 ISSN
ISSN 





-
在实时系统中,任务互斥访问关键数据结构、I/O设备等共享资源时,需要采用实时锁协议以避免死锁、阻塞链,同时减小优先级反转所造成的调度损失。在基于共享内存的多处理器实时系统中,文献[1]提出了一种单处理器优先级天花板协议(priority ceiling protocol, PCP)[2]的多处理器天花板协议(multiprocessor priority ceiling protocol, MPCP)。该协议适用于分组固定优先级(partitioned fixed-priority, P-FP)[3-4]调度下的多核/多处理器实时系统。
为了确保实时任务在其截止时限内完成,需要对任务的可调度性进行定量分析。在基于P-FP+ MPCP的调度策略下,可调度性分析包含任务最坏阻塞时间分析。文献[1]将任务阻塞分为本地局部资源阻塞、本地全局资源阻塞、远程低优先级任务阻塞、远程高优先级任务阻塞,以及间接阻塞,并通过计算各部分阻塞时间的累加和得到任务最坏阻塞时间。由于前两个阻塞部分并非相互独立,该方法存在重复计算问题。文献[5]将任务描述为临界区与非临界区相间的模型,采用响应时间分析法(response time analysis, RTA)[6-8]计算任务远程阻塞时间。该方法减小了文献[1]中的重复计算问题,但没有考虑相邻临界区间的间隔,因此所得的最坏阻塞时间仍较保守。文献[3]利用任务中相邻临界区间的最短时间间隔,提出了新的任务最坏时间分析方法。该方法在相邻临界区最短时间间隔较大时可排除文献[1]中的部分保守计算,相反则可能得到更坏的结果。文献[9]改进了文献[5]中的计算方法,提高了任务最坏阻塞响应时间计算的准确性。为了进一步提高任务阻塞时间分析的准确性,本文结合文献[5]的任务模型以及文献[9]的RTA分析框架,提出了分析任务多次请求同一共享资源所需的最短执行时间,以及任务在任意时间内累计执行临界区上限的方法,并基于该分析方法提出一种新的任务最坏阻塞时间分析方法。该方法进一步减小了分析所得的任务最坏阻塞时间,实验表明,该分析方法可提高实时任务集合的可调度性。
HTML
-
一组任务 $\Gamma = \{ {\tau _1},{\tau _2}, \cdots ,{\tau _n}\} $ 在一个m核处理器上执行,并共享q个共享资源 $\Phi = \{ {\rho _1},{\rho _2}, \cdots ,{\rho _q}\} $ 。 ${\tau _i}$ 的第l个作业表示为 ${J_{i,l}}$ (一般情况下,用 ${J_{i,l}}$ 表示 ${\tau _i}$ 的任意作业)。任务互斥访问共享资源,且一次最多允许获得一个共享资源。任务按优先级倒序编号,即若i < j则 ${\tau _i}$ 的优先级高于 ${\tau _j}$ 。同一任务的所有作业的优先级相同(即 ${J_{i,x}}$ 和 ${J_{i,y}}$ 具有相同的优先级)。令 ${\tau _{i,j}}$ 表示 ${\tau _i}$ 的第j个非临界区段, ${\tau _{i,j*}}$ 表示 ${\tau _i}$ 的第j个临界区段。假设任务各段的执行时间确定,且各任务段按序依次执行,则 ${\tau _i}$ 可表示为(( $N{C_i}_{,1}$ , ${C_i}_{,1}$ , $N{C_i}_{,2}$ , ${C_i}_{,2}$ , …), ${T_i}$ )。其中, ${S_i}$ 为 ${\tau _i}$ 的非临界区段数, $N{C_{i,j}}$ 和 ${C_{i,j}}$ 分别是 ${\tau _{i,j}}$ 和 ${\tau _{i,j*}}$ 的执行时间, ${T_i}$ 为 ${\tau _i}$ 的最短到达时间间隔(或周期)。 ${\tau _i}$ 的执行时间可表示为 ${C_i} = \sum\limits_{j = [1,Si - 1]}^ {({C_{i,j}} + N{C_{i,j}}) + N{C_{i,Si}}} $ 。任务CPU利用率为 ${u_i} = {C_i}/{T_i}$ ,系统利用率为 $U = \sum\limits_{\forall i}^ {{u_i}} $ 。本文假设任务相对截止时限等于任务周期。令 ${J_{i,l}}$ 的到达与结束时刻分别为 ${r_{i,l}}$ 和 ${f_{i,l}}$ ,则 ${\tau _i}$ 的最坏响应时间为 ${R_i} = {\rm{ma}}{{\rm{x}}_{\forall l}}({f_{i,l}} - {r_{i,l}})$ 。本文采用P-FP两级调度:首先将任务静态地划分到不同的处理器核上;然后在各核上根据任务的固定优先级进行抢占式调度。P-FP下,共享资源可分为本地资源和全局资源,前者为仅被分配到相同处理器核上的任务(简称同核任务)访问的资源,后者为可以被分配到不同处理器核上的任务(简称异核任务)访问的资源。MPCP采用PCP协议机制仲裁本地资源的共享。当任务访问某全局资源 ${\rho _k}$ 而被阻塞时,该任务挂起并插入到 ${\rho _k}$ 的优先级队列上等待。当该任务获得 ${\rho _k}$ 时,其优先级将提升为 ${\Omega _k} = {\pi _s} + {\pi _k}$ ,直至释放 ${\rho _k}$ 。其中 ${\pi _s}$ 为系统最高优先级(大于 ${\tau _1}$ 的优先级), ${\pi _k}$ 为需要访问 ${\rho _k}$ 的最高优先级任务的优先级。根据MPCP,任务执行临界区时仍可能被抢占,使得任务的阻塞与抢占关系变得十分复杂[5, 9]。
-
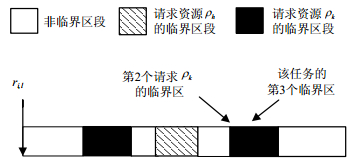
令 ${N_{i,k}}$ 表示 ${J_i}$ 请求资源 ${\rho _k}$ 的次数, ${\tau _{i,k,x}}$ 表示 ${\tau _i}$ 第x次访问 ${\rho _k}$ 的临界区, ${S_{i,k,x}}$ 表示与 ${\tau _{i,k,x}}$ 对应的临界区编号。如图 1所示, ${N_{i,k}} = 2$ , ${N_{i,h}} = 1$ , ${\tau _i}$ 在其第3个临界区中第2个请求 ${\rho _k}$ ,因此 ${S_{i,k,}}_2 = 3$ 。从 ${r_{i,l}}$ 到 ${\tau _i}$ 第x次( $1 \le x \le {N_{i,k}}$ )请求 ${\rho _k}$ 的最短时间间隔可由式(1)计算如下:

变量 含义 ${N_{i,k}}$ ${J_i}$ 请求资源 ${\rho _k}$ 的次数 ${\tau _{i,k,x}}$ ${\tau _i}$ 第x次访问 ${\rho _k}$ 的临界区 ${S_{i,k,x}}$ 与 ${\tau _{i,k,x}}$ 对应的临界区编号 ${d_{i,k,x}}$ 从 ${r_{i,l}}$ 到 ${\tau _i}$ 第x次( $ 1 \le x \le {N_{i,k}}$ )请求 ${\rho _k}$ 的最短时间间隔 ${\delta _{i,k,x}}(n)$ 从 ${J_i}$ 开始执行 ${\tau _{i,k,x}}$ 起,到其随后第n次请求 ${\rho _k}$ 的最短时间间隔 ${\eta _{i,k,x}}(\Delta t)$ 从 ${J_{i,l}}$ 执行 ${\tau _{i,k,x}}$ 开始, ${\tau _i}$ 在 $\Delta t$ 时间内请求 ${\rho _k}$ 的最大次数 $\Delta t$ 从 ${J_{i,l}}$ 执行 ${\tau _{i,k,x}}$ 开始, ${\tau _i}$ 在接下来的n次对 ${\rho _k}$ 的请求中其相应的临界区执行时间 ${\xi _{i,k}}$ ${\tau _i}$ 的一个作业在与 ${\rho _k}$ 相应的临界区中的累计执行时间 ${\varphi _{i,k}}$ ${\varphi _{i,k}}$ 在 ${\rho _k}$ 的临界区内被其他任务抢占的最大时间 ${\varepsilon _{i,k}}$ ${\tau _i}$ 占用资源 ${\tau _i}$ 的最大时间 ${b_{i,k,L}}$ ${\tau _i}$ 每次被异核低优先级任务阻塞的时间上限 ${b_{i,k,H}}(\Delta t)$ ${b_{i,k,H}}(\Delta t)$ 每次请求全局资源 ${\rho _k}$ 时,在 $\Delta t$ 内被异核高优先级任务阻塞的最大时间 ${Y_{i,k}}$ ${\tau _i}$ 每次请求全局资源时,被远程阻塞的最大时间 ${Y_i}$ ${\tau _i}$ 最大远程阻塞时间 ${\delta _{i,*,j}}(n)$ 从 ${J_i}$ 开始执行 ${\tau _{i,k,x}}$ ,执行n个临界区的最短时间间隔 ${\tau _{i,k,x}}$ 从 ${J_i}$ 执行 ${\tau _{i,k,x}}$ 开始,执行n个临界区的临界区执行时间之和 ${B_{i,L}}$ 在 ${\tau _i}$ 的一次执行中,其被本地低优先级任务阻塞的时间上限 ${B_i}$ ${\tau _i}$ 的最大本地阻塞时间 定理1 令 ${t_x}$ 为 ${J_{i,l}}$ 开始执行 ${\tau _{i,k,x}}\left( {1 \le x \le {N_{i,k}}} \right)$ 的时刻, ${t_n}$ 为该任务从 ${t_x}$ 开始到第n次( $n \ge 1$ ,且将 ${J_{i,l}}$ 执行 ${\tau _{i,k,x}}$ 设为第一次)请求资源 ${\rho _k}$ 的时刻,则 ${\rm{min}}({t_n} - {t_x}) = {\delta _{i,k,x}}(n)$ 。
其中,当 $x \le {N_{i,k}} - n + 1$ 且 $1 \le n \le {N_{i,k}}$ 时:
当 $x > {N_{i,k}} - n + 1$ 且 $1 \le n \le {N_{i,k}}$ 时:
当 $x + n - 1 > 2{N_{i,k}}$ 时:
其中,
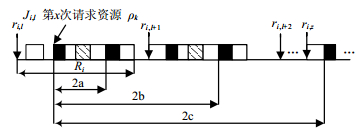
证明:当 $x \le {N_{i,k}} - n + 1$ 且 $1 \le n \le {N_{i,k}}$ 时, $x + n - 1 \in [x,{N_{i,k}}]$ ,即n次请求在 ${\tau _i}$ 的一个作业内完成,如图 2所示。根据式(1)可知, ${\delta _{i,k,x}}(n) = {d_{i,k,}}_{(x + n - 1)} - {d_{i,k,x}}$ 。

当 $x > {N_{i,k}} - n + 1$ 且 $1 \le n \le {N_{i,k}}$ 时, $x + n - 1 \in [{N_{i,k}},2{N_{i,k}}]$ ,即n次请求由两个连续作业 ${J_{i,l}}$ 和 ${J_{i,l}}_{ + 1}$ 完成。其中, $[{t_x},{t_n}]$ 可分为三个部分: $[{t_x},{f_{i,l}}]$ , $[{f_{i,l}},{r_{i,l}}_{ + 1}]$ , $[{r_{i,l}}_{ + 1},{t_n}]$ 。若 ${J_{i,l}}$ 从 ${t_x}$ 起连续执行(不被中断)直至任务完成,则 $[{t_x},{f_{i,l}}]$ 取得最小值 ${C_i} - {d_{i,k,x}}$ 。由于 ${R_i} = {\rm{ma}}{{\rm{x}}_{\forall f}}({f_{i,l}} - {r_{i,l}})$ ,所以当 ${f_{i,l}} - {r_{i,l}} = {R_i}$ 时, ${r_{i,l}}_{ + 1} - {f_{i,l}} = {r_{i,l}}_{ + 1} - {r_{i,l}} - {R_i} = {T_i} - {R_i}$ 取得最小值,即 $[{f_{i,l}},{r_{i,l}}_{ + 1}]$ 的最小值为 ${T_i} - {R_i}$ 。由于 ${J_{i,l}}$ 已完成 ${N_{i,k}} - x + 1$ 个请求, ${J_{i,l}}_{ + 1}$ 需完成剩余的 $n - {N_{i,k}} + x - 1$ 个请求。根据式(1), $[{r_{i,l}}_{ + 1},{t_n}]$ 的最小值为 ${d_{i,k,x + n - 1 - {N_{i,k}}}}$ 。综合以上分析,式(2b)得证。
当 $x + n - 1 > 2{N_{i,k}}$ 时,n次请求由至少三个连续作业完成。令 ${J_{i,z}}$ >表示完成n次请求的最后的一个作业,则 $[{t_x},{t_n}]$ 可分为三个部分: $[{t_x},{r_{i,l}}_{ + 1}]$ , $[{r_{i,l}}_{ + 1},{r_{i,z}}]$ , $[{r_{i,z}},{t_n}]$ 。根据前述分析可知, $[{t_x},{r_{i,l}}_{ + 1}]$ 的最小值为 ${C_i} - d_{i,k}^x + {T_i} - {R_i}$ 。 $[{r_{i,l}}_{ + 1},{r_{i,z}}]$ 可包含 $\left\lceil {(n - {N_{i,k}} + x - 1)/{N_{i,k}}} \right\rceil - 1$ 个完成周期,因此该段时间为 $(\left\lceil {(n + x - 1)/{N_{i,k}}} \right\rceil - 2){T_i}$ 。 $[{r_{i,z}},{t_n}]$ 为 ${J_{i,z}}$ 执行直至完成余下的 $n - {N_{i,k}} + x - 1 - (\left\lceil {(n + x - 1)/{N_{i,k}}} \right\rceil - 2){N_{i,k}}$ 个请求所需的最短时间。根据f(x)定义及式(1)可知, $[{r_{i,z}},{t_n}]$ 的最小值为 ${d_{i,k,f}}_{(x)}$ 。综合以上分析,式(2c)得证。
定理1给出了一个任务从某个时刻开始任意次请求某个共享资源所需的最短时间。通过求 ${\delta _{i,k,x}}(n)$ 的反函数,可计算出任意时间间隔内一个任务请求某个共享资源的最大次数。
推论1 从 ${J_{i,l}}$ 执行 ${\tau _{i,k,x}}(1 \le x \le {N_{i,k}})$ 的时刻开始, ${\tau _i}$ 在 $\Delta t$ 时间内请求 ${\rho _k}$ 的最大次数为 ${\rho _k}$ 。
参照 ${\delta _{i,k,x}}(n)$ 的计算方法,还可推导出一个任务请求任意次某共享资源时在相应的临界区内执行的时间。进而可计算出任意时间间隔内,一个任务在与某共享资源相应的临界区内的执行时间上限。
推论2 从 ${J_{i,l}}$ 执行 ${\tau _{i,k,x}}(1 \le x \le {N_{i,k}})$ 的时刻开始, ${\tau _i}$ 在接下来的n次对 ${\rho _k}$ 的请求中其相应的临界区执行时间为 ${\psi _{i,k,x}}(n)$ 。
其中,当 $x \le {N_{i,k}} - n + 1$ 且 $1 \le n \le {N_{i,k}}$ 时:
当 $x > {N_{i,k}} - n + 1$ 且 $1 \le n \le {N_{i,k}}$ 时:
当 $x + n - 1 > 2{N_{i,k}}$ 时:
式中, ${\xi _{i,k}} = \sum\limits_{\Phi ({\tau _{i,j*}}) = {\rho _k}} {{C_{i,j}}} $ 是 ${\tau _i}$ 的一个作业在与 ${\rho _k}$ 相应的临界区中的累计执行时间(令 $\Phi ({\tau _{i,j*}})$ 为临界区 ${\tau _{i,j*}}$ 对应的共享资源)。
推论3 从 ${J_{i,l}}$ 执行 ${\tau _{i,k,x}}(1 \le x \le {N_{i,k}})$ 的时刻开始, ${\tau _i}$ 在 $\Delta t$ 时间内在与 ${\rho _k}$ 相应的临界区上的执行时间上限为 ${\psi _{i,k,x}}({\eta _{i,k,x}}(\Delta t))$ 。
-
P-FP调度下,任务 ${\tau _i}$ 请求共享资源时可能发生本地阻塞(被本核任务阻塞)或远程阻塞(被异核任务阻塞)。当 ${\tau _i}$ 被远程阻塞时,锁住相应资源的异核任务可能在临界区内被抢占,从而可能对 ${\tau _i}$ 造成传递阻塞。本节采用文献[9]的任务阻塞时间分析框架,结合以上时间分析结果,提出新的任务最坏阻塞时间分析方法。
-
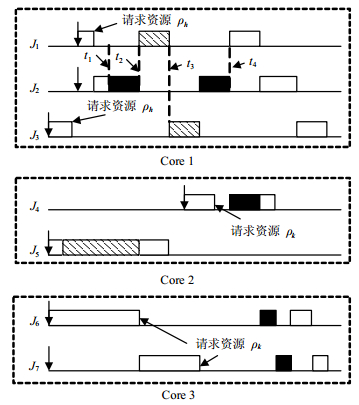
由于各全局资源的优先级天花板可能不同,任务在临界区内仍可能被抢占。如图 3所示,由于 ${\Omega _h} = {\pi _s} + {\pi _1} > {\Omega _k} = {\pi _s} + {\pi _2}$ , ${J_2}$ 在 ${\rho _k}$ 的临界区内被 ${J_1}$ 在 ${t_2}$ 时刻抢占,被 ${J_3}$ 在 ${t_3}$ 时刻抢占。根据文献[9],任务 ${\tau _i}$ 在 ${\rho _k}$ 的临界区内被其他任务抢占的最大时间为:
式中, ${\Gamma _{i,{\rm{local}}}}$ 为 ${\tau _i}$ 的本地任务。进而可知, ${\tau _i}$ 占用资源 ${\rho _k}$ 的最大时间为 ${\varepsilon _{i,k}} = {\varphi _{i,k}} + \mathop {\max }\limits_{j \in [1,{S_{i - 1}}] \wedge \Phi ({\tau _{i,j*}}) = {\rho _k}} {C_{i,j}}$ 。如图 3所示, ${\varepsilon _{2,k}} = {t_4} - {t_1}$ 。

当任务 ${\tau _i}$ 请求全局资源 ${\rho _k}$ 时,可能被异核低优先级任务阻塞。由于MPCP采用优先级排队机制,因此 ${\tau _i}$ 每次只能被一个低优先级任务阻塞。其中, ${\tau _i}$ 每次被异核低优先级任务阻塞的时间上限为:
当 ${\tau _i}$ 在某全局资源的优先级队列中等待时,若有高优先级异核任务请求相同资源,则这些异核任务会插入到 ${\tau _i}$ 前面,先于 ${\tau _i}$ 获得相应全局资源。如图 3所示, ${J_6}$ 在 ${J_4}$ 之前请求 ${\rho _k}$ ,而由于 ${J_4}$ 优先级较高, ${J_4}$ 先于 ${J_6}$ 获得 ${\rho _k}$ 。值得注意,在 ${\tau _i}$ 挂起等待 ${\rho _k}$ 期间,异核高优先级任务可能多次请求 ${\rho _k}$ ,从而可能多次阻塞 ${\tau _i}$ 。当某异核高优先级任务 ${\tau _h}$ 开始执行 ${\tau _{h,k,x}}(1 \le x \le {N_{i,k}})$ 时,在 $\Delta t$ 时间内, ${\tau _h}$ 在 ${\rho _k}$ 相应临界区内的最大执行时间为 ${\psi _{h,k,x}}({\eta _{h,k,x}}(\Delta t))$ ,在临界区内被抢占的最大时间为 ${\eta _{h,k,x}}(\Delta t){\varphi _{i,k}}$ 。因此 ${\tau _i}$ 每次请求全局资源 ${\rho _k}$ 时,在 $\Delta t$ 内被异核高优先级任务阻塞的最大时间为:
由于式(5)等号两边关于 $\Delta t$ 单调递增,且 ${\tau _i}$ 的远程阻塞时间为 ${\tau _i}$ 被异核低优先级任务和异核高优先级任务阻塞的时间之和,因此 ${\tau _i}$ 每次请求全局资源时,被远程阻塞的时间可通过以下迭代过程决定:
式中, $Y_{i,k}^0{\rm{ = }}0$ ,当 $Y_{i,k}^{n + 1} = Y_{i,k}^n$ , ${Y_{i,k}} = Y_{i,k}^{n + 1}$ ;若 $Y_{i,k}^{n + 1} > {T_i}$ ,则迭代可提前结束,此时 ${\tau _i}$ 不可调度。令 ${\Phi _{i,G}}$ 表示 ${\tau _i}$ 请求的全局资源集合,根据式(7)可得 ${\tau _i}$ 的最大远程阻塞时间为:
-
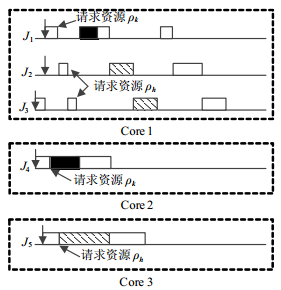
在任务 ${\tau _i}$ 就绪前或被远程阻塞而挂起时,其本地低优先级任务可能被调度执行并请求共享资源。当低优先级本地任务获得并继承相应资源的优先级天花板时,其有效优先级将高于 ${\tau _i}$ ,从而发生优先级翻转,延迟 ${\tau _i}$ 的执行。在实时系统中,这种由优先级翻转引起的任务延迟被视作任务阻塞[10]。如图 4所示,在 ${J_1}$ 挂起等待全局资源 ${\rho _k}$ 期间, ${J_2}$ 和 ${J_31}$ 相继请求全局资源 ${\rho _k}$ 并挂起等待。此后,当 ${J_1}$ 执行非临界区时, ${J_2}$ 和 ${J_3}$ 的共享资源请求相继得到满足,从而阻塞 ${J_1}$ 。

令 ${N_{i,G}}$ 为 ${\tau _i}$ 的全局临界区数,则 ${\tau _i}$ 最多因远程阻塞而挂起 ${N_{i,G}}$ 次。此外,由于在 ${\tau _i}$ 到达时低优先级任务可能已经获得共享资源,因此 ${\tau _i}$ 最多可被每个低优先级本地任务阻塞 ${N_{i,G}} + 1$ 次。设 ${\tau _l}$ 为 ${\tau _i}$ 的本地低优先级任务, ${\tau _l}$ 只有执行临界区时才可能阻塞 ${\tau _i}$ ,而在 ${\tau _i}$ 就绪后, ${\tau _l}$ 只有在 ${\tau _i}$ 挂起期间才有机会执行其非临界区,因此 ${\tau _l}$ 在 ${\tau _i}$ 就绪期间的执行时间减去 ${\tau _i}$ 的远程阻塞时间即为 ${\tau _l}$ 对 ${\tau _i}$ 的本地阻塞时间。
设 ${t_{x*}}$ 为 ${J_{i,l}}$ 开始执行第 $j(1 \le j \le {S_i}_{ - 1})$ 个临界区的时刻, ${t_{n*}}$ 为该任务从 ${t_{x*}}$ 开始到 ${\tau _i}$ 第n次进入临界区的时刻。令 ${\delta _{i,*,j}}(n) = {\rm{min}}({t_{n*}} - {t_{x*}})$ ,令 ${\psi _{i,*,j}}(n)$ 表示 ${\tau _i}$ 从 ${t_{x*}}$ 起执行的n个临界区时间之和。其中, ${\delta _{i,*,j}}(n)$ 和 ${\psi _{i,*,j}}(n)$ 的计算方法与定理1和推论2类似(推论1、2针对特定共享资源 ${\rho _k}$ 的临界区,而 ${\delta _{i,*,j}}(n)$ 和 ${\psi _{i,*,j}}(n)$ 针对连续临界区)。根据以上分析, ${\delta _{i,*,j}}(n) = {\psi _{i,*,j}}(n) + {Y_i}$ 。由于 ${\delta _{i,*,j}}(n) \le {\psi _{i,*,j}}(n) + {Y_i}$ ,因此 ${\psi _{i,*,j}}(n) \ge {\delta _{i,*,j}}(n) - {Y_i}$ 。从而,在 ${\tau _i}$ 的一次执行中,其被本地任务阻塞的时间上限为:
由于在任务 ${\tau _i}$ 就绪前或被远程阻塞而挂起时,其所有本地低优先级任务均可能先后被调度执行并请求共享资源,因此 ${\tau _i}$ 的本地阻塞时间不大于所有本地低优先级任务对请求造成的最大阻塞之和,即:
3.1. 远程阻塞时间
3.2. 本地阻塞时间
-
本节实验在Microsoft VS平台上进行,根据UUnifast-Discard算法[11]随机产生任务集合。其中,任务周期在[200, 1 000]内服从均匀分布, ${u_i}$ 在[0.05, 0.2]内随机产生,Ci根据任务CPU利用率定义由 ${u_i}$ 与 ${T_i}$ 决定。每个任务有x∈[1, 10]个临界区,各临界区长度y∈[0.5, 8]。系统中有q=20个共享资源,任务各临界区访问各共享资源的概率均等,且每个任务集合中最多有20个任务访问同一个共享资源。
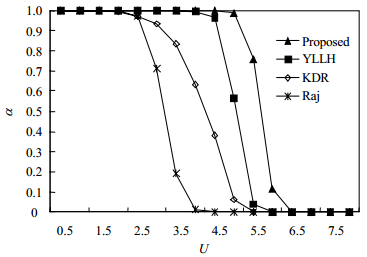
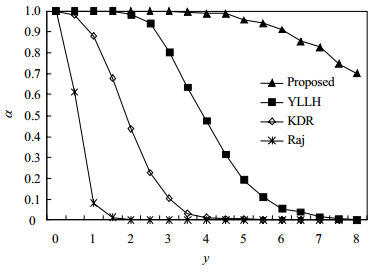
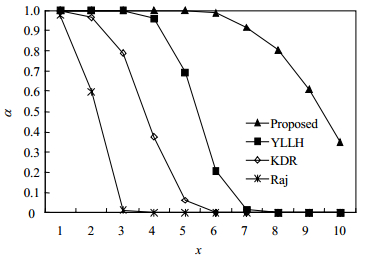
将以上所得任务集合按照Worst-Fit算法(以避免任务分配故障问题[12])进行任务分配(本文模拟m=8核处理器),并采用Raj[1]、KDR[5]、YLLH[9],以及本文提出的方法(Proposed)计算任务最坏阻塞时间。根据各方法所得最坏阻塞时间,采用文献[5]的RTA方法分析任务集合的可调度性。每次实验随机产生h=5 000个任务集合,分别计算以上4种分析方法的可调度率α。其中,可调度率计算方法如下:设一次实验随机产生c个任务集合,其中由分析方法A得出有g个任务集合可调度,则方法A的可调度率为 $\alpha = g/c$ 。由于以上各方法的所得的任务最坏阻塞时间不相同,而实验中采用了相同的可调度分析算法,因此,实验结果中各方法的可调度率反映了最坏阻塞时间的差异对的系统可调度性的影响。可调度率越高的方法,其分析所得的最坏阻塞时间越小。
图 5中,每个任务有4个临界区,临界区长度为1.5。该实验显示,各方法的可调度率均随系统利用率增加而下降,其中新方法的可调度率高于其余方法。新方法通过计算任务执行多个临界区所需的执行时间下限以及在任意时间内执行临界区的时间上限,将给定时间内不可能发生的阻塞时间排除在分析所得的最坏阻塞时间以外。而其余方法对任务在某段具体时间内是否会发生任务阻塞不敏感,使得分析结果较保守。

图 6中,系统利用率为4,每个任务有4个临界区。由于任务阻塞时间随临界区长度增加而增加,各分析方法的可调度率均随临界区长度增加而下降。当 $y \le 3.5$ 时Proposed的可调度率为1;而在y=3.5时,YLLH与KDR的可调度率分别约为0.62和0.03,Raj为0。当y > 3.5时,Proposed的可调度率下降速度低于其余方法。图 7中,系统利用率为4.5,任务临界区长度为1.5。随任务的临界区数增加,任务在最坏情况下被阻塞的次数随之增加,从而降低了可调度率。其中,各方法的α值随x的变化趋势与图 6相似,Proposed的可调度率明显高于其余方法。



 DownLoad:
DownLoad: