 ISSN
ISSN 


-
实体关系抽取[1]是自然语言处理中的一项基本任务,主要应用于信息抽取、问答系统、自动文本摘要等,其任务是将实体间的关系形式化地描述为三元组
$ \left\langle E_{1}, R, E_{2}\right\rangle $ 。关系抽取的定义如下,给定一个句子$ S $ ,存在一对标记实体$ E_{1} $ 和$ E_{2} $ ,其目的是抽取出$ E_{1} $ 和$ E_{2} $ 之间的关系$ R $ 。如在句子“马云创办了阿里巴巴”中,包含了实体“马云”和“阿里巴巴”,以及之间的关系“创办”。实体关系抽取的目的是识别句子中标注的实体,并对关系进行抽取。在实体关系抽取的发展过程中,学者们提出了各种关系抽取方法。早期的抽取方法主要是基于规则的方法[2]和基于词典驱动的方法[3]。基于规则的抽取方法对跨领域的可移植性较差,人力物力消耗大。基于词典驱动的抽取方法灵活性不高,难以解决以动词为关系词之外的识别抽取,同时在关系抽取的过程中存在特征依赖和关系重叠的问题,对抽取的性能产生很大影响。基于传统机器学习的抽取方法[4]优于早期的关系抽取方法,在提高抽取结果准确率和召回率方面有所改善,但存在实体关系重叠的问题。随着深度学习[5]和远程监督方法[6]的发展,上述方法中存在的问题得到了较好的解决。然而,远程监督方法在处理数据时会引入大量的噪声数据。深度学习虽然减少了专家提取特征的数量,但仍然需要依赖词汇资源来获取高级特征。因此,实体关系抽取的主要问题集中在噪声数据和特征提取两个方面。
随着强化学习[7]在自然语言处理领域的应用,强化学习为解决实体关系抽取问题提供了新的研究思路,同时对于任务中远程监督的噪声问题提供了一种十分有效的解决方法。
因此,本文提出了一种新的融合强化学习的实体关系联合抽取模型。该模型包括两部分:联合网络模型和强化学习(Reinforcement Learning, RL)代理。本文的联合网络模型用于抽取实体及实体之间的关系,强化学习代理通过与联合网络模型进行交互,识别并过滤掉带有噪声的句子,从而提高联合网络模型抽取的性能。
-
流水线方法和联合抽取方法是目前广泛使用在实体关系联合抽取中的两种方法。
-
流水线方法首先提取文本中的标记跨度以检测实体对,然后预测它们之间的关系类型。许多传统的命名实体识别模型(Name Entity Recognition, NER)都是线性序列模型[8],如隐马尔可夫模型(Hidden Markov Model, HMM)[9]、条件随机场(Conditional Random Fields, CRF)[10]和最大熵马尔可夫模型(Maximum Entropy Markov Model, MEMM)[11]。这些模型在很大程度上依赖适当的特征,并且这些特征需要大量的手动特征工程或外部资源。
随着深度学习方法的出现,利用神经网络构造特征提取出适当的语义特征,不再依赖专家手工提取特征。在关系抽取任务中,基于神经网络的方法明显优于传统的NER模型。文献[12]首先提出一种基于循环神经网络(Recurrent Neural Network, RNN)的简单框架,该模型可以给关系分类提供更好的性能,尤其是能够学习长距离的关系模式。文献[13]利用卷积神经网络(Convolutional Neural Network, CNN)来提取词级和句子级的特征,将所有单词标记为输入,无需复杂的预处理。随后文献[14]改进了CNN网络,提出了一种新的分段卷积神经网络模型(Piecewise Convolutional Neural Network, PCNN),模型具有多实例学习,用以解决错误标签问题和特征提取过程中的噪声数据问题。然而卷积神经网络受限于卷积核的大小,在序列特征的学习上有一定局限性。文献[15]提出了基于注意力的双向长短期记忆网络来捕获句子中最重要的语义信息,用于解决重要信息可能出现在句子中任何位置的情况。文献[16]为了缓解错误标签导致关系抽取性能的降低,提出了一种基于句子级注意力的关系提取模型。
-
针对流水线方法中存在的问题,实体关系联合抽取方法被提出,该方法可以同时识别实体并确定它们之间的关系。联合抽取方法[17]体现了实体和关系的联系,其性能优于大多数流水线方法。大多数传统的联合抽取方法基于特征,需要依赖大量的特征工程。
近年来,学者们使用联合抽取方法改善流水线方法中存在的错误累积传播以及实体关系重叠等问题。文献[18]提出了一种新的端到端神经模型来提取实体之间的关系,该模型共享实体提取和关系分类的参数。文献[19]设计了一种混合神经网络模型提取实体及其关系,其中包含用于实体提取的新型双向编码器−解码器的长短期记忆网络(Long Short-Term Memory, LSTM)模块Bi-LSTM-ED和用于关系分类的CNN模块。文献[20]提出了一种联合神经网络模型,将实体识别任务和关系提取任务建模为多头选择问题。
-
一般情况下,神经网络模型的训练需要大量的标注数据。虽然远程监督可以产生大量的标注数据,但训练数据中会掺杂大量的噪声数据。强化学习是一种学习和决策计算方法,它具有试错搜索和延迟奖励两个特点,可以有效地处理噪声数据问题。随着强化学习在自然语言领域的发展,许多学者将强化学习应用于大规模的实体关系抽取中。
文献[21]使用强化学习代理去除训练集中的噪声数据,并使用句子可能性作为奖励来指导训练,奖励来自于不同联合神经网络的性能变化。文献[22]使用强化学习策略生成假阳性指标,自动识别每种关系类型的假阳性,无须任何监督信息,侧重于增强联合模型的鲁棒性。文献[23]将联合抽取建模为两步决策过程,通过设计每步奖励函数获得反馈,并采用Q-Learning算法作为模型的策略网络来控制联合抽取模型的决策过程。文献[24]采用分层强化学习框架来增强实体提取和关系类型之间的交互,整个提取过程被分解为两级RL策略的层次结构,分别用于关系检测和实体提取。文献[25]提出了一种具有生成参数的新型图神经网络,使用图神经网络处理多跳关系推理,提高了关系推理的准确性。文献[26]提出了一种用于关系提取的新型图神经网络模型,考虑两个实体之间的相互作用,提高了关系抽取的准确率。
在这些研究基础上,本文将强化学习应用到联合抽取模型中,提高联合抽取模型的性能。
-
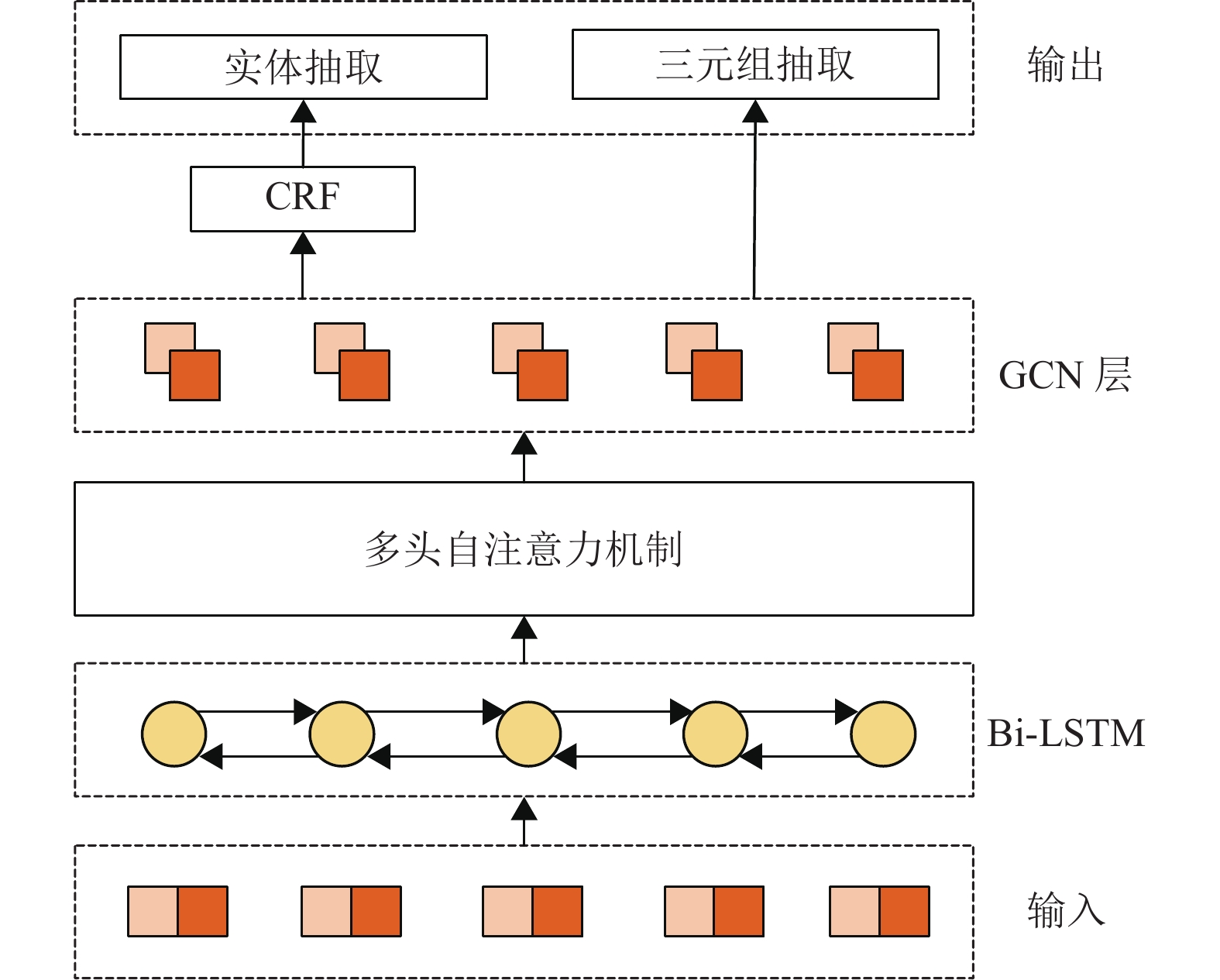
针对噪声数据问题,本文提出了一种融合强化学习的实体关系联合抽取模型(GCN-MHATT-RL)。其总体框架如图1所示,该模型由强化学习模型(RL)和联合抽取模型(GCN-MHATT)组成。联合抽取模型由多头自注意力机制和图卷积网络(GCN)构成,它独立于RL模型。联合抽取中的多头自注意力层,用于提高关系抽取的精确率和模型的整体性能。RL模型的功能是从原始数据集中去除带有噪声的句子并构建一个干净的数据集。原始数据集中的每个句子都由代理的策略网络所确定,代理采取行动决定是否应该删除该句子。在训练的过程中,RL代理不断与联合网络进行交互,使RL代理在交互中进行学习和决策,并从数据集中识别出所有句子,过滤带有噪声的句子,将高质量的句子输入到联合抽取模型中,根据联合抽取模型获得的奖励去更新策略网络并启动新的选择过程。两个模块的联合学习可以减少远程监督过程中的噪声数据,有效提高抽取性能。

图 1 融合强化学习的实体关系联合抽取总体模型
-
本文提出的联合抽取模型是一个基于多头自注意力机制和图卷积神经网络(GCN)的联合抽取模型,它独立于RL模型,模型架构如图2所示。

图 2 联合抽取模型
该模型由以下5部分组成。
1)输入层
将句子输入到模型中。
2)编码层
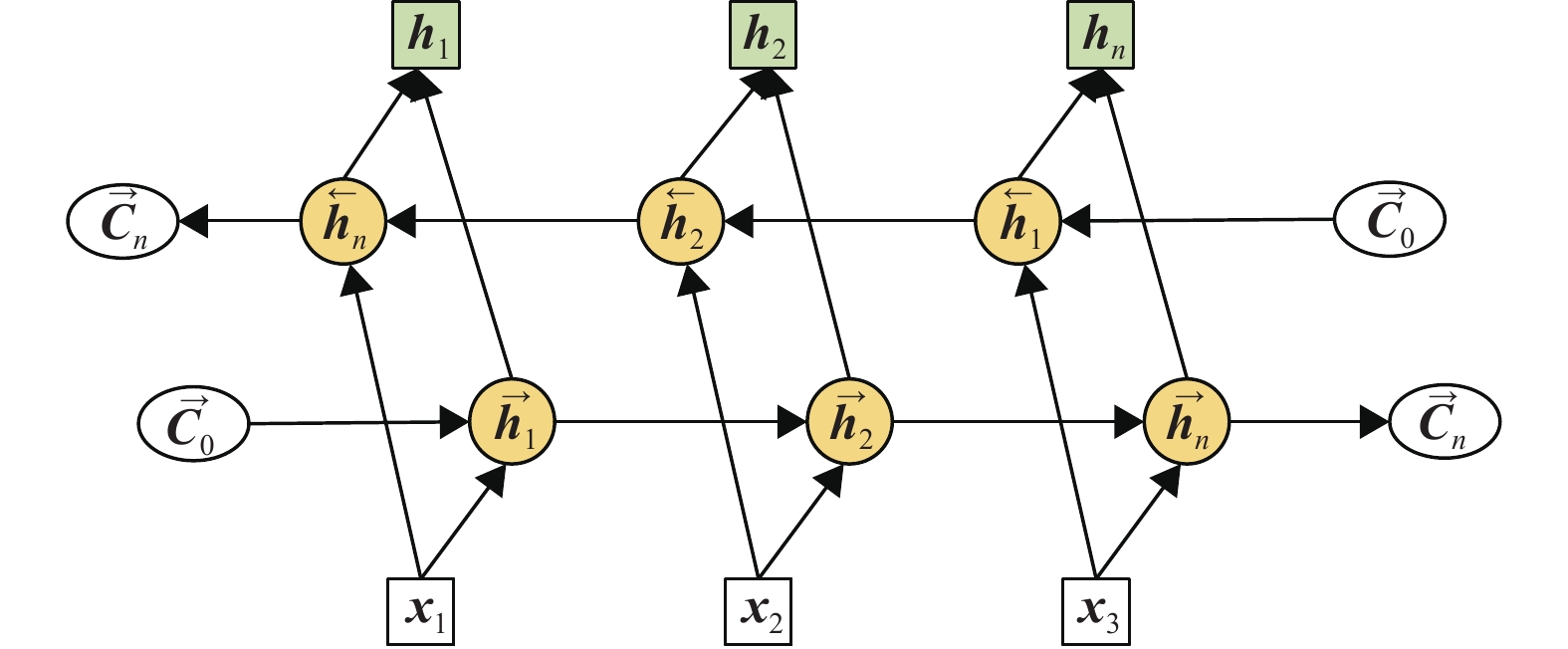
在编码层,模型将输入层输入的句子
$ l_{1},l_{2}, \cdots, l_{n} $ 标记序列映射到词向量,采用预训练单词嵌入和字符嵌入相结合的方法作为初始嵌入。本文使用Bi-LSTM模型捕获远程上下文信息,如图3所示。对该模型从左到右和从右到左进行编码,以获得每个单词的双向信息表示。通过将向量$ {\boldsymbol{x}}_{i} $ 传递给Bi-LSTM来获取上下文表示信息$ {\boldsymbol{h}}_{i} $ 。初始化向量公式为:$$ {\boldsymbol{x}}_{i} = w\oplus c $$ (1) 式中,
$ w $ 表示词嵌入;$ c $ 表示字符嵌入。第
$ i $ 个词的隐藏特征表示为:$$ \overrightarrow{{\boldsymbol{h}}_{l}} = \overrightarrow{\text{LSTM}}(\overrightarrow{{\boldsymbol{h}}}_{l-1}, {\boldsymbol{x}}_{i}) $$ (2) $$ \overleftarrow{{\boldsymbol{h}}}_{l} = \overleftarrow{\text{LSTM}}(\overleftarrow{{\boldsymbol{h}}}_{l-1}, {\boldsymbol{x}}_{i}) $$ (3) $$ {\boldsymbol{h}}_{i} = [\overrightarrow{{\boldsymbol{h}}_{l}} ; \overleftarrow{{\boldsymbol{h}}_{l}}] $$ (4) 式中,
$ \overrightarrow{{\boldsymbol{h}}_{l}} $ 和$ \overleftarrow{{\boldsymbol{h}}_{l}} $ 为LSTM的前向和后向隐藏状态。
图 3 编码层
3)多头自注意力层
Bi-LSTM在计算过程中无法在上下文中显示关键信息的重要性,在处理长序列任务时会丢失命名实体识别任务中的重要信息。为了增强语义的特征提取,本文在联合抽取模型中加入了多头自注意力机制。其中自注意力用于学习句子中任意两个单词之间的依赖关系,并获得句子内部的结构信息。自注意力机制通过映射操作
$ {\boldsymbol{Q}} $ (Query)、$ {\boldsymbol{K}} $ (Key)、$ {\boldsymbol{V}} $ (Value)将嵌入的输入矩阵$ {\boldsymbol{E}} $ 转换为维度均为$ d_{k} $ 的矩阵。自注意机制将一组查询和键值映射到输出,得到$ V $ 的加权求和结果,其中分配给每个$ {\boldsymbol{V}} $ 的权重是通过$ {\boldsymbol{Q}} $ 到对应$ {\boldsymbol{K}} $ 的相似度函数来计算:$$ \text{Attention}({\boldsymbol{Q}}, {\boldsymbol{K}}, {\boldsymbol{V}}) = \text{soft}\left(\frac{{\boldsymbol{Q}} {\boldsymbol{K}}^{{\rm{T}}}}{\sqrt{d_{k}}}\right) {\boldsymbol{V}} $$ (5) 式中,
$ d_{k} $ 表示矩阵$ {\boldsymbol{Q}} $ 、$ {\boldsymbol{K}} $ 、$ {\boldsymbol{V}} $ 的向量维度;$\text{soft}\left(\dfrac{{\boldsymbol{Q}} {\boldsymbol{K}}^{{\rm{T}}}}{\sqrt{d_{k}}}\right) {\boldsymbol{V}}$ 为注意力加权值。多头自注意力模块中,
$ {\boldsymbol{Q}} $ 、$ {\boldsymbol{K}} $ 、$ {\boldsymbol{V}} $ 分别使用$ h $ 个自注意机制进行线性映射,生成不同的权重矩阵,表示词向量在不同子空间中的唯一特征信息。因此拓展了模型对不同位置的关注能力。输入特征通过不同的权重矩阵线性映射到不同的信息空间,并在每个子空间中进行相同的注意力函数计算,充分学习句子的结构和语义,头部计算过程为:$$ \text { head }_{i} = \text{Attention}\left({\boldsymbol{Q}} {\boldsymbol{W}}_{i}^{{\boldsymbol{Q}}}, {\boldsymbol{K}} {\boldsymbol{W}}_{i}^{{\boldsymbol{K}}}, {\boldsymbol{V}} {\boldsymbol{W}}_{i}^{{\boldsymbol{V}}}\right) $$ (6) 式中,
$ {\boldsymbol{W}}_{i}^{{\boldsymbol{Q}}} $ ,$ {\boldsymbol{W}}_{i}^{{\boldsymbol{K}}} $ ,$ {\boldsymbol{W}}_{i}^{{\boldsymbol{V}}} $ 表示线性映射的参数矩阵。多个自注意基本单元堆叠形成多头自注意力编码模块,将
$ h $ 个并行自注意的结果进行合并,然后通过线性映射,得到最终的输出$ {\rm{Att}} $ :$$ \begin{split} &\qquad \text{Att} = \text{MultiHead}({\boldsymbol{Q}}, {\boldsymbol{K}}, {\boldsymbol{V}})=\\ & \text{Concat}\left(\text {head}_{1}, \text {head}_{2}, \cdots, \text{head}_{h}\right) {\boldsymbol{W}}^{o} \end{split}$$ (7) 式中,
$ {\boldsymbol{W}}^{o} $ 表示线性映射的参数矩阵。4)图卷积网络层
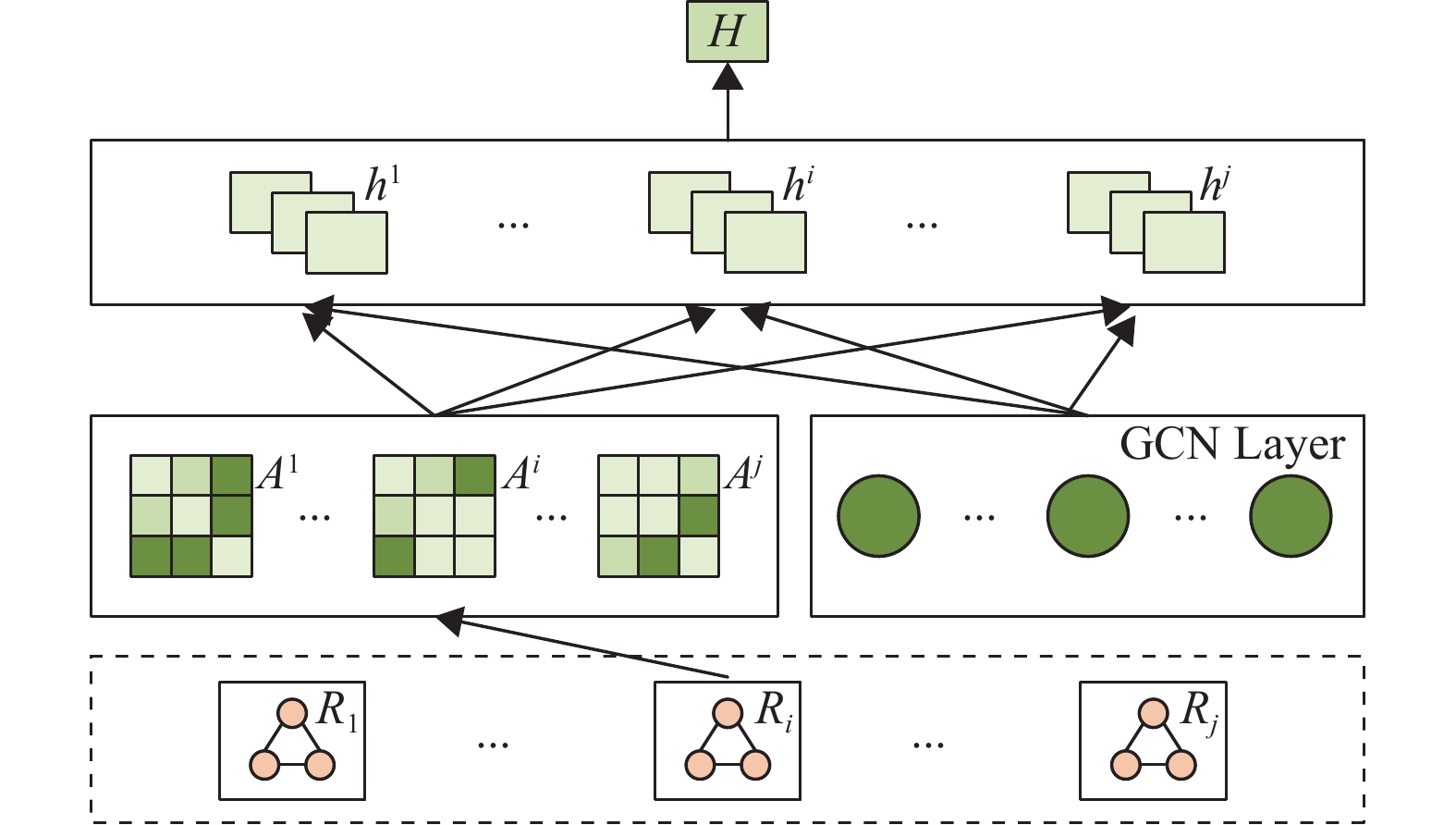
GCN类似于CNN,但GCN适用于图结构数据,其主要功能是获取图上邻接结点的结构信息,而CNN只能用于二维数据结构。图4展示了GCN层中的具体操作,
$ {\boldsymbol{A}}^{i} $ 为多头自注意力层后的关系加权矩阵,矩阵中的颜色越浅,两个结点之间的注意力权重就越大。加权矩阵中节点$ i $ 到$ j $ 之间有不同含义的边$ A_{ij} $ 和$ A_{ji} $ ,$ A_{ij} $ 表示节点$ i $ 到$ j $ 有一条边,$ A_{ji} $ 表示$ j $ 到$ i $ 有一条边。在每个关系下都有一个邻接矩阵,它的形式和原来的$ n\times n $ 矩阵相同。根据每个关系聚合词汇的信息,对于每个关系下的节点,从其出边和入边中提取,并将其进行聚合,其中初始化特征$ h_{0} $ 是编码层的输出。
图 4 图卷积网络层结构
$$ h_{i^{*}}^{\overleftarrow{t+1}} = \text{ReLU}\left(\sum\limits_{j = 1}^{n} A_{i j^{*}} \overleftarrow{W^{t}} h_{j^{*}}^{t}+\overleftarrow{h^{t}}\right) $$ (8) $$ h_{i^{*}}^{\overrightarrow{t+1}} = \text{ReLU}\left(\sum\limits_{j = 1}^{n} A_{i j^{*}} \overrightarrow{W^{t}} h_{j^{*}}^{t}+\overrightarrow{h^{t}}\right) $$ (9) $$ h_{i^{*}}^{t+1} = \left[h_{i^{*}}^{\overleftarrow{t+1}}, h_{i^{*}}^{\overrightarrow{t+1}}\right] $$ (10) 式中,
$ \overleftarrow{W^{t}} $ 、$ \overrightarrow{W^{t}} $ 和$ \overleftarrow{h^{t}} $ 、$ \overrightarrow{h^{t}} $ 分别表示出边和入边的权重;$ A_{i jk} $ 和$ A_{jik} $ 表示在关系$ k $ 下从$ i $ 到$ j $ 的路径和$ j $ 到$ i $ 的路径;$ h_{i^{*}}^{\overleftarrow{t+1}} $ 和$ h_{i^{*}}^{\overrightarrow{t+1}} $ 分别表示输入和输出特征,从而将输入和输出特征连接起来作为最终特征;$ h_{ik}^{t+1} $ 表示$ i $ 在$ t+1 $ 层的关系$ k $ 下的隐藏特征,因此得到$ l $ 关系层下的特征表示结果$ h_{i 1}, h_{i 2}, \cdots, h_{i l} $ 。$ H $ 是每个节点在每个关系下的特征,使用上一层的表示特征和本层的结果来更新词表示作为新一轮的输入:$$ H^{t+1} = \sum\limits_{j \in l} h_{* j}^{t+1}+H^{t} $$ (11) 式中,
$ h_{* j} $ 表示关系j下的所有节点信息;$ H^{t+1} $ 表示第t+1层的最终输出。5)输出层
在实体预测层,使用BIO编码方案和CRF来计算每个词的可能标签,在联合抽取中每个实体可能与其他实体有不同的关系。本文将联合抽取作为多头选择,同时预测每个词的中心词和关系,当给定一个单词时将预测它与其他单词关系下的权重,并计算出单词的概率:
$$ \begin{split} &\qquad\qquad P_{r} = (e_{i}, r_{k}, e_{j})=\\ & \text{softmax} \left(f\left(T H_{i}+W H_{j}+b\right) U\right) \end{split} $$ (12) 式中,
$ e_{i} $ 和$ e_{j} $ 表示实体$ i $ 和$ j $ ;$ r_{k} $ 表示关系$ k $ ;$ f $ 为激活函数tanh;$H_i $ 和$H_j $ 分别表示单词i和j之间的Bi-LSTM编码;$ T $ ,$ W $ ,$ U $ 均表示单词r与其他单词权重分数。 -
本文使用强化学习与联合抽取模型进行多次交互,使强化学习在交互中进行学习和决策,并从数据集中识别出所有句子,过滤掉带有噪声的句子,将高质量的句子输入到联合抽取模型中。
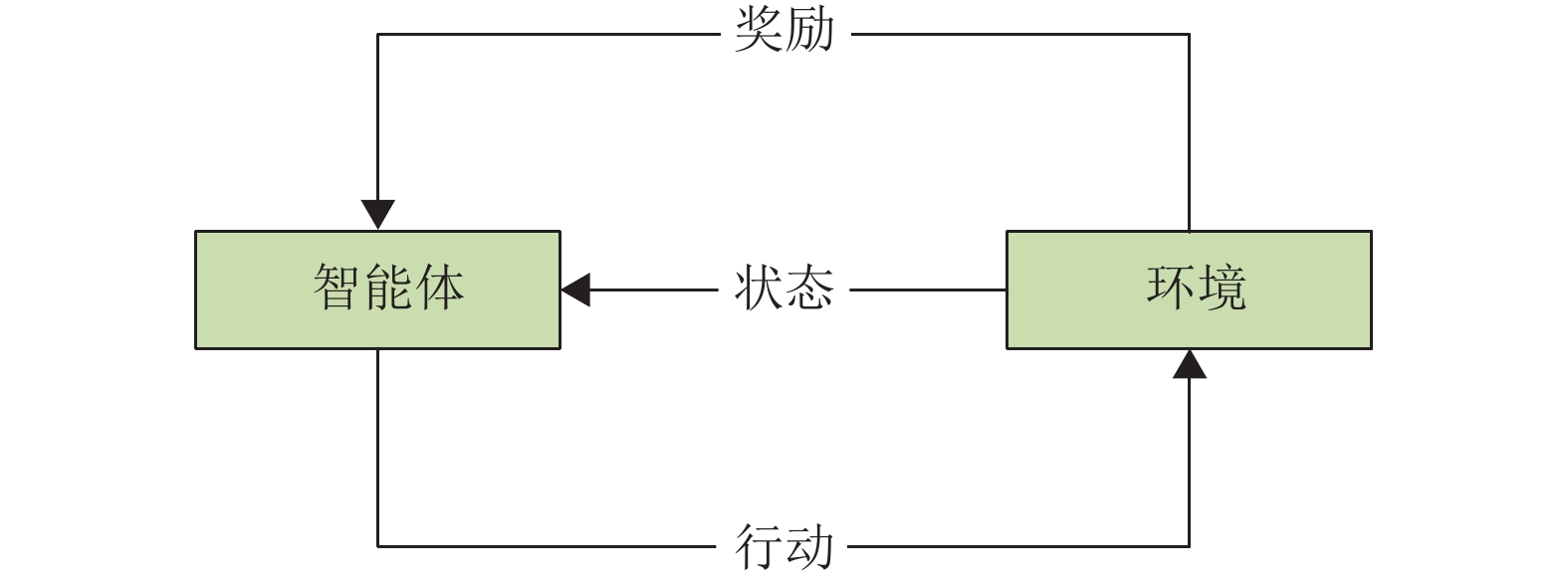
在RL模型中,智能体和环境不断进行交互,智能体基于当前状态进行决策以执行一个行动,然后从联合抽取模型中获得相应的反馈奖励,其中状态由当前句子、所选句子集合组成,而行动则代表是否选择当前句子。因此,只有在完成对所有训练语料的选择后,强化学习才能从联合抽取模型中获得延迟反馈。
RL代理模型如图5所示,主要包括状态、行动、奖励以及迭代优化。

图 5 强化学习模型
1)状态
状态
$ s_{i} $ 表示当前句子和已经选择的句子,本文将状态表示为连续的实值向量$ {\boldsymbol{F}}_{\left ( s_{i} \right ) } $ ,它对以下信息进行编码:①从联合抽取模型中获得的当前句子的向量表示;
②所选句子集的表示,即所有向量表示的平均值。
2)动作
本文定义了一个动作
$ a_{i} \in \left \{ 0,1 \right \} $ 来指示RL代理是否选择当前句子$ i $ ,通过策略$ \pi _{\varTheta } $ 对$ a_{i} $ 进行采样,其中$ \varTheta $ 是要学习的参数。并采用逻辑函数作为策略函数:$$ \pi_{\varTheta}\left(\mathrm{s}_{i}, \mathrm{a}_{i}\right) = {P}_{\theta}\left({s}_{i} \mid {a}_{i}\right) $$ (13) $$ \begin{split} & {P}_{\varTheta}\left({s}_{i} \mid {a}_{i}\right) = a_{i} \sigma (W^{*} F_{\left(s_{i}\right)}+b)+\\ &\quad \left(1-a_{i}\right)(1-\sigma (W^{*} F_{\left(s_{i}\right)}+b)) \end{split} $$ (14) 式中,
$ F_{\left ( S_{i} \right ) } $ 表示状态特征向量;$ \sigma \left ( \cdot \right ) $ 表示参数为$ \varTheta = \left \{ W,b \right \} $ 的sigmoid函数;w和b表示权重变量和偏移矩阵。3)奖励
奖励函数是所选句子的质量指标,通过对集合
$ B = \left\{x_{1}, x_{2}, \cdots, x_{|B|}\right\} $ 中的每个句子进行抽样来确定是否使用该句子。如果模型完成所有的选择,它会获得最终的奖励,因此只需要在终端状态$ S_{\left | B \right | +1} $ 处收到延迟加奖励,其他状态下奖励均为零。奖励定义为:$$ R\left({s}_{i} \mid B\right)\left\{\begin{array}{ll} \dfrac{1}{|\hat{B}|} \displaystyle\sum\nolimits_{x_{j} \in \hat{B}} \log p\left(r \mid x_{j}\right) & i=|B|+1 \\ 0 & i<|B|+1 \end{array}\right.$$ (15) 式中,
$ \hat{B} $ 表示所选句子的集合;$ \hat{B} $ 是$ B $ 的子集;$ r $ 是集合$ B $ 的标签;$ p( r\mid x_{j}) $ 由联合抽取模型计算出来。对于$ \hat{B} = \phi $ 的情况,将奖励设置为训练数据中所有句子的平均似然值,使RL模型能够有效消除噪声数据。在选择的过程中,不仅最后的行动会产生奖励,之前的所有行动也会产生,所以这种奖励是延迟的,可以通过RL模型处理。
4)迭代优化
对于集合
$ B $ ,最后的目标是获得最大化的奖励。因此目标函数定义为:$$ J_{\varTheta} = V_{\varTheta}\left(s_{1} \mid B\right) = E_{s_{1}, a_{1}, s_{2}, \ldots, s_{i}, a_{i}, s_{i+1}, \ldots}\left[\sum\limits_{i = 0}^{|B|+1} r\left(s_{i} \mid B\right)\right] $$ (16) 式中,
$ a\sim \pi _{\varTheta } \left ( s_{i},a_{i} \right ) $ ,$ s_{i+1} \sim P \left ( s_{i+1}\mid s_{i} ,a_{i} \right ) $ ,由于状态$ s_{i+1} $ 完全由状态$ s_{i} $ 和$ a_{i} $ 确定,因此转换函数$ P \left ( s_{i+1}\mid s_{i} ,a_{i} \right )=1 $ ,$ V_{\varTheta } $ 表示价值函数,$ V_{\varTheta}\left(s_{1} \mid B\right) $ 表示从策略$ \pi _{\varTheta _{\left ( s_{i},a_{i} \right ) } } $ 的某一状态$ s_{1} $ 开始可以获得预期反馈奖励。迭代策略可通过下列方法计算:
①对于每个集合
$ B $ ,根据当前策略对每个状态进行采样,得到$ \left\{s_{1}, a_{1}, s_{2}, a_{2}, \cdots, s_{|B|}, a_{|B|}, s_{|B|+1}\right\} $ 和相对应的最终奖励$ r\left(s_{|B|+1} \mid B\right) $ ;②只有一个非零最终奖励,所有状态的值函数都相同,即
$ v_{i} = V\left(s_{i} \mid B\right) = r\left(s_{|B|+1} \mid B\right) $ ,其中$i = 1, 2,\cdots ,\left | B \right |$ 。更新当前策略的迭代规则为:$$ \varTheta \leftarrow \varTheta+\alpha \sum\limits_{i = 1}^{|\hat{B}|} v_{i} \nabla_{\varTheta} \log \pi_{\varTheta}\left(s_{i}, a_{i}\right) $$ (17) -
为了全面评估本文提出的模型性能,本次实验在远程监督开发的纽约时报(New York Times, NYT)语料库上进行,且所有数据集都包含噪声数据。所用数据集的统计数据如表1所示。
表 1 数据集统计
类型 句子 实体对 关系 训练集 522611 281270 18252 测试集 172448 96678 1950 -
为了评价模型的性能,本文采用精确率(Precision)、召回率(Recall)和F1作为评价指标,计算公式分别如下:
$$ \text {Precision} = \frac{{\rm{TP}}}{{\rm{TP}}+{\rm{FP}}} $$ $$ \text {Recall} = \frac{{\rm{TP}}}{{\rm{TP}}+{\rm{FN}}} $$ $$ {\rm{F}}1 = \frac{2 \times \text{Precision} \times \text{Recall}}{\text{Precision}+\text{Recall}} $$ 式中,TP表示模型正确地预测为正例(正确的实体或关系)的数量,即模型正确地将实际存在的实体或关系标识出来的数量;FP表示模型错误地预测为正例的数量,即错误地将不存在的实体或关系标识为存在的情况;FN表示模型错误地预测为负例(未标识的实体或关系)的数量,即模型未能正确地识别出实际存在的实体或关系。
-
在本实验的设置中,将单词嵌入的维度设置为50,位置嵌入的维度为5。为Bi-LSTM设置的隐藏单元数为128,GCN的维度为256。学习率和丢失率分别设置为0.02和0.5,更新率设置为0.01。具体设置如表2所示。
表 2 实验参数
参数 值 词嵌入维度 50 位置嵌入维度 5 Bi-LSTM隐藏单元数 128 GCN维度 256 GCN层数 3 学习率 0.02 丢失率 0.5 更新率 0.01 权重因子 0.01 注意力头的大小 8 -
针对实体关系抽取任务,本文选择了不同的基线方法来进行对比。
1)Bi-LSTM[27]:对分词后的词嵌入进行深层Bi-LSTM网络处理以获取上下文语义信息。然后在时间步维度做最大池化降维获取其句子级别特征,最后结合实体尾部的隐藏层向量进行分类。
2)Bi-LSTM-ATT[28]:将双向长短期记忆(Bi-LSTM)和注意机制作为一个联合模型来处理句子的文本特征,并对两个实体之间的关系进行分类。
3)Bi-LSTM-ATT-RL[28]:将RL模型引入Bi-LSTM-ATT中,使用RL过滤掉数据集中带有噪声的句子,在句子级别上取得较好的关系分类性能。
4)GCN:该模型为一种多层的图卷积神经网络,每个卷积层只处理一阶领域信息,通过叠加几个卷积层可以实现多阶领域的信息传递。
5)GAT:在图卷积神经网络中加入注意力机制,来给每个邻居结点分配不同的权重,从而能够识别出更加重要的邻居结点。
-
为了证明本文提出模型的有效性,从两个方面对实验结果进行分析,并通过Precision、Recall和F1值对模型的性能进行评判。
-
在网络模型训练中,本文使用Bi-LSTM、Bi-LSTM-ATT、GCN、GAT和本文提出的联合网络模型(GCN-MHATT)进行比较,实验结果如表3所示。
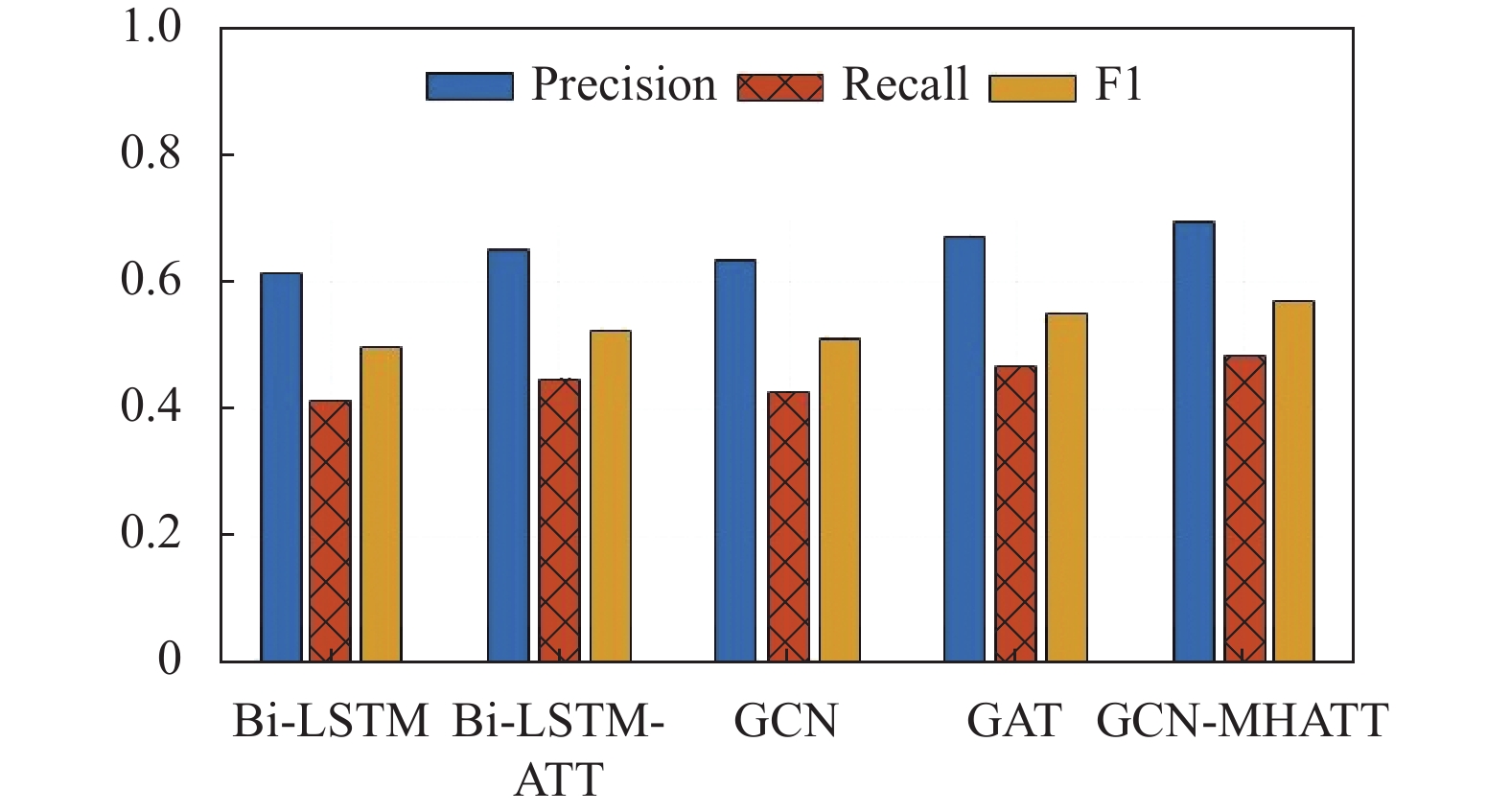
根据表3的实验结果显示,相较于Bi-LSTM模型,GCN在Precision、Recall和F1评分方面都有所提高,验证了GCN在关系抽取任务中比Bi-LSTM模型更加有效。同时,实验结果表明,在融合了注意力机制的Bi-LSTM-ATT模型中,其效果优于普通的Bi-LSTM模型。GAT和GCN的实验结果也表明,联合使用注意力机制和GCN能够显著改善各项性能指标,证明注意力机制可以进一步提高关系抽取任务的性能。本文提出的联合抽取模型(GCN-MHATT)由GCN和多头自注意力机制组成,在与Bi-LSTM-ATT和GAT相比较时,它的Precision分别提高了4.3%和2.1%,F1值分别提高了4.5%和1.8%。证明GCN和多头自注意力机制对于关系抽取任务的有效性,并在抽取任务中实现了良好的效果。
表 3 联合网络模型实验结果比较
模型 Precision Recall F1 Bi-LSTM 0.615 0.414 0.495 Bi-LSTM-ATT 0.650 0.447 0.524 GCN 0.635 0.426 0.510 GAT 0.672 0.465 0.551 GCN-MHATT 0.693 0.482 0.569 根据图6的结果可以更加直观地发现,相较于之前的模型,GCN模型在性能上表现更好且训练后的模型精确率更高。此外,在GCN模型的基础上,分别加入了自注意力机制和多头自注意力机制,使得模型的训练效果均有所提升,其中采用多头自注意力机制的模型表现最佳。

图 6 联合抽取模型实验结果对比
联合训练中,对联合网络模型和RL模型进行总体实验,使用Bi-LSTM-ATT、Bi-LSTM-ATT-RL、GCN-MHATT和GCN-MHATT-RL进行比较,实验结果如表4所示。
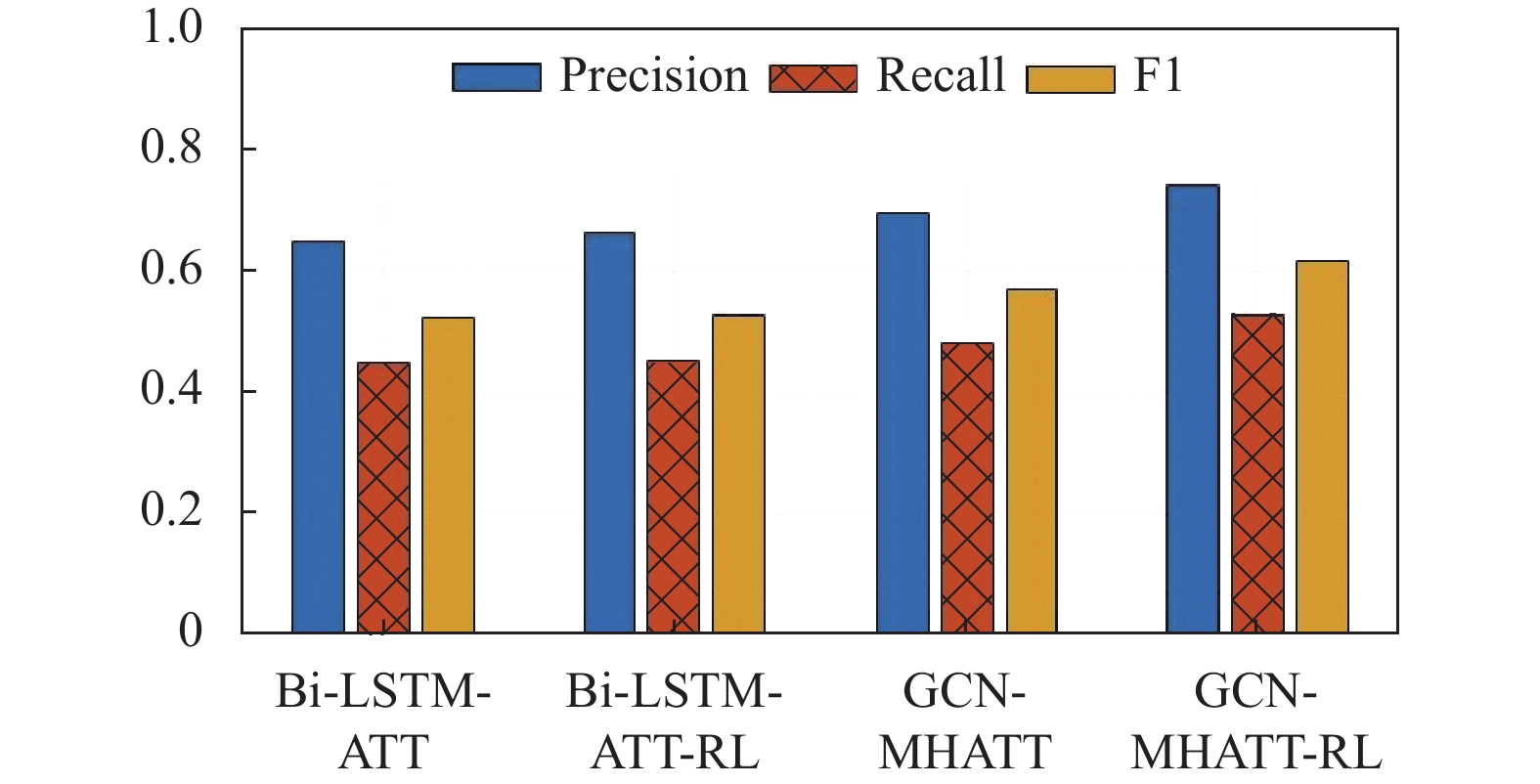
根据表4可以发现,相较于Bi-LSTM-ATT模型,采用RL方法的Bi-LSTM-ATT-RL模型在Precision、Recall和F1评分方面均有所提高,这证明了RL方法能够有效提高实体关系抽取模型的性能。为了进一步验证本文提出模型中RL方法的效果,在联合抽取模型基础上加入RL方法进行共同训练。结合RL方法可以改善联合抽取模型的实验结果,使精确率提高了4.9%,F1值提高了4.7%。这些实验结果表明,RL方法可以提高联合抽取模型的性能,并且在本文提出的联合抽取模型基础上,性能表现更佳。与Bi-LSTM-ATT-RL模型进行比较,本文提出的基于强化学习的实体关系联合抽取模型在Precision、Recall和F1值上的结果分别为74.2%、52.7%和61.6%,在实体关系抽取任务上表现出了非常理想的效果。
表 4 联合模型实验结果比较
模型 Precision Recall F1 Bi-LSTM-ATT 0.650 0.447 0.524 Bi-LSTM-ATT-RL 0.661 0.452 0.528 GCN-MHATT 0.693 0.482 0.569 GCN-MHATT-RL 0.742 0.527 0.616 通过观察图7中的柱形数据变化,发现在Bi-LSTM-ATT和GCN-MHATT模型的基础上加入强化学习能够显著提高新模型的抽取效果。此外,本文提出的模型效果明显优于Bi-LSTM-ATT-RL,表明该模型能够有效处理数据噪声问题,在实体关系抽取方面获得了良好的性能。
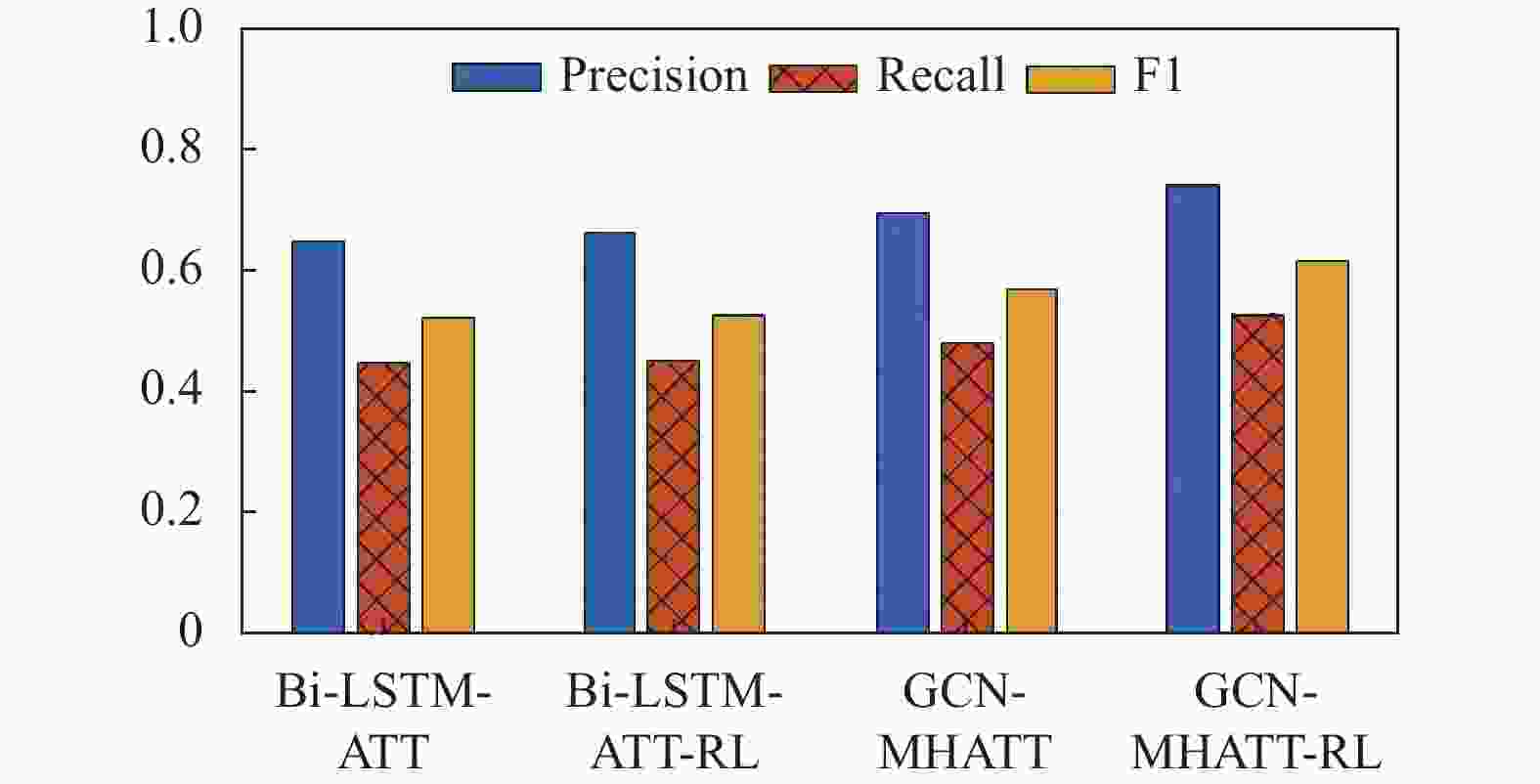
图 7 联合模型实验结果对比
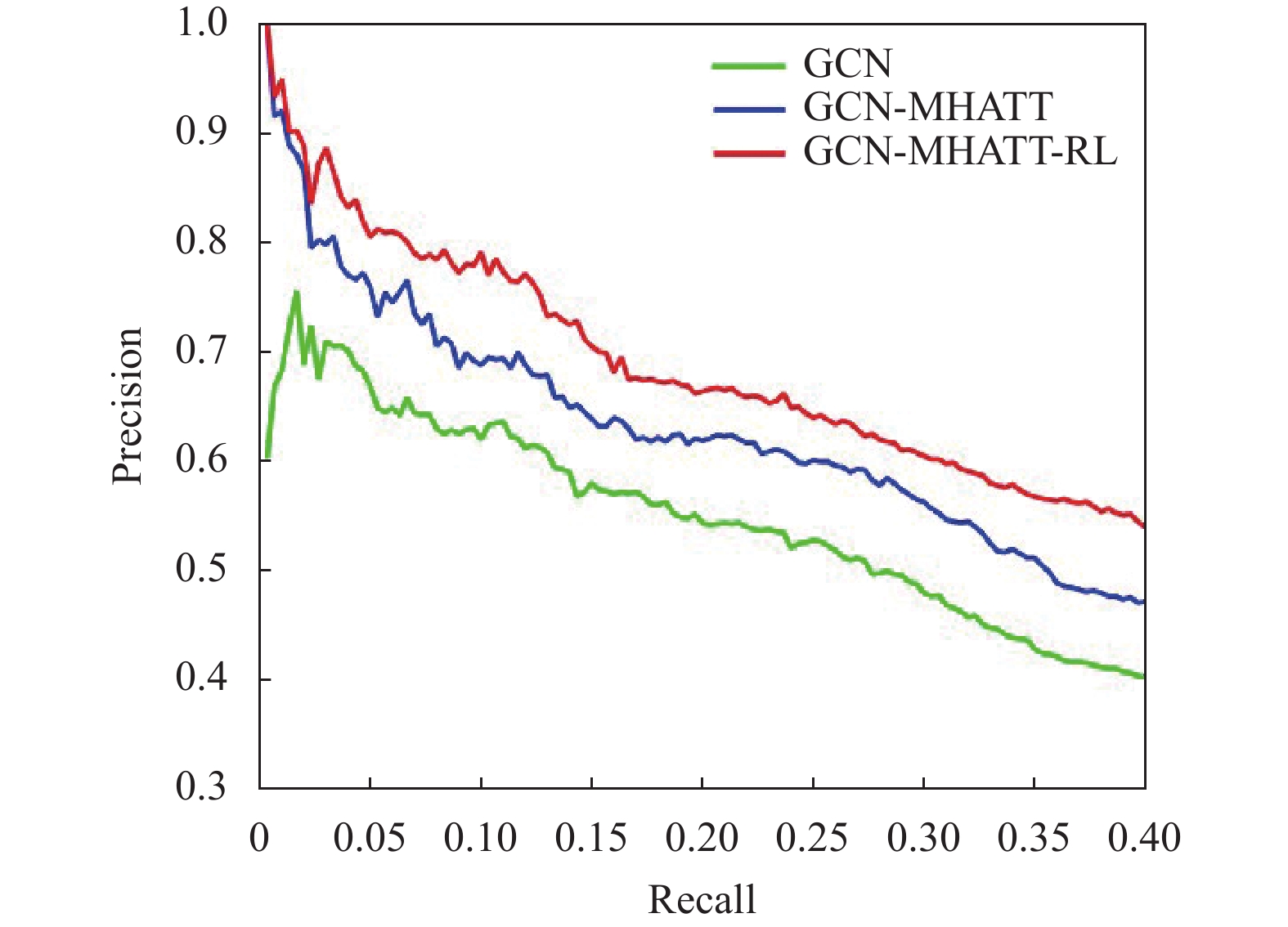
在带有噪声的数据集中,将本文提出的模型与GCN、GCN-MHATT进行性能比较。根据图8中的精确/召回曲线所示,融合了强化学习的GCN-MHATT-RL方法在性能上优于GCN方法和GCN-MHATT方法,这表明采用强化学习可以有效去除原始数据集中的噪声数据。

图 8 不同模型的性能对比
-
为检测模型组件的有效性,本文引入了GCN-MHATT-RL的3种变体,在数据集上进行消融研究。
1)GCN:从GCN-MHATT-RL中移除强化学习模型和多头自注意力机制,在实验中只包含图卷积神经网络模型;
2)GCN-RL:从GCN-MHATT-RL中移除多头自注意力机制,检测实验中只含有强化学习对模型的效果;
3)GCN-MHATT:从GCN-MHATT-RL中移除强化学习模型,检测实验中只含有多头自注意力机制对模型的效果。
表 5 消融实验结果比较
模型 Precision Recall F1 GCN 0.635 0.426 0.510 GCN-RL 0.681 0.463 0.576 GCN-HMATT 0.693 0.482 0.569 GCN-MHATT-RL 0.742 0.527 0.616 由表5可看出,模型在仅含有图卷积神经网络的情况下效果较差,说明通过融合强化学习代理和多头自注意力机制模型的性能得到了显著的提高。图卷积神经网络分别对强化学习和多头自注意力机制进行融合,效果均有提升,但相较GCN-MHATT-RL模型,实验结果低于本文提出的模型,说明了本文所提出的联合抽取模型对于抽取任务的有效性,并在抽取模型上取得了不错的效果。
-
本文提出了一种融合强化学习的实体关系联合抽取模型,该模型由强化学习和联合抽取模型构成。通过强化学习去除原始数据集中带有噪声的句子,将降噪后的句子输入到联合抽取模型中,再通过联合抽取模型对句子中的实体和关系进行预测抽取,并向强化学习提供反馈,指导句子选择过程。大量实验结果表明,本文提出的模型能够有效处理噪声数据问题,在实体关系抽取方面获得较好的性能。
Entity-Relationship Joint Extraction Model Infused with Reinforcement Learning
-
摘要: 现有的实体关系联合抽取任务为了自动生成大规模训练数据引入远程监督策略,在处理数据时产生严重的噪声数据问题。对此提出了一种融合强化学习的实体关系联合抽取模型,该模型由强化学习和联合抽取模型两个部分组成,其中联合抽取模型由图卷积网络和多头自注意力机制构成。首先,使用强化学习去除原始数据集中带有噪声的句子,将降噪后的高质量句子输入到联合抽取模型中;其次,使用联合抽取模型对输入句子中的实体和关系进行预测抽取,并向强化学习提供反馈奖励,指导强化学习挑选出高质量的句子;最后,对强化学习和联合抽取模型进行联合训练,并对模型进行迭代优化。实验证明了该模型能够有效处理数据噪声问题,在实体关系抽取方面优于基线方法。Abstract: Existing joint extraction tasks of entities and relationships introduce distant supervision strategies to automatically generate large-scale training data, leading to severe problems of noisy data during data processing. To address the issue of noisy data, this paper proposes an entity relation joint extraction model with reinforcement learning integration. The model consists of two components: reinforcement learning and joint extraction model. The joint extraction model is composed of a graph convolutional network and a multi-head self-attention mechanism. Firstly, reinforcement learning is utilized to eliminate noisy sentences from the original dataset, and the denoised high-quality sentences are input into the joint extraction model. Secondly, the joint extraction model is employed to predict and extract entities and relationships from the input sentences, and provide feedback rewards to the reinforcement learning component to guide it in selecting high-quality sentences. Finally, the reinforcement learning and joint extraction models are jointly trained and iteratively optimized. The experiments demonstrating that the proposed model can effectively address the issue of data noise and outperform baseline methods in entity relationship extraction.
-
表 2 实验参数
参数 值 词嵌入维度 50 位置嵌入维度 5 Bi-LSTM隐藏单元数 128 GCN维度 256 GCN层数 3 学习率 0.02 丢失率 0.5 更新率 0.01 权重因子 0.01 注意力头的大小 8  下载: 导出CSV
下载: 导出CSV
表 3 联合网络模型实验结果比较
模型 Precision Recall F1 Bi-LSTM 0.615 0.414 0.495 Bi-LSTM-ATT 0.650 0.447 0.524 GCN 0.635 0.426 0.510 GAT 0.672 0.465 0.551 GCN-MHATT 0.693 0.482 0.569
下载: 导出CSV
表 4 联合模型实验结果比较
模型 Precision Recall F1 Bi-LSTM-ATT 0.650 0.447 0.524 Bi-LSTM-ATT-RL 0.661 0.452 0.528 GCN-MHATT 0.693 0.482 0.569 GCN-MHATT-RL 0.742 0.527 0.616
下载: 导出CSV
表 5 消融实验结果比较
模型 Precision Recall F1 GCN 0.635 0.426 0.510 GCN-RL 0.681 0.463 0.576 GCN-HMATT 0.693 0.482 0.569 GCN-MHATT-RL 0.742 0.527 0.616
下载: 导出CSV
-
[1] TUO M, YANG W. Review of entity relation extraction[J]. Journal of Intelligent & Fuzzy Systems, 2023, 44(5): 7391-7405. [2] ZHAO S, SU C, LU Z, et al. Recent advances in biomedical literature mining[J]. Briefings in Bioinformatics, 2021, 22(3): bbaa057. doi: 10.1093/bib/bbaa057 [3] ELTYEB S, SALIM N. Chemical named entities recognition: A review on approaches and applications[J]. Journal of cheminformatics, 2014, 6: 1-12. doi: 10.1186/1758-2946-6-1 [4] BAI T, GUAN H T, WANG S, et al. Traditional Chinese medicine entity relation extraction based on CNN with segment attention[J]. Neural Computing and Applications, 2022, 34(4): 2739-2748. [5] YE Z, KUMAR Y J, SING G O, et al. A comprehensive survey of graph neural networks for knowledge graphs[J]. IEEE Access, 2022, 10: 75729-75741. doi: 10.1109/ACCESS.2022.3191784 [6] AYDAR M, BOZAL Ö, ÖZBAY F. Neural relation extraction: A review[J]. Turkish Journal of Electrical Engineering and Computer Sciences, 2021, 29(2): 1029-1043. doi: 10.3906/elk-2005-119 [7] VlITHAYATHI VARGHESE N, MAHMOUD Q H. A survey of multi-task deep reinforcement learning[J]. Electronics, 2020, 9(9): 1363. doi: 10.3390/electronics9091363 [8] ZHU Y, WANG G, KARLSSON B F. CAN-NER: Convolutional attention network for Chinese named entity recognition[EB/OL]. [2023-02-22]. https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8844740&tag=1. [9] LIU C, YANG S. Using text mining to establish knowledge graph from accident/incident reports in risk assessment[J]. Expert Systems with Applications, 2022, 207: 117991. doi: 10.1016/j.eswa.2022.117991 [10] HU W, HE L, MA H, et al. Kgner: Improving chinese named entity recognition by bert infused with the knowledge graph[J]. Applied Sciences, 2022, 12(15): 7702. doi: 10.3390/app12157702 [11] LV C, PAN D, LI Y, et al. A novel Chinese entity relationship extraction method based on the bidirectional maximum entropy Markov model[J]. Complexity, 2021, 2021: 1-8. [12] ZHANG D, WANG D. Relation classification via recurrent neural network[EB/OL]. [2023-02-26]. https://arxiv.org/pdf/1508.01006.pdf. [13] ZENG D, LIU K, LAI S, et al. Relation classification via convolutional deep neural network[EB/OL]. [2023-03-02]. https://aclanthology.org/C14-1220.pdf. [14] ZENG D J, LIU K, CHEN Y, et al. Distant supervision for relation extraction via piecewise convolutional neural networks[C]//Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Lisbon: [s.n.] 2015: 1753-1762. [15] ZHOU P, SHI W, TIAN J, et al. Attention-based bidirectional long short-term memory networks for relation classification[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin: ACL, 2016: 207-212. [16] LIN Y, SHEN S, LIU Z, et al. Neural relation extraction with selective attention over instances[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin: ACL, 2016: 2124-2133. [17] YANG Y, WU Z, YANG Y, et al. A survey of information extraction based on deep learning[J]. Applied Sciences, 2022, 12(19): 9691. doi: 10.3390/app12199691 [18] MIWA M, BANSAL M. End-to-end relation extraction using lstms on sequences and tree structures[EB/OL]. [2023-03-08]. https://arxiv.org/pdf/1601.00770.pdf. [19] ZHENG S, HAO Y, LU D, et al. Joint entity and relation extraction based on a hybrid neural network[J]. Neurocomputing, 2017, 257: 59-66. doi: 10.1016/j.neucom.2016.12.075 [20] BEKOULIS G, DELEU J, DEMEESTER T, et al. Joint entity recognition and relation extraction as a multi-head selection problem[J]. Expert Systems with Applications, 2018, 114: 34-45. doi: 10.1016/j.eswa.2018.07.032 [21] FENG J, HUANG M, ZHAO L, et al. Reinforcement learning for relation classification from noisy data[EB/OL]. [2023-03-08]. https://arxiv.org/pdf/1808.08013.pdf. [22] QIN P, XU W, WANG W Y. Robust distant supervision relation extraction via deep reinforcement learning[EB/OL]. [2023-03-08]. https://arxiv.org/pdf/1805.09927.pdf. [23] FENG Y T, ZHANG H J, HAO W N, et al. Joint extraction of entities and relations using reinforcement learning and deep learning[J]. Computational intelligence and neuroscience, 2017, DOI: 10.1155/2017/7643065. [24] TAKANOBU R, ZHANG T, LIU J, et al. A hierarchical framework for relation extraction with reinforcement learning[EB/OL]. [2023-03-18]. https://arxiv.org/pdf/1811.03925.pdf. [25] ZHU H, LIN Y, LIU Z, et al. Graph neural networks with generated parameters for relation extraction[EB/OL]. [2023-03-22]. https://arxiv.org/pdf/1902.00756.pdf. [26] CHRISTOPOULOU F, MIWA M, ANANIADOU S. A walk-based model on entity graphs for relation extraction[EB/OL]. [2023-03-26]. https://arxiv.org/pdf/1902.07023v1.pdf. [27] ZHANG S, ZHENG D, HU X, et al. Bidirectional long short-term memory networks for relation classification[EB/OL]. [2023-03-28]. https://aclanthology.org/Y15-1009.pdf. [28] LIU Z, DI X Q, SONG W, et al. A sentence-level joint relation classification model based on reinforcement learning[J]. Computational Intelligence and Neuroscience, 2021, 2021: 1-10. -

 点击查看大图
点击查看大图

图(8) / 表(5)
计量
- 文章访问数: 2364
- HTML全文浏览量: 787
- PDF下载量: 6
- 被引次数: 0













































































































































