 ISSN
ISSN 





-
测谎,是对谎言的鉴别活动。从心理学角度,测谎技术分为准绳问题测试法与犯罪情景测试法(guilty knowledge technique, GKT)。后者主要是测试犯罪嫌疑人大脑中是否留有犯罪人应当留有的有关犯罪行为的记忆痕迹。该技术的心理基础是认知心理。P300是事件相关电位(event-related potential, ERP)[1]中的一种内源性成份,出现在刺激后300~800 ms时间窗口内的一个正向波[2],主要反映了受试者的思维与决策过程。利用GKT技术进行测谎的原理是与案情相关的事物会引起罪犯进行更大的信息加工,从而引出高幅值ERP,而无辜者则相反。1987年,文献[3]首次利用事件相关电位进行测谎并获得实验上的成功。国内的作者也基于P300成分证明了测谎的可能性[4]。
研究表明,大脑神经元活动及其脑电(EEG)都表现为非线性动力学低维混沌特征[5]。近几年,脑电研究人员开始探索脑电信号的非线性特征——复杂度。复杂度的最初算法实现由文献[6]给出,称为算法复杂度,又称柯尔莫哥洛夫复杂度(kolmogorov complexity, KC),简称KC复杂度。将KC复杂度用于脑电分析,可以刻画并区分不同状态下的脑电序列的复杂度[7]。近年来,研究人员又提出了其他复杂性测度。文献[8]引入了近似熵(approximate entropy, ApEn)理论,近似熵描述的是一维序列进行多维空间重构后,维数由m增加至m+1时产生新模式的可能性大小,利用该算法,只需少量数据就可得出稳定的数值。文献[9]提出了样本熵的概念,进一步提高了熵值算法的准确度。
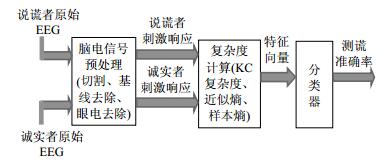
目前为止,将脑电信号的复杂度特征用于谎言识别是否有效的研究还未见报道,基于GKT协议及脑电信号的P300成分,本文提出对说谎者和诚实者的脑电信号提取复杂度特征进行识别的方法。研究中,选用了广泛应用的3种典型的复杂度指标:KC复杂度、近似熵和样本熵,分别对两类受试者的多导脑电信号进行特征提取,最后使用分类器对两类受试者的特征样本进行分类,本研究的脑电信号处理基本流程如图 1所示。

HTML
-
本文选取3种典型复杂性测度算法,其中,KC复杂度是把时间序列二值化为符号序列,然后对序列反复进行如下操作:每次添加一个元素构成一个检验子串,如果该子串在除去最后添加的那个元素之前所构成的序列中已经出现过,那么所构成的新序列的复杂度维持不变,并继续添加元素,直到上述情况未出现,复杂度增加1,继续添加元素并建立新的检验子串,如此反复进行,直到结束[10]。KC复杂度反映了给定序列随其长度的增长出现新模式的速率,即序列接近随机的程度。
Shannon熵理论用于复杂度刻画的理论基础即熵值越低,时间序列的自我相似性越高,反之则序列随机性越强,序列复杂度越高。样本熵与近似熵的最大区别就是无需进行自身模板匹配。本文仅对样本熵算法步骤描述如下:
1) 将信号表达为一个N点的时间序列:
2) 构造一组m维向量:
其中,
3) 定义两个向量${{\boldsymbol{X}}_m}(i),{{\boldsymbol{X}}_m}(j)$之间的距离为分量之间的最大距离:
4) 给定一个r值,然后对每个i统计$d[{{\boldsymbol{X}}_m}(i),{{\boldsymbol{X}}_m}(j)]$中小于r×SD(SD中序列的标准差)数目${N^m}(i)$,并计算${C^m}(r)$:
式中,$C_i^m(r) = {N^m}(i)/(N - m)$。
5) 增加维数至m+1,重复上述步骤,计算$C^{m + 1}(r)$:
6) 样本熵定义为:
可见,样本熵的计算与参数m和r有关,m值越大,计算量越大,耗费时间越长;r值越小,噪声对结果的影响越显著,表示对序列自相似匹配程度要求越高。一般经验,对应N =1 000时,可以设m = 3,r可以在0.1~0.25之间选择[11]。
-
受试者为30名身体健康的本科生,年龄为20~23岁,平均年龄22.3岁,右利手,无神经精神疾病及记忆障碍,视力正常。将他们随机分为无辜和说谎两组,每组各15名。标准三刺激模式作为测谎协议[12-14],刺激信息为6张仿真珠宝图片,风格和材质相近,但颜色等细节特征存在显著差异。
实验要求说谎者“偷走”保险箱中的两个珠宝中的任意一个,作为探针刺激(Probe, P),箱中另外一个作为靶刺激(Target, T),其余珠宝作为无关刺激(Irrelevant, I);诚实者认清保险箱中放入的唯一的一个珠宝,要求受试者看清该物品的细节信息,将其作为T刺激,从剩余的5个珠宝中任选一个作为P刺激,其余珠宝作为I刺激。实验过程中,屏幕上随机显示6张珠宝图片,要求受试者对看到的每张图片尽快做出反应,即要求诚实者全部“说真话”(见过该珠宝按鼠标左键,没见过该珠宝按鼠标右键),而说谎者面对P刺激时,按右鼠标键,即回答没有见过,面对其余两类刺激时“说真话”。E-Prime2.0作为刺激软件。实验时每张图片随机出现50次,刺激间隔1.6 s,图片停留时间0.5 s。每次实验中,I、P和T刺激出现次数依次为120次、30次和30次。一次实验后休息5 min再重复上述实验5次。对行为学数据、响应时间及响应错误率,分别进行统计分析,显示两种受试者无显著差异。
-
采集电极如下:F3、Fz、F4、C3、Cz、C4、P3、Pz、P4、O1、Oz、O2,双侧乳突为参考电极,前额接地。眼电电极放在标准位置,Synamps放大器对信号进行放大,放大倍数500,通带频率为0.05~70 Hz,采样率500 Hz,各导联阻抗均小于3 kΩ。
首先将采集的原始脑电用Neuroscan设备自带软件去除眼电,并去掉超过正负75 uv的信号段。然后在EEGLab工具箱[13]中对采集到的连续脑电信号进行分割,刺激前300 ms到刺激后1 300 ms作为一个Epoch。采用相干平均法,将每名受试者在各个电极上的每5个P刺激响应信号进行平均,称为少次刺激的平均ERP信号。
-
由于P300成分主要产生于刺激后300~800 ms,为了突出两类受试者的脑电响应信号的差异,对各个导联的少次平均ERP信号进行再次分割,只取出每个Epoch中刺激后的300~800 ms时间段的脑电信号,然后对它们分别计算KC复杂度、近似熵及样本熵。根据经验,本研究中,令m = 3,r=0.2。
对各个导联上两类受试者的3种复杂度指标进行t-test分析,以得到有显著差异的电极及对应的复杂度指标。
-
对每一种复杂度指标,取出有显著差异的电极对上的两类受试者的复杂度值,组成特征向量,并送入到支持向量机[15-16]中分类。得出各个复杂度指标的测谎分类准确率。
2.1. 受试者与测谎协议
2.2. 数据预处理
2.3. 特征提取及统计分析
2.4. 特征分类
-
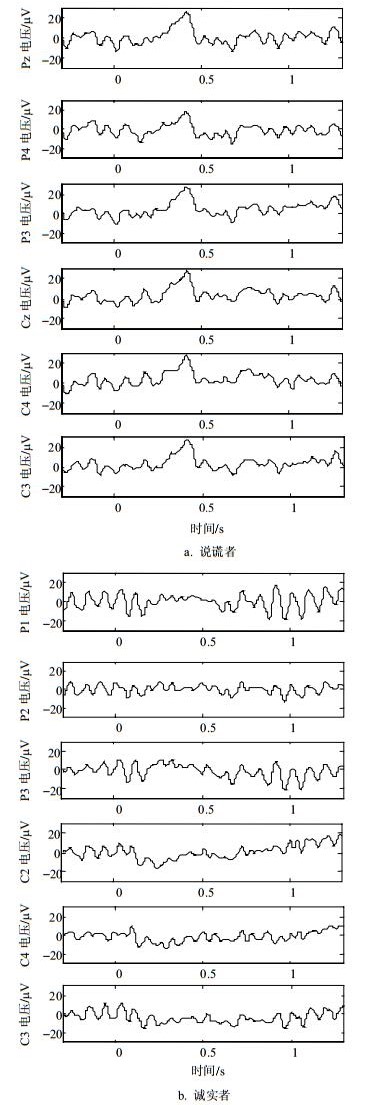
图 2为随机抽取的一名说谎者和一名诚实者在列举的6个极上的ERP波形,可以看出在这些电极上说谎者的ERP波形相对诚实者的ERP波形,P300特征都更为明显。

-
分别针对3种复杂度指标应用t-test统计检验(由于多重检验,使用了Bonferroni校正,即p < 0.01/12),测试两类受试者在各个电极上是否存在显著差异。表 1列举了12个电极上的两类受试者的3种复杂度指标的统计显著值。从表中可以看出,样本熵在更多的电极上存在显著差异。显著差异的电极有6个,分别是:P3、Pz、P4、C3、Cz、Oz。近似熵指标上达到显著差异的电极数为4个,分别是:P3、Pz、C3、C4。KC复杂度指标上达到显著差异的电极数为4个,分别是:F4、P4、C3、C4。
复杂度指标 显著差异性 F3 Fz F4 P3 Pz P4 C3 Cz C4 O1 Oz O2 样本熵 ○ ○ ○ * ** * ** * ○ ○ * ○ 近似熵 ○ ○ ○ * * ○ * * ○ ○ ○ ○ KC复杂度 ○ ○ * ○ ○ * ** ○ * ○ ○ ○ “**”代表两类受试者在该电极上的复杂度指标存在显著差异(p < 0.01/12);“*”代表两类受试者在该电极上的复杂度指标存在显著差异(p < 0.05/12);“○”代表受试者在该电极上的复杂度指标不存在显著差异。
针对每一种复杂度指标,构建分类模型:即将显著差异电极上的两类受试者的复杂度值取出,构成特征向量、对KC复杂度、近似熵及样本熵,3种分类模型的特征向量的维数分别为4、4及6。文中分别将3种分类模型称为KC复杂度模型、近似熵分类模型及样本熵分类模型。
对支持向量机分类器,首先取惩罚因子C和RBF核函数($K(x,y){\rm{ = }}{{\rm{e}}^{ - {\rm{1/2*}}\left\| {x - y} \right\|/{\sigma ^{\rm{2}}}}}$,Burges,1998) 的参数σ通过下列网格C=[2-5, 2-4, …, 28]和σ=[2-5, 2-4, …, 28](步长为2) 进行训练,得到最佳参数。然后使用十则交叉验证,对每则的训练样本集进行训练,得出训练敏感度及特异度,记为:TRsen及TRspe。最后,将对应的测试样本集送入到训练好的分类器中,得出测试敏感度及特异度,记为:TEsen及TEspe,因此,通过十则交差验证,对于训练和测试,均可以得到10对敏感度及特异度,分别计算敏感度及特异度的均值及标准差(standard deviation, SD),将它们显示在表 2中。
分类模型 准确率/% 训练 测试 TRsen±SD TRspe±SD TEsen±SD TEspe±SD 样本熵模型 92.77±2.40 93.00±3.06 91.18±2.51 91.52±2.92 近似熵模型 88.33±2.55 89.17±3.70 87.87±3.06 84.52±3.46 KC复杂度模型 74.43±4.23 72.11±4.54 74.00±4.32 72.12±4.59 表 2可见,样本熵分类模型的训练及测试准确率均明显高于其他两种复杂度指标的分类模型(不同分类模型之间的准确率进行t-test统计检验,均具有显著差异,p < 0.01);同时也发现样本熵与近似熵分类模型之间的准确率的差别较KC复杂度之间的准确率差别更小,即样本熵与近似熵分类模型的准确率更为接近;实验结果也发现KC复杂度模型相对于其他两种分类模型,标准差更大,即该复杂度指标产生的分类准确率波动性更大,推测应该是该复杂度指标相对于其他两种复杂度指标,更易受到噪声的干扰所致。通过计算,最后得到基于样本熵的分类模型的平均测试准确率为91.35%,高于基于KC复杂度模型的73.16%及近似熵分类模型的86.20%。
3.1. 预处理结果
3.2. 统计分析
-
本文首次将非线性特征——复杂度指标用于测谎研究中,对谎言实验中的EEG信号进行复杂度分析,计算了脑电信号的KC复杂度、近似熵和样本熵3种指标值,通过统计分析,得到两类受试者具有显著差异的电极,分别建立特征向量进行分类。
样本熵是在近似熵的基础上发展起来的一种复杂度指标,样本熵拥有近似熵的抗噪、抗干扰的优点,避免了近似熵计算过程中出现的统计量不一致问题,这应该是本文中基于样本熵的测谎准确率高于近似熵的测谎准确率的原因之一。研究结果发现在3种复杂度指标中,样本熵的分类准确率最高,表明了该复杂度指标用于测谎的有效性。
研究中也尝试对单个电极的特征样本用于分类器,并将它们的最高准确率与多电极的特征联合的方式做了对比,均发现低于多电极的特征联合的准确率,此结果说明,多电极上的复杂度指标联合形成特征向量后,具有更强的分类能力,也即说明不同电极上的复杂度信息并非完全冗余,而是可以互补,可以提供更多的复杂度信息,对分类更有利,进而说明了提出方法中的多导脑电特征提取方案的优势。
由于本文研究过程中对原始脑电信号进行了5次平均进行降噪处理。因此,在实际测试过程中,可只对被试者使用约5次刺激进行测试,相对于目前广泛使用的BCD和BAD[12]等方法,本文提出的这种少次刺激的测谎方法更加简便,并降低了被测人员的疲劳程度,更有利于提高测谎准确率。

 DownLoad:
DownLoad: