 ISSN
ISSN 





-
片上多核处理器MPSoC(multi-processor system-on-chip)把多个处理核心集成到一个芯片中,通过这些处理核心的并行工作提高系统性能,以满足日益增长的功能及性能需求[1]。其中,异构MPSoC中的处理器核心具有不同结构、地位、功耗及运算能力,大幅度增强了信息处理能力。在实际应用中,任务调度算法的优劣直接影响异构MPSoC系统的利用率[2],是被广泛关注的研究热点。
目前,针对复杂任务的调度技术主要有随机搜索调度技术和启发式调度技术[3-4]。随机搜索调度技术如遗传算法[5-6]、模拟退火算法[7]等,随着任务数和核数量的增加,搜索开销和计算复杂度呈非线性增长,收敛速度急剧下降。而启发式调度技术因设计简单且能够获得较好的次优解,获得更多研究者的青睐,涌现出大量研究成果,如:对任务进行分簇的边消除算法[8];为了减小通信依赖而对前驱任务进行复制的任务复制算法[9];根据任务属性构造任务列表以依次调度任务的最早截止时间优先算法[10]、关键路径算法[11]、优先级调度算法[12]等。但是在任务间依赖关系复杂、异构处理器核性能差异较大的情况下,以上算法灵活性较差,且存在处理器负载不均的问题。为此,研究人员在考虑核异构性的基础上,应用启发式调度技术以获得更好的调度性能。HEFT(heterogeneous earliest-finish-time)算法[13]将EDF算法应用于异构环境,是异构环境下很多其他调度模型的基础,但缺乏处理系统过载的能力。文献[14]提出的PLTSF(probably lag time shortest first)算法,通过复制fork节点将具有复杂依赖关系的任务转化为多个相互独立的并行任务树,再动态地计算任务树优先级,根据优先级将任务分配到处理器核上,但该算法每次只选择一个任务进行映射,效率较低。
本文提出了一种具备负载感知能力的异构MPSoC任务调度算法LATS(load-aware task scheduling),依据任务计算开销和任务间通信负载,将具有依赖关系的任务集划分为并行任务子集,在考虑处理器核负载状态的前提下,根据赋权二部图的最大权匹配将多个任务子集优化调度到适载处理器核上,提高了待调度任务集的总执行效率。仿真实验及结果表明,本文提出的算法在负载感知的基础上,有效降低了任务集的调度长度,提高了处理器核利用率。
HTML
-
定义 1 异构MPSoC环境是一个4元组E = (Core, Speed, Cap, Que)。
1) ${\rm{Core = }}\left\{ {{\rm{Cor}}{{\rm{e}}_0}{\rm{,Cor}}{{\rm{e}}_{\rm{1}}}{\rm{,}} \cdots {\rm{,Cor}}{{\rm{e}}_{N - 1}}} \right\}$ 是具有N个处理器核的片上系统, $N \ge 2$ 。
2) ${\rm{Speed}} = \left\{ {{S_0},{S_1}, \cdots ,{S_{N - 1}}} \right\}$ 是处理器核运算速率的集合,处理器核的运算速率是由主频、流水线、缓存等因素共同决定,为简化模型,本文使用Si刻画第i个核的运算速率。
3) ${\rm{Cap}} = \left\{ {{C_0},{C_1}, \cdots ,{C_{N - 1}}} \right\}$ 是处理器核存储能力的集合,Ci表示第i个核总存储容量。
4) ${\rm{Que}} = \left\{ {{Q_0},{Q_1}, \cdots ,{Q_{N - 1}}} \right\}$ 是处理器核维护的等待队列的集合,Qi表示第i个核所维护的等待队列,|Qi|表示 ${\rm{Cor}}{{\rm{e}}_i}$ 上排队等待执行的任务数。
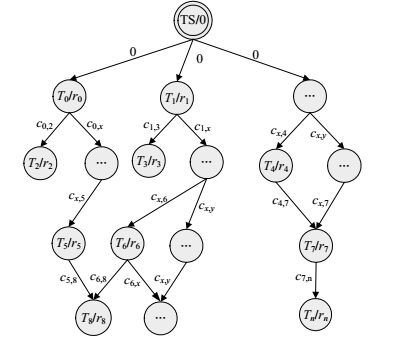
定义 2 待调度的任务集可表示为DAG图, $DAG = ((T,R),\mathit{\boldsymbol{C}},{\rm{TS)}}$ 。
1) $T = \left\{ {{T_0},{T_1}, \cdots ,{T_{n - 1}}} \right\}$ 是任务节点集合, $n \ge 1$ 。Ti对应任务集中的一个任务。
2) $R = \left\{ {{r_0},{r_1}, \cdots ,{r_{n - 1}}} \right\}$ 是任务权重集合,ri表示任务Ti的计算开销, ${r_i} \in {R^ + }$ 。
3) C是任务间通信权重矩阵, ${c_{i,j}}$ 表示任务Ti到Tj的通信负载, ${c_{i,j}} \ge 0$ ;若 ${c_{i,j}} = 0$ 表示任务Ti与Tj没有依赖关系。
4) TS为虚拟起始节点,TS的计算开销为0,TS到其直接后续的通信负载为0。
如图 1所示,该DAG图表示了n个任务的计算开销,任务间依赖关系和通信负载。后续任务需要使用其所有直接前驱任务的输出结果或占用的系统资源,因此,后续任务要等其所有直接前驱任务都执行结束后,才能开始被调度执行。

-
为了充分利用MPSoC丰富的计算资源,LATS算法在任务子集划分阶段以尽量降低任务间通信负载为目标,将含有n个任务的任务集划分为m个并行任务子集。
任务直接前驱所在的集合称为前驱任务子集,任务的最大前驱开销 ${\rm{MaxPredCost(}}{T_i}{\rm{)}}$ 是当前任务Ti的所有前驱任务子集的开销与通信负载之和的最大值。
式中, ${T_j} \in {\rm{pred}}({T_i})$ 表示任务Tj是Ti的直接前驱;Taskj是Tj所在的前驱任务子集; ${T_i} \in {\rm{Tas}}{{\rm{k}}_i}$ 表示Tj已经被划分到任务子集Taski中。
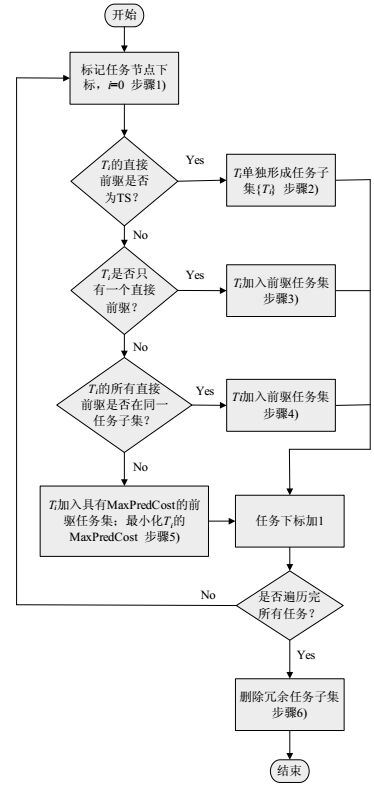
LATS任务子集划分算法如图 2所示。

1) 按任务节点索引值递增的顺序遍历所有节点。任务节点索引值定义为:
2) 如果Ti的直接前驱为TS,则Ti单独形成任务子集Taski。
3) 如果Ti的直接前驱不为TS,且Ti只有一个直接前驱Tj,则直接将Ti加入Tj所在任务子集Taskj,形成新的任务集Taski,若已经遍历了Tj的所有直接后续,删除冗余任务子集Taskj。
4) 如果Ti的直接前驱不为TS,且Ti的多个直接前驱都在同一个任务子集Taskj中,则直接Ti加入Taskj,并将Taskj重命名为Taski。
5) 如果Ti的直接前驱不为TS,且Ti的多个直接前驱分属于p个不同的任务子集,此时 ${T_i} \notin {\rm{Tas}}{{\rm{k}}_i}$ ,根据式(1),计算Ti的最大前驱开销 ${\rm{MaxPredCost(}}{T_i}{\rm{)}}$ ,并选取具有最大前驱开销的直接前驱Tj所在的任务集Taskj加入,形成新的任务子集Taski,若已经遍历了Tj的所有直接后续,删除冗余任务集Taskj;将Ti划分到Taski后, ${T_i} \in {\rm{Tas}}{{\rm{k}}_i}$ ,重新计算最大前驱开销,对于剩余的p-1个前驱任务子集,若其中某个前驱任务子集Taskh合并到Taski中能减小Ti的最大前驱开销,即:min imize(MaxPredCost(Ti)),则合并Taskh到Taski中,否则不合并。
6) 若已遍历完所有任务,则在生成的任务子集中删除冗余集合:若任务子集Taski包含于Taskj,则删除Taski;否则转到步骤2)。
-
在异构MPSoC环境下,每个处理器核的计算速率和当前负载都是不相同且在随时变化的,负载感知调度综合考虑当前处理器核的负载、处理器核运算速率、任务间通信负载和任务计算开销等多个方面的因素,将划分好的任务子集在运行时环境下动态地映射到合适的处理器核。
Corei的负载状态通过LSi表示,分为超载、适载两种状态。核的负载状态需要在每次调度开始之前进行一次更新。
式中, ${T_{{\rm{hreshold}}}} \in (0,1)$ 表示核负载阈值,可根据应用场景设定; ${\rm{L}}{{\rm{S}}_i} = 0$ 表示Corei处于超载状态,即 $\sum\limits_{k = 0}^{|{Q_i}| - 1} {{r_k}} /{C_i} \ge {T_{{\rm{hreshold}}}}$ ,此时不能再向Corei分配任务,而应当选择向适载状态LSi=1的核分配任务子集。
待分配任务子集到处理器核的映射关系可表示为赋权二部图 $G = ({\rm{Task}},{\rm{Core}},E{\rm{)}}$ ,Task顶点集对应待分配的任务子集 $\{ {\rm{Tas}}{{\rm{k}}_0},{\rm{Tas}}{{\rm{k}}_{\rm{1}}}, \cdots ,{\rm{Tas}}{{\rm{k}}_{m - 1}}\} $ ;Core顶点集对应当前处于适载状态的处理器核的集合 $\{ {\rm{Cor}}{{\rm{e}}_i},{\rm{Cor}}{{\rm{e}}_j}, \cdots ,{\rm{Cor}}{{\rm{e}}_k}\} $ ;E为Task集合中的顶点到Core集合中的顶点的边,表示任务子集和处理器核的映射关系,边的权重定义为:
式中, $\sum\limits_{k = 0}^{|{Q_j}| - 1} {{r_k}} $ 表示Corej上负载任务的计算开销; $\sum\limits_{k = 0}^{|{\rm{Tas}}{{\rm{k}}_i}| - 1} {{r_k}} $ 表示Taski中所有任务的计算开销。于是,负载感知调度即在赋权二部图G中寻找覆盖顶点集合Task的最大权匹配。
MPSoC相较于多处理器系统和分布式系统,其核间通信速率大大提升,处理器核采用计算与传输重叠模式工作,即处理器核能够在运行任务的同时发送/接收数据,因此,在MPSoC环境下核间通信已不是影响处理器核执行效率的主要因素。
在赋权二部图G的顶点集 $V = {\rm{Task}} \cup {\rm{Core}}$ 上确定一个函数L,L满足以下条件:
则称L为图G的一个顶点标号。 $L({\rm{Tas}}{{\rm{k}}_i})$ 或 $L({\rm{Cor}}{{\rm{e}}_j})$ 称为顶点Taski或顶点 ${\rm{Cor}}{{\rm{e}}_j}$ 的一个标号。如:
就是图G的一个顶点标号。令
则具有边集EL的G的生成子图称为对应于顶点标号L的等价子图,记为GL。
基于赋权二部图最大权匹配的负载感知调度如图 3所示。

为了得到一个覆盖Task顶点的权最大的匹配,以下分情况讨论:
1) 根据式(2)更新处理器核负载状态,选择处于适载状态的处理器核 $\{ {\rm{Cor}}{{\rm{e}}_i},{\rm{Cor}}{{\rm{e}}_j}, \cdots ,{\rm{Cor}}{{\rm{e}}_k}\} $ 作为Core顶点集, $|{\rm{Core}}| \le N$ ;按照任务子集下标递增的顺序,在未处理的m′个任务子集选出 $\min \left\{ {|{\rm{Core}}|,m'} \right\}$ 个,并将选出的任务子集作为Task顶点集 $|{\rm{Task}}| \le m$ ,根据式(3)计算边权重,生成赋权二部图G。
2) 给出G的任意顶点标号L,求出GL,在GL中以Taski的下标递增的顺序,选一个最大匹配M。
3) 若M覆盖了Task顶点集中的所有顶点,GL就是G的最大权匹配,转步骤6);否则,选择Task集合中未被M覆盖,且下标最小的顶点x,令 $X = \{ x\} ,Y = \emptyset $ 。
4) 若GL中集合X的邻集 ${N_{{G_L}}}(X) \supset Y$ ,则转步骤5);否则, ${N_{{G_L}}}(X) = Y$ 时,计算
且由
给出新的顶点标号L′,用L′代替L。转到步骤2)。
5) 在 ${N_{{G_L}}}(X)\backslash Y$ 中选取一个顶点y,如果y被匹配M覆盖,且 $yz \in M$ ,则 $X = X \cup \{ z\} $ , $Y = Y \cup \{ y\} $ ,转步骤4);否则,在GL中找一条M-可增长路P,将P加入匹配M,再转步骤3)。
6) 若未分配完所有任务子集,转步骤1),否则算法结束。
-
LATS算法通过任务子集划分和负载感知调度两个步骤将具有依赖关系的任务调度到处理器核上并行运行。在任务子集划分阶段,算法遍历DAG图中所有任务,对每个任务再遍历其所有直接前驱以计算最大前驱开销用于子集划分,该阶段的复杂度为 $O(n \times d)$ ,n为总任务数,d为DAG图中节点的最大入度。在任务调度阶段,首先需要更新处理器核负载以选择适载处理器核作为调度目标,复杂度为O(N),N为处理器个数;其次根据赋权二部图中最大权匹配进行任务子集分配,复杂度为 $O(m \times N)$ ,m为任务划分阶段得到的任务子集个数。
考虑在最坏情况下,d=n-1,且每个任务单独形成一个任务子集,即m=n,则LATS算法复杂度为 $O(n \times (n - 1)) + O(N) + O(n \times N)$ 。在一般情况下, $N \ll n$ ,因此,LATS整个算法的时间复杂度应为 $O({n^2})$ 。
2.1. 任务子集划分
2.2. 负载感知调度

2.3. 算法复杂度分析
-
仿真实验利用随机DAG图生成器,设置任务节点数 $m \in \left\{ {25,50,75,100,125,150} \right\}$ 和任务的最大出度 ${\rm{out}}\_\deg {\rm{ree}} = \left\{ {1,3,5,|m|} \right\}$ ,生成24种不同类型的随机DAG图,随机生成每种类型的DAG图 1 000幅,对每幅图用随机函数生成的随机数表示任务计算开销和通信负载,并取1 000次测试结果的算术平均值作为计算结果,参与实验的随机DAG图数量为24M。仿真实验中, ${T_{{\rm{hreshold}}}}$ 取经验值0.85,同时还引入通信计算比CCR(communication to computation Ratio)度量调度算法在不同计算开销和通信负载下的性能。
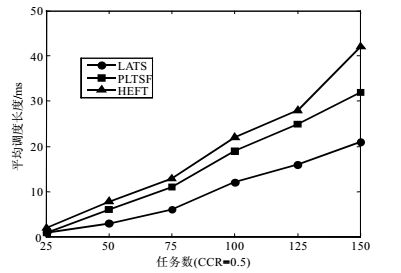
图 4、图 5分别在CCR为0.5和2时,LATS、HEFT和PLTSF的平均调度长度的比较图。


从两幅图均可看出,随着任务节点数的增加,系统负载相应增大时,LATS的平均调度长度明显优于HEFT和PLTSF。这是因为LATS考虑了当前系统所有核的负载,将一批任务同时分配到适载处理器核,而HEFT和LATS每次只把一个任务分配到能使其最早执行的处理器核上,只能实现局部最优。
值得注意的是,从图 4和图 5的对比可以看出,当CCR较大时,LATS算法相同任务数的平均调度长度得到进一步提高。这是因为在LATS算法任务子集划分阶段将具有最大前驱开销的任务划分在了一个任务子集,并在调度阶段将任务子集中的所有任务都调度到处理器核,降低了任务间的通信开销。
图 6统计了1 000幅含有150个任务节点的随机DAG图在运行LATS算法、HEFT算法和PLTSF算法的处理器核的利用率。异构MPSoC处理器核利用率是每个异构核利用率的算术平均值。

从图 6可知,LATS算法的处理器核利用率较之HEFT算法和PLTSF算法有所提升,且由于LATS算法每次分配一批任务到适载处理器核,而不是一个一个地分配,其处理器核利用率在任务集运行之初增长较快。


-
任务调度算法使得异构MPSoC的性能得以充分发挥,而处理器核的异构性、运行时负载和任务间依赖关系,是影响异构MPSoC上任务调度算法性能的关键因素。本文提出了一种负载感知的异构MPSoC任务调度算法LATS,在满足任务间依赖关系的前提下,根据计算开销和通信负载将待调度任务集划分为任务子集;在考虑处理器核负载状态的基础上,通过赋权二部图最大权匹配,将任务子集调度到适载处理器核上运行,提高了待调度任务集总执行效率。仿真实验结果表明,LAST算法有效降低了具有依赖关系的DAG任务图的调度长度,提高了处理器核利用率。

 DownLoad:
DownLoad: