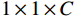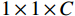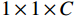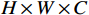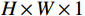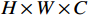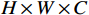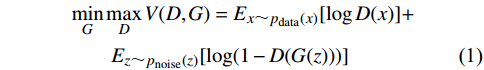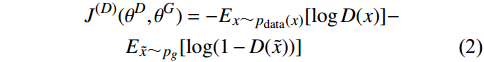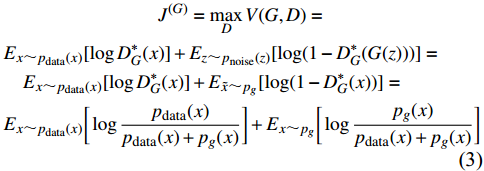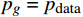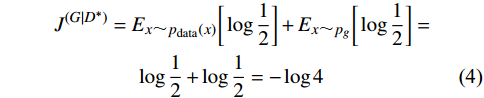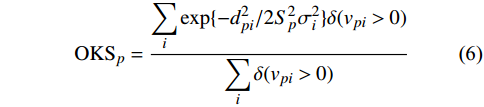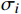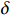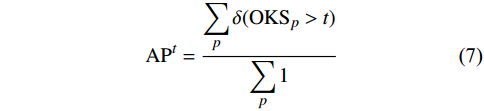ISSN
ISSN 

| Citation: |
LIU Changyuan, ZANG Yancheng, LAN Chaofeng. Research on Multiplayer Pose Estimation in Complex Sports Scenes[J]. Journal of University of Electronic Science and Technology of China, 2024, 53(6): 930-939. DOI: 10.12178/1001-0548.2023233

|
In terms of the problems such as mutual occlusion, self-occlusion, sports equipment occlusion and complex background interference among athletes in motion scenes, a high-resolution feature generation recovery network is proposed in this paper. The attention fusion mechanism is introduced to screen the useful feature information channels. The deconvolution and multi-scale feature fusion modules are added to deal with the pose estimation tasks for small target portraits and large and medium-sized target portraits in a hierarchical manner. The adversarial module is designed and generated to complete and predict the missing parts to obtain the keypoint heat map, the keypoint connection mode is determined through the pose skeleton and the optimal matching algorithm, and the visual pose estimation results are output. Experimental results on MSCOCO and Crowd Pose datasets have showed that the pose estimation method is more effective in complex motion scenes.
人体姿态估计的研究对象是图像或视频中的人像,具体表现方式是对检测到的人像定位出关节点的正确位置并标注出来,最后可视化输出到结果图上。人体姿态估计被广泛应用于动作识别[1]、体育健身[2]等重要领域,在深度学习的发展和推动下不断丰富和完善。
传统的姿态估计方法依赖手工设计的特征[3]和人体模型[4]进行姿态估计。文献[5]提出了一种基于深度神经网络(Deep Neural Network, DNN)的人体姿态估计方法,将姿态估计问题转化为基于DNN的回归问题,整体推导人体姿态,实现高精度姿态估计。文献[6]受文献[7]启发提出了一种基于序列化的网络结构卷积位姿机(Convolutional Pose Machines, CPM),利用CPM学习丰富的隐式空间模型,能够有效预测被遮挡人体的关节点。文献[8]将多内容信息注意力机制整合到卷积神经网络(Convolution Neural Network, CNN)中,得到端到端的人体姿态估计框架,并选用堆叠沙漏网络(Stacked Hourglass Networks, SHN)形成不同分辨率的注意力图,再利用条件随机场(Conditional Random Field, CRF)对注意力图中相邻区域的关联性进行建模,从而提高了关节点定位的准确性[9]。文献[10]提出了一种以残差网络为主网络的PifPaf算法和部位强度场(Part Intensity Field, PIF)的概念来解决低分辨率和拥挤场景下的姿态估计问题。文献[11]提出高分辨率网络(High Resolution Networks, HRNet),并行连接不同分辨率的卷积,以提升高分辨率的表示。文献[12]提出了HigherHRNet网络,该网络在HRNet的基础上引入高效的反卷积模块,并采用了多分辨率训练和热图聚合策略,提升了关节点的预测效率。文献[13]提出了深度卷积生成对抗模型(Deep Convolution Generative Adversarial Network, DCGAN)设计分层对抗网络(Hierarchical Adversarial Network, HAN)和层次感知损失,以提高身体各个部位的位置估计精度。文献[14]提出Lite-HRNet用于轻量化HRNet的网络结构,将ShuffleNet中的高效Shuffle块用于HRNet,提升网络性能并达到轻量和高效的姿态估计效果。文献[15]提出DEKR(Disentangled Keypoint Regression)算法,采用多分支结构,分支与关节点对应,然后利用自适应卷积激活关节点周围的像素,并学习关节点周围像素的特征,基于这些特征回归关节点的位置,实现各个关节点之间的解耦。文献[16]提出动态轻量化网络Dite-HRNet,用动态拆分卷积和自适应上下文建模的方法解决高分辨率网络无法捕获大范围相互作用关节点的问题。文献[17]提出HDFormer(High-Order Directed Transformer)框架,将自注意力、高阶注意力机制和卷积神经网络整合,从而降低模型的参数量。文献[18]提出ED-Pose方法,引入检测解码器来提取全局特征,将姿势估计视为一个关键点盒子检测问题,学习每个关键点的盒子位置和内容,无须后期处理和密集的热图监督。
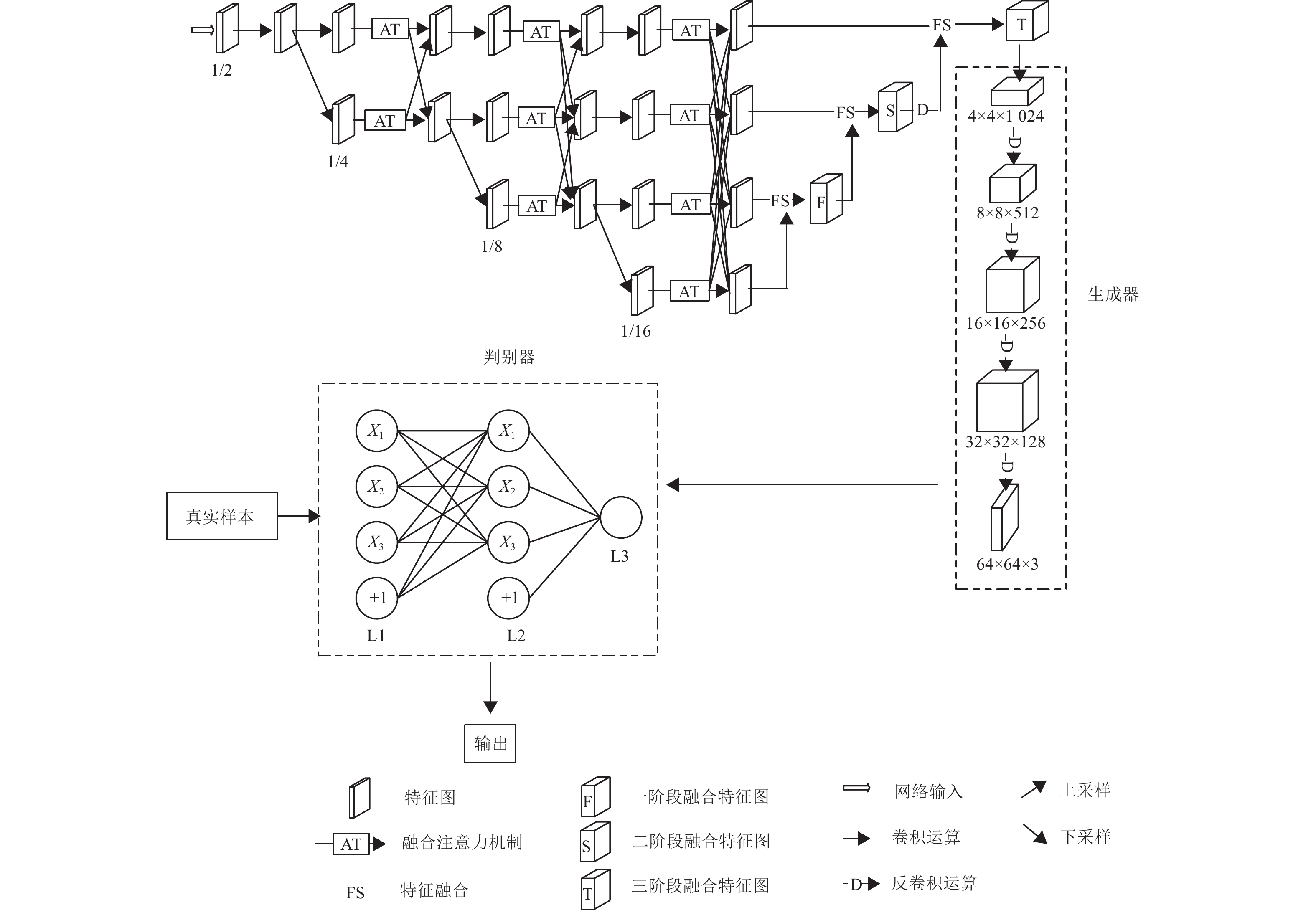
综合上述的研究方法发现:传统的姿态估计方法需要人工干预,算法效率受限于复杂环境因素,在遮挡场景和复杂背景干扰情况下精度偏低,在遮挡和光照不均的情况下,容易漏检或误检人体关节点,相同人体的不同姿态的预测精度也存在差异。本文基于上述复杂运动场景的难点问题提出高分辨特征生成复原网络,该网络由高分辨特征图网络和缺失热图生成复原网络组成,在子网中保留HRNet原有的骨干网络,网络分支连接方式为并行连接,每个分支中的特征图分辨率从高到低依次排列,最后将多个不同尺度的特征图进行融合,重复利用特征图中的特征信息,在特征图后引入注意力机制提取关节点特征信息,网络最后的输出特征图传入复原网络模块进行特征信息的修复和补全,从而实现在复杂运动场景下的遮挡人像姿态估计。
复杂运动场景的姿态估计任务需要克服的困难在于:1)运动员自身关节点遮挡问题,如图1a所示,运动员在运动锻炼过程中的动作比较复杂,自身的手臂关节或腿部关节点存在相互遮挡,以及关节点位置重叠,导致无法正确检测和定位被遮挡关节点;2)运动员之间的相互遮挡问题,如图1b所示,在多人竞技类体育运动和密集遮挡场所中,相互之间会遮挡一个或多个关节点,站位比较密集时的关节点分布也密集,易造成关节点错误连接;3)运动器械设备遮挡问题,如图1c所示,人与物的遮挡情况是关节点的部分缺失,需要根据人体骨架进行预测;4)复杂背景干扰问题,如图1d所示,当运动员的着装和背景颜色无法区分时会导致关节点的定位不准确或关节点缺失。
HRNet网络在复杂遮挡场景下特征提取能力不足,遮挡关键点定位不够精确[19-20],关节点遮挡对其他关节点的预测也产生负面影响[21],从而导致HRNet网络在复杂遮挡场景下表现不佳。针对上述问题,新增融合注意力机制模块、多尺度特征图融合、反卷积和生成对抗模块,网络整体结构如图2所示。其中,HRNet的主干骨架用于生成具有高分辨率图像信息的特征图,便于后续阶段的关节点预测和定位;多尺度特征图融合模块用于处理网络中的冗余信息和图像背景信息,完成大中小型人像和模糊目标人像的姿态估计;反卷积模块用于最大限度地复原特征信息;生成对抗模块的主要作用是在训练阶段增强热图的生成能力,通过学习真实样本的热图信息得到缺失部分的关节点分布,补全和预测缺失的关节点信息,实现对处于复杂遮挡场景的人像关节点的精确预测。
主干骨架采用了并行连接方式,以保证各个阶段和各个分支都有不同分辨率的特征图。引入融合注意力机制,侧重关注特征图的人像区域和各个关节点的预测位置,避免冗余背景信息干扰造成关节点热图缺失。以多阶段融合的方式融合不同分辨率信息的特征图,得到信息完善的输出图像。高分辨特征生成复原网络的输出包含各类检测目标的图像信息和关节点位置信息,各个分支并行连接保证网络分支中存在各个分辨率的特征图,各个分支交互融合图像信息避免了背景干扰带来的错误预测结果。
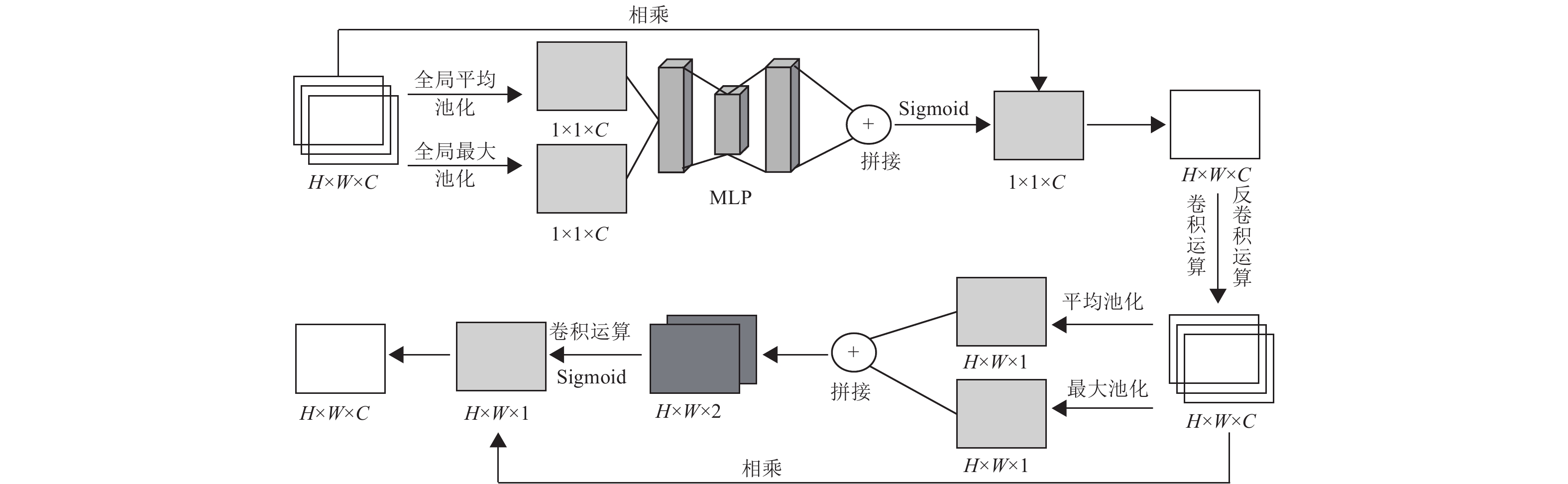
融合注意力机制结合了通道注意力和空间注意力机制的优点,可以滤除图像背景信息的干扰,得到高准确率的关节点定位信息,融合方式如图3所示。
具体实现方式为:尺寸为
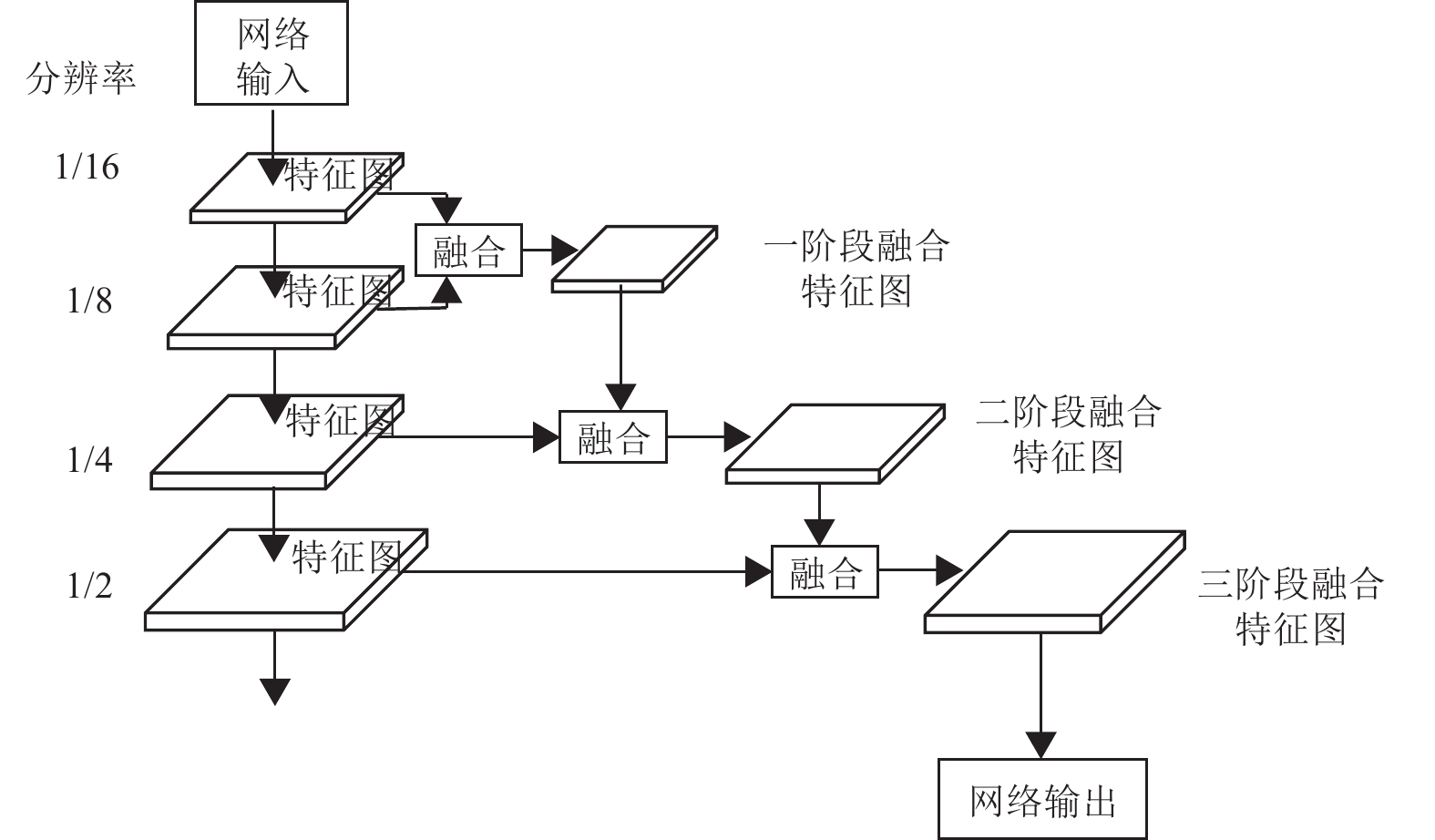
经过融合注意力机制处理的特征图分辨率信息不一,各个分支的特征图中包含许多图像特征信息,需要进行整合后才能用于关节点定位与预测。因此,本文采用多尺度融合的方式得到最后阶段的特征图,用于关节点检测和定位。具体实现流程如图4所示。
底层1/16分辨率的特征图,与1/8分辨率分支的特征图进行融合,得到一阶段的融合特征图;然后一阶段的融合特征图与1/4分辨率分支的特征图进行融合,得到二阶段融合特征图。二阶段的特征图信息可用于大型和中型目标人像的姿态估计,该阶段分辨率不高,包含的冗余信息较少,在网络训练时可以减少资源消耗;最后,二阶段特征图与1/2分辨率分支的特征图进行融合,得到三阶段融合特征图,该阶段特征图包含所有分辨率的信息,能够纠正前序预测中的错误信息,可用于小型目标和模糊目标的关节点检测与定位。网络整体的多尺度特征图融合能够充分利用图像信息,对于解决遮挡情况和复杂场景中的人体姿态估计起到推进作用。
本文根据生成对抗网络的思想,在基础网络上添加生成对抗模块,并在生成对抗模块中的生成器部分进行改进,添加反卷积运算来恢复特征图。改进后的生成对抗模块能够提升网络在热图缺失情况下的预测能力,根据数据集的关节点分布规律,学习人体关节点的热图分布。
生成对抗网络的目标函数为:
|
minGmaxDV(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pnoise(z)[log(1−D(G(z)))] |
(1) |
式中,G表示生成器;D表示判别器;
固定生成器G的参数,优化判别器D。即最大化maxV(D, G),等价于min[−V(D, G)],故判别器D的损失函数等价于:
|
J(D)(θD,θG)=−Ex∼pdata(x)[logD(x)]−E˜x∼pg[log(1−D(˜x))] |
(2) |
固定判别器D参数时,生成器G的损失函数为:
|
J(G)=maxDV(G,D)=Ex∼pdata(x)[logD∗G(x)]+Ez∼pnoise(z)[log(1−D∗G(G(z)))]=Ex∼pdata(x)[logD∗G(x)]+E˜x∼pg[log(1−D∗G(x))]=Ex∼pdata(x)[logpdata(x)pdata(x)+pg(x)]+Ex∼pg[logpg(x)pdata(x)+pg(x)] |
(3) |
当
|
J(G|D∗)=Ex∼pdata(x)[log12]+Ex∼pg[log12]=log12+log12=−log4 |
(4) |
引入JS散度,生成器的损失函数等价为:
|
J(G)=Ex∼pdata(x)[logpdata(x)(pdata(x)+pg(x))/2]+Ex∼pg[logpg(x)(pdata(x)+pg(x))/2]−log(4)=KL(pdata||pdata+pg2)+KL(pg||pdata+pg2)−log4=−log4+2JSD(pdata||pg) |
(5) |
由于JS散度具有非负性,所以当生成器样本与数据集样本分布相同时,散度为0。D(x)的训练效果与G(z)的优化效果越好,生成器样本分布与真实样本分布越接近,损失就越小,判别器判别结果为真,否则判别为假。
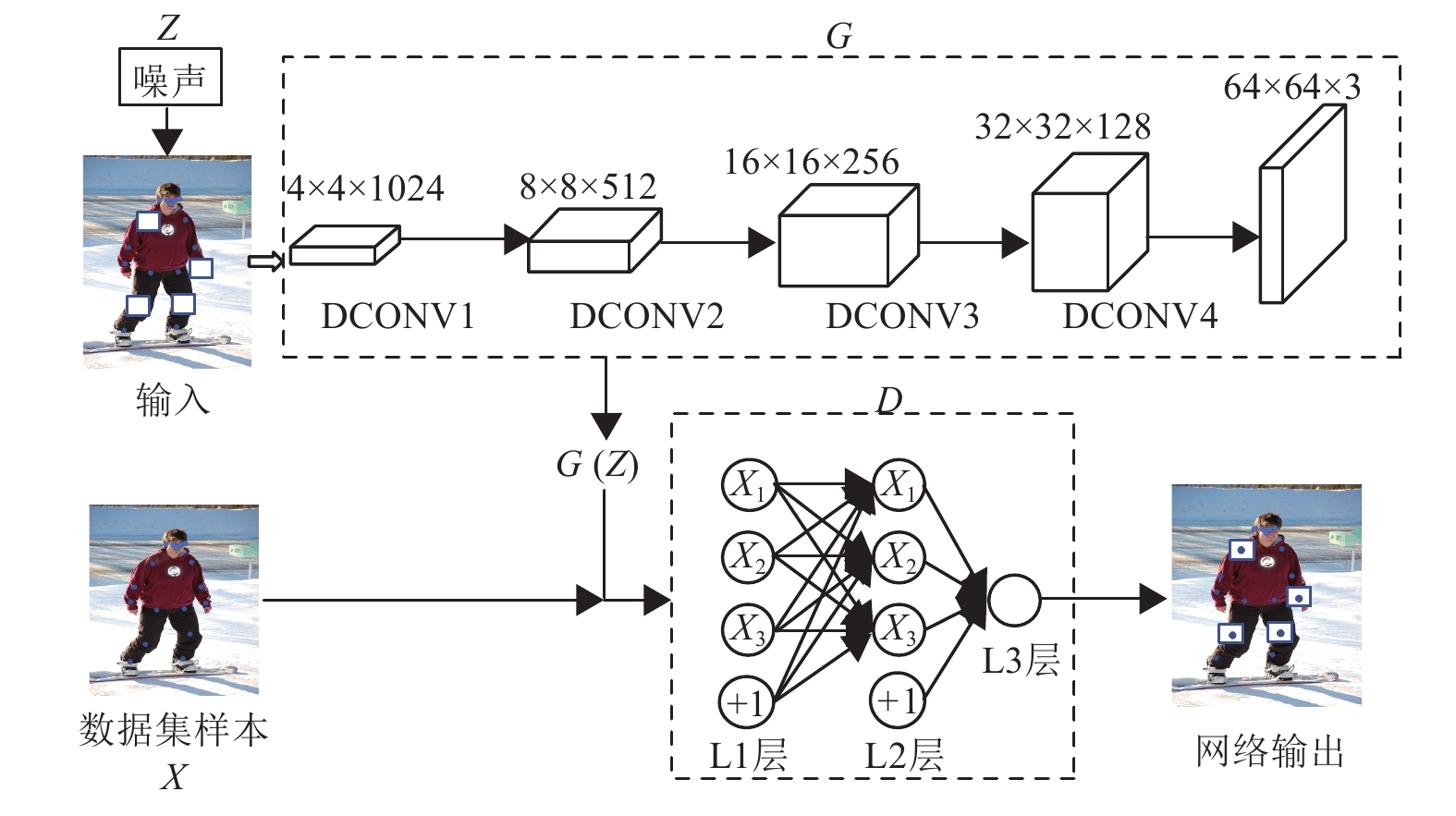
生成对抗模块的具体结构如图5所示。在训练阶段,将白色掩膜噪声添加到输入图像形成遮挡来模拟关节点热图缺失。将处理后的图像传入生成器,生成器中包含4个反卷积块DCONV,反卷积块用于最大限度还原高分辨率图像,4
图5中以单幅图像为例,随机遮挡了人像的右肩、左腕、左膝和右膝4个关节点,特征图由4
MSCOCO数据集[22]在人体姿态估计任务中标注出的人体关节点共计17个类别。数据集中共有
Crowd Pose数据集[23]多用于解决拥挤场景的多人姿态估计问题,数据集中的标签人像被标注的关节点共计14个类别。数据集包含
评价指标如下。
1) 关键点相似性[24] (Object Key-point Similarity, OKS),计算真值和预测人体关节点的相似度:
|
OKSp=∑iexp{−d2pi/2S2pσ2i}δ(vpi>0)∑iδ(vpi>0) |
(6) |
式中,p表示多人场景下图像中人物的编号;i表示人体关键点的编号;dpi表示第p个人的第i个标注的关键点与模型预测的关键点结果之间的欧几里得距离;Sp表示第p个人的尺度因子,数值为人体检测框面积的平方根;
2) 正确关键点百分比[24] (Percentage of Correct Key-points, PCK),给定边界框内的候选区域包含原始关键点坐标位置,参照结合阈值得到的不同准确率来判断预测关节点的合理性,本文选择阈值r=0.5。
3) 平均精确度(Average Precision, AP)。
|
APt=∑pδ(OKSp>t)∑p1 |
(7) |
式中,t为给定OKS的阈值,本文选取阈值为0.5和0.75;预测准确率由测试集所有图片中人物的
实验使用PyTorch框架进行开发,GPU选用GTX 1080Ti,Epoch设置为200;训练数据集为MSCOCO Dataset和Crowd Pose Dataset,输入图像大小设置为256
在HRNet网络作为主干骨架的基础上设计了消融实验,以验证各个网络模块的性能。针对Crowd Pose数据集,消融实验采用32通道宽度作为骨干网络,分析每个模块的精确度,实验结果见表1。
| 反卷积 | 融合注意力 机制 |
生成对抗模块 | 准确率/% |
| √ | 88.2 | ||
| √ | 88.4 | ||
| √ | 88.4 | ||
| √ | √ | 88.5 | |
| √ | √ | 89.1 | |
| √ | √ | 89.6 | |
| √ | √ | √ | 90.3 |
 DownLoad:
CSV
DownLoad:
CSV
所有模块都添加到骨干网络之后,反卷积模块前后的网络输出可以得到大中小型目标人像的有效信息,低分辨率的图像可用于预测大中小型目标人像,避免信息冗余,高分辨图像则用于小型目标和模糊目标的预测;融合注意力机制则能够对人像的关节点有所侧重,为遮挡图像的预测和缺失关节点的补全提供有效信息;生成对抗模块对于前序网络中的输出信息进行提取,缺失部分图像根据训练过程的学习来补全缺失部分的关节点做出高效正确的预测,测试图像准确率能达到90.3%。
为了验证本文网络的有效性,本文首先在MSCOCO train训练集上对高分辨特征生成复原网络进行训练,然后分别在MSCOCO val验证集和MSCOCO test-dev测试集上对改进网络与基线网络的性能进行测试。表2为本文网络与基线网络在MSCOCO val验证集上的性能比较结果,表3为本文网络与基线网络在MSCOCO test-dev测试集上的性能比较结果。其中,参数量表示网络模型的大小,GFLOPs用于衡量网络的计算复杂度。
| 网络模型 | #Params/M | GFLOPs | 输入尺寸 | AP | AP50 | AP75 | APM | APL |
| HRNet-W32 | 28.5 | 7.1 | 256×192 | 65.9 | 86.4 | 70.6 | 66.5 | 57.9 |
| HRNet-W48 | 63.6 | 14.6 | 256×192 | 66.8 | 86.7 | 71.1 | 66.7 | 58.4 |
| Ours(HRNet-W32) | 28.8 | 48.1 | 256×192 | 69.9 | 90.8 | 76.5 | 66.9 | 76.9 |
DownLoad:
CSV
| 网络模型 | #Params/M | GFLOPs | 输入尺寸 | AP | AP50 | AP75 | APM | APL |
| HRNet-W32 | 28.5 | 7.1 | 256×192 | 64.8 | 87.2 | 71.5 | 65.5 | 56.8 |
| HRNet-W48 | 63.6 | 14.6 | 256×192 | 66.2 | 87.8 | 72.4 | 66.0 | 57.6 |
| Ours(HRNet-W32) | 28.8 | 48.1 | 256×192 | 69.4 | 91.0 | 77.2 | 65.7 | 76.2 |
DownLoad:
CSV
根据表2、表3中的结果可以看出,本文网络相较于基线网络HRNet-W32和通道数更多的HRNet-W48,在模型参数量方面与HRNet-W32相近,小于HRNet-W48,虽然计算量GFLOPs略大于基线网络HRNet-W32和HRNet-W48,但在表2验证集上的AP、AP50、AP75、APM、APL均有不同程度的提升。同时在表3中可以看出,在测试集上AP、AP50、AP75、APL上均有提升,在APM指标上与HRNet-W48的最佳结果接近。
为了评估本文网络在复杂场景下的性能表现,本文在Crowd Pose数据集上对网络的性能进行了测试。首先,基于Crowd Pose训练集对卷积神经网络进行训练,然后,针对Crowd Pose测试集中不同场景下的图像进行姿态估计性能测试。Crowd Pose数据集依据密集指数将图像中场景划分为稀疏、拥挤和密集3个水平,并在评估标准中使用APE、APM和APH来分别对各场景下的平均精确度进行表示。本文网络与基线网络在Crowd Pose测试集上的性能比较结果如表4所示。
根据表4结果可以看出,本文网络相较于基线网络HRNet-W32和通道数更多的HRNet-W48,在模型参数量方面与HRNet-W32相近,小于HRNet-W48,虽然计算量GFLOPs略大于基线网络HRNet-W32和HRNet-W48,但是在AP、AP50、AP75、APM、APH上均有提升,在APE指标上与HRNet-W48的最佳结果接近。通过表2、表3和表4实验结果可知,高分辨特征复原网络提高了对于关节点的估计精确度,在一定程度上可以有效克服复杂场景的干扰。
为了验证本文网络的先进性,分别在MSCOCO val验证集和MSCOCO test-dev测试集上对本文网络与主流网络的性能进行测试,在MSCOCO val验证集和MSCOCO test-dev测试集上的性能比较结果分别如表5、表6所示。
| 网络模型 | #Params/M | GFLOPs | 输入尺寸 | AP | AP50 | AP75 | APE | APM | APH |
| HRNet-W32 | 28.5 | 7.1 | 256×192 | 65.2 | 85.7 | 70.2 | 72.9 | 67.3 | 58.8 |
| HRNet-W48 | 63.6 | 14.6 | 256×192 | 65.7 | 86.1 | 71.0 | 73.7 | 68.0 | 59.3 |
| Ours(HRNet-W32) | 28.8 | 48.1 | 256×192 | 65.9 | 86.5 | 71.3 | 73.5 | 68.8 | 59.5 |
DownLoad:
CSV
| 网络模型 | 输入尺寸 | AP | AP50 | AP75 | APM | APL |
| HigherHRNet-W48 | 256×192 | 69.7 | 87.1 | 76.0 | 65.3 | 77.0 |
| DEKR-W32 | 256×192 | 65.7 | 85.7 | 70.4 | 66.4 | 57.5 |
| LiteHRNet-18 | 256×192 | 67.4 | 89.6 | 75.6 | 63.9 | 74.0 |
| LiteHRNet-30 | 256×192 | 69.7 | 90.7 | 77.5 | 66.6 | 75.0 |
| DiteHRNet-18 | 256×192 | 67.4 | 87.2 | 73.0 | 63.8 | 74.2 |
| DiteHRNet-30 | 256×192 | 69.0 | 88.0 | 76.0 | 65.5 | 75.5 |
| Ours(HRNet-W32) | 256×192 | 69.9 | 90.8 | 77.3 | 66.9 | 76.9 |
DownLoad:
CSV
| 网络模型 | 输入尺寸 | AP | AP50 | AP75 | APM | APL |
| HigherHRNet-W48 | 256×192 | 68.8 | 87.9 | 76.3 | 62.5 | 76.1 |
| DEKR-W32 | 256×192 | 65.0 | 86.4 | 70.6 | 65.5 | 57.0 |
| LiteHRNet-18 | 256×192 | 66.5 | 89.9 | 74.4 | 62.7 | 73.1 |
| LiteHRNet-30 | 256×192 | 67.6 | 88.7 | 76.9 | 64.8 | 74.4 |
| DiteHRNet-18 | 256×192 | 67.1 | 88.0 | 73.5 | 61.9 | 73.5 |
| DiteHRNet-30 | 256×192 | 68.3 | 89.4 | 77.4 | 64.9 | 75.2 |
| Ours(HRNet-W32) | 256×192 | 69.4 | 91.0 | 77.2 | 65.7 | 76.2 |
DownLoad:
CSV
根据表5的结果可以看出本文网络相较于HigherHRNet-W48、DEKR-W32、LiteHRNet-18、LiteHRNet-30、DiteHRNet-18、DiteHRNet-30,在AP、AP50、APM上均有一定提升,在AP75、APL两项指标上与其他网络的最佳结果十分接近。根据表6结果可以看出本文网络在MSCOCO test-dev测试集上相较于HigherHRNet-W48、DEKR-W32、LiteHRNet-18、LiteHRNet-30、DiteHRNet-18、DiteHRNet-30在AP、AP50、APM、APL上均有一定提升,在AP75指标上与其他网络的最佳结果十分接近。大型目标人像的关节点图像占比大,遮挡后导致图像整体信息丢失严重,不利于关节点的预测和估计,会影响AP75和APL两项指标的变化;中小型目标人像的图像占比小,受遮挡处理影响之后的信息丢失较少,影响AP、AP50、APM这3项指标的数值变化。而本文添加的注意力机制和生成对抗模块能够赋予网络预测和生成复原的能力,能够检测到其他网络检测不到的关节点,在遮挡情况下的关节点缺失问题也能依靠生成对抗模块进行复原,在中小型目标人像的姿态估计上体现出优越性。
本文网络与主流网络在Crowd Pose测试集上的性能比较结果如表7所示。
| 网络模型 | 输入尺寸 | AP | AP50 | AP75 | APE | APM | APH |
| HigherHRNet-W48 | 256×192 | 65.6 | 86.4 | 70.6 | 73.3 | 68.1 | 58.9 |
| DEKR-W32 | 256×192 | 65.7 | 85.7 | 70.4 | 73.0 | 66.4 | 57.5 |
| LiteHRNet-18 | 256×192 | 64.4 | 83.0 | 69.8 | 72.8 | 67.2 | 58.5 |
| LiteHRNet-30 | 256×192 | 65.7 | 85.8 | 70.3 | 73.1 | 68.5 | 58.7 |
| DiteHRNet-18 | 256×192 | 64.6 | 84.8 | 69.0 | 71.2 | 67.6 | 55.9 |
| DiteHRNet-30 | 256×192 | 65.8 | 86.0 | 70.5 | 73.2 | 68.7 | 58.8 |
| Ours(HRNet-W32) | 256×192 | 65.9 | 86.5 | 71.3 | 73.5 | 68.8 | 59.5 |
DownLoad:
CSV
根据表7结果可以看出,本文网络在MSCOCO test-dev测试集上相较于HigherHRNet-W48、DEKR-W32、LiteHRNet-18、LiteHRNet-30、DiteHRNet-18、DiteHRNet-30在AP、AP50、AP75、APE、APM、APH上均有一定提升。能够对拥挤场景下的被遮挡人像进行准确姿态估计,对于缺失部分的关节点也能够通过网络训练得出补全的关节点位置,从而得到准确的估计结果,在解决拥挤场景和复杂场景的问题上效果较好。
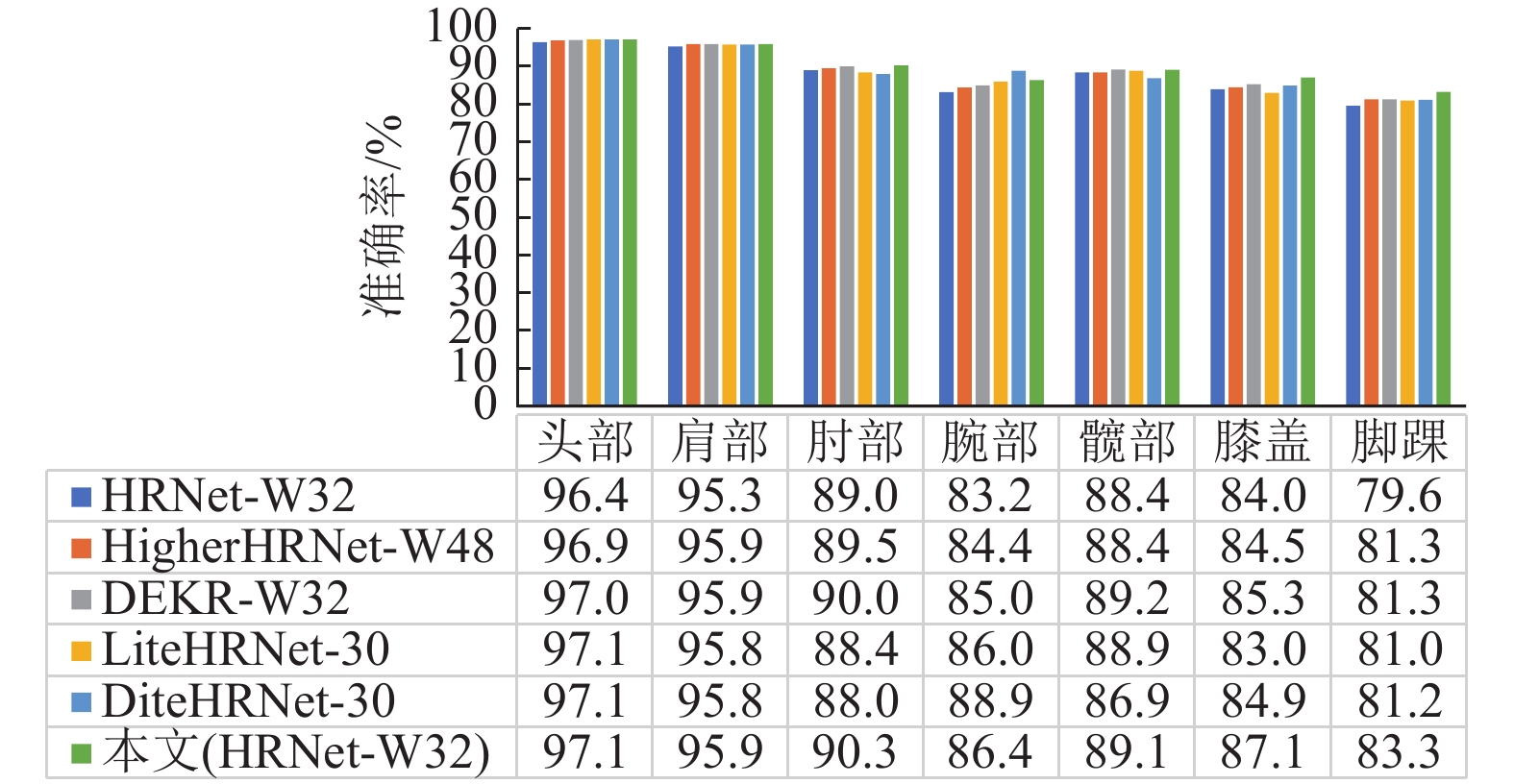
为验证本文网络的预测效果,在MSCOCO数据集中的验证集图像进行关节点检测,各方法的预测精度对比如图6所示。其中,头部表示左眼、右眼、左耳、右耳、鼻5个人体关节点的平均准确率;肩部表示左肩和右肩两个关节点的平均准确率;肘部表示左肘和右肘的平均准确率;腕部表示左腕和右腕的平均准确率;髋部表示左髋和右髋的平均准确率;膝盖表示左膝和右膝的平均准确率;脚踝表示左脚踝和右脚踝的平均准确率。
由图中数据可以看出本文网络在头部、肩部、肘部、膝盖、脚踝关节点的预测准确率均高于HRNet-W32、HigherHRNet-W48、DEKR-W32、LiteHRNet-30、DiteHRNet-30,对于腕部、髋部关节点的预测准确率分别达到86.4%和89.1%。在普通场景下的人体姿态估计任务中,高分辨特征生成复原网络能够有效完成关节点的检测和姿态估计。
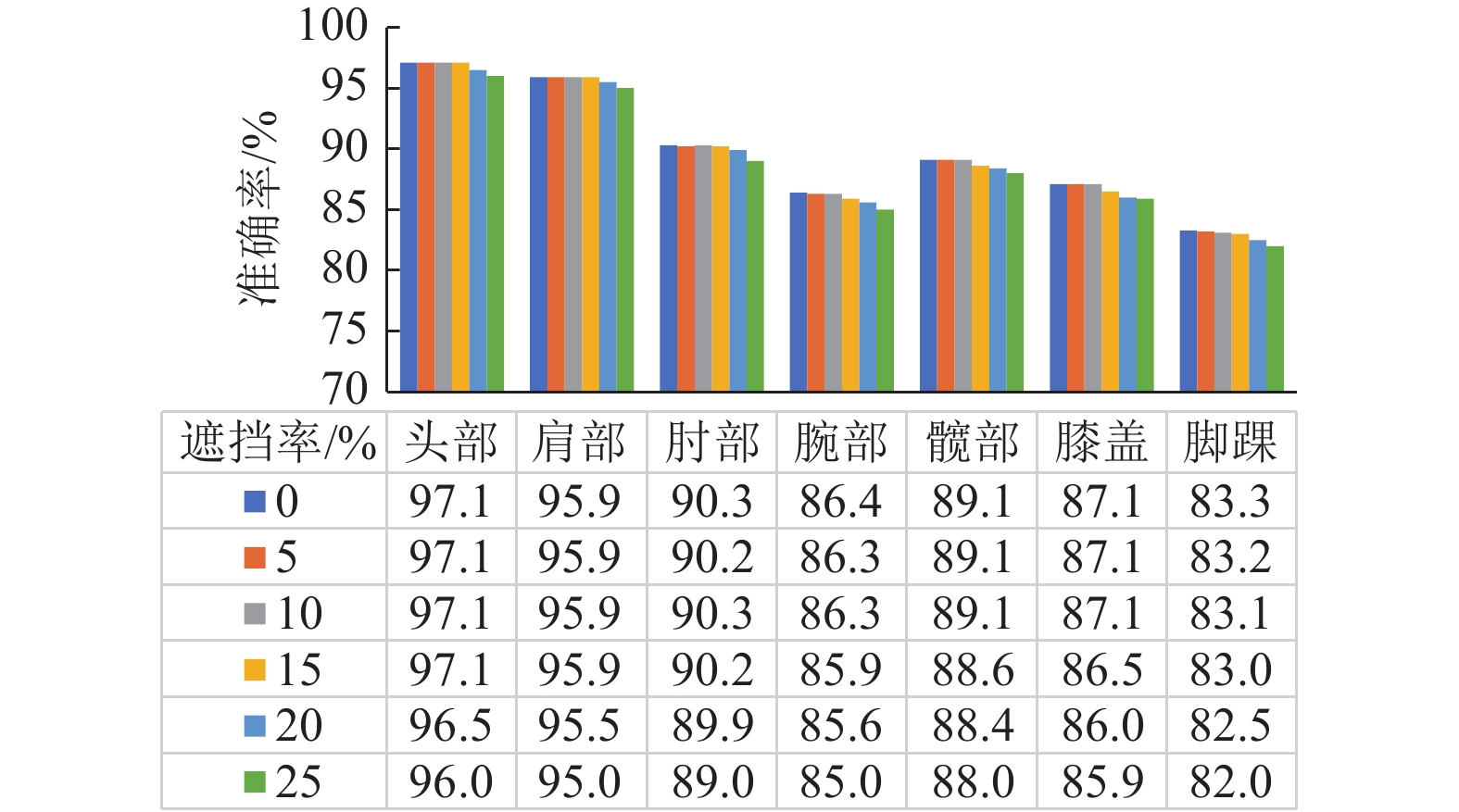
实验选取Crowd Pose数据集中的测试图像进行遮挡,遮挡关节点的数量按比例分别为0、5%、10%、15%、20%、25%进行测试,测试结果如图7所示。在几种遮挡率下头部关节点的检测精度能够保证在96%以上;对于图像面积占比较大的人体关节,如肩部、髋部和膝盖关节点的预测准确率在85.9%以上;在较小面积占比的人体部位如肘部、腕部、脚踝关节点的检测也均高于82%;在不同遮挡率下的走势基本相同,不会出现因遮挡关节数量过多而导致无法检测的情况。这表明本文网络可以稳定地完成各种复杂拥挤场景下的姿态估计任务。
对本文网络在Crowd Pose验证集上的测试结果图做了可视化处理,单人姿态估计结果对比如图8所示。图中第一行为无遮挡情况的单人姿态估计结果,本文网络和DiteHRNet-30能够检测到人像的左膝和右膝两个关节点并进行正确连接,其余网络则漏检了这两个关节点。图中第二行为有遮挡情况的单人姿态估计结果,由于人像侧身站位,遮挡住了左肘关节点,各个网络都能够检测出人像的左腕关节点,本文网络在检测出人像的左腕关节点的同时,还能够基于网络的预测能力预测出左肘关节点,完整连接出人像的左手骨架。
图中第三行为较复杂遮挡情况的单人姿态估计结果,HRNet-W32错误估计了左踝和右踝的位置,在连接时也将左膝和右膝跟后续关节连接错误;其他网络虽能正确估计左踝和右踝的位置,但是左膝的位置预测与实际存在偏差;本文网络能够正确估计左踝、右踝和左膝的位置,在关节点预测和骨架连接的准确性上都优于其他网络。
由图9中的原图预测结果可以看出,当所拍摄图像中的人像大小不一,且目标人像较小和较模糊时,其他网络对于原图中最左边和最右边的小目标人像无法预测完全。而本文网络不仅可以检测和估计原图中左边的两个小目标人像,还可以预测和估计原图中最右边的小目标人像,对于小目标和模糊目标预测表现均优于其他几个网络。
图10是在复杂运动场景下的可视化结果,以Crowd Pose数据集为基准预测人体的14个关节点位置并可视化到输出结果图中。由可视化结果可以看出本文网络能够将处于遮挡情况和复杂背景情况的关节点找出并正确连接出人体姿态骨架。从预测结果看来,本文网络能够处理室内场景和室外场景的人体姿态估计,也能够有效捕捉小型目标人像和模糊人像的特征信息,把握关节点信息并精准定位。
本文以HRNet网络作为基础网络,加入反卷积模块、融合注意力机制和生成对抗模块,将前序的高分辨特征图网络输出作为后序的缺失热图生成复原网络的输入,最终的输出结果作为姿态估计的网络输出,整体的网络为高分辨特征生成复原网络。使用MSCOCO Dataset和Crowd Pose Dataset进行网络训练和测试,所得的实验结果表明:提出的姿态估计方法在普通场景下准确率高,对不同的人体关节点预测精度均有不同程度的提升,对于0~25%程度的关节点遮挡及复杂运动场景模拟情况,具有优越稳定的效果。未来的研究方向是保证准确率的同时,做到网络的轻量化。
| [1] |
胡青松, 张亮, 丁娟, 等. 人体动作数据编码与CNN精确识别[J]. 电子科技大学学报, 2020, 49(3): 473-480. DOI: 10.12178/1001-0548.2019108
HU Q S, ZHANG L, DING J, et al. Data encoding and CNN accurate recognition of human body motion[J]. Journal of University of Electronic Science and Technology of China, 2020, 49(3): 473-480. DOI: 10.12178/1001-0548.2019108
|
| [2] |
ZHANG J H, LI P, JIN C C, et al. A novel adaptive Kalman filtering approach to human motion tracking with magnetic-inertial sensors[J]. IEEE Transactions on Industrial Electronics, 2020, 67(10): 8659-8669. DOI: 10.1109/TIE.2019.2946557
|
| [3] |
BISSACCO A, YANG M H, SOATTO S. Fast human pose estimation using appearance and motion via multi-dimensional boosting regression[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2007: 1-8.
|
| [4] |
FISCHLER M A, ELSCHLAGER R A. The representation and matching of pictorial structures[J]. IEEE Transactions on Computers, 1973, C-22(1): 67-92. DOI: 10.1109/T-C.1973.223602
|
| [5] |
TOSHEV A, SZEGEDY C. DeepPose: Human pose estimation via deep neural networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2014: 1653-1660.
|
| [6] |
WEI S H, RAMAKRISHNA V, KANADE T, et al. Convolutional pose machines[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2016: 4724-4732.
|
| [7] |
RAMAKRISHNA V, MUNOZ D, HEBERT M, et al. Pose machines: Articulated pose estimation via inference machines[M]//Lecture Notes in Computer Science. Cham: Springer International Publishing, 2014: 33-47.
|
| [8] |
NEWELL A, YANG K Y, DENG J. Stacked hourglass networks for human pose estimation[M]. Cham: Springer International Publishing, 2016: 483-499.
|
| [9] |
CHU X, YANG W, OUYANG W, et al. Multi-context attention for human pose estimation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2017: 5669-5678.
|
| [10] |
KREISS S, BERTONI L, ALAHI A. PifPaf: Composite fields for human pose estimation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2019: 11977-11986.
|
| [11] |
SUN K, XIAO B, LIU D, et al. Deep high-resolution representation learning for human pose estimation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2019: 5693-5703.
|
| [12] |
CHENG B W, XIAO B, WANG J D, et al. Bottom up higher resolution networks for multi-person pose estimation[EB/OL]. [2023-03-27]. https://doi.org/10.48550/arXiv.1908.10357.
|
| [13] |
吴春梅, 胡军浩, 尹江华. 利用改进生成对抗网络进行人体姿态识别[J]. 计算机工程与应用, 2020, 56(8): 96-103. DOI: 10.3778/j.issn.1002-8331.1910-0386
WU C M, HU J H, YIN J H. Using improved generative adversarial network for human pose estimation[J]. Computer Engineering and Applications, 2020, 56(8): 96-103. DOI: 10.3778/j.issn.1002-8331.1910-0386
|
| [14] |
YU C Q, XIAO B, GAO C X, et al. Lite-HRNet: A lightweight high-resoultion network[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 10435-10445.
|
| [15] |
GENG Z G, SUN K, XIAO B, et al. Bottom-up human pose estimation via disentangled keypoint regression[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2021: 14671-14681.
|
| [16] |
LI Q, ZHANG Z Y, XIAO F, et al. Dite-HRNet: Dynamic lightweight high-resolution network[EB/OL]. [2023-03-27]. https://doi.org/10.48550/arXiv.2204.10762.
|
| [17] |
CHEN H Y, HE J Y, XIANG W M, et al. HDFormer: High-order directed transformer for 3D human pose estimation[EB/OL]. [2023-03-27]. https://doi.org/10.48550/arXiv.2302.01825.
|
| [18] |
YANG J, ZENG A L LIU S L, et al. Explicit box detection unifies end-to-end multi-person pose estimation [EB/OL]. [2023-03-27]. https://doi.org/10.48550/arXiv.2302.01593.
|
| [19] |
毋宁. 基于改进高分辨率网络的人体姿态估计算法研究[D]. 西安: 西安工业大学, 2023.
WU N. Research on human posture estimation algorithm based on improved high resolution network[D]. Xi’an: Xi’an Technological University, 2023.
|
| [20] |
宾言锐. 基于深度学习的人体姿态估计方法[D]. 武汉: 华中科技大学, 2020.
BIN Y R. Human pose estimation method based on deep learning[D]. Wuhan: Huazhong University of Science and Technology, 2020.
|
| [21] |
褚真, 米庆, 马伟, 等. 部位级遮挡感知的人体姿态估计[J]. 计算机研究与发展, 2022, 59(12): 2760-2769. DOI: 10.7544/issn1000-1239.20210723
CHU Z, MI Q, MA W, et al. Part-level occlusion-aware human pose estimation[J]. Journal of Computer Research and Development, 2022, 59(12): 2760-2769. DOI: 10.7544/issn1000-1239.20210723
|
| [22] |
LIN T Y, MICHAEL M, et al. Microsoft coco common objects in context[DB/OL]. [2023-03-27]. https://d-oi.org/10.48550/arXiv.1405.0312.
|
| [23] |
LI J F, WANG C, ZHU H, et al. Crowd pose: Efficient crowded scenes pose estimation and a new benchmark[EB/OL]. [2023-03-27]. https://doi.org/10.48550/arXiv.1812.00324.
|
| [24] |
YANG Y, RAMANAN D. Articulated pose estimation with flexible mixtures-of-parts[C]//Proceedings of the CVPR 2011. New York: IEEE, 2011: 1385-1392.
|
Figures(10) / Tables(7)
| 反卷积 | 融合注意力 机制 |
生成对抗模块 | 准确率/% |
| √ | 88.2 | ||
| √ | 88.4 | ||
| √ | 88.4 | ||
| √ | √ | 88.5 | |
| √ | √ | 89.1 | |
| √ | √ | 89.6 | |
| √ | √ | √ | 90.3 |
DownLoad:
CSV
| 网络模型 | #Params/M | GFLOPs | 输入尺寸 | AP | AP50 | AP75 | APM | APL |
| HRNet-W32 | 28.5 | 7.1 | 256×192 | 65.9 | 86.4 | 70.6 | 66.5 | 57.9 |
| HRNet-W48 | 63.6 | 14.6 | 256×192 | 66.8 | 86.7 | 71.1 | 66.7 | 58.4 |
| Ours(HRNet-W32) | 28.8 | 48.1 | 256×192 | 69.9 | 90.8 | 76.5 | 66.9 | 76.9 |
DownLoad:
CSV
| 网络模型 | #Params/M | GFLOPs | 输入尺寸 | AP | AP50 | AP75 | APM | APL |
| HRNet-W32 | 28.5 | 7.1 | 256×192 | 64.8 | 87.2 | 71.5 | 65.5 | 56.8 |
| HRNet-W48 | 63.6 | 14.6 | 256×192 | 66.2 | 87.8 | 72.4 | 66.0 | 57.6 |
| Ours(HRNet-W32) | 28.8 | 48.1 | 256×192 | 69.4 | 91.0 | 77.2 | 65.7 | 76.2 |
DownLoad:
CSV
| 网络模型 | #Params/M | GFLOPs | 输入尺寸 | AP | AP50 | AP75 | APE | APM | APH |
| HRNet-W32 | 28.5 | 7.1 | 256×192 | 65.2 | 85.7 | 70.2 | 72.9 | 67.3 | 58.8 |
| HRNet-W48 | 63.6 | 14.6 | 256×192 | 65.7 | 86.1 | 71.0 | 73.7 | 68.0 | 59.3 |
| Ours(HRNet-W32) | 28.8 | 48.1 | 256×192 | 65.9 | 86.5 | 71.3 | 73.5 | 68.8 | 59.5 |
DownLoad:
CSV
| 网络模型 | 输入尺寸 | AP | AP50 | AP75 | APM | APL |
| HigherHRNet-W48 | 256×192 | 69.7 | 87.1 | 76.0 | 65.3 | 77.0 |
| DEKR-W32 | 256×192 | 65.7 | 85.7 | 70.4 | 66.4 | 57.5 |
| LiteHRNet-18 | 256×192 | 67.4 | 89.6 | 75.6 | 63.9 | 74.0 |
| LiteHRNet-30 | 256×192 | 69.7 | 90.7 | 77.5 | 66.6 | 75.0 |
| DiteHRNet-18 | 256×192 | 67.4 | 87.2 | 73.0 | 63.8 | 74.2 |
| DiteHRNet-30 | 256×192 | 69.0 | 88.0 | 76.0 | 65.5 | 75.5 |
| Ours(HRNet-W32) | 256×192 | 69.9 | 90.8 | 77.3 | 66.9 | 76.9 |
DownLoad:
CSV
| 网络模型 | 输入尺寸 | AP | AP50 | AP75 | APM | APL |
| HigherHRNet-W48 | 256×192 | 68.8 | 87.9 | 76.3 | 62.5 | 76.1 |
| DEKR-W32 | 256×192 | 65.0 | 86.4 | 70.6 | 65.5 | 57.0 |
| LiteHRNet-18 | 256×192 | 66.5 | 89.9 | 74.4 | 62.7 | 73.1 |
| LiteHRNet-30 | 256×192 | 67.6 | 88.7 | 76.9 | 64.8 | 74.4 |
| DiteHRNet-18 | 256×192 | 67.1 | 88.0 | 73.5 | 61.9 | 73.5 |
| DiteHRNet-30 | 256×192 | 68.3 | 89.4 | 77.4 | 64.9 | 75.2 |
| Ours(HRNet-W32) | 256×192 | 69.4 | 91.0 | 77.2 | 65.7 | 76.2 |
DownLoad:
CSV
| 网络模型 | 输入尺寸 | AP | AP50 | AP75 | APE | APM | APH |
| HigherHRNet-W48 | 256×192 | 65.6 | 86.4 | 70.6 | 73.3 | 68.1 | 58.9 |
| DEKR-W32 | 256×192 | 65.7 | 85.7 | 70.4 | 73.0 | 66.4 | 57.5 |
| LiteHRNet-18 | 256×192 | 64.4 | 83.0 | 69.8 | 72.8 | 67.2 | 58.5 |
| LiteHRNet-30 | 256×192 | 65.7 | 85.8 | 70.3 | 73.1 | 68.5 | 58.7 |
| DiteHRNet-18 | 256×192 | 64.6 | 84.8 | 69.0 | 71.2 | 67.6 | 55.9 |
| DiteHRNet-30 | 256×192 | 65.8 | 86.0 | 70.5 | 73.2 | 68.7 | 58.8 |
| Ours(HRNet-W32) | 256×192 | 65.9 | 86.5 | 71.3 | 73.5 | 68.8 | 59.5 |
DownLoad:
CSV