 ISSN
ISSN 





-
眼底是人类唯一可以直接观察动脉、静脉和毛细血管的部位。糖尿病、高血压以及各种眼部疾病都会造成眼底血管几何形态的变化[1]。如糖尿病会导致视网膜血管病变与新生血管,高血压会导致血管异常增生等。因此在临床研究中,视网膜血管分割对帮助医生诊断相关疾病具有重要意义。然而由于视网膜血管拓扑结构复杂以及本身成像的限制,人为分割血管的难度较高,因此,提出一种高效、准确的视网膜血管分割方法非常重要。
近些年,视网膜血管自动分割算法从早期的无监督方法慢慢过渡到如今的有监督方法,这都归功于深度学习领域中卷积神经网络的飞速发展。在无监督算法中,主要是依据视网膜血管的一些物理特征(形状、颜色与纹理)或者人为定义的特征来对血管进行分割。文献[2]首先确定血管中心线,用作血管填充的依据,然后依据四个方向的差分算子来判断周围像素点是否作为中心线像素的候选点,最后通过迭代区域生长方法得到分割.结果。文献[3]提出了一种基于水平集和区域生长的视网膜血管分割方法,首先通过自适应直方图均衡与2D Gabor小波变换进行数据增强,然后使用各向异性扩散滤波器提取血管边界特征并平滑图像,最后使用区域生长方法和基于区域的活动轮廓模型分割视网膜血管。
相较于无监督方法,有监督方法虽然需要人工对数据进行标注,但也取得了更高的分割准确度。文献[4]将典型的视网膜血管分割问题从全尺寸图像分割简化为区域血管元素识别,并且使用经过预训练的AlexNet作为FCN[5]的特征提取骨干网络,最终很好地实现了血管像素的端到端分割。虽然FCN不限制输入网络的图像大小,但由于下采样操作造成空间信息的损失以及对卷积平移不变性的破坏,导致分割的血管出现断裂。文献[6]通过迭代mini-UNet增加网络深度,提升了模型分割血管细节的能力。文献[7]等人对金字塔池化进行改进,并在跳跃连接处加入注意力机制,有效地减少特征信息的损失。文献[8]在生成对抗网络GAN[9]的基础上,首先对眼底图像进行非均匀光照移除和主成分分析,然后将带偏移量的深度可分离卷积[10]和SE模块[11]同时加到生成器与判别器中,有效的减少了分割结果中血管断裂的现象。文献[12]将Transformer[13]架构引入到U-net中,通过对编码阶段特征的通道信息和位置信息联合关注增强编码局部细节特征,提高了网络对血管特征的敏感度。上述基于U型架构的网络模型受限于卷积核大小的限制,不能对全局信息进行建模,并且在下采样过程中会造成空间信息的损失,从而造成分割结果中出现血管边界不清晰或出现噪声等现象。
针对以上问题,本文提出了一种基于图卷积的多层级特征融合网络的视网膜血管分割算法。
-
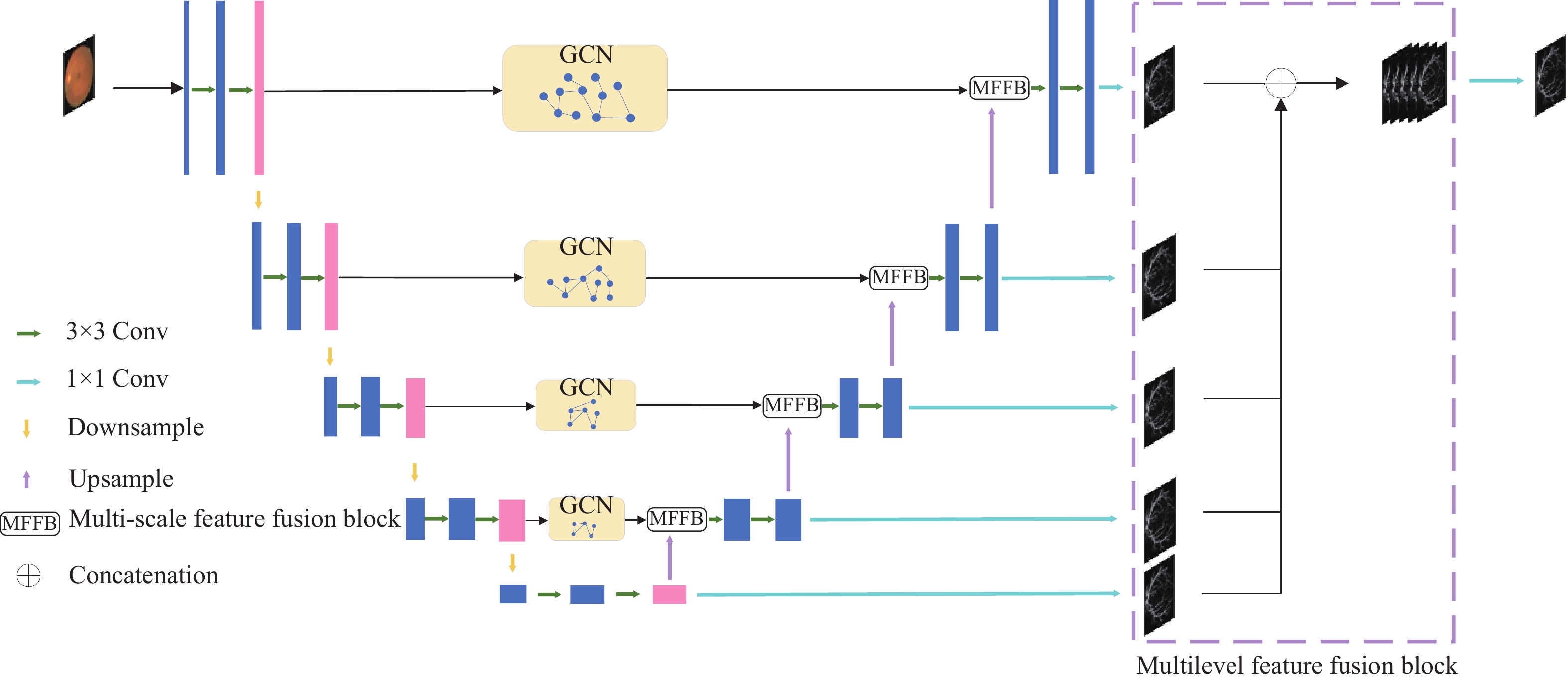
本文在U形编码器-解码器[14]架构的基础上,提出一种图卷积多层级特征融合的眼底视网膜血管分割网络(Retinal Vessels Segmentation Algorithm Based on Graph Convolutional Feature Fusion Network, GCFF-Net)。网络结构如图1所示。
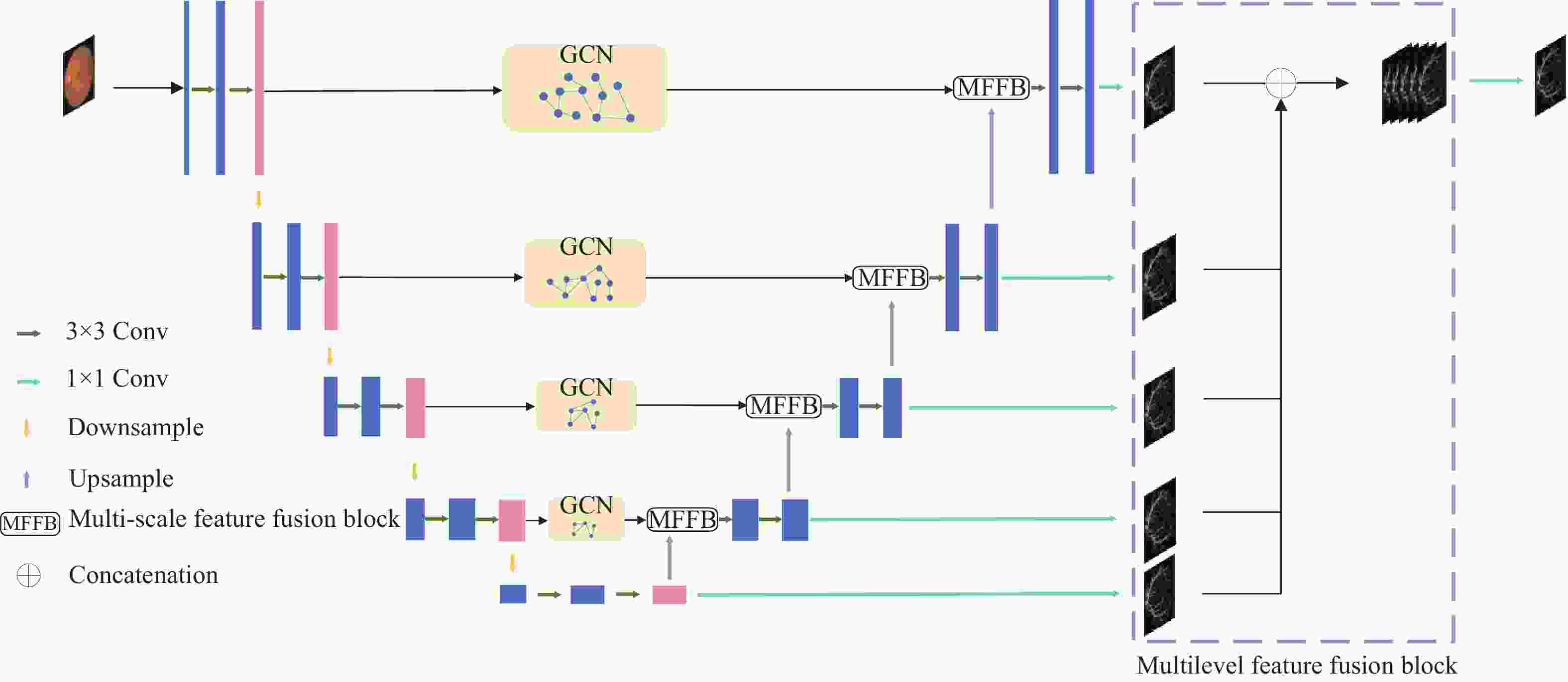
图 1 方法结构图
该网络主要由4部分组成,分别为U型编解码器,图卷积模块,多尺度特征融合模块以及多层次特征融合模块。编码器的每一层主要由两个3×3的卷积层提取特征,在两层之间使用最大池化层进行下采样,在降低图像分辨率的同时增加特征图所蕴含的语义信息。在编码器与解码器之间的跳跃连接处加入图卷积模块,通过K-近邻算法将编码器提取到的特征图转化为图结构,并使用图卷积进行特征变换,对图像的全局上下文信息进行建模,并捕获像素之间的长距离依赖关系,从而减少分割结果中出现血管断裂的现象。解码器的每一层主要由一个多尺度特征融合模块与两个3×3的卷积层组成,多尺度特征融合模块通过计算图卷积特征层与普通卷积层特征的通道注意力权重对两种特征进行融合,对特征层中的噪声信息进行抑制并注重血管的特征信息,可以有效地减少分割结果中噪声的出现。解码器的每一层之间使用双线性插值算法代替转置卷积进行上采样,来减少模型参数量。多层次特征融合模块将解码器每一层首先通过空洞卷积层提取不同尺度特征,然后经过sigmoid激活与1×1卷积层变换通道数,最后使用双线性插值将特征图上采样至输入图像大小并在通道维拼接,以此来减少编码器下采样过程中空间信息的损失,并对深层特征加以复用。模型的输出是将融合后的多层次特征经过1×1卷积与softmax激活得到最后的分割概率图。
-
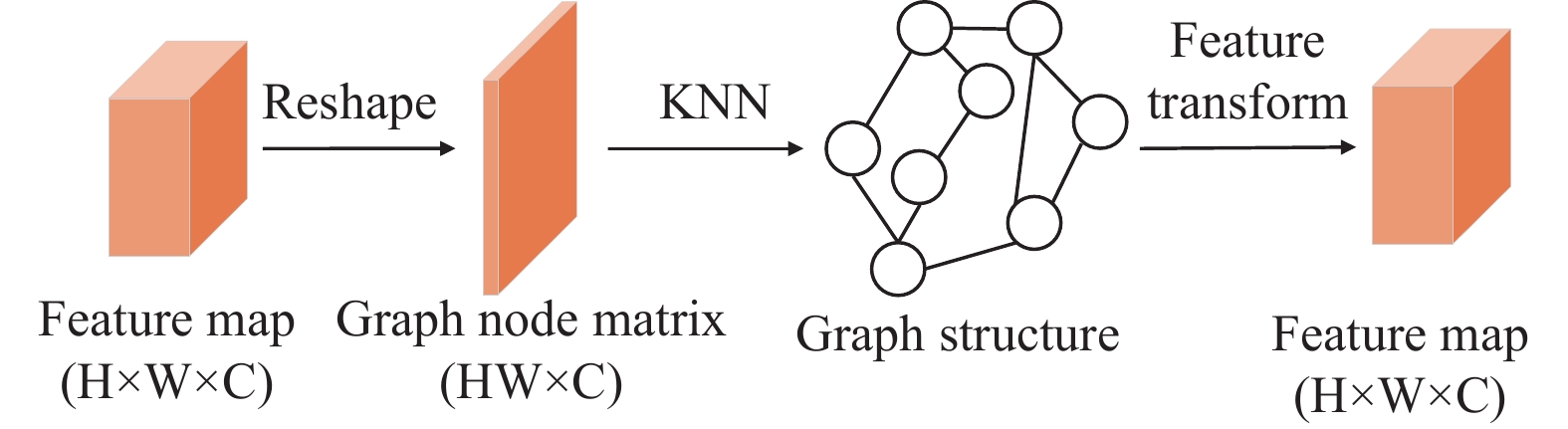
图卷积网络(Graph Convolutional Networks, GCN)是一种针对图结构数据的深度学习模型,可以用于节点分类、图分类、链接预测等任务。GCN[15]的核心思想是将卷积运算扩展到图结构数据,通过对邻居节点的信息进行聚合,实现节点的特征更新。文献[16]提出一种新型视觉GNN(ViG)架构。ViG首先将图像分割成一组形状规则的补丁,并将每个补丁视为一个图节点,通过K近邻算法找到每个节点的K个最近邻居作为图的边,然后在每个节点上进行图卷积操作学习节点特征。基于此,本文在编码器与解码器之间加入GCN模块,将编码器特征图的每个像素都当作一个图节点,使用K邻近算法构图,通过图卷积操作捕获全局特征信息。GCN模块架构如下:
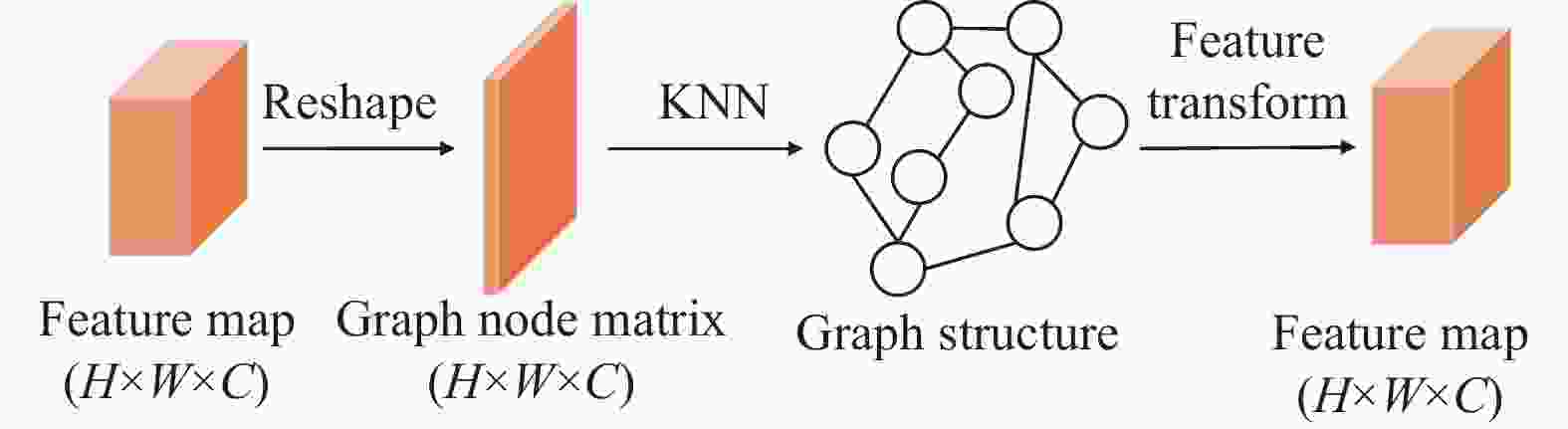
图 2 图卷积模块
GCN模块包含两个部分,分别为图构造与图卷积计算。
1)图的构造。首先使用reshape函数将编码器层的特征
$ X \in {\mathbb{R}^{H \times W \times C}} $ 转换为图节点矩阵$ {X{'}} \in {\mathbb{R}^{HW \times C}} $ 。然后使用K近邻算法得出两两节点之间的距离,选择每个节点距离最近的K个节点作为该节点的相邻节点,由此可以得到邻接矩阵A。2)图卷积计算。本文使用拉普拉斯矩阵来定义图卷积。对于一个无向图
$ \varsigma = \left\{ {\nu ,\varepsilon } \right\} $ ,A代表邻接矩阵,D代表度矩阵,$ {D_{ii}} = \sum _j^N{A_{ij}} $ 。$ L = I - {D^{ - 1/2}} A{D^{ - 1/2}} $ 表示对$ \varsigma $ 进行归一化操作的拉普拉斯矩阵。L可以分解为$ L = U\Lambda {U^T} $ ,其中U为特征向量矩阵,$ \Lambda = diag[{\lambda _1}, \cdots ,{\lambda _n}] $ 为特征值矩阵。图卷积网络(GCN)引入ChebNet的一阶近似$ (K = 1) $ 。GCN迭代的聚合来自邻居节点的信息。关于节点$ {v_i} $ 的前向传播过程为:$$ {h_i}^{(l + 1)} = \sigma \left(\sum\limits_{{v_j} \in \mathcal{N}({v_i}) \cup \{ {v_i}\} } {\hat a({v_i},{v_j}){W^{(l)}}{h_j}^{(l)}} \right) $$ (1) 式中,
$ \sigma ( \cdot ) $ 为非线性激活函数;$ \hat A = (\hat a({v_i},{v_j})) $ 表示重新归一化的邻接矩阵A;$ {W^{(l)}} $ 表示第$ l $ 层的可学习变换矩阵。 -
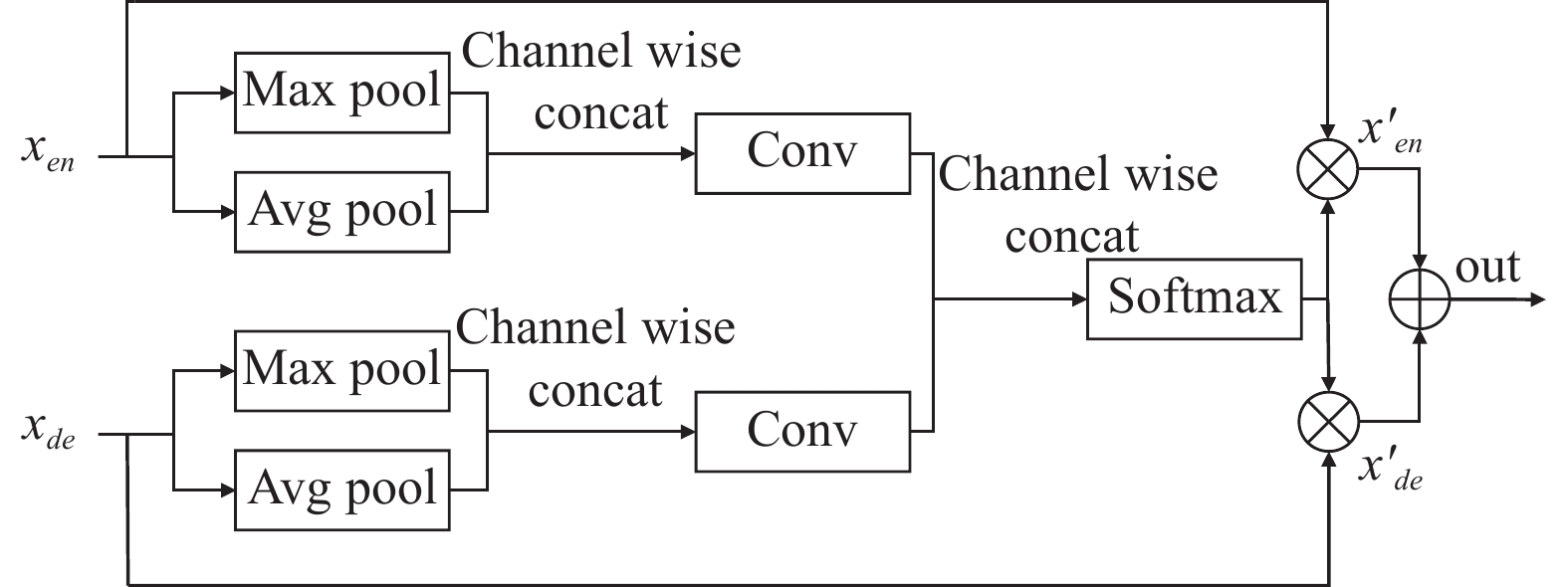
在U-Net中,Skip-connection解决的问题主要是如何在编码器和解码器之间进行信息传递和整合,以提高模型对于目标的分割精度。然而,仅仅使用简单的跳跃连接无法去除编码器与解码器特征中的噪声信息,并且还会丢失一部分血管信息。因此,本文提出一种多尺度特征融合模块(Multi-scale Feature Fusion Block),增加特征图中血管特征的权重,并减少噪声的权重,使编码器与解码器之间特征更好的融合。其结构如下图3所示。
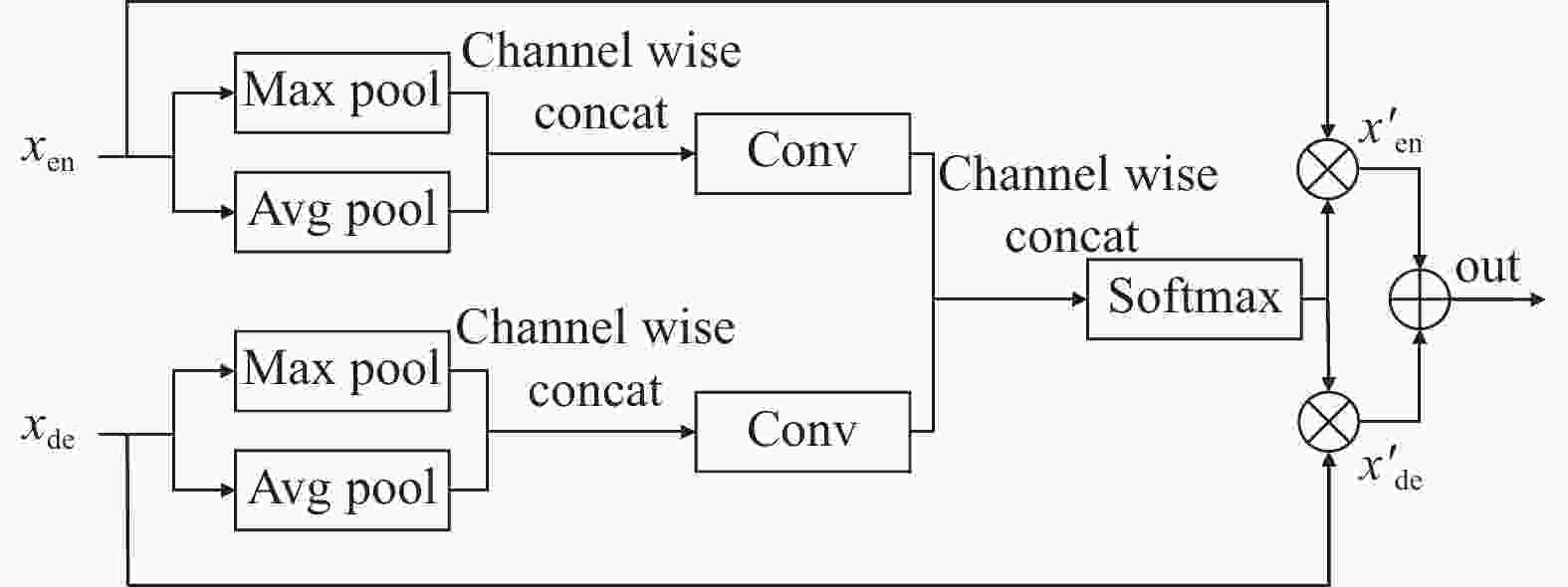
图 3 多尺度特征融合模块
其中
$ {x_{en}} $ 与$ {x_{de}} $ 分别为编码器与解码器的特征图,$ x'_{en} $ 与$ x'_{de} $ 是经过权重计算后的特征图。首先,$ {x_{en}} $ 和$ {x_{de}} $ 分别通过最大池化和的平均池化聚合特征图的空间信息[17],然后经过1$ \times $ 1卷积变换通道维度,最后拼接在一起经过softmax层得到权重系数矩阵$ \alpha $ 。最后得到的编码器特征与解码器特征计算过程如下:$$ x'_{en} = {\alpha _0} \circ {x_{en}} $$ (2) $$ x'_{de} = {\alpha _1} \circ {x_{de}} $$ (3) 式中,
$ \circ $ 为哈达玛积;$ {\alpha _0} $ 与$ {\alpha _1} $ 分别为权重系数矩阵$ \alpha $ 的第一、二个通道;$ \alpha $ 的计算公式如下:$$ {\alpha _0} = Conv[cat(avgpool({x_{en}}),maxpool({x_{en}}))] $$ (4) $$ {\alpha _1} = Conv[cat(avgpool({x_{de}}),maxpool({x_{de}}))] $$ (5) $$ \alpha = softmax(cat({\alpha _0},{\alpha _1})) $$ (6) -
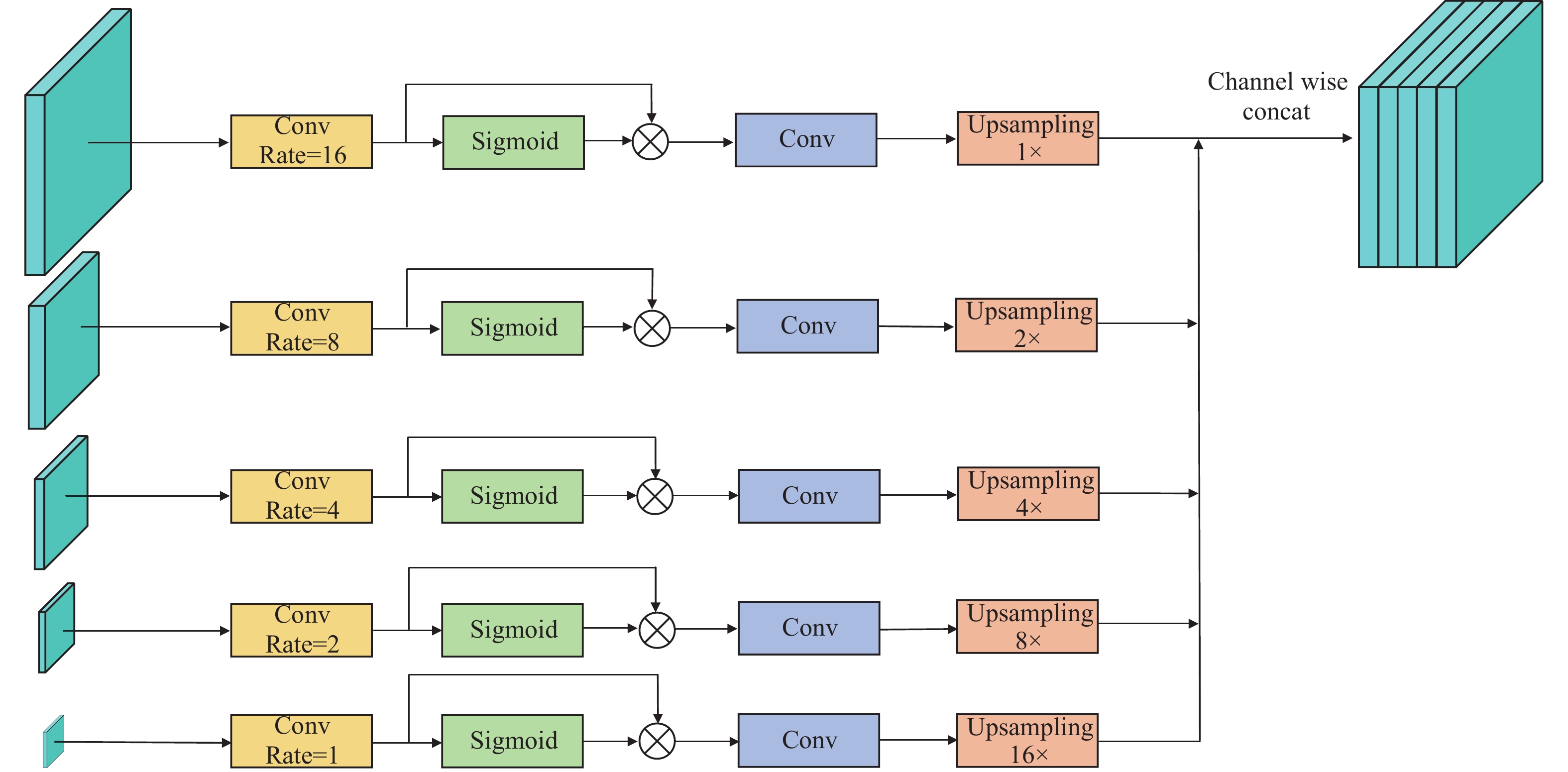
在U-Net中,编码器通过多次下采样和卷积操作,逐步提取出图像的高级特征,而解码器则通过多次上采样或者转置卷积操作,将这些特征转换成分割结果。然而,在这个过程中,随着特征图分辨率不断减小,在增加语义信息的同时会造成空间信息的损失,因此,解码器需要在重建图像时从编码器中获取更多的上下文信息,以提高分割的准确性。基于此,本文提出多层次特征融合模块(Multilevel Feature Fusion Block),其结构如下图4所示。
为了弥补下采样过程中空间信息的损失以及充分利用解码器每一层的特征信息,该模块首先通过使用不同空洞率的卷积层[18]来提取不同尺度的特征,每一层的空洞率分别为16,8,4,2,1,再通过sigmoid激活函数得到特征权重
$ \alpha $ ,特征层x与$ \alpha $ 相乘得到该层解码器输出,然后通过1$ \times $ 1卷积与上采样将解码器每一层的输出投射到相同的特征空间,每一层的上采样率分别为1,2,4,8,16,即:$$ \hat x_{de - out}^i = upsampling(x_{de - out}^i),{\text{ }}i = 1,2,3,4,5 $$ (7) 最后将每一层输出在通道维度拼接起来得到多层次特征融合层。

图 4 多层次特征融合模块
-
本文实验环境为基于12th Gen Intel(R) Core(TM) i7-12700 @ 2.10 GHz CPU 16 G内存,显卡为NVIDIA RTX A4000 GPU 16 G,采用Windows 10系统。该模型代码基于Pytroch深度学习框架,训练过程中初始学习率为0.0005,选用的优化器为Adam,损失函数设置为交叉熵损失加上DICE损失的联合损失,根据显卡性能选择送入网络的图片批量大小batch_size为16,使用余弦退火算法作为学习率衰减策略。此外若连续10个epoch未取得最优,则停止训练。
-
本实验采用的数据集包括DRIVE、STARE以及CHASEDB1。DRIVE数据集的照片来自荷兰的糖尿病视网膜病变筛查项目,其中包含40幅图像,每幅图像大小为768×584。STARE数据集来自加州大学圣地亚哥分校,包含20幅大小为605×700的图像。CHASEDB1数据集包含28幅大小为999×960像素的彩色视网膜图像,这些图像采集自14名学童的左眼和右眼。每幅图像都由两位独立的专家注释。
由于在视网膜血管图像中,绿色通道图像的血管与背景对比度较高,因此将原图分离为RGB三通道特征图并进行加权处理,然后使用直方图均衡化将视网膜图像的直方图近似均匀分布,从而增强图像的对比度,最后进行Gamma变换,更有效的保留图像亮度信息。为了防止神经网络出现欠拟合现象,在本次研究中,3个数据集都只有几十张图片,因此需要对数据集进行扩充:对输入图像进行随机水平、垂直翻转,分块。本实验将训练图像以及标签切分为64×64大小的像素块,每个像素块间隔16个像素点。最终预处理结果如下图5所示。

图 5 数据预处理最终结果
-
为了定量评估本文模型的分割性能,使用F1-score、准确率ACC、ROC曲线下的AUC面积、特异性SP(正确分类非血管像素占总体非血管像素的比例)、灵敏性SE(正确分类血管像素占总体血管像素的比例)作为评价指标:
$$ F1 = \frac{{2 \times TP}}{{2 \times TP + FP + FN}} $$ (8) $$ A c c=\frac{T P+T N}{T P+F P+T N+F N} $$ (9) $$ Se = \frac{{TP}}{{TP + FN}} $$ (10) $$ Sp = \frac{{TN}}{{TN + FP}} $$ (11) 式中,TP,TN,FP,FN分别为真阳性,真阴性,假阳性,假阴性。
-
为了验证本文算法在视网膜血管图像上的分割性能,将GCFF-Net与U-Net、Attention U-Net[19]两个模型在DRIVE、CHASEDB1、STARE三个数据集上进行比较。为公平比较3个模型分割性能,对比实验采用相同的实验环境。性能指标对比与分割效果对比分别如表1与表2所示。
表 1 不同模型在DRIVE、CHASEDB1和STARE上的性能指标比较
Dataset Model F1 SE SP ACC AUC(ROC) DRIVE U-Net 0.8248 0.8213 0.9751 0.9555 0.9773 Attention U-Net 0.8254 0.8389 0.9717 0.9548 0.9805 GCFF-Net(ours) 0.8290 0.8345 0.9739 0.9573 0.9813 CHASEDB1 U-Net 0.8224 0.8213 0.9782 0.9609 0.9837 Attention U-Net 0.8328 0.8320 0.9778 0.9631 0.9873 GCFF-Net(ours) 0.8379 0.8427 0.9791 0.9640 0.9878 STARE U-Net 0.8002 0.7285 0.9896 0.9632 0.9807 Attention U-Net 0.8032 0.7546 0.9860 0.9626 0.9821 GCFF-Net(ours) 0.8063 0.7786 0.9814 0.9595 0.9836 表 2 不同模型复杂度对比
model Params(M) Times(ms) U-Net 34.5259 3.4007 Attention-Unet 34.8774 6.4478 GCFF-Net 34.8793 10.1559 -
由表1可知,由于Attention U-Net在U-Net的基础上加入基于网格的注意力门机制,增加了模型对前景像素的敏感度,在表1中DRIVE和CHASEDB1数据集体现为SE指标的上升,在一定程度上提高了提取血管像素的能力,然而Attention U-Net过于注重前景像素会造成过度分割的问题,即将背景像素错误分类为前景像素,从而导致SP指标的下降。本文算法在SE与SP指标上都取得了较高的得分,且F1值与AUC值在3个数据集上均由于其他方法,说明本文算法的分割结果与金标准的相似程度最高。
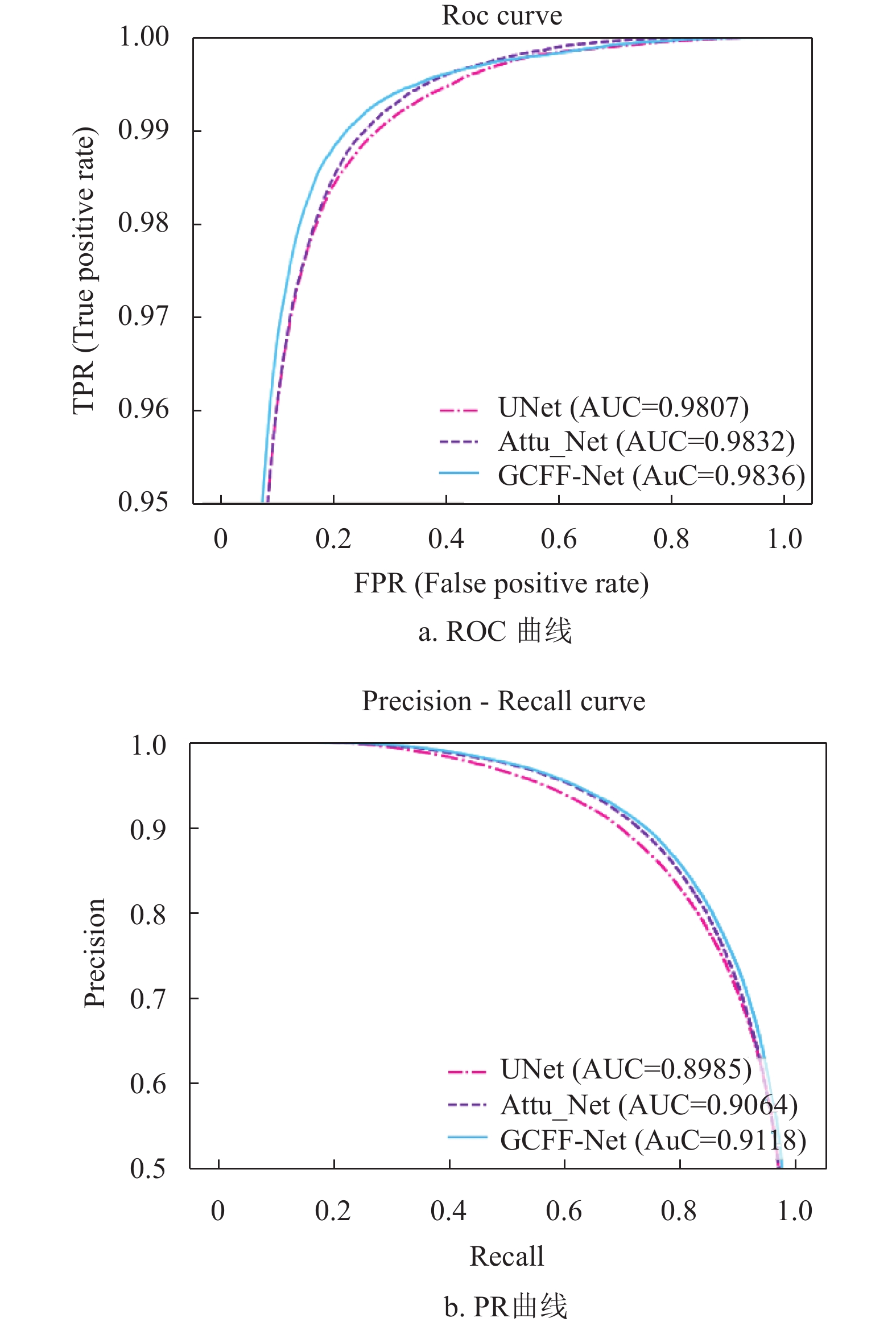
图6、图7与图8分别为上述3个网络模型在DRIVE、CHASEDB1和STARE数据集上的ROC曲线与PR曲线,可以看出本文算法较其他模型的AUC(ROC)值与AUC(PR)值分别平均高出0.24%、0.63%、0.22%和0.23%、1.13%、0.93%,说明本文算法分割血管的能力优于其他网络。
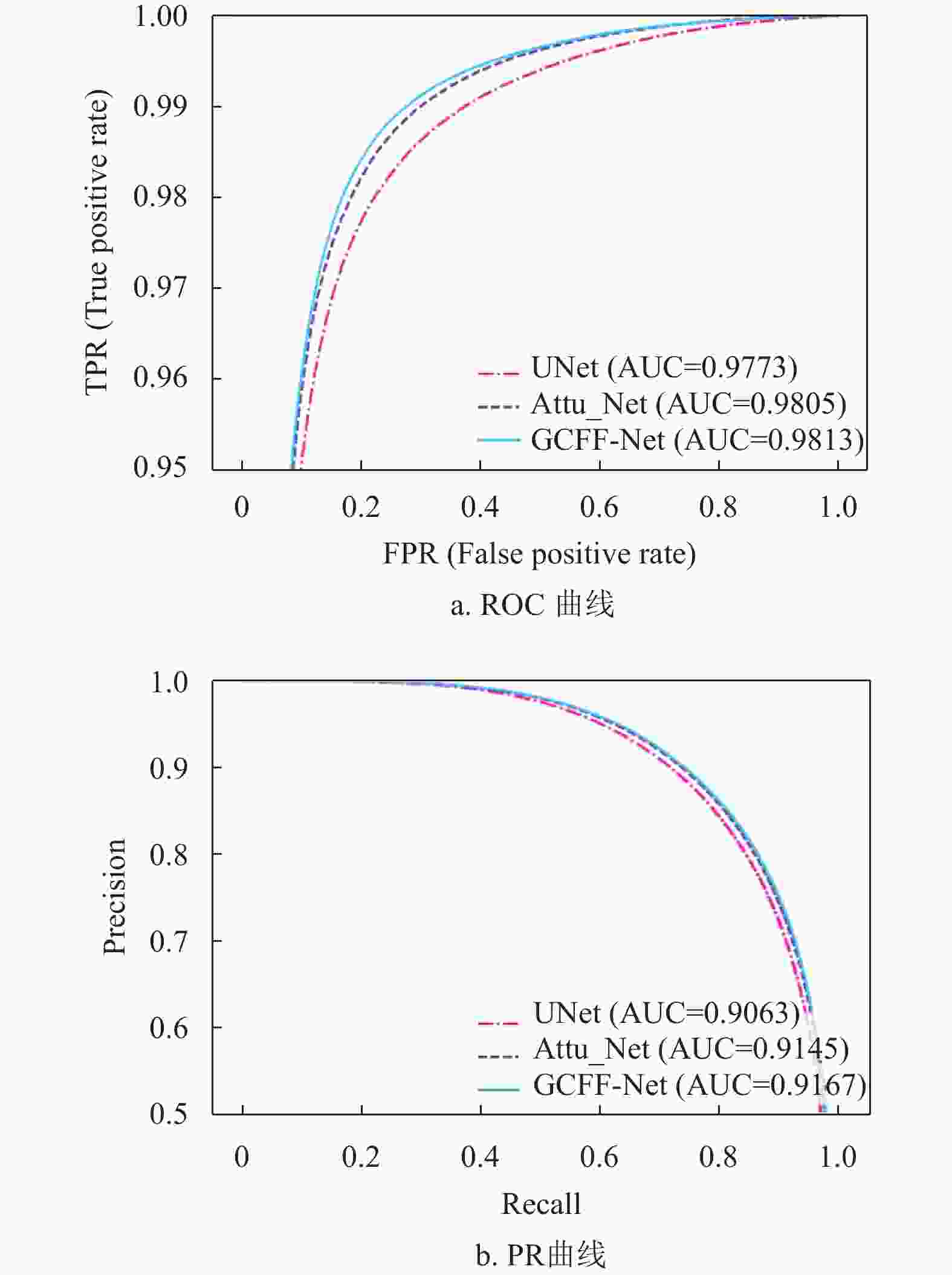
图 6 不同模型在DRIVE数据集上ROC曲线与PR曲线对比图
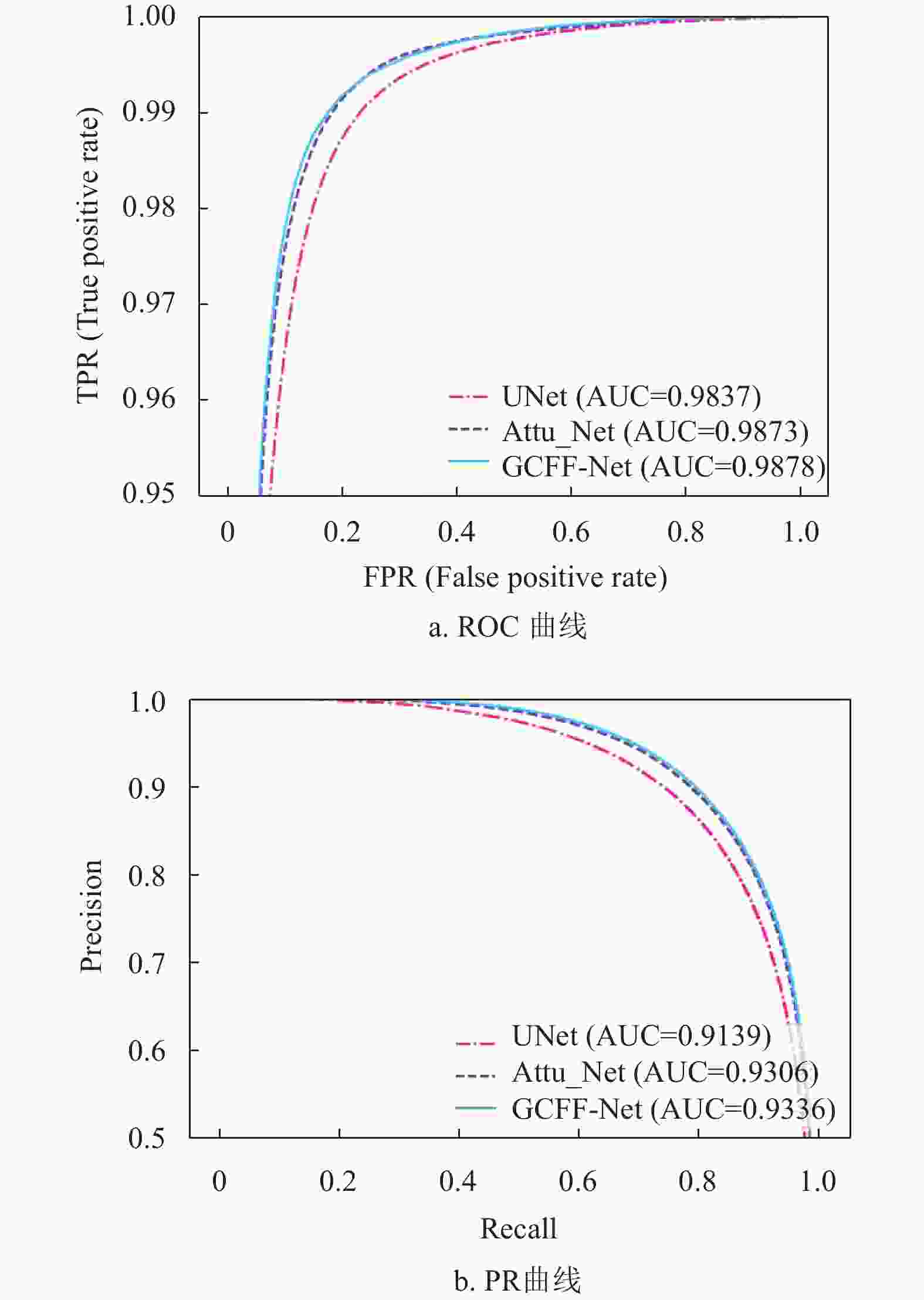
图 7 不同模型在CHASEDB1数据集上ROC曲线与PR曲线对比图
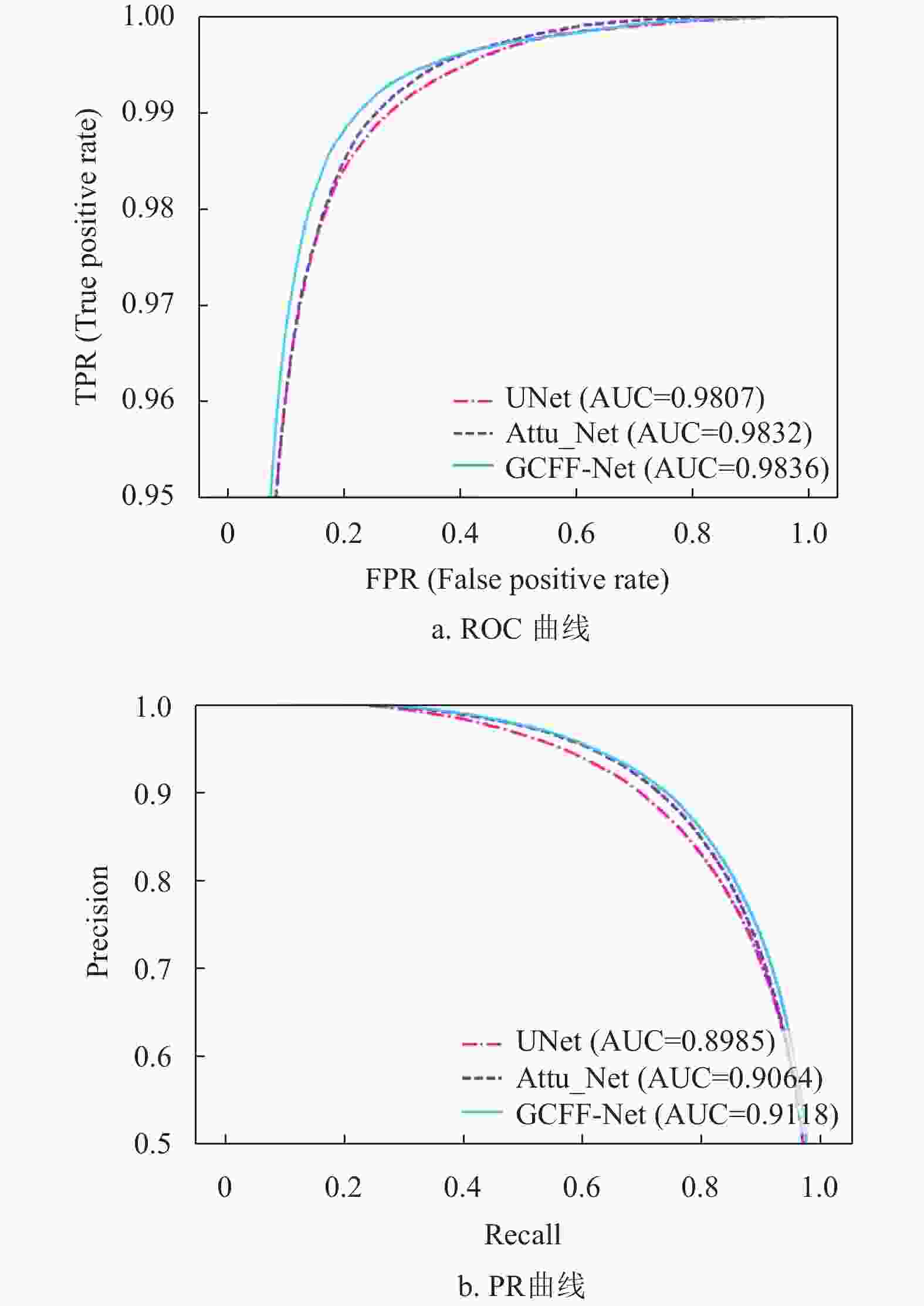
图 8 不同模型在STARE数据集上ROC曲线与PR曲线对比图
-
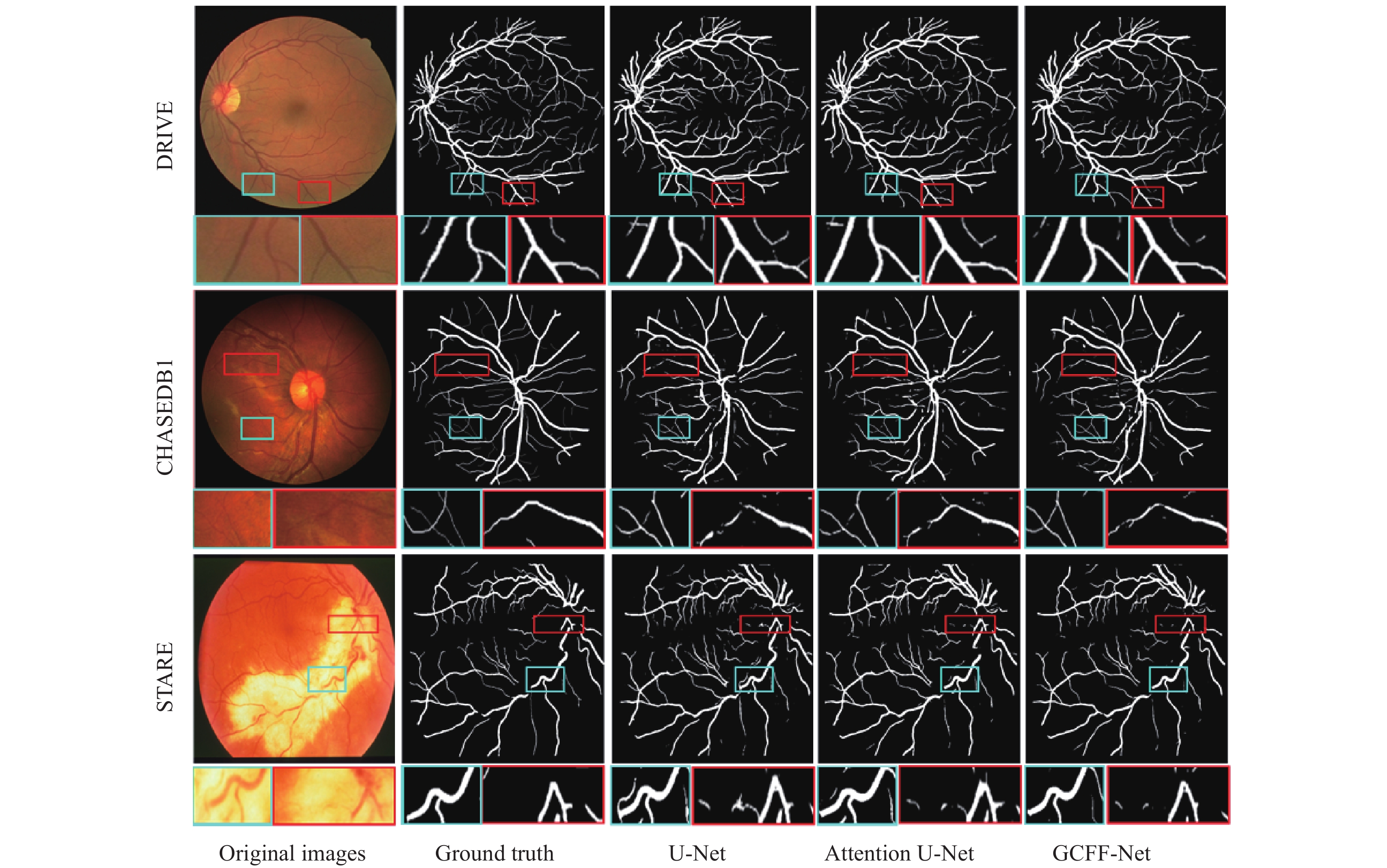
图9从DRIVE、CHASEDB1和STARE三个数据集中分别挑选出一张图片进行分割效果对比,每幅图片都有两个对比的矩形局部区域。表中第一行DRIVE数据集的分割结果中,由于血管末端的小血管太薄,U-Net与Attention U-Net都将部分背景像素分类成血管像素,导致局部分割图中出现些许噪声,这是因为这两种算法直接将编码器特征与解码器特征拼接,无法去除卷积层提取到的特征中的噪声信息,而本文算法在跳跃连接处加入的多尺度特征融合模块,可以有效减少编码器与解码器特征中的噪声信息,同时增加血管特征的权重,从而避免分割结果中噪声的出现。表中第二行CHASEDB1数据集的分割结果中,因为光照不足或者过度曝光,使得图像对比度降低,进而造成视网膜血管边界不清晰和血管信息丢失,从矩形局部分割图中可以看出,U-Net与Attention U-Net使用普通卷积只能提取局部特征,虽然Attention U-Net在卷积层中加入注意力机制提升了提取血管像素的能力,缓解了血管断裂的问题,但也引入了少许噪声,而本文算法在编码器与解码器之间加入图卷积模块,来捕获血管像素之间的长距离依赖关系,从而有效减少了分割结果中血管断裂的现象。表中第三行STARE数据集中,对比区域为视盘区域,是整幅图像中血管最集中的地方,该处的血管分割难度更大。虽然U-Net与Attention U-Net可以很好的分割出血管轮廓,但也出现了血管边界不清晰的问题,这是由于编码器在下采样过程中会丢失空间信息,而本文算法提出的多层次特征融合模块可以有效弥补空间信息的损失以及充分利用编解码器每一层的特征,在血管拓扑结构复杂的情况下,依然能够准确地分割出血管结构。
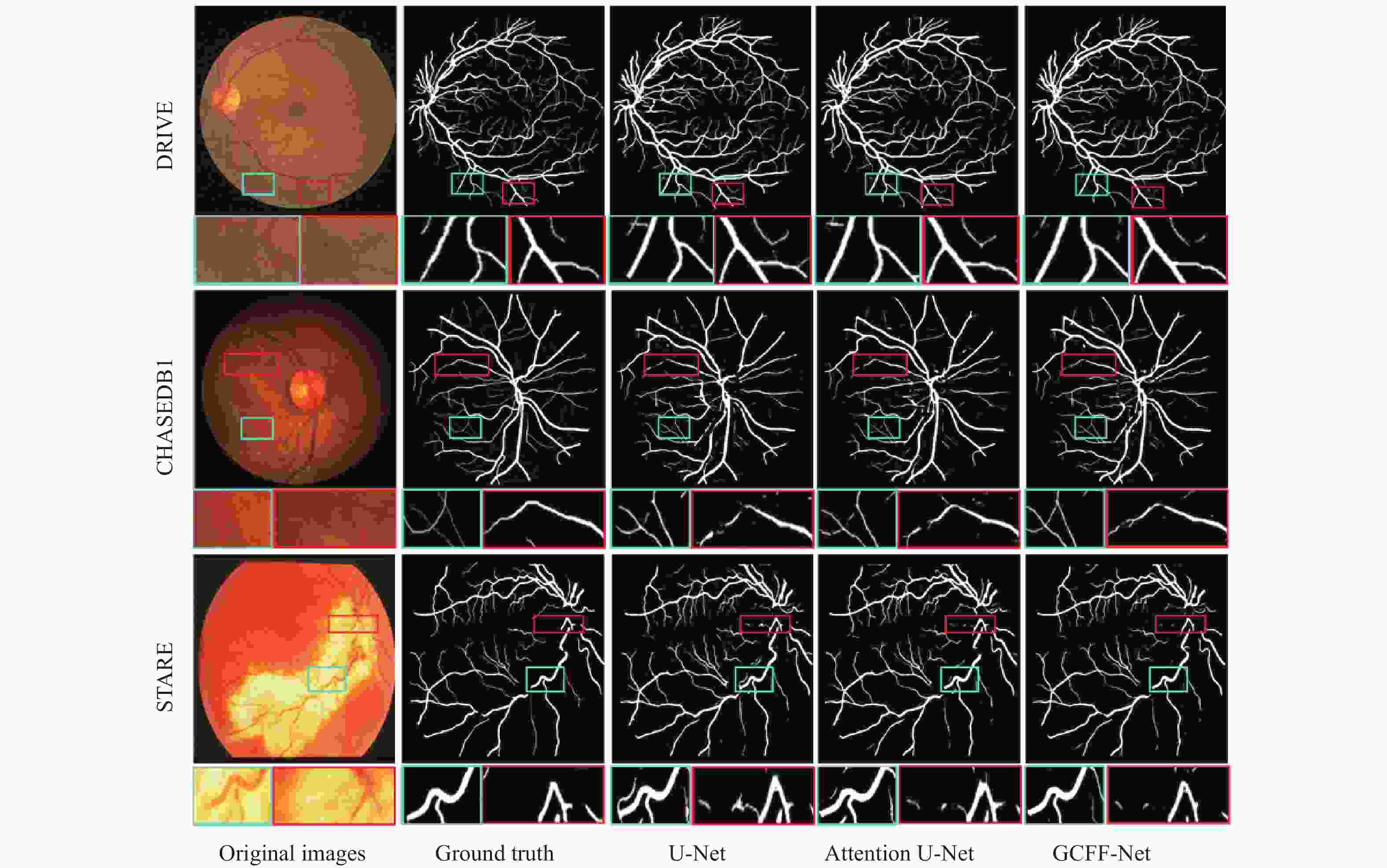
图 9 不同模型分割效果对比图
综上所述,本文算法在DRIVE、CHASEDB1与STARE数据集上都取得了优良的分割结果。相较于其他分割算法,本文算法分割出的血管结构更加清晰,不易出现血管断裂的现象,位于血管末端的小血管也能实现较为精确的分割。同时在由于光照不足造成图像对比度低的情况下,本文算法也能避免伪影的干扰,捕获完整的血管。实验结果证明,本文算法能出色的完成视网膜血管分割的任务。
-
本节主要从时间复杂度与空间复杂度两个方面对模型的复杂度进行分析。其中空间复杂度主要通过模型的参数量来衡量;时间复杂度通过将(1,1,64,64)大小的张量输入模型,并迭代100次,最后计算平均每次迭代所使用的时间。
由表2可知,本文提出的模型相较于U-Net参数量仅增加了1.02%,且与Attention-UNet的参数量相差无几。在模型的推理速度方面,由于本模型的图卷积模块中使用K近邻算法计算每个像素之间的距离来达到构图的目的,因此推理时间较UNet与Attention-UNet有所增加。综上所述,由于本文模型的优异性能,因此模型在时间复杂度与空间复杂度上稍许增加是可以接受的。
-
为了进一步验证本文算法在视网膜血管上的分割能力,先择了近几年的先进算法在F1、SE、SP、ACC、AUC这5个指标上进行对比,对比结果如表3-5所示。MLA-Net提出自适应通道注意力模块对特征通道赋以权重,以此来减少特征中冗余的信息,但其SE值在3个数据集上均低于本文,且在CHASEDB1与STARE数据集上的F1值与AUC值也低于本文,其中F1值分别比本文低0.11%和1.31%,AUC值分别比本文低0.66%和0.10%,说明多尺度特征融合模块对特征图血管噪声的抑制要强于自适应通道注意力模块。DU-Net使用可变形卷积代替U-Net中的传统卷积,从而学习局部、密集和自适应感受野来模拟各种形状的和尺度的视网膜血管,虽然可变形卷积可以依据输入图像改变卷积核的感受野,但依然很难关注到血管这样细小的结构,而本文所使用的图卷积模块通过捕获血管像素之间的长距离依赖关系,可以更好地关注血管的结构信息,因此本文算法在DRIVE与CHASEDB1数据集上的各指标均高于DU-Net。ConvMixer借用ViT的思想,将输入图像划分为补丁,并使用深度卷积与点卷积分别在空间和通道维度上混和提取的特征,然而其F1值仍低于本文算法,且该模型在整个网络中保持相同的大小和分辨率,虽然有利于减少上采样与下采样所造成的信息损失,但也增加了模型的参数量与计算开销。SA-Unet引入空间注意力模块使特征图自适应特征细化,是模型更加关注血管特征,但其SE值比本文低1.33%,说明其提取血管特征的能力弱于本文所提出的多尺度特征融合模块。综合表3~5可知,本文算法的分割性能优于其他网络,尤其是F1值在三个数据集上都达到最优,体现了本文算法更加稳健。
表 3 不同算法在DRIVE数据集上的性能指标
Algorithm F1 SE SP ACC AUC R2U-Net[20] 0.8150 0.7735 0.9818 0.9553 0.9784 DUNet[21] 0.8237 0.7963 0.9721 0.9566 0.9820 MResU-Net[22] 0.8237 0.7969 0.9799 -- 0.9799 RSAN[23] 0.8222 0.8149 0.9839 0.9691 0.9855 MLA-Net[24] 0.8279 0.8046 0.9805 0.9581 0.9827 SA-UNet[25] 0.8263 0.8212 0.9840 0.9698 0.9864 ConvMixer[26] 0.8245 - - - - GCFF-Net 0.8290 0.8345 0.9739 0.9573 0.9813 表 4 不同算法在CHASEDB1数据集上的性能指标
Algorithm F1 SE SP ACC AUC R2U-Net[20] 0.7928 0.7756 0.9820 0.9634 0.9815 DU-Net[21] 0.8001 0.8115 0.9752 0.9610 0.9804 RSAN[23] 0.8111 0.8486 0.9836 0.9751 0.9804 MLA-Net[24] 0.8248 0.8042 0.9801 0.9673 0.9824 SA-UNet[25] 0.8153 0.8573 0.9835 0.9755 0.9905 DEU-Net[27] 0.8037 0.8074 0.9821 0.9661 0.9812 GCFF-Net 0.8379 0.8427 0.9791 0.9640 0.9878 -
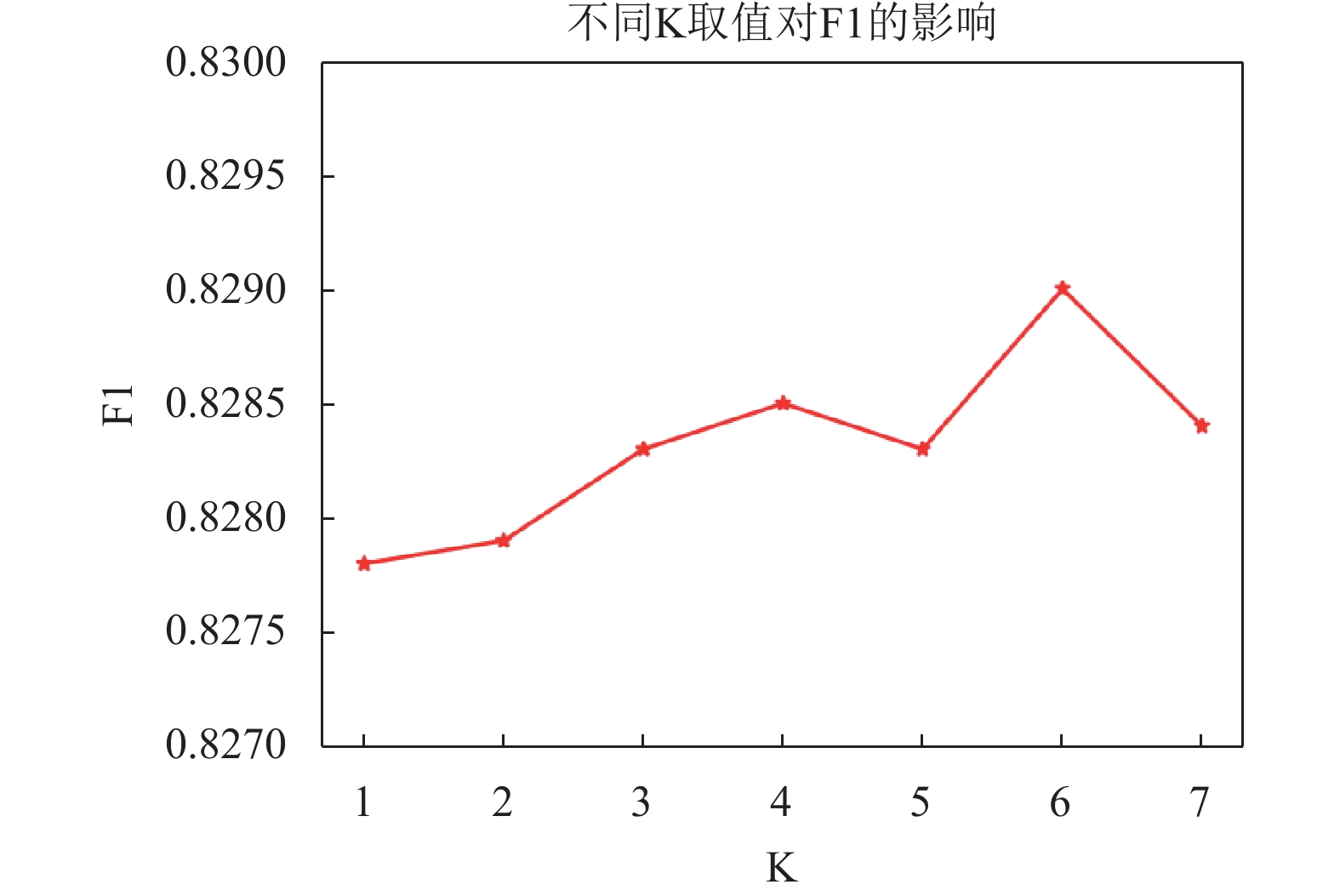
在使用K近邻算法构造图的过程中,邻居节点的数量K是一个控制聚集范围的超参数。邻居太少会降低信息交换的质量,而邻居节点太多会降低每个节点特征的独特性。为了得到最优的K值,在DRIVE数据集上将K设置从1调优到7,由图10可知,当邻居节点K取6时,F1值最佳。
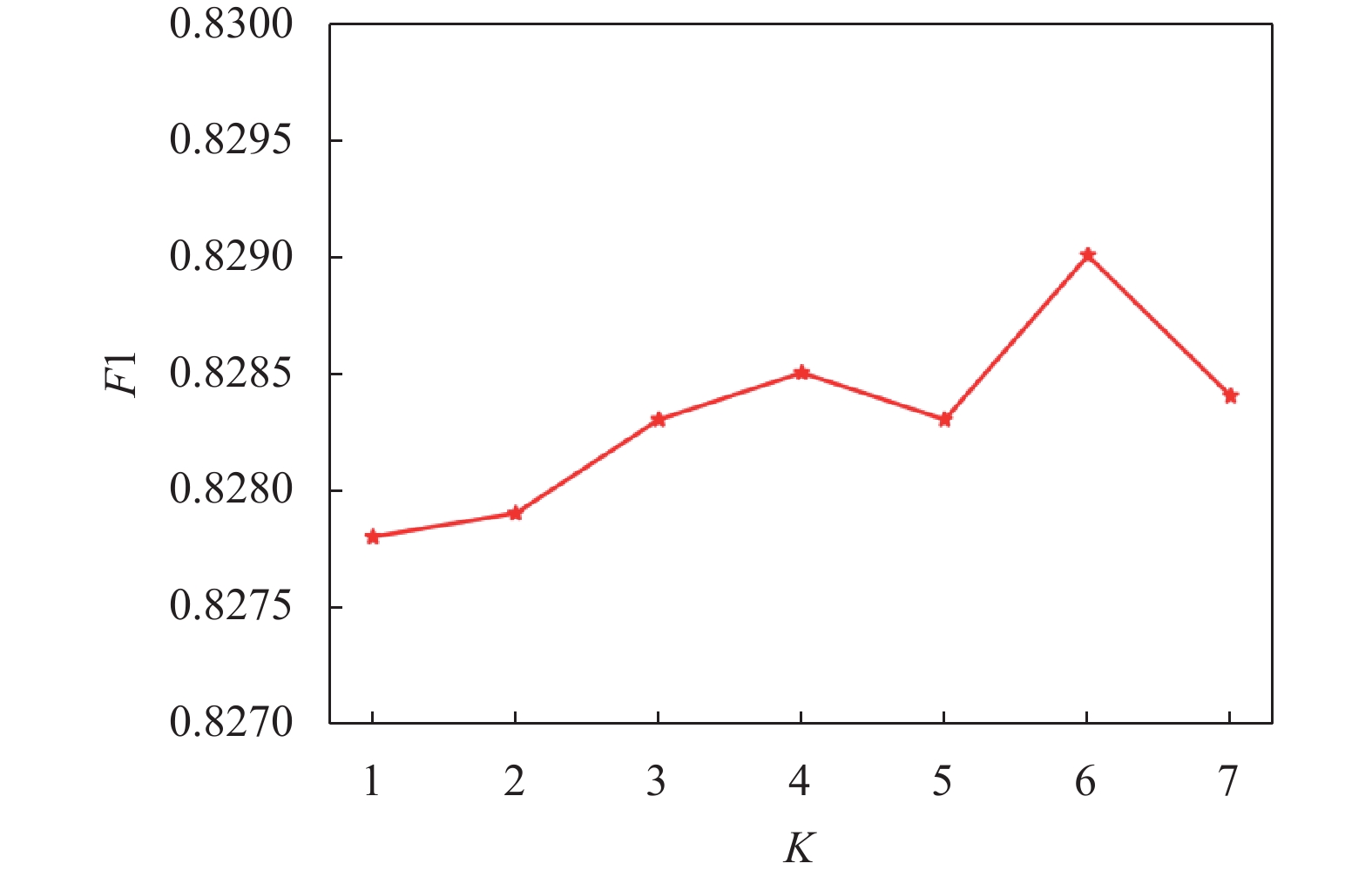
图 10 K取值分析
-
为了验证本文算法所提出模块的有效性,分别在DRIVE、CHASEDB1和STARE三个数据集上进行消融实验。实验结果如表2所示。表中模型A1表示基础模型U-Net,模型A2表示在模型A1的基础上加入GCN模块,模型A3表示在模型A2的基础上加入多层次特征融合模块,模型A4为本文算法。
从表6可知,由于U-Net使用普通卷积只能提取局部特征信息,导致血管像素容易被分类成背景像素,A2模型在U-Net的基础上加入图卷积模块,可以充分提取图像的全局特征信息,并且捕获血管像素之间的长期依赖关系,从而提升了模型提取血管像素的能力,在DRIVE数据集和CHASEDB1数据集上可以看到SE指标有所上升,由于STARE数据集中大部分图像血管像素占比较低,SE指标有所下降,但SP有所提升。模型A3加入多层次特征融合模块,各项指标均有所上升,说明多层次特征融合模块可以有效减少U-Net下采样过程中空间信息的损失,提升模型分割的准确度。模型A3加入多尺度特征融合块,减少了特征图中的噪声信息的同时且保留语义信息,达到了最好的分割效果。综上所述,本文提出的模块具有一定的有效性和合理性。
表 6 消融实验结果
Dataset model F1 SE SP ACC AUC DRIVE A1 0.8248 0.8213 0.9751 0.9555 0.9773 A2 0.8262 0.8313 0.9730 0.9560 0.9779 A3 0.8278 0.8342 0.9741 0.9571 0.9810 A4 0.8290 0.8345 0.9739 0.9573 0.9813 CHASEDB1 A1 0.8224 0.8213 0.9782 0.9609 0.9837 A2 0.8355 0.8455 0.9779 0.9629 0.9865 A3 0.8364 0.8464 0.9780 0.9635 0.9872 A4 0.8379 0.8427 0.9791 0.9640 0.9878 STARE A1 0.8002 0.7285 0.9896 0.9632 0.9807 A2 0.8015 0.7692 0.9817 0.9587 0.9822 A3 0.8038 0.7754 0.9813 0.9590 0.9829 A4 0.8063 0.7786 0.9814 0.9595 0.9836 -
本文针对视网膜血管分割中出现的血管断裂、边界不清晰等问题,在基于编码器-解码器的架构上进行改进,提出了一种图卷积多层级特征融合的视网膜血管分割算法。为了提升模型提取血管特征的能力,本文算法在编码器与解码器之间加入图卷积模块捕获血管像素之间的长距离依赖关系;同时在跳跃连接处加入多尺度特征融合模块以减少特征层中的噪声信息,并且使模型更加关注血管特征。此外,本文提出的多层次特征融合模块可以有效的减少因下采样造成的空间信息的损失。试验结果表明,本文算法的F1值在3个数据集上均高于其他算法,分割结果可视化图也显示出本文算法的优越性。然而,本文算法的图卷积模块中构图所使用的K-近邻算法比较耗时,增加了模型的训练时长和推理时长,在后续的研究中,主要探索使用注意力矩阵计算像素之间的相似性代替K近邻算法来构图,并且使用部分卷积代替传统卷积来减少模型的参数量,从而减少模型的时间复杂度与空间复杂度。
GCFF-Net:A Multilayer Graph Convolutional Feature Fusion Neural Encoding and Decoding Network for Fine Segmentation of Retinal Vessels
-
摘要: 眼底视网膜血管分割可以帮助医生对于眼科疾病以及心脑血管疾病进行辅助诊断。然而,由于血管拓扑结构复杂,边界不清晰,大大增加分割难度。针对这些问题,在U型结构的基础上提出了一种基于图卷积特征融合网络。该网络使用图卷积模块对编码器特征中像素之间的全局上下文信息进行建模,弥补普通卷积缺少全局建模的能力;然后使用多尺度特征融合模块对编码器特征与解码器特征进行融合,来减少特征层中噪声信息对分割结果的影响;最后使用多层次特征融合模块将解码器每一层特征融合输出,减少下采样过程中空间信息的缺失以及对深层特征的复用。在公开数据集DRIVE、CHASEDB1以及STARE上进行验证,F1值分别为82.90%、83.79%和80.63%,AUC分别为98.13%、98.78%和98.36%。实验结果表明,所提方法优于近些年视网膜分割算法。Abstract: Fundus retinal vessels segmentation can assist doctors in the diagnosis of ophthalmic diseases and cardiovascular and cerebrovascular diseases. However, due to the complex topological structure of blood vessels and unclear boundaries, it greatly increases the difficulty of segmentation. A graph convolutional feature fusion network is proposed based on the U-shaped structure to address these issues. This network uses a graph convolution module to model the global contextual information between pixels in encoder features, making up for the lack of global modeling ability in ordinary convolutions; Then, a multi-scale feature fusion module is used to fuse the encoder features and decoder features to reduce the impact of noise information in the feature layer on the segmentation results; Finally, a multi-level feature fusion module is used to fuse and output the features of each layer of the decoder, reducing the loss of spatial information and the reuse of deep features during the downsampling process. Verified on the public datasets DRIVE, CHASEDB1, and START, the F1 values were 82.90%, 83.79%, and 80.63%, respectively, and the AUC values were 98.13%, 98.78%, and 98.36%, respectively. The experimental results show that the proposed method is superior to recent retinal segmentation algorithms.
-
表 1 不同模型在DRIVE、CHASEDB1和STARE上的性能指标比较
Dataset Model F1 SE SP ACC AUC(ROC) DRIVE U-Net 0.8248 0.8213 0.9751 0.9555 0.9773 Attention U-Net 0.8254 0.8389 0.9717 0.9548 0.9805 GCFF-Net(ours) 0.8290 0.8345 0.9739 0.9573 0.9813 CHASEDB1 U-Net 0.8224 0.8213 0.9782 0.9609 0.9837 Attention U-Net 0.8328 0.8320 0.9778 0.9631 0.9873 GCFF-Net(ours) 0.8379 0.8427 0.9791 0.9640 0.9878 STARE U-Net 0.8002 0.7285 0.9896 0.9632 0.9807 Attention U-Net 0.8032 0.7546 0.9860 0.9626 0.9821 GCFF-Net(ours) 0.8063 0.7786 0.9814 0.9595 0.9836  下载: 导出CSV
下载: 导出CSV
表 2 不同模型复杂度对比
model Params(M) Times(ms) U-Net 34.5259 3.4007 Attention-Unet 34.8774 6.4478 GCFF-Net 34.8793 10.1559
下载: 导出CSV
表 3 不同算法在DRIVE数据集上的性能指标
Algorithm F1 SE SP ACC AUC R2U-Net[20] 0.8150 0.7735 0.9818 0.9553 0.9784 DUNet[21] 0.8237 0.7963 0.9721 0.9566 0.9820 MResU-Net[22] 0.8237 0.7969 0.9799 -- 0.9799 RSAN[23] 0.8222 0.8149 0.9839 0.9691 0.9855 MLA-Net[24] 0.8279 0.8046 0.9805 0.9581 0.9827 SA-UNet[25] 0.8263 0.8212 0.9840 0.9698 0.9864 ConvMixer[26] 0.8245 - - - - GCFF-Net 0.8290 0.8345 0.9739 0.9573 0.9813
下载: 导出CSV
表 4 不同算法在CHASEDB1数据集上的性能指标
Algorithm F1 SE SP ACC AUC R2U-Net[20] 0.7928 0.7756 0.9820 0.9634 0.9815 DU-Net[21] 0.8001 0.8115 0.9752 0.9610 0.9804 RSAN[23] 0.8111 0.8486 0.9836 0.9751 0.9804 MLA-Net[24] 0.8248 0.8042 0.9801 0.9673 0.9824 SA-UNet[25] 0.8153 0.8573 0.9835 0.9755 0.9905 DEU-Net[27] 0.8037 0.8074 0.9821 0.9661 0.9812 GCFF-Net 0.8379 0.8427 0.9791 0.9640 0.9878
下载: 导出CSV
表 6 消融实验结果
Dataset model F1 SE SP ACC AUC DRIVE A1 0.8248 0.8213 0.9751 0.9555 0.9773 A2 0.8262 0.8313 0.9730 0.9560 0.9779 A3 0.8278 0.8342 0.9741 0.9571 0.9810 A4 0.8290 0.8345 0.9739 0.9573 0.9813 CHASEDB1 A1 0.8224 0.8213 0.9782 0.9609 0.9837 A2 0.8355 0.8455 0.9779 0.9629 0.9865 A3 0.8364 0.8464 0.9780 0.9635 0.9872 A4 0.8379 0.8427 0.9791 0.9640 0.9878 STARE A1 0.8002 0.7285 0.9896 0.9632 0.9807 A2 0.8015 0.7692 0.9817 0.9587 0.9822 A3 0.8038 0.7754 0.9813 0.9590 0.9829 A4 0.8063 0.7786 0.9814 0.9595 0.9836
下载: 导出CSV
-
[1] 李兰兰, 张孝辉, 牛得草, 等. 深度学习在视网膜血管分割上的研究进展[J]. 计算机科学与探索, 2021, 15(11): 2063-2076. doi: 10.3778/j.issn.1673-9418.2103099 LI L L, ZHANG X H, NIU D C, et al. Research progress of deep learning in retinal vessel segmentation[J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(11): 2063-2076. doi: 10.3778/j.issn.1673-9418.2103099 [2] MENDONÇA A M, CAMPILHO A. Segmentation of retinal blood vessels by combining the detection of centerlines and morphological reconstruction[J]. IEEE Trans Med Imaging, 2006, 25(9): 1200-1213. doi: 10.1109/TMI.2006.879955 [3] YU Q Z, WANG X H, WANG X F, et al. Retinal vessels segmentation based on level set and region growing[J]. Pattern Recognition, 2014, 47(7): 2437-2446. doi: 10.1016/j.patcog.2014.01.006 [4] JIANG Z, ZHANG H, WANG Y, et al. Retinal blood vessel segmentation using fully convolutional network with transfer learning[J]. Comput Med Imaging Graph, 2018, 68: 1-15. doi: 10.1016/j.compmedimag.2018.04.005 [5] LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2015: 3431-3440. [6] LI L Z, VERMA M, NAKASHIMA Y, et al. IterNet: Retinal image segmentation utilizing structural redundancy in vessel networks[C]//Proceedings of the IEEE Winter Conference on Applications of Computer Vision. New York: IEEE, 2020: 3656–3665. [7] DU X F, WANG J S, SUN W Z. UNet retinal blood vessel segmentation algorithm based on improved pyramid pooling method and attention mechanism[J]. Physics in Medicine and Biology, 2021, 66(17): 175013. doi: 10.1088/1361-6560/ac1c4c [8] 梁礼明, 蓝智敏, 盛校棋, 等. 融合轮廓信息与条件生成对抗的视网膜血管分割[J]. 生物医学工程学杂志, 2021, 38(2): 276-285. doi: 10.7507/1001-5515.202005019 LIANG L M, LAN Z M, SHENG X Q, et al. Segmentation of retinal vessels by fusing contour information and conditional generative adversarial[J]. Journal of Biomedical Engineering, 2021, 38(2): 276-285. doi: 10.7507/1001-5515.202005019 [9] GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial networks[J]. Communications of the ACM, 2020, 63(11): 139-144. doi: 10.1145/3422622 [10] CHOLLET F. Xception: Deep learning with depthwise separable convolutions[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2017: 1251-1258. [11] HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 7132-7141. [12] 蒋芸, 刘文欢, 梁菁. 联合注意力和Transformer的视网膜血管分割网络[J]. 计算机工程与科学, 2022, 44(11): 2037-2047. JIANG Y, LIU W H, LIANG J. Retinal vessel segmentation network with joint attention and Transformer[J]. Computer Engineering & Science, 2022, 44(11): 2037-2047. [13] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[J]. Advances in Neural Information Processing Systems, 2017, 30. [14] RONNEBERGER O, FISCHER P, BROX T. U-net: Convolutional networks for biomedical image segmentation[M]//Lecture Notes in Computer Science. Cham: Springer International Publishing, 2015: 234-241. [15] KIPF T, WELLING M. Semi-supervised classification with graph convolutional networks[C]//International Conference on Learning Representations. 2016. [16] HAN K, WANG Y, GUO J, et al. Vision GNN: An image is worth graph of nodes[C]//Advances in Neural Information Processing Systems. [17] WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]//European Conference on Computer Vision. Cham: Springer, 2018: 3-19. [18] CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Trans Pattern Anal Mach Intell, 2018, 40(4): 834-848. doi: 10.1109/TPAMI.2017.2699184 [19] OKTAY O, SCHLEMPER J, LE FOLGOC L, et al. Attention U-Net: Learning where to look for the pancreas[C]//Medical Imaging with Deep Learning. [20] ALOM M Z, YAKOPCIC C, HASAN M, et al. Recurrent residual U-Net for medical image segmentation[J]. Journal of Medical Imaging, 2019, 6(1): 014006. [21] JIN Q G, MENG Z P, PHAM T D, et al. DUNet: A deformable network for retinal vessel segmentation[J]. Knowledge-Based Systems, 2019, 178(C): 149-162. [22] LI D, DHARMAWAN D A, NG B P, et al. Residual U-net for retinal vessel segmentation[C]//Proceedings of the IEEE International Conference on Image Processing. New York: IEEE, 2019: 1425-1429. [23] GUO C L, SZEMENYEI M, YI Y G, et al. Residual spatial attention network for retinal vessel segmentation[C]//Proceedings of the Neural Information Processing: 27th International Conference. New York: ACM, 2020: 509–519. [24] YUAN Y, ZHANG L, WANG L, et al. Multi-level attention network for retinal vessel segmentation[J]. IEEE J Biomed Health Inform, 2022, 26(1): 312-323. doi: 10.1109/JBHI.2021.3089201 [25] GUO C L, SZEMENYEI M, YI Y G, et al. SA-UNet: Spatial attention U-net for retinal vessel segmentation[C]//Proceedings of the 25th International Conference on Pattern Recognition. New York: IEEE, 2021: 1236-1242. [26] SOLANO A, DIETRICH K N, MARTÍNEZ-SOBER M, et al. Deep learning architectures for diagnosis of diabetic retinopathy[J]. Applied Sciences, 2023, 13(7): 4445. doi: 10.3390/app13074445 [27] WANG B, QIU S, HE H G. Dual encoding U-net for retinal vessel segmentation[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer, 2019: 84-92. [28] LI H, WANG Y K, WAN C, et al. MAU-net: A retinal vessels segmentation method[C]//Proceedings of the 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society. New York: IEEE, 2020: 1958-1961. [29] LI X J, DING J Q, TANG J J, et al. Res2Unet: A multi-scale channel attention network for retinal vessel segmentation[J]. Neural Computing and Applications, 2022, 34(14): 12001-12015. doi: 10.1007/s00521-022-07086-8 [30] ZHANG Y, FANG J, CHEN Y, et al. Edge-aware U-net with gated convolution for retinal vessel segmentation[J]. Biomedical Signal Processing and Control, 2022, 73: 103472. doi: 10.1016/j.bspc.2021.103472 [31] WANG C, ZHAO Z Y, YU Y. Fine retinal vessel segmentation by combining Nest U-net and patch-learning[J]. Soft Computing, 2021, 25(7): 5519-5532. doi: 10.1007/s00500-020-05552-w -

 点击查看大图
点击查看大图
图(10) / 表(6)
计量
- 文章访问数: 252
- HTML全文浏览量: 95
- PDF下载量: 8
- 被引次数: 0









































