 ISSN
ISSN 





-
多输入多输出(multiple input multiple output, MIMO)技术是提高无线通信可靠性的一个重要手段,其标准主要为IEEE802.16e和IEEE802.11n[1]。STBC是一种在MIMO系统中有效的编码方式[2]。无论在军用还是民用领域,MIMO系统中的信号识别问题日益重要,STBC的识别问题同样受到学术界越来越多的关注。目前,主流的STBC盲识别算法主要分为最大似然的识别法(maximum likelihood, ML)[3-4]和基于特征值的识别法(feature based, FB)[5-16],其中后者根据使用方法的不同,可分为基于$k$阶累积量(或$k$阶矩)的识别法[5-12]和基于高阶循环谱的识别法[13-16]。ML方法给出了正确识别概率的最优解,然而其识别过程需要预先知道信道信息、噪声信息和载波频偏(carrier frequency offset, CFO)等,且算法复杂度较高[3-4]。FB法是从接收信号中提取特征参数,根据不同的特征参数识别不同的STBC。其中,利用接收信号的二阶统计特征的算法是最常用的算法[5-9],文献[10-12]在多天线条件下使用接收信号的四阶统计特性进行分析,基于二阶循环平稳[13-15]和四阶循环平稳[16]的算法同样是当前区分STBC的热点算法。
不少研究者在研究STBC的识别算法时仅考虑了空间复用(spatial multiplexing, SM)和Alamouti(AL)[17]两种码[7, 9-10, 15],没有考虑更一般的STBC。大多数算法是在多接收天线条件下对STBC识别算法进行研究[3-8, 13-16]。然而在实际系统中,受限于接收端的尺寸和功率等因素,接收天线的数量越少越好。现有的多接收天线下的基于特征参数的算法均不适用于单接收天线,因此单接收天线下的STBC识别方法的研究非常重要。
目前为止,研究单接收天线下STBC识别方法的文献较少[9-12]。文献[9]利用接收信号在不同时延下的二阶统计特征进行区分,其缺点是对接收信号的利用率低,其将接收信号分成了两份,相当于将接收样本数缩小了一半,从而影响到识别概率,且该文仅对SM和Al进行区分,没有扩展到其他常用STBC。文献[10]和文献[12]方法类似,是对接收信号的带时延的四阶矩(fourth-order lag products, FOLP)进行傅里叶变换(FFT),以此作为特征参数进行识别,该方法需要大量接收样本进行计算,计算复杂度较高,在较少的样本条件下,该方法识别效果一般。文献[11]根据不同的空时分组码的四阶累积量不同来达到识别目的,尽管取得了较好的识别效果,但所需识别样本数较多。
本文在单天线条件下提出一种新的算法进行STBC识别。首先将接收信号处理成为不同的两段,再对其经验分布函数之间的距离进行K-S检测,最后根据本文构造的STBC决策树达到识别目的。其具有以下5个优点:
1) 适用于单接收天线系统;
2) 不需要预先知道信道信息、噪声信息和调制方式;
3) 所需接收样本数少;
4) 适用于至少4种STBC的识别;
5) 无论在高斯还是非高斯条件下,算法在衰落信道中均具有良好的识别性能。
HTML
-
考虑具有${n_t}$个发射天线、1个接收天线的线性STBC系统,每组码中需要传输的符号数为$n$,传输的时间间隙数为$L$,则STBC码矩阵维数为${n_t} \times L$,定义为${\boldsymbol{C}}({\boldsymbol{S}})$。定义${\boldsymbol{S}} = [{s_1}, {s_2}, \cdots, {s_n}]$为某组码待传输的符号,假定信号${\boldsymbol{S}}$为经过相同线性调制方式调制($ \ge 2PSK, \ge 4{\rm{QAM}}$)的复信号(BPSK调制的是实数信号),且独立同分布。不失一般性,假设${\boldsymbol{y}}(0)$为第一个接收信号,${{\boldsymbol{C}}_{{k_1}}}({{\boldsymbol{S}}_j})$对应发射信号中第j个空时分组码的第$k + 1$列。在加性噪声干扰下,第$k$时刻接收到的符号为[9]:
式中,$ {\boldsymbol{X}}(k) = {{\boldsymbol{C}}_u}({{\boldsymbol{S}}_v}) $,$u = (k + {k_1})\bmod L$,$v = j + $ $(k + {k_1})divL$,$z\bmod L$和$zdivL$分别表示$z/L$的余数和商;$ {b_k} $为加性高斯白噪声(additive white Gaussian noise, AWGN);${\boldsymbol{H}} = [{h_1}, {h_2}, $$ \cdots, {h_{{n_t}}}]$为衰落信道。
-
近两年,多数学者对于STBC识别的研究仅限于SM码和AL码[7, 9-10, 15],一方面SM和AL码是最常用最简单的编码形式,另一方面SM和AL码较容易区分。然而适用于SM和AL的识别算法不一定适用于其他常用STBC。本文对常用的4种STBC进行区分,其中STBC3和STBC4是实际系统中常用的编码方式[2, 18],也多次在识别算法中被提到[3-6, 8, 12-14, 16]。分别为:
1) SM:发射天线数${n_t} = j$(不失一般性,在本文中令$j = 2$),码矩阵长度$L = 1$[2],有:
2) AL:发射天线数${n_t}$=2,码矩阵长度$L$=2[17],有:
3) STBC3:发射天线数${n_t} = 3$,码矩阵长度$L = $4[2],有:
4) STBC4:发射天线数${n_t} = 3$,码矩阵长度$L = $8[18],有:
1.1. 信号模型
1.2. STBC选取
-
在接收端,接收信号可表示为:
式中,N为接收信号数量。定义2个长度为$N - T$的向量:
定义${{\boldsymbol{Y}}_0}$和${{\boldsymbol{Y}}_1}$各元素之间的相关函数为:
式中,$| \cdot |$为绝对值函数;$i = 0, 1$。不失一般性,设$N\bmod 2T = 0$,若$N\bmod 2T$不为零,可对接收信号${\boldsymbol{Y}}$进行处理,去掉尾部$N\bmod 2T$个元素。由式(5) 可分别得到${{\boldsymbol{Y}}_0}$和${{\boldsymbol{Y}}_1}$的自相关向量:
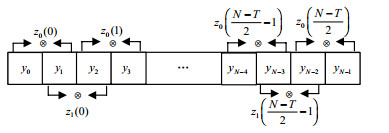
式中,$ M = \frac{N}{{2T}} - 1 $。以$T = 1$为例,式(3)~式(6) 的含义如图 1所示,其中${{\boldsymbol{Y}}_0} = [{y_0}, {y_1}, \cdots, {y_{N-2}}]$,${{\boldsymbol{Y}}_1} = [{y_1}, $ ${y_2}, \cdots, {y_{N-1}}]$。

-
观察编码矩阵可得,传输信号为SM时,向量${{\boldsymbol{Y}}_0}$和${{\boldsymbol{Y}}_1}$均为独立同分布;传输信号为AL、STBC3和STBC4时,向量${{\boldsymbol{Y}}_0}$和${{\boldsymbol{Y}}_1}$并非独立同分布。当$T$确定时,传输信号为SM时向量$ {{\boldsymbol{Z}}_i} $均为独立同分布,传输信号为AL、STBC3和STBC4时$ {{\boldsymbol{Z}}_i} $不一定独立同分布。以Alamouti STBC为例,当$T = 1$时,$ {{\boldsymbol{Z}}_i} $存在两种情况:
1) 当接收信号的第一个符号对应AL码矩阵的第一列时,$ {{\boldsymbol{Z}}_0} $独立同分布,$ {{\boldsymbol{Z}}_1} $非独立同分布;
2) 当接收信号的第一个符号对应AL码矩阵的第二列时,$ {{\boldsymbol{Z}}_1} $独立同分布,$ {{\boldsymbol{Z}}_0} $非独立同分布。
通过计算在特定$T$(此处$T = 1$)下$ {{\boldsymbol{Z}}_i} $是否为独立同分布来进行SM和AL的区分。同样,$T$的取值恰当,也可区分STBC3和STBC4。
记情况1) 和情况2) 任意发生一种时为事件Event,记$ {{\boldsymbol{Z}}_0} $和$ {{\boldsymbol{Z}}_1} $均独立同分布时为事件iid,记事件Non为未定事件:既可能出现事件Event,也可能出现事件iid。
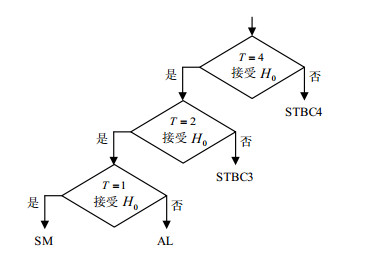
如表 1所示,在$T = \{ 1, 2, 4\} $时,不同STBC对应的$ {{\boldsymbol{Z}}_i} $呈现出不同的分布情况。以此作为区分不同STBC的依据,定义事件iid为假设检验的事件${H_0}$,定义非iid的事件为${H_1}$:
T SM AL STBC3 STBC4 1 iid Event Non Non 2 iid iid Event Non 4 iid iid iid Event 当$T = 4$时,拒绝${H_0}$的STBC为STBC4;排除STBC4,当$T = 2$时,拒绝${H_0}$的STBC为STBC3;排除STBC3,当$T = 1$时,拒绝${H_0}$的STBC为AL,接受${H_0}$的码为SM。可表示为图 2所示的决策树。

-
判断两个经验分布函数是否同为独立同分布可使用两样本的K-S检验[19]。
令K-S检验中接收信号的经验累积分布函数为:
式中,$\text{Ind}( \cdot )$为指示函数,当输入参数为真时,指示函数值为1,当输入参数为假时,指示函数值为0。两个分布函数之间最大距离可表示为:
以此作为拟合优度统计值。当满足条件$\hat D \ge \beta $时,拒绝假设${H_0}$,其中:
式中,$\hat H$为K-S检验的估计;$\beta $为门限值;$\alpha $为置信区间,可表示为:
式中$ \mathit{\Phi} (x) \buildrel \Delta \over = 2\sum\limits_{i = 1}^\infty {{{( - 1)}^{i - 1}}{{\rm{e}}^{ - 2{i^2}{x^2}}}} $。
-
本文提出的针对STBC识别的算法步骤为:
1) 获取接收信号${\boldsymbol{Y}}$;
2) 通过式(3)~式(6),求取$ {{\boldsymbol{Z}}_0} $和$ {{\boldsymbol{Z}}_1} $;
3) 通过式(12),求取门限值$\beta $;
4) 通过式(8) 和式(9),求取经验累积分布函数$ {\hat F_0}(z) $和$ {\hat F_1}(z) $;
5) 计算$ {\hat F_0}(z) $和$ {\hat F_1}(z) $之间最大距离$\hat D$;
6) if $\hat D < \beta $ then接收${H_0}$;
7) else拒绝${H_0}$;
8) end。
2.1. 识别参数
2.2. 决策树
2.3. 两样本K-S检验
2.4. 算法流程
-
无特殊说明的话,算法经过1 000次蒙特卡洛仿真,对每次蒙特卡洛仿真,信道采用Nakagami-m衰落信道,$m = 3$,使得${\rm{E}}[|h_i^2|] = 1$[20],噪声为零均值加性高斯白噪声(AWGN),其信噪比为${\rm{SNR}} = 10\lg ({n_t}/{\sigma ^2})$,信号采用QPSK方式进行调制,接收信号采样数量$N = 4{\rm{ }}096$,置信区间$\alpha = 0.99$。频谱整形采用滚降系数为0.35的升余弦滤波器,过采样系数$P = 8$,接收端采用13阶巴特沃斯低通滤波器,发射滤波器和接收滤波器的时延$\varepsilon $和载波相位偏差${\phi _0}$分别取分布为$[0, T)$和$[0, 2{\rm{\pi }})$的随机数,载波频偏$\Delta {f_c} = 0.04/T$。采用两种识别概率衡量仿真结果[10]:
1) 平均识别概率:
式中,$ \mathit{\Omega} \in \{ \text{SM, AL, STBC3, STBC4}\} $。
2) 正确识别概率:
-
默认条件下对4种STBC进行识别,如图 3所示。其中,SM识别效果最好,SM的识别概率接近置信区间0.99。STBC3的识别效果最差,这是由于STBC3的码矩阵中包含符号0,这将影响到${{\boldsymbol{Z}}_i}$的分布特性,使得分布函数$ {\hat F_0}(z) $和$ {\hat F_1}(z) $的距离较小,导致STBC3在较小信噪比下不易识别。AL、STBC3和STBC4的识别概率随着信噪比的提高而提高,这是由于在低信噪比下,噪声使得经验分布函数$ {\hat F_0}(z) $和$ {\hat F_1}(z) $的距离变小;信噪比的提高,抑制了噪声的影响,提高了识别性能。

-
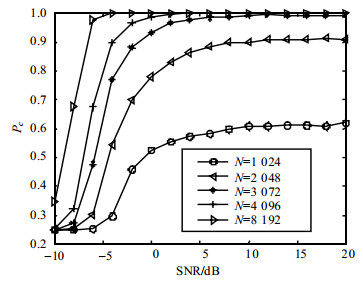
图 4为采样数不同时平均识别概率的变化,采样数$N \in \{ 1{\rm{ }}024, {\rm{ }}2{\rm{ }}048, 3{\rm{ }}072, {\rm{ }}4{\rm{ }}096, {\rm{ }}8{\rm{ }}192\} $。算法的平均识别概率在采样数为1 024和2 048时分别为0.6和0.9,在3 072以上时,达到0.99~1。采样组数过少使得$T$值较大,$ {\hat F_0}(z) $和$ {\hat F_1}(z) $中元素过少,不利于抑制噪声和信道对经验分布函数的影响,导致STBC3和STBC4识别效果较差,从而影响平均识别概率。以STBC4为例,STBC4需要在$T = 4$时进行识别,当采样数$N = 2{\rm{ }}048$、$T = 4$时,由式(6)、式(8) 和式(9) 可知,自相关向量$ {{\boldsymbol{Z}}_i} $和经验累积分布函数$ {\hat F_i}(z) $只有255个元素,导致识别效果较差。图 5为$N = 2{\rm{ }}048$时4种STBC的正确识别概率,较小的样本数量对STBC3和STBC4影响较大,对SM和AL影响较小。


-
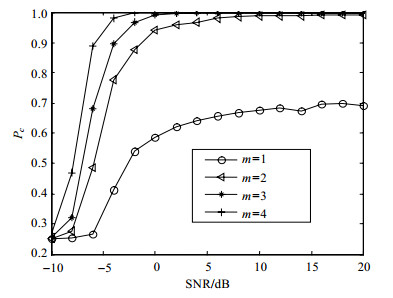
取不同的Nakagami-m信道参数进行仿真,$m \in \{ 1, 2, 3, 10\} $,仿真结果如图 6所示。平均识别概率随着m的增大而增大,较好的信道条件增大了经验分布函数之间的距离,有利于STBC的识别。

-
图 7为不同线性调制方式下的平均识别概率曲线图,BPSK调制的是实数信号,算法在传输信号为实数时性能更好,可在信噪比为-6 dB左右达到较好的性能;MPSK调制方式比MQAM性能更好,这是由于样本数量不够大引起的,若样本数$N = 8{\rm{ }}192$,16QAM和64QAM的性能可分别达到0.997和0.998左右。

-
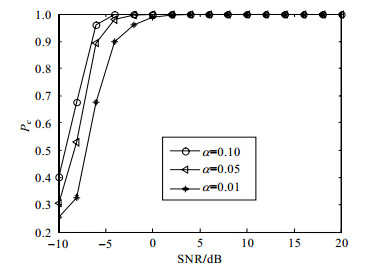
如图 8所示,算法在$\alpha \in \{ 0.1, 0.05, 0.01\} $下进行仿真。在较高信噪比下,设置不同置信区间,识别概率均接近1;在较低信噪比下,$\alpha $减小时算法识别概率也随之减小。其原因在于$\alpha $较高时,门限$\beta $也较高,因此识别概率较大。

-
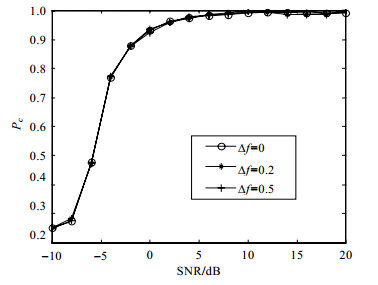
图 9为载波频偏$\Delta f \in \{ 0, 0.2, 0.5\} $下的平均识别概率,可以看出载波频偏对本文算法的性能影响不大,这是由于式(5) 中绝对值的处理减小了载波频偏的影响。

-
比较算法在非高斯噪声下与高斯白噪声下的性能,观察算法对非高斯噪声的鲁棒性。取样本数$N = 2{\rm{ }}048$和$N = 4{\rm{ }}096$进行仿真。取零均值二分布高斯噪声作为非高斯噪声[21],其由两个高斯白噪声以如下方式组成:
式中,$0 < \varepsilon < 1$为混合参数;${f_N}(g)$和${f_I}(g)$为零均值高斯白噪声,其方差分别为$\sigma _N^2$和$\sigma _I^2$。假定$\varepsilon = 0.01$且$\sigma _I^2/\sigma _N^2 = 100$,信噪比SNR通过总体方差获得:
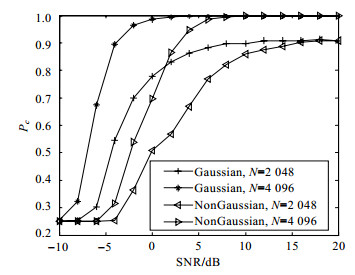
如图 10所示,图中Gaussian表示高斯噪声条件下,算法的平均识别概率;NonGaussian表示非高斯噪声条件下,算法的平均识别概率。可以看出,在信噪比较高时,高斯噪声环境和非高斯噪声环境对算法没有太大影响;在信噪比较低时,算法在高斯噪声环境下识别效果更好。在采样数$N = 4{\rm{ }}096$的情况下,当信噪比大于6 dB时,算法适用于非高斯噪声环境下的识别。

-
单接收天线条件下的STBC识别算法较少,其中文献[10]和文献[12]算法类似,因此,将本文算法与文献[9]和文献[12]的算法作比较。由于文献[9]仅研究了SM和AL的识别性能,对于其他空时分组码的识别问题没有说明;文献[12]则研究了SM、AL、STBC3和STBC4的性能,且两篇文献达到较好性能所需的样本数不同,因此本文分别与两篇文献进行比较。
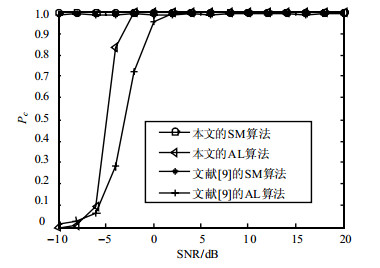
首先比较本文算法与文献[9]的算法。取采样数$N = $$2{\rm{ }}048$,采用QPSK方式进行调制,Nakagami-m衰落信道参数$m = 3$,噪声为零均值高斯白噪声,置信区间$\alpha = 0.99$,仅对SM和AL平均识别概率进行研究。图 11为本文算法与文献[9]算法的识别性能的比较,可以看出,本文算法的识别性能优于文献[9]的识别性能。其原因在于文献[9]在识别参数选取时将接收信号分成不交叠的两段,使得用于单次识别的样本数量近似为$N/2$(略大或略小于$N/2$,但两段信号平均长度小于$N/2$),而本文提出的算法用于单次识别的样本数量为$N - 1$,本文提出的算法接收样本利用率高,识别效果也较好。

其次将本文算法与文献[12]的算法进行比较。取采样数$N = 4{\rm{ }}096$,采用QPSK方式进行调制,Nakagami-m衰落信道参数$m = 3$,噪声为零均值高斯白噪声,置信区间$\alpha = 0.99$,对SM、AL、STBC3和STBC4平均识别概率进行研究。
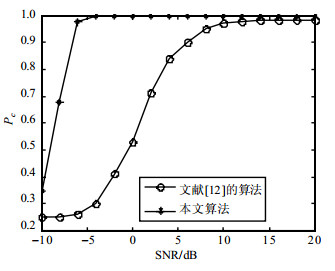
图 12为在上述仿真条件下,本文算法与文献[12]算法的性能比较。可以看出,本文算法的识别概率明显优于文献[12]。文献[12]使用基于带有时延的四阶累积量(fourth-order lag products, FOLP)的傅里叶变换作为特征参数,这需要大量的接收样本才能达到较好的识别性能,在样本数较少时该算法的识别性能较差,且在高信噪比条件下,文献[12]的算法识别概率为0.98左右,本文算法则趋近于1。

3.1. 识别不同STBC的性能

3.2. 采样数$N$对算法影响

3.3. 信道参数对算法影响
3.4. 不同调制方式对算法影响

3.5. 不同置信区间对算法的影响
3.6. 不同载波频偏对算法的影响
3.7. 非高斯噪声下算法性能
3.8. 与其他算法性能比较
-
本文提出了一种在单接收天线条件下的STBC盲识别算法。通过构造两段接收信号序列,求得其经验分布函数,使用K-S检验的方法,检测两个经验分布函数之间的距离,从而达到识别STBC的目的。对本文提出的算法在不同采样数、不同信道参数、不同调制方式、不同置信区间和不同载波频偏的条件下进行了仿真,并讨论了算法在非高斯噪声下的性能,最后将本文算法与仅有的两篇单接收天线下的文献进行了比较。仿真结果表明,本文提出的算法性能较好。

 DownLoad:
DownLoad: