 ISSN
ISSN 





-
技术状态是反映装备实时质量状况的重要指标。准确预测装备在未来时刻的技术状态,不仅有利于评估装备任务成功性,而且能够为维修决策提供可靠依据。装备技术状态劣化规律与其影响因素之间存在着高度复杂的非线性时变关系,其技术状态参数既依赖于多因素的空间聚合,又与时变因素在时间上的累积效应密切相关[1]。对装备技术状态进行预测时,可直接预测其技术状态,也可间接预测反映其技术状态的相关参数的数值。装备技术状态预测方法较多,但均有一定的适用条件。如文献[2-4]分别针对特定的故障模式建立了相应的数学模型,进而对直接反映系统状态的参数进行了预测。由于装备实际工作时技术状态较之试验情形下状态更为复杂,该方法仅被用于处理零件层次的少数故障类型。装备技术状态监测结果通常为离散的时间序列数据,用于此类数据预测的方法种类较多,如常见的时间序列预测法、灰色预测法、回归分析预测法等[5-7]。然而这些方法过于简单,无法精确描述时间序列数据间的传递关系,技术状态预测结果可信性较差。近年来,随着现代智能算法的发展,人们逐渐将各类智能算法引入到装备技术状态预测中。如文献[8-9]将支持向量机算法引入装备技术状态预测过程;文献[10-12]运用普通神经网络技术对装备技术状态参数进行了预测;文献[13]将粒子滤波算法用到了技术状态预测中。上述智能算法虽然相对于普通时间序列预测方法预测精度有所提高,但由于不能同时处理装备技术状态多维参数的空间聚合及时间累积效应,预测精度依然不够理想。
为解决现行装备技术状态预测方法中存在的上述问题,本文研究了装备技术状态多维数据预测方法,将离散过程神经网络(discrete process neural network)有效地应用到装备技术状态预测中,同时处理装备技术状态多维参数的空间聚合效应及时间累积效应,提高预测精度。
HTML
-
装备技术状态监测数据通常为一组离散多维时间序列数据,其预测过程不仅包含普通时间序列预测工作中的时间累积效应,而且包含多维数据间的空间聚合效应。其中时间累积效应可理解为装备未来时刻技术状态不仅与当前时刻装备技术状态相关,而且与当前时刻前一段时间内的装备技术状态也存在密切关系。这是由于装备技术状态在不同工作环境、工作强度下体现出不同的劣化速度的缘故。因此,有必要研究装备技术状态在时间上的延续性,即时间累积效应。空间聚合效应可理解为装备技术状态各参数之间存在的相互影响关系。装备中各部件并非单独存在,而是相互依存的一个系统。各部件技术状态之间存在一定的制约关系,这一关系具体反映在装备技术状态监测数据中各参数间的协同作用,即空间聚合效应。时间累积效应与空间聚合效应在装备技术状态预测全过程中始终存在。因此,在进行装备技术状态预测时,要研究二者的综合效应。作为过程神经网络的一个特例,离散过程神经网络是由我国著名学者何新贵于2007年提出的一种基于普通神经网络的智能学习算法。该算法不仅能有效模仿系统的空间聚合效应,而且能模仿系统的时间累积效应[14]。因此可用离散过程神经网络学习算法对装备技术状态进行预测。
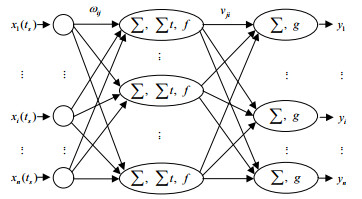
假设装备的技术状态可由n个技术状态参数组成的向量表示,称为技术状态参数向量。等时间间隔监测并记录该装备全寿命周期内各技术状态参数向量,其中第s次(${t_s}$时刻)监测结果记为:,$s = 1,2, \cdots $。现要求根据已知数据预测(s+1)次监测时刻该装备的技术状态参数向量。由于装备各技术状态参数的劣化规律不仅与运行时间相关,而且与其他参数也存在密切关系,因此可构建如图 1所示预测模型。

该预测模型中,模型输入为预测时刻前的l个技术状态参数向量(l为时间累积量)。如预测时刻为${t_{(s + 1)}}$时,模型输入为:;模型输出为:$y = ({y_1},{y_2}, \cdots ,{y_n})$,其中,${y_i} = {x_i}{t_{(s + 1)}}$,$i = 1,2, \cdots ,n$。
如图 1所示,网络输入层共有n个节点,分别代表输入技术状态向量的n分量;网络输出层有p(p=n)个节点;中间层(隐层)共有m个节点。其中,$\Sigma $表示加权求和算子;$\Sigma t$表示时间效应累积算子;f为隐层神经元激励函数;g为输出节点激励函数;${\omega _{ij}}$为第i个输入节点对第j个隐层节点的连接权值;${v_{ji}}$为第j个隐层节点对第i个输出节点的连接权值。
预测模型中,空间聚合效应由加权求和算子$\Sigma $实现。如第j个中间层(隐层)节点可实现输入技术状态向量各分量的空间聚合为:
在中间层(隐层)中,各节点可通过时间效应累积算子$\sum t$实现输入层的时间累积效应。如,该预测模型需实现预测时刻前l个时刻(${t_{s - l + 1}},{t_{s - l + 2}}, \cdots ,{t_s}$)的时间累积效应,则第j个中间层节点的输出为:
综合网络空间聚合效应及时间累积效应可知,第i个输出节点的输出为:
式中,${\theta _j}$为第j个隐层节点的激励阈值;${\varepsilon _i}$为第i个输出节点激励阈值。$\Delta t$为给定的数据采集间隔时间。由于技术状态数据为等时间间隔监测数据,因此可令$\Delta t = 1$。此时,第i个输出节点的输出可简化为:
不难看出,基于离散过程神经网络的装备技术状态预测模型的实质是拟合输入与输出数据间的对应关系,需要一定量的数据对模型进行训练,且这些数据应当能够反映装备全寿命周期内的各种技术状态。因此,收集模型训练数据时,通常选用与待预测装备同型号且工况相仿的装备全寿命监测数据。
此外,基于离散过程神经网络的装备技术状态预测模型还可进行多步预测。例如进行q步预测时,网络第i个输出节点的输出可设为${x_i}({t_s} + q)$。进而对网络进行训练,实现预测。
-
离散过程神经网络是普通神经网络的推广,其网络学习原理基本相同。本文所建装备技术状态预测模型可借鉴BP神经网络学习中常用的梯度下降法进行学习。
1)梯度下降法[15]
离散过程神经网络可用梯度下降法进行学习。其原理如下:
给定K个学习样本:
其中,${d_k} = {x^k}({t_{s + 1}})$表示网络的期望输出,即装备技术状态真实值;设网络实际输出为${y^k}$。可定义网络误差函数为:
因此,可制定学习规则如下:
式中,$\alpha ,\beta ,\gamma ,\eta $为学习效率常数。
给定网络学习次数N,网络学习精度H,利用上述学习规则对网络参数进行学习。达到网络学习次数或学习精度要求时停止学习。
2)基于混沌粒子群算法的网络学习过程优化
基于梯度下降法的过程神经网络学习过程的实质是一个非线性多维函数的极小化过程。因此在网络实际训练过程中,可能会获得局部最优解[16],影响网络输入、输出关系的拟合。这一现象主要受网络的学习过程及训练样本多样化程度影响。因此,在实际训练时,不仅要选择能反映数据总体特性的样本数据,而且要进行多次训练,从而避免上述现象的出现。
样本数据由装备技术状态监测结果确定,尽可能地采取全寿命监测获取,没有太大的改进空间。在训练时,将样本数据进行归一化处理,消除各参数量纲差异带来的不便。至于网络的学习过程,可利用混沌粒子群算法进行优化。
在进行装备技术状态预测时,构建如图 1所示预测模型并令模型中各参数${\omega _{ij}},{v_{ji}},{\theta _j},{\varepsilon _i}$均为区间(-1, 1)内的随机数。以权值${\varepsilon _i}$的混沌化处理为例进行分析。
令$|{\varepsilon _i}| = {\psi _r}$,构建Logistic映射[17-19]:
式中,$\mu $为控制参数,取值0~4;当$\mu = 4$时,系统处于混沌状态。取随机初始值,迭代400次,可得混沌化处理后的${\psi _r}\left( {{\psi _r} \in (0,1)} \right)$。进而可实现${\varepsilon _i}$的混沌化处理。同理,可依次对${\omega _{ij}},{v_{ji}},{\theta _j}$进行混沌化处理。网络参数混沌化处理的目的是使得此后多次网络参数初始化时能够尽可能做到离散,从而避免出现多次训练结果在少数几个局部最优解附近聚集的现象。
考虑到网络一旦陷入局部最优解便很难跳出,可适当地对各局部最优解添加混沌激励,使其跃出原有局部困扰,获得新网络参数向量,称为扰动局部最优解。利用多个扰动局部最优解重新训练网络可得多个全局次优解。将已获取的局部最优解与全局次优解共同组成粒子群,利用粒子群优化算法进一步优化,得全局最优解。
依据这一思路,本文提出如下网络学习算法优化过程。
初步优化阶段:
1)将预测模型中各参数在logistic映射400次迭代的基础上再进行n*次迭代(n*可根据实际试验需求设置),并记录每次迭代的结果,构成n*个初始参数向量:
2)将n*个初始参数向量分别代入网络,用梯度下降法进行学习,得n*个局部最优解。
3)对每个局部最优解进行一次混沌激励。如对第i个局部最优解中参数$\varepsilon _j^i$进行激励。令$\varepsilon _j^i = (1 - \beta )\varepsilon _j^i + \beta {\upsilon _k}$,$\beta \in [0,1]$为扰动强度系数,${\upsilon _k} \in ( - 1,1)$为迭代k次后的混沌变量。经混沌激励后,得到n*个扰动局部最优解。
4)将n*个扰动局部最优解代入网络进行梯度学习,得到n*个全局次优解。
初步优化阶段的目的是以较快速度缩小全局最优解的取值范围。分析该阶段得到的n*个局部最优解和n*个全局次优解中各网络参数的取值,分别找出每个参数的最大值和最小值。如参数$\varepsilon _j^i$的最大值与最小值分别为$\max \varepsilon _j^i$、$\min \varepsilon _j^i$,则全局最优解中参数$\varepsilon _j^i \in [\max \varepsilon _j^i,\min \varepsilon _j^i]$。
精确优化阶段:
5)将n*个局部最优解与n*个全局次优解共同组成粒子群,其中每个解为一个粒子。粒子中各参数的取值范围取为全局最优解中各参数取值范围,并以此范围设定参数更新速度约束。如参数$\varepsilon _j^i \in [\max \varepsilon _j^i,\min \varepsilon _j^i]$,其更新速度约束为$[(\min \varepsilon _j^i - \max \varepsilon _j^i)/2,(\max \varepsilon _j^i - \min \varepsilon _j^i)/2]$。适应度函数取为E,适应度越小粒子越优。
6)设定最大迭代次数M,迭代精度Q。利用标准粒子群算法[20]进行优化,当达到迭代次数或迭代精度要求时停止优化,输出群最佳位置即为全局最优解。
全局最优解的获取与n*的取值关系密切。n*取值过小,无法获取全局最优解;n*取值过大,将极大增加运算复杂性。因此在实验时,可根据装备技术状态数据特点设定n*值,然后逐步增大n*取值直至全局最优解变化范围收敛至规定精度为止。此时的n*即可用于构建装备技术状态预测模型。
-
本文选取某装备变速箱油液分析数据,对变速箱技术状态进行预测,以验证本文方法的可行性。
1)建立预测模型
①训练数据收集及处理
以某装备运行过程中传动箱油液等时间间隔(20 h)监测数据为例,共选取油液中铁、铝、铅、硼、钡、铬、镁、硅共8种元素的浓度作为特征参量进行分析,样本容量为32。由于数据为装备全寿命监测数据,因此,需要将数据中非变速箱劣化因素(换油等因素)引起的油液质量变化进行处理。具体的处理方法可查阅相关文献,此处不加赘述。样本数据归一化处理如表 1所示。
序号 铁 铝 铅 硼 钡 鉻 镁 硅 1 0.000 5 0.072 8 0.134 0 0.406 7 0.352 4 0.169 3 0.241 6 0.917 0 2 0.163 3 0.123 5 0.185 9 0.302 2 0.369 5 0.286 5 0.298 7 0.963 6 $ \vdots $ $ \vdots $ $ \vdots $ $ \vdots $ $ \vdots $ $ \vdots $ $ \vdots $ $ \vdots $ $ \vdots $ 18 0.753 9 0.564 4 0.701 8 0.271 5 0.296 7 0.903 4 0.401 1 0.399 6 $ \vdots $ $ \vdots $ $ \vdots $ $ \vdots $ $ \vdots $ $ \vdots $ $ \vdots $ $ \vdots $ $ \vdots $ 31 0.938 2 0.785 4 0.913 9 0.324 0 0.252 4 0.237 9 0.561 6 0.154 2 32 0.938 2 0.785 4 0.913 9 0.324 0 0.252 4 0.237 9 0.561 6 0.154 2 ②初步优化阶段
构建如图 1所示过程神经网络预测模型,其中输入层节点数n=8;输出层节点数为p=8;隐层节点数m可根据文献[21]提供的公式计算,$m = \sqrt {n + p} + a$,a为1到10之间的常数。为提高网络训练精度,此处取最大值m=14。
网络输入为连续5次监测所得的共5个技术状态参数向量。以序号1数据为例,该时刻的技术状态参数向量为:(0.000 5, 0.072 8, 0.134 0, 0.406 7, 0.352 4, 0.169 3, 0.241 6, 0.917 0)。网络输出为连续5次监测之后再进行一次监测所得的技术状态参数向量。依据该方式,可将表 1数据组合成共27组样本数据。将这27组样本数据依次代入上述过程神经网络中,计算总体误差E并据此调节相应权值,记作一次训练。
本次试验中n*=50,模型训练精度H=0.001,最大训练次数N=500,隐层激励函数选用S型传输函数,输出层激励函数选用线性传输函数。将27组样本数据代入预测模型并依据第2节中基于混沌粒子群的网络学习过程初步优化阶段步骤进行计算,分别得到50组局部最优解和50组全局次优解。
③精确优化阶段
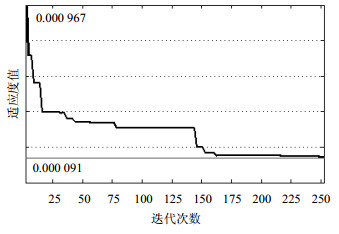
将50组局部最优解与50组全局次优解共同组成规模为100的粒子群。取标准粒子群算法中惯性权重为0.5,群加速常数与个体加速常数均为1.494 45,迭代最大次数M=300,迭代精度Q=0.000 1。根据已获取的粒子群中各参数的最大、最小值设定各参数取值范围及更新速度,进行迭代得全局最优解。其中,全局最优解适应度变化过程如图 2所示。

如图所示,粒子群迭代到251代时达到目标要求,可输出全局最优解。
实验中,初步优化阶段耗时2 min 27 s,精确优化阶段耗时34 s,总耗时为3 min 1 s。由于传动箱技术状态劣化为磨损劣化,劣化速度较慢,因此文中预测模型可用于实际技术状态预测。
2)技术状态数据预测
采集该工况下,某同型号装备连续监测的15组数据如表 2所示。
序号 铁 铝 铅 硼 钡 鉻 镁 硅 1 0.746 3 0.523 3 0.662 2 0.319 8 0.302 8 0.886 7 0.396 8 0.349 9 2 0.736 5 0.568 6 0.661 6 0.288 6 0.223 5 0.840 6 0.348 0 0.347 0 3 0.753 9 0.564 4 0.701 8 0.271 5 0.296 7 0.903 4 0.401 1 0.399 6 4 0.786 5 0.562 2 0.795 4 0.265 0 0.368 4 0.950 9 0.452 8 0.337 7 5 0.789 9 0.596 3 0.736 5 0.201 3 0.366 9 0.769 8 0.396 7 0.235 6 6 0.805 1 0.570 2 0.717 7 0.158 7 0.365 8 0.139 4 0.325 5 0.136 2 7 0.865 9 0.425 8 0.799 8 0.256 8 0.532 6 0.148 9 0.425 7 0.129 5 8 0.910 3 0.350 2 0.868 1 0.300 4 0.782 8 0.160 3 0.633 9 0.129 0 9 0.942 1 0.418 9 0.865 3 0.319 8 0.631 1 0.150 7 0.589 9 0.142 1 10 0.964 5 0.742 3 0.860 4 0.347 7 0.384 5 0.145 4 0.542 9 0.160 4 11 0.969 9 0.752 3 0.879 8 0.334 5 0.358 9 0.196 5 0.499 8 0.160 0 12 0.985 0 0.764 7 0.907 6 0.324 0 0.347 1 0.231 9 0.463 0 0.159 3 13 0.935 8 0.821 1 0.893 2 0.386 9 0.340 1 0.230 1 0.524 4 0.160 0 14 0.910 7 0.882 6 0.874 4 0.477 5 0.334 2 0.214 0 0.621 4 0.170 7 15 0.919 5 0.871 1 0.900 2 0.399 6 0.298 7 0.219 9 0.601 2 0.160 7 分别采用本文预测方法(F1)、仅考虑时间累积效应的BP神经网络预测法[22](F2)以及仅考虑空间聚合效应的BP神经网络预测法[23](F3)对后10组数据进行预测。以铁元素预测结果为例统计相对误差,并计算各元素总体预测结果与实际数据之间的欧氏距离,可得表 3。
序号 F1 F2 F3 浓度(铁) 相对误差/% (铁) 欧式距离 浓度(铁) 相对误差/% (铁) 欧式距离 浓度(铁) 相对误差/% (铁) 欧式距离 6 0.804 8 0.04 0.020 2 0.799 1 0.75 0.026 6 0.806 3 0.15 0.021 5 7 0.866 0 0.01 0.045 7 0.844 1 2.52 0.032 6 0.859 1 0.79 0.023 1 8 0.906 7 0.39 0.028 1 0.914 2 0.43 0.009 8 0.918 7 0.92 0.026 6 9 0.942 6 0.05 0.007 7 0.945 0 0.31 0.017 2 0.941 7 0.04 0.013 7 10 0.956 6 0.82 0.011 4 0.966 1 0.17 0.014 1 0.956 1 0.87 0.023 7 11 0.978 1 0.85 0.017 6 0.982 4 1.29 0.018 4 0.981 0 1.14 0.050 1 12 0.977 2 0.79 0.015 7 0.956 0 2.94 0.035 5 0.964 2 2.11 0.051 3 13 0.943 1 0.78 0.012 7 0.941 0 0.56 0.013 4 0.938 8 0.32 0.025 7 14 0.908 9 0.20 0.021 1 0.920 5 1.08 0.025 1 0.913 6 0.32 0.022 7 15 0.918 8 0.08 0.008 2 0.912 2 0.79 0.013 8 0.916 6 0.32 0.013 6 如表 3所示,分析铁元素浓度预测相对误差:序号为6、7、8、11、12、14、15的数据,F1预测结果明显优于F2、F3预测结果;序号为9、10、13的数据,F1预测结果虽然未体现明显的预测优势,但与F2、F3预测结果相差不大。可知,单就铁元素浓度预测而言,F1预测精度明显高于F2和F3。就总体数据预测结果与实际数据之间欧式距离而言,除序号为7、8的数据F1预测结果不能完全优于F2和F3,其余数据的预测结果F1均能体现明显的预测优势。综合分析可知,在预测精度上,F1明显高于F2和F3。
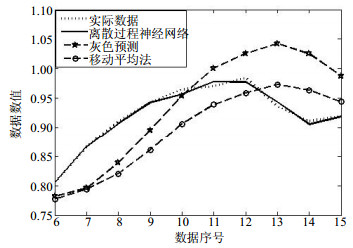
为进一步验证本文方法的有效性,选用目前最常用的灰色预测和移动平均法对上述15组数据的后10组进行预测,并以铁元素预测结果为例绘制如图 3所示预测结果示意图。

如图 3所示,本文方法预测结果较之灰色预测法和移动平均法预测结果更加贴近实际数据,且数据变化趋势与实际数据变化趋势拟合程度较好。可见本文方法能够有效应用于实际预测工作中。
-
本文利用离散过程神经网络对装备技术状态多维参数进行了预测。针对神经网络训练可能出现局部最优解这一缺陷,利用混沌粒子群算法对训练过程进行了优化。基于离散过程神经网络的装备技术状态预测方法能够有效表征装备技术状态多维参数预测中的空间聚合及时间累积效应,优于其他同类预测方法。

 DownLoad:
DownLoad: