 ISSN
ISSN 





-
定量评价科研人员的学术影响力,对引进人才、晋升、科研成果报奖、科研项目申请等具有重要的指导意义[1-4]。科研人员发表的文章是学术产出的主要形式[5-6],体现了科研人员的最新研究进展和成果,研究者公开发表的文章被学术界或同行重视、认可和引用的情况,一定程度上反映了学者的学术水平和影响力[7-9]。
目前,评价研究者的学术影响力有两种比较重要的方法,同行评议法[10]和文献计量法[11]。同行评议法只有少数专家参加且对参评专家的知识和经验要求较高,缺乏一个统一和公认的标准,容易受主观因素的影响,一定程度上影响着评价效果。发表文章数[12]、总引用量[13]、影响因子[14]等基本的文献计量指标在学术影响力评价中逐渐被认可和使用。2005年,文献[5]在基本的文献计量指标的基础上提出了一种评价学术成就的指标H指数。一个人的H指数越高,则表明其论文影响力越大。但是该指标也存在一定的局限性,H指数越大,越难增长,对于发表文章数较少而总引用量较高的学者的评价缺乏科学性[15]。文献[16]于2006年提出了G指数,用于改进H指数的不足,G指数是基于研究者累积贡献的评价指标,对于发表文章数较少而总引用量较高的学者的评价结果更加公平。此外,一些用于优化H指数的指标也相继被提出,用于弥补或完善上述文献计量指标的不足。2011年,Google公司为了评价一个学者的学术影响力提出了I10指数[17],I10指数是指作者发表的文章被引用10次以上的数目。在依据某一文献计量学指标对研究者进行学术影响力排名时,不但会由于研究者的指标值相同而无法排名的问题,而且会导致最后的评价结果具有一定的片面性。近年来,社会网络分析方法因其能够定量地反映出节点在网络中位置的重要性[18-22],进而可以与引文分析方法相结合用于评价学者在网络中的重要性,处于引文网络中重要位置的作者,具有较高的学术影响力[23]。但社会网络分析法因其动态性较弱,并不能展现作者学术影响力的动态变化过程[24]。
为了建立一个综合的评价体系去度量作者的学术影响力,文献[25]提出了综合考虑目标多属性的综合决策方法(又称TOPSIS方法),对作者学术影响力的评估问题进行了细致研究。然而,TOPSIS方法对于正理想解与负理想解中垂线上的点无法进行排序。本文将作者的发表文章数、总引用量、平均被引用量、I10指数、H指数等5种评价指标作为TOPSIS的输入属性,根据每项指标对作者学术影响力评价的准确性(AUC值)进行加权来计算其综合评价值,对作者进行排序。由于相对熵(relative entropy)[26]并不对称也不满足三角不等式,因此可以用于两个概率分布差别的非对称性度量,从而解决正理想解和负理想解的中垂线上的点无法排序的问题。基于此思想,本文提出了一个基于相对熵的作者影响力排序方法(TOPSIS-RE),用于评价研究者的学术影响力并对其做出排名。本文采用美国物理学会(American physical society, APS)的数据,将获得诺贝尔奖的文章的作者作为测试数据集,用AUC值说明算法的准确性。实验结果表明,基于相对熵的多属性排序方法(TOPSIS-RE)算得的AUC值为0.932 1,比总引用量指标提高了2.047%,并且比基于欧式距离的多属性排序方法(TOPSIS-ED)提高了0.833%。本文算法不仅解决了单个指标影响力值相同导致无法进行排序的问题,并且解决了基于欧氏距离的多属性排序方法(TOPSIS-ED)无法对中垂线上的点进行排序的问题,较全面准确地给出了作者学术影响力排名。
HTML
-
研究者vi的发表文章数目Ni用于量化其学术影响力。
-
作者vi一共发表了Ni,每篇文章的被引用次数记为cij(j=1, 2, …, Ni), 该作者vi的总引用量记为Ci,即:
总引用量Ci常被用于度量vi的学术影响力。
-
作者vi一共发表了Ni篇文章,总引用量为Ci,则该作者的平均被引用量记为Mi,即:
平均被引用量Mi亦被用于度量vi的学术影响力。
-
I10指数(I10-index)是由Google公司提出,并在Google学术网站上用以评价研究者学术影响力的指标。该指标是指作者vi已发表的文章中,被引用次数cij(j=1, 2, …, Ni)大于10次的文章个数m,记为Ii=m。
-
H指数的计算基于研究者vi的论文数量Ni及其论文被引用的次数cij(j=1, 2, …, Ni) "。一名科研人员的H指数是指其至多有h篇论文分别被引用了至少h次,则研究者vi的H指数为Hi=h。
1.1. 发表文章数
1.2. 总引用量
1.3. 平均被引用量
1.4. I10指数
1.5. H指数
-
本文运用上述5种指标对美国物理学会APS数据集中所有作者的学术影响力进行量化,这5种指标具有一定的代表性,反映了科研文章的数量、质量以及领域研究情况等方面的特性。作者可以表示为V={v1, v2, …, vn}点的集合,发表文章数N、总引用量C、平均被引用量M、I10指数I、H指数H作为作者的影响力属性,可以表示为F={f1, f2, f3, f4, f5}={N, C, M, I, H}。vi(fi)=(i=1, 2, …, n; j=1, 2, 3, 4, 5)表示研究者vi的第j个评价指标值,由于各种指标的量纲不同,需要标准化各项指标的值:
式中,tij(i=1, 2, …, n; j= 1, 2, 3, 4, 5)表示作者vi的第j个评价指标值标准化后的学术影响力值。
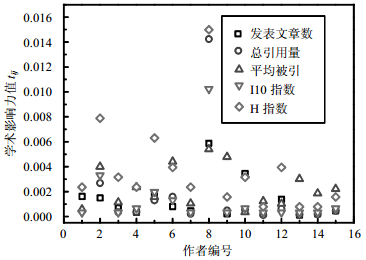
图 1随机选取了15位作者并比较其各项指标的值,可以看出,不同作者的部分指标尤其是I10指数和H指数值相近或者相同(如11、12、13、14号作者的I10指标值相同;3、7、12号作者的平均被引指标值相同等),这样就不能精确地区分不同作者的学术影响力。另外,由于每种指标的重要性程度不同,指标的选取对作者最终的排名有很大的影响。因此,本文提出多属性决策TOPSIS法,综合考虑多项指标来评价研究者的学术影响力,对作者进行排名。

TOPSIS[27]通过构造多属性问题的理想解,并以接近正理想解和远离负理想解这两个基准作为评价各可行方案的依据。正理想解是设想各指标属性都达到最满意的解,负理想解就是设想各指标属性都达到最不满意的解。本文首先计算作者的学术影响力值与正理想解和负理想解的距离,再根据算得的距离计算该作者影响力值贴近正理想解的程度,对作者进行排名具体步骤如下。
-
属性矩阵可以表示为P:
-
因为每种评价指标的量纲不同,作者的属性矩阵P应该转换成标准化矩阵T:
式中,每个元素tij(i=1, 2, …, n; 1, 2, 3, j=1, 2, 3, 4, 5)表示作者vi的第j个评价指标的学术影响力值,计算公式如式(3)所示。
-
第j个评价指标的权重系数为wj(j=1, 2, 3, 4, 5; ${\rm{ }}\sum {{w_j} = 1})$,因此,加权标准化矩阵R可以通过权重向量WT和标准化矩阵T=(tij)n×5重新构建:
式中,WT$[{w_N}\;\;{\rm{ }}{w_C}\;\;{\rm{ }}{w_M}\;\;{\rm{ }}{w_I}\;\;{\rm{ }}{w_H}]$根据层次分析法[26, 28]计算得到,具体过程如下:
1) 评价指标的比较矩阵
根据5种单指标对研究者学术影响力评价的准确性,可以区分各项指标的重要程度。发表文章数N只是对作者工作量简单的量化,并不能体现所发表文章的质量,因此这一指标最不重要。文章的总引用量C和平均被引用量M表现为作者发表的文章被别人继续研究的情况,从一定程度上说明了作者的学术影响力,所以总引用量C和平均被引用量M是非常重要的两个指标,并且重要程度相当。而I10指数,只是部分统计了作者已发表的文章中被引用量大于10的文章数目,不能完全量化作者的全局影响力,H指数的评价性质与I10指数类似,因此I10指数和H指数的重要性略逊于总引用量C和平均被引用量M。
表 1列出了按照式(7)三标度值方法构建的比较矩阵CV中的值。
CV N C M I H bi N 1 0 0 0 0 1 C 2 1 1 2 2 8 M 2 1 1 2 2 8 I 2 0 0 1 1 4 H 2 0 0 1 1 4 表 1中:
2) 判断矩阵
用极差法构造判断矩阵,因为f(bi, bj)=dij=db(bi-bj)/B,所得的矩阵D = (dij)n×n为一致性判断矩阵,其中db为一常量,是按某种标准预先给定的极差元素对的相对重要程度(一般在实践应用中常取db=9;${b_i} = \sum\limits_{j = 1}^5 {{\rm{c}}{{\rm{v}}_{ij}}} $(其中,cvij为表 1中比较矩阵CV中的元素);B=bmax-bmin,称为极差,其中bmax=max(b1, b2, b3, …, b5),bmin=min(b1, b2, …, b5) 。一致性判断矩阵D为:
权重系数W确定如下:
式中:${W'_i} = \prod\limits_{j = 1}^5 {{d_{ij}}} $; ${W_i} = \sqrt[5]{{{{W'}_i}}}$,(i,j=1,2,3,4,5)。
3) 一致性检验
一致性检验是为了检验各指标重要程度之间的协调性,避免出现前后矛盾的情况。按一致性检验指标PC.I.=(λmax)=− n)/(n-1)≤ε(ε为满足一致性要求所允许的最大值,一般根据具体情况来确定),进行一致性检验。其中λmax为一致性判断矩阵E(ei)=D×W的最大特征向量值,n为评价指标个数。λmax为:
通过计算得到${P_{{\rm{C}}{\rm{.I}}}}_{\rm{.}} = \frac{{{\lambda _{\max }}-5}}{{5-1}} = {\rm{0}}{\rm{.000 \;15}}$,因为ε =0.000 15 < 0.1(当ε ≤时,判断矩阵符合一致性0.1要求[29]),所以满足一致性检验。由以上计算可知,各评价指标相应的权重系数为WΤ=[0.041 4 0.373 0 0.373 0 0.106 3 0.106 3]。
-
本文将每种评价指标计算得到的作者学术影响力的最大值和最小值分别作为该项指标的正理想解rj+和负理想解rj−(j=1, 2, …, 5)。根据式(6)加权标准化矩阵R,可求得正理想解A+和负理想解A−分别为:
-
记Si+和Si−分别为作者vi的学术影响力值与正理想解A+和负理想解A−的欧氏距离(Euclidean distance),称为TOPSIS-ED,计算公式如下:
式中,rij表示作者vi的第j个指标对其学术影响力的量化值;rj+和rj−分别表示第j个指标对所有作者学术影响力评估值中的最大值和最小值。
当作者vi的学术影响力值处于正理想解A+和负理想解A−的中垂线上时,上面介绍的欧氏距离的计算方法无法对作者进行排序。由于相对熵并不对称也不满足三角不等式,可以用于两个概率分布差别的非对称性度量。考虑作者学术影响力值与正理想解和负理想解相对熵,可以解决欧氏距离中垂线上的点无法排序的问题。作者vi的学术影响力值与正理想解A+和负理想解A−的相对熵(relative entropy)[26, 30],称为TOPSIS-RE,计算公式如下:
-
根据Si+和Si−可以计算作者vi的学术影响力与理想方案的相对接近程度,记为Ai:
Ai值越大,表示作者vi的学术影响力越大。如果Ai =0,表示作者vi最不重要;相反,如果Ai =1,则表示作者vi最重要。根据Ai的值降序排序,可以综合评估作者vi的学术影响力排名。
2.1. 构造属性矩阵
2.2. 标准化矩阵
2.3. 加权标准化矩阵
2.4. 确定正理想解和负理想解
2.5. 计算距离
2.6. 计算接近度
-
本文采用美国物理学会(American Physical Society, APS)的数据,包括从1893年~2009年,超过46万篇已发表的文章。每篇文章包含唯一的文章编号、文章名、发表时间(年-月-日)、作者名字、以及每位作者的所属机构。另一个数据集用文章编号,提供了超过470万条引用关系。为了研究作者的学术影响力,本文最终处理完的数据包含10万多位作者,包括他们的发表文章情况以及被引用情况。
-
在APS数据集中,本文提出TOPSIS-RE方法,综合考虑5种指标对作者的影响力进行计算,并与单个指标及TOPSIS-ED方法作了对比。图 2随机选取了15位作者并比较其各项指标的值,纵坐标表示作者学术影响力值(5种单指标的数值为式(3)中的tij值,TOPSIS-ED和TOPSIS-RE的数值为式(13)中的Ai值)。依据指标值的大小,本文可以对作者进行排名。本文提出的TOPSIS-RE方法对不同作者的影响力值有相对明显的区分,解决了单个评价指标值相同导致无法进行排名的问题(如11、13、14号作者的H指数值相同);并且解决了TOPSIS-ED方法中垂线上的点无法排名的问题(如6、9号作者的TOPSIS-ED值相同)。再者,本文对不同指标进行加权,分析了各项指标在评价作者影响力时的重要程度,提高了依靠作者指标值进行排名的准确性。

-
为了评价本文方法对作者学术影响力排名的准确性,本文选取物理领域获得诺贝尔奖的文章的作者(去重之后共142位)作为测试数据集,如表 2所示,其他的作者作为非测试数据集。将实验求得的作者学术影响力排名和测试数据集作比对,计算其AUC的值[31-32],当AUC=1时,表明测试数据集里作者的排名都高于非测试数据集里作者的排名;当AUC=0.5时,表明所有作者的排名是随机的。较大的AUC值代表了较好的实验准确性,其计算公式如下:
文章DOI 作者人数 获奖年份 PhysRevLett.35.1489(1975) 36 1995 PhysRevLett.55.48(1985) 5 1997 PhysRevLett.61.826(1988) 5 1997 PhysRevLett.61.169(1988) 6 1997 PhysRevLett.48.1559(1982) 3 1998 PhysRev.140.A1133(1965) 2 1998 PhysRevLett.75.3969(1995) 7 2001 PhysRevLett.20.1205(1968) 3 2002 PhysRevLett.58.1490(1987) 23 2002 PhysRevLett.9.439(1962) 4 2002 PhysRevLett.84.5102(2000) 10 2005 PhysRevLett.84.3232(2000) 6 2005 PhysRevLett.61.2472(1988) 9 2007 PhysRevLett.57.2442(1986) 5 2007 PhysRev.122.345(1961) 2 2008 PhysRevLett.53.1951(1984) 4 2011 PhysRevLett.77.4887(1996) 8 2012 PhysRevLett.76.1796(1996) 5 2012 PhysRevLett.13.321(1964) 2 2013 式中,n表示比较次数(取105);n1表示测试数据集里作者影响力值高于非测试数据集里作者影响力值的次数;n2表示测试数据集里作者影响力值等于非测试数据集里作者影响力值的次数。
AUC计算结果如表 3所示,本文作者影响力评价指标中,总引用量指标相对于其他几个指标能较好的反应作者的学术影响力水平,其AUC值为0.913 4。基于相对熵的多属性排序方法(TOPSIS-RE),比单个指标中最高的总引用量提高了2.047%,并且比经典的TOPSIS-ED方法提高了约0.833%,对作者影响力排名的评估更加准确。
发表
文章数总引
用量平均
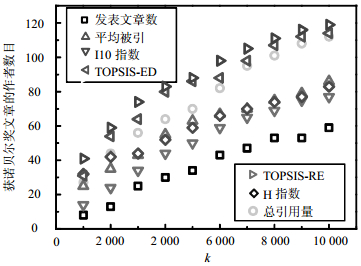
被引I10指数 H指数 TOPSIS-ED TOPSIS-RE AUC 0.754 2 0.913 4 0.881 3 0.822 7 0.809 3 0.924 4 0.932 1 为了直观地看出本文提出的TOPSIS-RE方法能更准确地从120 000位作者中识别出获得诺贝尔奖文章的142位作者,本文将各种指标的排名结果进行了对比分析。如图 3所示,横坐标表示排名列表中的前k个作者,纵坐标表示前k个作者中获得诺贝尔奖文章的作者数目。例如,按各指标值排名的前1 000位作者中,发表文章数指标、总引用量指标、平均被引指标、I10指数指标、H指数指标、TOPSIS-RE指标分别包含了8位、27位、25位、14位、32位、41位获诺贝尔奖文章的作者;前10 000位作者中,发表文章数指标、总引用量指标、平均被引指标、I10指数指标、H指数指标、TOPSIS-RE指标分别包含了59位、112位、86位、77位、83位、119位获诺贝尔奖文章的作者。图 3可以看出本文提出的TOPSIS-RE方法能够使获得诺贝尔奖的文章的作者排名较其他指标更靠前,对作者排名的准确性比单个指标高,并且高于TOPSIS-ED方法。

3.1. 数据描述
3.2. 实验结果

3.3. 评价方法
-
本文综合考虑作者的发表文章数、总引用量、平均被引用量、I10指数、H指数等5种指标,通过计算作者的学术影响力值与正理想解和负理想解的相对熵,提出了一种基于相对熵的多属性排序方法。在美国物理学会APS数据集上的实验结果表明,TOPSIS-RE方法算得的AUC值为0.932 1,比总引用量指标提高了2.047%,并且比TOPSIS-ED方法提高了0.833%。从图 3可以看出TOPSIS-RE方法比其他指标能更好地识别出获得诺贝尔奖文章的作者。本文算法不仅解决了单个评价指标值相同导致无法进行排名的问题,同时解决了TOPSIS-ED方法中垂线上的点无法排序的问题。运用相对熵的距离计算方法还会存在少部分作者的学术影响力相同的情况:由于数据集的限制,存在一部份作者,他们是某篇或者某几篇文章的合作关系,而数据集中没有他们发表的其他的文章信息,这会导致这部分作者的5种单指标的值完全一致,所以不管何种计算方法,都不能把他们区分开,需要更丰富的发表文章信息。
多属性排序方法的有效运用,取决于所选指标的优劣和赋予权重系数的合理性,因此可以进一步研究作者的学术影响力评价指标以及更优的赋权方法,使作者的排名更为准确。在研究作者学术影响力时,时间因素也会对作者的排名结果产生重大的影响,未来的工作中,将通过年份的划分更细化地研究作者学术影响力动态变化。另外,通过引文网络,研究网络的结构对理解作者的学术地位和合作模式具有重要意义。

 DownLoad:
DownLoad: