FOBIUM算法进行分析对比。以混合矩阵估计的相对误差为性能指标,分别在不同符号长度和不同信噪比条件下分析性能。混合矩阵相对误差性能指标定义为:
式中,$ \mathit{\boldsymbol{\hat A}} $表示估计的混合矩阵。为了方便对比算法的性能,考虑文献[6-7]中相同的参数设定,设窄带信源数P=5,被一个N=4传感器半径为Ra的均匀圆阵接收。考虑自由空间传播模型,因此混合矩阵的模型为:
式中,${\rm{i}} = \sqrt { - 1} $;${\alpha _j} = ({R_a}/\lambda )\cos (2{\rm{\pi (}}j - 1{\rm{)}}/J)$;$ {\beta _j} = ({R_a}/\lambda )\sin (2{\rm{\pi (}}j - 1{\rm{)}}/J) $;${R_a}/\lambda = 0.55$。标准化的混合矩阵A通过A中各列除以各自的Frobenius范数。信源是单位方差的QPSK,具有均匀分布,升余弦成型滤波,滚降因子为0.3,4倍过采样。不同源的来波方向分别设定为:θ1=3π/10,θ2=3π/10,θ3=2π/5,θ4=0,θ5=π/10和ϕ1=7π/10,ϕ2=9π/10,ϕ3=3π/5,ϕ4=4π/5,ϕ5=3π/5。考虑观测信号受到零均值的复高斯白噪声影响,随机选取区间[-1,1]内的100个不同处理点τ进行蒙特卡洛仿真实验。
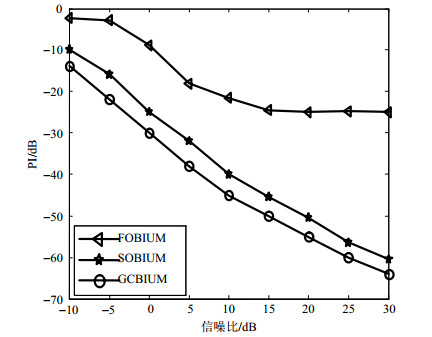
图 4说明了在不同信噪比条件下的相对误差性能指标,数据符号数为1 000。从图 4可以得知,本文提出算法的性能优于SOBIUM和FOBIUM算法。数据符号长度和信噪比水平影响了性能,因为统计信息的估计比较敏感。

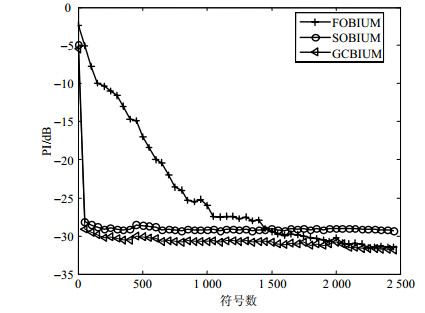
图 5说明了采用不同符号数时3种算法的相对误差性能指标,信噪比为10 dB。根据图 5的仿真结果可以得知:在较长符号数情况下FOBIUM优于SOBIUM算法;随着符号数的变大,GCBIUM算法与FOBIUM有着相近的性能。

综合上述结果,可以总结为以下原因:首先,比起SOUBIUM算法和本文所提算法,四阶累积量在FOBIUM算法中需要更多的采样聚集统计信息。另一方面,四阶累积量是不敏感于高斯噪声的。最后,广义协方差能更好地提取统计信息且含有高阶统计的信息,所以能够优化混合矩阵的估计性能。
-
本文使用新型的统计工具和塔克张量分解,提出一种的新的欠定盲辨识算法。利用广义协方差矩阵建立核函数,比起基于协方差矩阵和四阶累积量的核函数,能更好地提取统计信息,改善盲辨识的性能。利用塔克张量分解可以有效地降低计算复杂度,优于现有的规范张量分解方法。下一步工作是研究基于广义协方差张量分解的欠定盲源分离算法。

 DownLoad:
DownLoad: